Introducción a los índices de almacén de columnas para el análisis operativo en tiempo real
Se aplica a: ![]() SQL Server
SQL Server ![]() Azure SQL Database
Azure SQL Database ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
SQL Server 2016 (13.x) incorpora análisis operativos en tiempo real, esto es, la posibilidad de ejecutar simultáneamente análisis y cargas de trabajo OLTP en las mismas tablas de base de datos. Aparte de poder ejecutar análisis en tiempo real, también puede prescindir del uso de ETL y de un almacén de datos.
Análisis operativos en tiempo real explicados
Tradicionalmente, las empresas siempre han tenido sistemas independientes para las cargas de trabajo operativas (es decir, OLTP) y de análisis. En estos sistemas, los trabajos de extracción, transformación y carga de datos (ETL) mueven periódicamente los datos desde el almacén operativo a un almacenamiento de análisis. Los datos de análisis suelen residir en un almacén de datos o data mart dedicado a ejecutar consultas de análisis. Si bien esto ha venido siendo lo habitual, plantea tres retos importantes:
Complejidad. La implementación de ETL puede conllevar una tarea de codificación considerable, especialmente para cargar solamente las filas modificadas. Saber qué filas se han modificado puede ser bastante complicado.
Costo. La implementación de ETL requiere invertir en más licencias de software y hardware.
Latencia de datos. La implementación de ETL conlleva un retraso de tiempo a la hora de ejecutar los análisis. Por ejemplo, si el trabajo de ETL tiene lugar al final de cada día laborable, las consultas de análisis se ejecutarán en datos que llevan como mínimo un día de desfase. Para muchas empresas, este retraso es inaceptable porque el negocio depende de poder analizar los datos en tiempo real. Por ejemplo, para poder detectar fraudes, es preciso analizar los datos operativos en tiempo real.
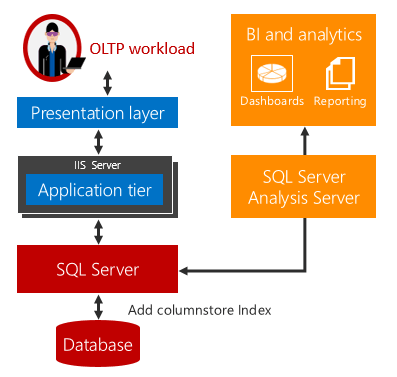
Los análisis operativos en tiempo real ofrecen una solución a estos retos.
No comportan ningún retraso cuando las cargas de trabajo OLTP y de análisis se ejecutan en la misma tabla subyacente. En las situaciones en las que se pueden usar análisis en tiempo real, los costos y la complejidad se reducen enormemente, ya que se pone fin a la necesidad de realizar trabajos ETL o de adquirir y mantener un almacén de datos independiente.
Nota:
Los análisis operativos en tiempo real abordan un escenario con un único origen de datos, como una aplicación de planificación de recursos empresariales (ERP) en la que se pueden ejecutar las cargas de trabajo tanto operativas como de análisis. Esto no significa que no pueda necesitarse un almacén de datos independiente cuando haya que integrar datos procedentes de varios orígenes antes de ejecutar la carga de trabajo de análisis, o cuando necesite disponer de un rendimiento de análisis extremo con datos previamente agregados, como los cubos.
Los análisis en tiempo real usan un índice de almacén de columnas actualizable en una tabla de almacén de filas. El índice de almacén de columnas mantiene una copia de los datos, por lo que las cargas de trabajo OLTP y de análisis ejecutarán copias de los datos distintas. Esto reduce el impacto en el rendimiento que supone ejecutar ambas cargas de trabajo al mismo tiempo. SQL Server mantiene automáticamente los cambios en el índice para que los cambios de OLTP siempre estén actualizados para los análisis. Con este diseño, es posible (y útil) ejecutar análisis en tiempo real en los datos actualizados. Esto es válido tanto para las tablas basadas en disco como para las tablas optimizadas para memoria.
Ejemplo introductorio
Para empezar a usar análisis en tiempo real:
Identifique las tablas del esquema operativo que contienen los datos necesarios para el análisis.
En cada tabla, quite todos los índices de árbol B que están diseñados principalmente para acelerar el análisis existente en la carga de trabajo OLTP. Sustitúyalos por un índice de almacén de columnas único. Esto mejorará el rendimiento general de la carga de trabajo OLTP, ya que habrá menos índices que mantener.
--This example creates a nonclustered columnstore index on an existing OLTP table. --Create the table CREATE TABLE t_account ( accountkey int PRIMARY KEY, accountdescription nvarchar (50), accounttype nvarchar(50), unitsold int ); --Create the columnstore index with a filtered condition CREATE NONCLUSTERED COLUMNSTORE INDEX account_NCCI ON t_account (accountkey, accountdescription, unitsold) ;El índice de almacén de columnas de una tabla en memoria permite los análisis operativos al integrar las tecnologías de OLTP en memoria y almacén de columnas en memoria, con lo que se logra un alto rendimiento en las cargas de trabajo OLTP y de análisis. El índice de almacén de columnas de una tabla en memoria debe incluir todas las columnas.
-- This example creates a memory-optimized table with a columnstore index. CREATE TABLE t_account ( accountkey int NOT NULL PRIMARY KEY NONCLUSTERED, Accountdescription nvarchar (50), accounttype nvarchar(50), unitsold int, INDEX t_account_cci CLUSTERED COLUMNSTORE ) WITH (MEMORY_OPTIMIZED = ON ); GO
Ya está listo para ejecutar análisis operativos en tiempo real, sin haber realizado ningún cambio en la aplicación. Las consultas de análisis se ejecutarán en el índice de almacén de columnas y las operaciones OLTP seguirán ejecutándose en los índices de árbol B de OLTP. Las cargas de trabajo OLTP seguirán produciéndose, si bien con una ligera sobrecarga adicional para mantener el índice de almacén de columnas. Vea las optimizaciones de rendimiento en la siguiente sección.
Nota:
La documentación utiliza el término árbol B generalmente en referencia a los índices. En los índices del almacén de filas, el motor de la base de datos implementa un árbol B+. Esto no se aplica a los índices de almacén de columnas ni a los índices de tablas optimizadas para memoria. Para obtener más información, consulte la guía de diseño y arquitectura de índices de SQL Server y Azure SQL.
Publicaciones de blog
Lea las entradas de blog siguientes para obtener más información sobre el análisis operativo en tiempo real. Si lee estas entradas de blog primero, probablemente le será más fácil entender las secciones de consejos de rendimiento.
Vídeos
La serie de vídeos Data Exposed en más detalles sobre algunas de las funcionalidades y consideraciones.
- Parte 1: Cómo Azure SQL habilita análisis operativos en tiempo real (HTAP)
- Parte 2: Optimización de las aplicaciones y bases de datos existentes con análisis operativos
- Parte 3: Creación de análisis operativos con funciones de ventana.
Consejo de rendimiento n.º 1: usar índices filtrados para mejorar el rendimiento de las consultas
Los análisis operativos en tiempo real pueden tener un impacto negativo en el rendimiento de la carga de trabajo OLTP. Este impacto debería ser mínimo. En el ejemplo A se muestra cómo usar índices filtrados para minimizar el impacto del índice de almacén de columnas no agrupado en la carga de trabajo transaccional mientras se sigue entregando análisis en tiempo real.
Para reducir la sobrecarga derivada de mantener un índice de almacén de columnas no agrupado en una carga de trabajo operativa, puede usar una condición de filtrado para crear un índice de almacén de columnas no agrupado únicamente de los datos semiactivos o de variación lenta. Por ejemplo, en una aplicación de administración de pedidos, puede crear un índice de almacén de columnas no agrupado de los pedidos que ya se hayan enviado. Una vez que un pedido se envía, este apenas si cambia y, por tanto, se puede considerar como un dato semiactivo. Con el índice filtrado, los datos del índice de almacén de columnas no agrupado requieren menos actualizaciones, lo que reduce el impacto en la carga de trabajo transaccional.
Las consultas de análisis tienen un acceso transparente a los datos tanto activos como semiactivos, según sea necesario para proporcionar análisis en tiempo real. Si una parte considerable de la carga de trabajo operativa usa los datos "de acceso frecuente", esas operaciones no requerirán un mantenimiento adicional del índice de almacén de columnas. Un procedimiento recomendado es tener un índice agrupado de almacén de filas en las columnas usadas en la definición del índice filtrado. SQL Server usa el índice agrupado para examinar rápidamente las filas que no cumplen la condición de filtrado. Sin este índice agrupado, sería necesario realizar un recorrido de tabla completo de la tabla de almacén de filas para encontrar dichas filas, lo que puede repercutir negativamente y en gran medida en el rendimiento de las consultas de análisis. Si no hay un índice agrupado, podría crear un índice complementario de árbol B no agrupado filtrado para identificar esas filas, pero esto no es recomendable porque el acceso a un amplio rango de filas a través de índices de árbol B no agrupados es muy costoso.
Nota:
Un índice de almacén de columnas no agrupado filtrado solo se puede usar en tablas basadas en disco. No se admite en tablas optimizadas para memoria.
Ejemplo A: acceso a datos de acceso frecuente del índice de árbol B y a datos semiactivos del índice de almacén de columnas
En este ejemplo se usa una condición filtrada (accountkey > 0) para establecer qué filas estarán en el índice de almacén de columnas. El objetivo es diseñar la condición de filtrado y las consultas posteriores para acceder a los datos de acceso “frecuente” del índice de árbol B+ que cambian con frecuencia, así como para acceder a los datos "semiactivos" del índice de almacén de columnas, que son más estables.

Nota:
El Optimizador de consultas tendrá en cuenta el índice de almacén de columnas para el plan de consulta, pero no siempre lo elegirá. Cuando el optimizador de consultas elige el índice de almacén de columnas filtrado, combina de forma transparente tanto las filas del índice de almacén de columnas como las filas que no cumplen con la condición de filtrado para permitir los análisis en tiempo real. Esto difiere de un índice filtrado no agrupado regular, que solo se puede usar en las consultas limitadas a las filas existentes en el índice.
--Use a filtered condition to separate hot data in a rowstore table
-- from "warm" data in a columnstore index.
-- create the table
CREATE TABLE orders (
AccountKey int not null,
Customername nvarchar (50),
OrderNumber bigint,
PurchasePrice decimal (9,2),
OrderStatus smallint not null,
OrderStatusDesc nvarchar (50));
-- OrderStatusDesc
-- 0 => 'Order Started'
-- 1 => 'Order Closed'
-- 2 => 'Order Paid'
-- 3 => 'Order Fullfillment Wait'
-- 4 => 'Order Shipped'
-- 5 => 'Order Received'
CREATE CLUSTERED INDEX orders_ci ON orders(OrderStatus);
--Create the columnstore index with a filtered condition
CREATE NONCLUSTERED COLUMNSTORE INDEX orders_ncci ON orders (accountkey, customername, purchaseprice, orderstatus)
where orderstatus = 5;
-- The following query returns the total purchase done by customers for items > $100 .00
-- This query will pick rows both from NCCI and from 'hot' rows that are not part of NCCI
SELECT top 5 customername, sum (PurchasePrice)
FROM orders
WHERE purchaseprice > 100.0
Group By customername;
La consulta de análisis se ejecutará con el siguiente plan de consulta. Aquí se aprecia que el acceso a las filas que no cumplen con la condición de filtro se efectúa a través del índice de árbol B agrupado.

Para obtener más información, consulte Blog: Índice de almacén de columnas no agrupado filtrado.
Consejo de rendimiento n.º 2: descargar el análisis en una secundaria legible de AlwaysOn
Aunque puede usar un índice de almacén de columnas filtrado para minimizar el mantenimiento de los índices de almacén de columnas, las consultas de análisis seguirán necesitando importantes cantidades de recursos informáticos (CPU, E/S, memoria) que afectan al rendimiento de las cargas de trabajo operativas. Nuestra recomendación para la mayor parte de las cargas de trabajo críticas es usar la configuración de AlwaysOn. En esta configuración, puede eliminar el impacto de los análisis descargándolos en una secundaria legible.
Consejo de rendimiento n.º 3: reducir la fragmentación de índice conservando los datos activos en grupos de filas delta
Las tablas con índice de almacén de columnas pueden fragmentarse significativamente (es decir, filas eliminadas) si la carga de trabajo actualiza o elimina filas que se han comprimido. Un índice de almacén de columnas fragmentado conduce a un uso ineficaz de la memoria y el almacenamiento. Pero, aparte del uso ineficiente de los recursos, también repercute negativamente en el rendimiento de las consultas de análisis, dada la E/S adicional y la necesidad de filtrar las filas eliminadas del conjunto de resultados.
Las filas eliminadas no se quitarán físicamente hasta que se ejecute una desfragmentación del índice con el comando REORGANIZE o hasta que se recompile el índice de almacén de columnas en toda la tabla o en las particiones afectadas. Ambos comandos, REORGANIZE y REBUILD, son operaciones costosas que consumen recursos que, de otro modo, se podrían usar para la carga de trabajo. Además, si las filas se comprimen demasiado pronto, es posible que deba volver a comprimirse varias veces debido a las actualizaciones que conducen a una sobrecarga de compresión desperdiciada.
La fragmentación del índice se puede minimizar con la opción COMPRESSION_DELAY.
-- Create a sample table
CREATE TABLE t_colstor (
accountkey int not null,
accountdescription nvarchar (50) not null,
accounttype nvarchar(50),
accountCodeAlternatekey int);
-- Creating nonclustered columnstore index with COMPRESSION_DELAY. The columnstore index will keep the rows in closed delta rowgroup for 100 minutes
-- after it has been marked closed
CREATE NONCLUSTERED COLUMNSTORE index t_colstor_cci on t_colstor (accountkey, accountdescription, accounttype)
WITH (DATA_COMPRESSION= COLUMNSTORE, COMPRESSION_DELAY = 100);
Para obtener más información, consulte Blog: Retraso de compresión.
A continuación encontrará los procedimientos recomendados:
Carga de trabajo de inserción/consulta: si la carga de trabajo consiste principalmente en insertar datos y realizar consultas sobre estos, la opción recomendada para COMPRESSION_DELAY es 0. Las filas recién insertadas se comprimirán cuando se haya insertado 1 millón de filas en un solo grupo de filas delta.
Algunos ejemplos de dicha carga de trabajo son (a) análisis de secuencia de selección tradicional de dw (b) cuando necesite analizar el patrón de selección en una aplicación web.Carga de trabajo OLTP: si la carga de trabajo es pesada de DML (es decir, una combinación intensiva de actualización, eliminación e inserción), es posible que vea la fragmentación del índice de almacén de columnas mediante el examen de la DMV
sys. dm_db_column_store_row_group_physical_stats. Si ve que > 10 % de las filas se marcan como eliminadas en los grupos de filas comprimidos recientemente, puede usar la opción COMPRESSION_DELAY para agregar un retraso cuando las filas sean aptas para la compresión. Por ejemplo, si en la carga de trabajo las filas recién insertadas se mantienen como "activas" (es decir, se actualizan varias veces) durante, digamos, 60 minutos, conviene establecer la opción COMPRESSION_DELAY en 60.
Es de esperar que la mayoría de los clientes no tenga que hacer nada. El valor predeterminado de COMPRESSION_DELAY la opción debe funcionar para ellos.
Para los usuarios avanzados, se recomienda ejecutar la consulta siguiente y recopilar el porcentaje de filas eliminadas durante los últimos siete días.
SELECT row_group_id,cast(deleted_rows as float)/cast(total_rows as float)*100 as [% fragmented], created_time
FROM sys. dm_db_column_store_row_group_physical_stats
WHERE object_id = object_id('FactOnlineSales2')
AND state_desc='COMPRESSED'
AND deleted_rows>0
AND created_time > GETDATE() - 7
ORDER BY created_time DESC;
Si el número de filas eliminadas en grupos de filas comprimidos > 20 %, se aplana en grupos de filas más antiguos con < una variación del 5 % (denominada grupos de filas en frío) establecido COMPRESSION_DELAY = (youngest_rowgroup_created_time - current_time). Este enfoque funciona mejor con una carga de trabajo estable y relativamente homogénea.
Contenido relacionado
- Introducción a los índices de almacén de columnas
- Índices de almacén de columnas: Guía de carga de datos
- Rendimiento de las consultas de índices de almacén de columnas
- Índices de almacén de columnas en el almacenamiento de datos
- Optimización del mantenimiento de índices para mejorar el rendimiento de las consultas y reducir el consumo de recursos