Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Se aplica a:![]() SQL Server en Linux
SQL Server en Linux
En este documento se describe cómo realizar las siguientes tareas para SQL Server en un clúster de conmutación por error de disco compartido con Red Hat Enterprise Linux.
- Conmutación por error manual del clúster
- Supervisión de un servicio de SQL Server de clúster de conmutación por error
- Adición de un nodo de clúster
- Eliminación de un nodo de clúster
- Cambio de la frecuencia de supervisión de recursos de SQL Server
Descripción de la arquitectura
La capa de agrupación en clústeres se basa en el complemento de alta disponibilidad de Red Hat Enterprise Linux (RHEL) sobre Pacemaker. Corosync y Pacemaker coordinan las comunicaciones del clúster y la administración de recursos. La instancia de SQL Server está activa en un nodo o en el otro.
En el siguiente diagrama se ilustran los componentes de un clúster de Linux con SQL Server.
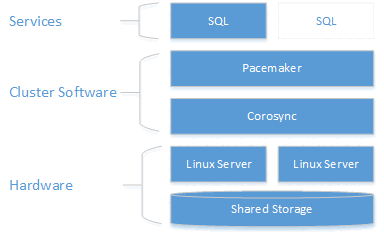
Para obtener más información sobre la configuración del clúster, las opciones de los agentes de recursos y la administración, vaya a la documentación de referencia de RHEL.
Conmutación por error manual del clúster
El comando resource move crea una restricción que obliga al recurso a iniciarse en el nodo de destino. Después de ejecutar el comando move, al ejecutar el recurso clear se quitará la restricción, por lo que es posible volver a colocar el recurso o hacer que este conmute por error automáticamente.
sudo pcs resource move <sqlResourceName> <targetNodeName>
sudo pcs resource clear <sqlResourceName>
En el ejemplo siguiente se mueve el recurso mssqlha a un nodo denominado sqlfcivm2 y después se quita la restricción para que el recurso pueda moverse más adelante a otro nodo.
sudo pcs resource move mssqlha sqlfcivm2
sudo pcs resource clear mssqlha
Supervisión de un servicio de SQL Server de clúster de conmutación por error
Vea el estado actual del clúster:
sudo pcs status
Vea el estado activo del clúster y los recursos:
sudo crm_mon
Vea los registros del agente de recursos en /var/log/cluster/corosync.log.
Adición de un nodo a un clúster
Compruebe la dirección IP de cada nodo. En el siguiente script se muestra la dirección IP del nodo actual.
ip addr showEl nuevo nodo necesita un nombre único que tenga 15 caracteres o menos. De forma predeterminada, en Red Hat Linux el nombre del equipo es
localhost.localdomain. Es posible que este nombre predeterminado no sea único y sea demasiado largo. Establezca el nombre de equipo del nuevo nodo. Para establecer el nombre de equipo, agréguelo a/etc/hosts. El siguiente script le permite editar/etc/hostsconvi.sudo vi /etc/hostsEn el ejemplo siguiente se muestra
/etc/hostscon adiciones para tres nodos denominadossqlfcivm1,sqlfcivm2ysqlfcivm3.127.0.0.1 localhost localhost4 localhost4.localdomain4 ::1 localhost localhost6 localhost6.localdomain6 10.128.18.128 fcivm1 10.128.16.77 fcivm2 10.128.14.26 fcivm3El archivo debe ser el mismo en todos los nodos.
Detenga el servicio SQL Server en el nuevo nodo.
Siga las instrucciones para montar el directorio de archivos de base de datos en la ubicación compartida:
Desde el servidor NFS, instale
nfs-utils:sudo yum -y install nfs-utilsAbra el firewall en clientes y servidor NFS:
sudo firewall-cmd --permanent --add-service=nfs sudo firewall-cmd --permanent --add-service=mountd sudo firewall-cmd --permanent --add-service=rpc-bind sudo firewall-cmd --reloadEdite el archivo
/etc/fstabpara incluir el comando mount:<IP OF NFS SERVER>:<shared_storage_path> <database_files_directory_path> nfs timeo=14,intrEjecute
mount -apara aplicar los cambios.En el nuevo nodo, cree un archivo para almacenar el nombre de usuario y la contraseña de SQL Server para el inicio de sesión de Pacemaker. Con el siguiente comando se crea y rellena este archivo:
sudo touch /var/opt/mssql/passwd sudo echo "<loginName>" >> /var/opt/mssql/secrets/passwd sudo echo "<password>" >> /var/opt/mssql/secrets/passwd sudo chown root:root /var/opt/mssql/passwd sudo chmod 600 /var/opt/mssql/passwdPrecaución
La contraseña debe seguir la directiva de contraseña predeterminada de SQL Server. De forma predeterminada, la contraseña debe tener al menos ocho caracteres y contener caracteres de tres de los siguientes cuatro conjuntos: mayúsculas, minúsculas, dígitos en base 10 y símbolos. Las contraseñas pueden tener hasta 128 caracteres. Use contraseñas lo más largas y complejas posible.
En el nuevo nodo, abra los puertos de firewall de Pacemaker. Para abrir estos puertos con
firewalld, ejecute el comando siguiente:sudo firewall-cmd --permanent --add-service=high-availability sudo firewall-cmd --reloadSi usa otro firewall que no tiene una configuración de alta disponibilidad integrada, deberán abrirse los puertos siguientes para que Pacemaker pueda comunicarse con otros nodos del clúster:
- TCP: puertos 2224, 3121, 21064
- UDP: puerto 5405
Instale paquetes de Pacemaker en el nuevo nodo.
sudo yum install pacemaker pcs fence-agents-all resource-agentsEstablezca la contraseña para el usuario predeterminado que se crea al instalar paquetes de Pacemaker y Corosync. Use la misma contraseña que los nodos existentes.
sudo passwd haclusterHabilite e inicie el servicio
pcsdy Pacemaker. Esto permitirá que el nuevo nodo se vuelva a unir al clúster después del reinicio. Ejecute el siguiente comando en el nuevo nodo.sudo systemctl enable pcsd sudo systemctl start pcsd sudo systemctl enable pacemakerInstale el agente de recursos de FCI para SQL Server. Ejecute los siguientes comandos en el nuevo nodo.
sudo yum install mssql-server-haEn un nodo existente del clúster, autentique el nuevo nodo y agréguelo al clúster:
sudo pcs cluster auth <nodeName3> -u hacluster sudo pcs cluster node add <nodeName3>En el ejemplo siguiente se agrega un nodo denominado vm3 al clúster.
sudo pcs cluster auth sudo pcs cluster start
Eliminación de nodos de un clúster
Para quitar un nodo de un clúster, ejecute el siguiente comando:
sudo pcs cluster node remove <nodeName>
Cambio de la frecuencia del intervalo de supervisión de recursos sqlservr
sudo pcs resource op monitor interval=<interval>s <sqlResourceName>
En el ejemplo siguiente se establece el intervalo de supervisión en 2 segundos para el recurso mssql:
sudo pcs resource op monitor interval=2s mssqlha
Solución de problemas del clúster de disco compartido de Red Hat Enterprise Linux para SQL Server
Para solucionar problemas del clúster, puede ser útil comprender cómo funcionan conjuntamente los tres demonios para administrar los recursos del clúster.
| Demonio | Descripción |
|---|---|
| Corosync | Proporciona la pertenencia al cuórum y la mensajería entre los nodos del clúster. |
| Marcapasos | Reside en Corosync y proporciona equipos de estado de los recursos. |
| PCSD | Administra Pacemaker y Corosync mediante las herramientas pcs. |
PCSD debe estar en ejecución para poder usar las herramientas pcs.
Estado actual del clúster
sudo pcs status devuelve información básica sobre el clúster, el cuórum, los nodos, los recursos y el estado del demonio de cada nodo.
Aquí tiene un ejemplo de una salida correcta del cuórum de Pacemaker:
Cluster name: MyAppSQL
Last updated: Wed Oct 31 12:00:00 2016 Last change: Wed Oct 31 11:00:00 2016 by root via crm_resource on sqlvmnode1
Stack: corosync
Current DC: sqlvmnode1 (version 1.1.13-10.el7_2.4-44eb2dd) - partition with quorum
3 nodes and 1 resource configured
Online: [ sqlvmnode1 sqlvmnode2 sqlvmnode3 ]
Full list of resources:
mssqlha (ocf::sql:fci): Started sqlvmnode1
PCSD Status:
sqlvmnode1: Online
sqlvmnode2: Online
sqlvmnode3: Online
Daemon Status:
corosync: active/disabled
pacemaker: active/enabled
En el ejemplo, partition with quorum implica que un cuórum de mayoría de nodos está en línea. Si el clúster pierde un cuórum de mayoría de nodos, pcs status devolverá partition WITHOUT quorum y se detendrán todos los recursos.
online: [sqlvmnode1 sqlvmnode2 sqlvmnode3] devuelve el nombre de todos los nodos que participan actualmente en el clúster. Si algún nodo no participa, pcs status devuelve OFFLINE: [<nodename>].
PCSD Status muestra el estado del clúster de cada nodo.
Motivos por los que un nodo puede estar sin conexión
Compruebe los elementos siguientes si un nodo está sin conexión.
Cortafuegos
Los siguientes puertos deben estar abiertos en todos los nodos para que Pacemaker pueda comunicarse.
- **TCP: 2224, 3121, 21064
Servicios de Pacemaker o Corosync en ejecución
Comunicación de los nodos
Asignaciones de nombres de los nodos