Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Aplica a:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() Azure Synapse Analytics
Azure Synapse Analytics![]() Sistema de Plataforma de Analítica (PDW)
Sistema de Plataforma de Analítica (PDW)![]() Base de datos SQL en Microsoft Fabric
Base de datos SQL en Microsoft Fabric
SQL Server usa combinaciones para recuperar datos de varias tablas en función de las relaciones lógicas entre ellas. Las combinaciones son fundamentales para las operaciones de base de datos relacionales y permiten combinar datos de dos o más tablas en un único conjunto de resultados.
SQL Server implementa las operaciones de combinación lógica (definidas por Transact-SQL sintaxis) y las operaciones de combinación física (los algoritmos reales que se usan para ejecutar las combinaciones). Comprender ambos aspectos le ayuda a escribir consultas eficaces y optimizar el rendimiento de la base de datos.
Las operaciones de combinación lógica incluyen:
- Combinaciones internas
- Combinaciones externas izquierda, derecha y completa
- Combinaciones cruzadas
Las operaciones de combinación física incluyen:
- Combinaciones de bucles anidados
- Combinaciones de mezcla
- Combinaciones hash
- Combinaciones adaptables (se aplica a: SQL Server 2017 (14.x) y versiones posteriores)
En este artículo se explica cómo funcionan las combinaciones, cuándo usar diferentes tipos de combinación y cómo selecciona el algoritmo de combinación más eficaz en función de factores como el tamaño de tabla, los índices disponibles y la distribución de datos.
Note
Para obtener más información sobre la sintaxis de combinación, vea CLÁUSULA FROM más JOIN, APPLY, PIVOT.
Aspectos básicos de la unión
Las combinaciones permiten recuperar datos de dos o más tablas según las relaciones lógicas entre ellas. Las combinaciones indican cómo debe usar SQL Server los datos de una tabla para seleccionar las filas de otra tabla.
Una condición de combinación define la forma en la que dos tablas se relacionan en una consulta al:
- Especificar la columna de cada tabla que debe usarse para la combinación. Una condición de combinación típica especifica una clave externa de una tabla y su clave asociada en otra tabla.
- Puede especificar un operador lógico (por ejemplo, = o <>) que se use para comparar los valores de las columnas.
Las combinaciones se expresan lógicamente mediante la siguiente sintaxis de Transact-SQL:
[ INNER ] JOINLEFT [ OUTER ] JOINRIGHT [ OUTER ] JOINFULL [ OUTER ] JOINCROSS JOIN
Las combinaciones internas se pueden especificar en las cláusulas FROM o WHERE. Las combinaciones externas y las combinaciones cruzadas solo se pueden especificar en la cláusula FROM. Las condiciones de combinación se combinan con las condiciones de búsqueda de WHERE y HAVING para controlar cuáles son las filas seleccionadas de las tablas base a las que se hace referencia en la cláusula FROM.
Especificar las condiciones de la combinación en la cláusula FROM ayuda a separarlas de cualquier otra condición de búsqueda que se pueda especificar en una cláusula WHERE; es el método recomendado para especificar combinaciones. La sintaxis simplificada de combinación de la cláusula FROM de ISO es:
FROM first_table < join_type > second_table [ ON ( join_condition ) ]
- El join_type especifica qué tipo de combinación se realiza: una combinación interna, externa o cruzada. Para obtener explicaciones de los distintos tipos de combinaciones, consulte cláusula FROM.
- join_condition define el predicado que se va a evaluar para cada par de filas combinadas.
El siguiente código es un ejemplo de la especificación de una combinación en la cláusula FROM:
FROM Purchasing.ProductVendor INNER JOIN Purchasing.Vendor
ON ( ProductVendor.BusinessEntityID = Vendor.BusinessEntityID )
El siguiente código es un ejemplo de una instrucción SELECT sencilla con esta combinación:
SELECT ProductID, Purchasing.Vendor.BusinessEntityID, Name
FROM Purchasing.ProductVendor INNER JOIN Purchasing.Vendor
ON (Purchasing.ProductVendor.BusinessEntityID = Purchasing.Vendor.BusinessEntityID)
WHERE StandardPrice > $10
AND Name LIKE N'F%';
GO
La instrucción SELECT devuelve la información de los productos y proveedores de cualquier combinación de partes suministrada por una empresa cuyo nombre empieza por la letra F y el precio del producto es superior a 10 USD.
Cuando en una consulta simple se hace referencia a varias tablas, ninguna de las referencias a las columnas debe ser ambigua. En el ejemplo anterior, las tablas ProductVendor y Vendor incluyen una columna denominada BusinessEntityID. Cualquier nombre de columna que esté duplicado en varias tablas a las que se hace referencia en la consulta debe ser calificado con el nombre de la tabla. Todas las referencias a las columnas Vendor del ejemplo están calificadas.
Cuando un nombre de columna no está duplicado en dos o más tablas usadas en la consulta, las referencias a ella no tienen que calificarse con el nombre de la tabla. Esto se muestra en el ejemplo anterior.
SELECT Esta cláusula a veces es difícil de entender porque no hay nada que indicar la tabla que proporcionó cada columna. La legibilidad de la consulta puede mejorarse si todas las columnas se califican con sus nombres de tabla. Incluso puede mejorarse más si se usan alias de tablas, especialmente cuando los propios nombres de las tablas se deben calificar con los nombres de las bases de datos y de los propietarios. A continuación se incluye el mismo ejemplo de código, con la salvedad de que se han asignado alias de tablas y las columnas se han calificado con dichos alias para facilitar su lectura:
SELECT pv.ProductID, v.BusinessEntityID, v.Name
FROM Purchasing.ProductVendor AS pv
INNER JOIN Purchasing.Vendor AS v
ON (pv.BusinessEntityID = v.BusinessEntityID)
WHERE StandardPrice > $10
AND Name LIKE N'F%';
Los ejemplos anteriores han especificado las condiciones de combinación en la cláusula FROM, el método recomendado. La consulta siguiente contiene la misma condición de combinación especificada en la cláusula WHERE:
SELECT pv.ProductID, v.BusinessEntityID, v.Name
FROM Purchasing.ProductVendor AS pv, Purchasing.Vendor AS v
WHERE pv.BusinessEntityID=v.BusinessEntityID
AND StandardPrice > $10
AND Name LIKE N'F%';
La lista SELECT de una combinación puede hacer referencia a todas las columnas de las tablas combinadas, o bien a cualquier subconjunto de las columnas. La SELECT lista no es necesaria para contener columnas de todas las tablas de la combinación. Por ejemplo, en una combinación de tres tablas, solo se puede usar una tabla para pasar de una de las dos tablas a la tercera y no es necesario que se haga referencia a ninguna columna de la tabla intermedia en la lista de selección. Esto también se denomina anti semicombinación.
Aunque las condiciones de combinación suelen tener comparaciones de igualdad (=), también se pueden especificar otros operadores relacionales o de comparación, así como otros predicados. Para obtener más información, vea Operadores de comparación y WHERE.
Cuando SQL Server procesa combinaciones, el optimizador de consultas elige el método más eficaz (entre varias posibilidades) para procesar la combinación. Esto incluye elegir el tipo más eficaz de combinación física, el orden en el que se combinarán las tablas e incluso el uso de tipos de operaciones de combinación lógica que no se pueden expresar directamente con Transact-SQL sintaxis, como combinaciones semi y combinaciones anti semi. La ejecución física de varias combinaciones puede usar muchas optimizaciones diferentes y, por tanto, no se puede predecir de forma confiable. Para obtener más información sobre las combinaciones semi y las combinaciones anti-semi, consulte Referencia del operador de plan de presentación lógico y físico.
Las columnas usadas en una condición de combinación no son necesarias para tener el mismo nombre ni tener el mismo tipo de datos. Sin embargo, si los tipos de datos no son idénticos, deben ser compatibles o ser tipos que SQL Server puede convertir implícitamente. Si los tipos de datos no se pueden convertir implícitamente, la condición de combinación debe convertir explícitamente el tipo de datos mediante la CAST función . Para obtener más información sobre las conversiones implícitas y explícitas, vea Conversión de tipos de datos (motor de base de datos).
La mayor parte de las consultas que usan una combinación se pueden volver a escribir con una subconsulta (una consulta anidada dentro de otra consulta). La mayor parte de las subconsultas se pueden volver a escribir como combinaciones. Para obtener más información sobre las subconsultas, vea Subconsultas (SQL Server).
Note
Las tablas no se pueden combinar directamente en columnas ntext, text o image. Sin embargo, las tablas no se pueden combinar directamente en columnas ntext, text o image utilizando SUBSTRING.
Por ejemplo, SELECT * FROM t1 JOIN t2 ON SUBSTRING(t1.textcolumn, 1, 20) = SUBSTRING(t2.textcolumn, 1, 20) realiza una combinación interna de dos tablas en los primeros 20 caracteres de cada columna de texto de las tablas t1 y t2.
Además, otra posibilidad para comparar columnas ntext o text de dos tablas consiste en comparar las longitudes de las columnas con una cláusula WHERE, por ejemplo: WHERE DATALENGTH(p1.pr_info) = DATALENGTH(p2.pr_info)
Descripción de las combinaciones de bucles anidados
Si la entrada de una combinación es pequeña (menor de 10 filas), y la entrada de otra combinación es bastante grande y está indizada en las columnas de combinación, una combinación de bucles anidados de índices es la operación de combinación más rápida, debido a que requieren menos E/S y menos comparaciones.
La combinación de bucles anidados, también denominada iteración anidada, utiliza una entrada de combinación como tabla de entrada externa (mostrada como la entrada superior en el plan de ejecución gráfico) y otra como tabla de entrada interna (inferior). El bucle externo procesa la tabla de entrada externa fila a fila. El bucle interno, que se ejecuta para cada fila externa, busca filas coincidentes en la tabla de entrada interna.
En el caso más sencillo, la búsqueda recorre una tabla o índice completo, lo cual recibe el nombre de combinación nativa de bucles anidados. Si la búsqueda aprovecha un índice, se denomina combinación de bucles anidados de índice. Si el índice se crea como parte del plan de consulta (y se destruye al finalizar la consulta), se denomina combinación de bucles anidados de índice temporal. El optimizador de consultas tiene en cuenta todas estas variantes.
Una combinación de bucles anidados resulta particularmente eficaz si la entrada externa es pequeña y la entrada interna está indizada previamente y es grande. En muchas transacciones pequeñas, como las que afectan solo a un pequeño conjunto de filas, las combinaciones de bucles anidados de índice son superiores a las combinaciones de mezcla y a las combinaciones hash. Sin embargo, en las consultas grandes, las combinaciones de bucles anidados a menudo no son la opción óptima.
Cuando el atributo OPTIMIZED de un operador de combinación de bucles anidados está establecido en True, significa que un bucle anidado optimizado (u ordenación por lotes) se usa para minimizar la E/S cuando la tabla interna es grande, independientemente de si está paralelizada o no. Es posible que la presencia de esta optimización en un plan determinado no sea demasiado obvia al analizar un plan de ejecución, debido a que la propia ordenación es una operación oculta. Pero si se mira el XML del plan correspondiente al atributo OPTIMIZED, indica que la combinación de bucles anidados podría intentar reordenar las filas de entrada para mejorar el rendimiento de E/S.
Combinaciones de mezcla
Si las dos entradas de combinación no son pequeñas, pero se ordenan en su columna de combinación (por ejemplo, si se obtuvieron mediante el examen de índices ordenados), una combinación de combinación es la operación de combinación más rápida. Si ambas entradas de combinación son grandes y tienen tamaños similares, una combinación de mezcla con una ordenación previa y una combinación hash ofrecen un rendimiento similar. Sin embargo, las operaciones de combinación hash a menudo son más rápidas si los tamaños de las dos entradas difieren significativamente entre sí.
La combinación de mezcla requiere que ambas entradas se ordenen en las columnas de combinación, que se definen mediante las cláusulas de igualdad (ON) del predicado de combinación. El optimizador de consultas normalmente recorre un índice, si existe uno en el conjunto de columnas apropiado, o bien coloca un operador de orden bajo la combinación de mezcla. En algunos casos, puede haber varias cláusulas de igualdad, pero las columnas de mezcla se toman solo de algunas de las cláusulas de igualdad disponibles.
Dado que cada entrada está ordenada, el operador Merge Join obtendrá una fila de cada entrada y las comparará. Por ejemplo, para operaciones de combinaciones internas, se devuelven las filas si son iguales. Si no son iguales, se descarta la fila de valor inferior y se obtiene otra fila de esa entrada. Este proceso se repite hasta que se han procesado todas las filas.
La operación de combinación de mezcla es una operación normal o de varios a varios. Una combinación de mezcla de varios a varios utiliza una tabla temporal para almacenar las filas. Si hay valores duplicados de cada entrada, una de las entradas tiene que rebobinar hasta el inicio de los duplicados a medida que se procesa cada duplicado de la otra entrada.
Si hay un predicado residual, todas las filas que cumplan el predicado de mezcla evaluarán el predicado residual y solo se devolverán las filas que lo cumplan.
La combinación de mezcla es muy rápida, pero puede ser una opción costosa si se requieren operaciones de ordenación. Sin embargo, si el volumen de datos es grande y los datos deseados se pueden obtener con una ordenación previa de los índices existentes de árbol b, la combinación de mezcla es, a menudo, el algoritmo de combinación disponible más rápido.
Combinaciones hash
Las combinaciones hash pueden procesar eficazmente entradas grandes, sin ordenar y no indizadas. Son útiles para obtener resultados intermedios en consultas complejas debido a que:
- Los resultados intermedios no se indexan (a menos que se guarden explícitamente en el disco y, a continuación, se indexen) y, a menudo, no se ordenan correctamente para la siguiente operación en el plan de consulta.
- Los optimizadores de consultas solo calculan los tamaños de resultados intermedios. Dado que las estimaciones pueden ser poco exactas en consultas complejas, los algoritmos utilizados para procesar los resultados intermedios no solo deben ser eficaces, sino que también deben rebajarse si un resultado intermedio es mayor de lo previsto.
La combinación hash permite reducir el uso de la desnormalización. La desnormalización se suele utilizar para conseguir un rendimiento mejor mediante la reducción de las operaciones de combinación, a pesar del peligro de redundancia, como las actualizaciones incoherentes. Las combinaciones hash reducen la necesidad de desnormalización. Las combinaciones hash permiten que las particiones verticales (que representan grupos de columnas de una sola tabla en archivos o índices independientes) se conviertan en una opción viable para el diseño físico de bases de datos.
La combinación hash tiene dos entradas: la entrada de compilación y la entrada de sondeo. El optimizador de consultas asigna estos roles de forma que la entrada más pequeña sea la entrada de generación.
Las combinaciones hash se utilizan para muchos tipos de operaciones de coincidencia de conjuntos: combinación interna; combinación externa completa, izquierda y derecha; semicombinación izquierda y derecha; intersección; unión y diferencia. Además, una variante de la combinación hash puede realizar la eliminación duplicada y la agrupación, como SUM(salary) GROUP BY department. Estas modificaciones solo utilizan una entrada para los roles de generación y sondeo.
En las secciones siguientes se describen los distintos tipos de combinaciones hash: combinación hash en memoria, combinación hash aplazada y combinación hash recursiva.
Combinación hash en memoria
La combinación hash primero recorre o calcula la entrada de generación completa y, a continuación, genera una tabla hash en memoria. Cada fila se inserta en un cubo hash según el valor hash calculado para la clave hash. Si la entrada de generación completa es menor que la memoria disponible, se pueden insertar todas las filas en la tabla hash. Después de la fase de generación se produce la fase de sondeo. La entrada de sondeo completa se recorre o se calcula fila a fila y, por cada fila de sondeo, se calcula el valor de la clave hash, se recorre el cubo hash correspondiente y se obtienen las coincidencias.
Combinación hash de gracia
Si la entrada de compilación no cabe en la memoria, una combinación hash continúa en varios pasos. Esto se denomina combinación hash aplazada. Cada paso contiene una fase de generación y una fase de sondeo. Inicialmente, se procesan todas las entradas de generación y sondeo, y se crean particiones (con una función hash sobre las claves hash) en varios archivos. La utilización de la función hash sobre las claves hash garantiza que todos los pares de registros combinados estén en la misma pareja de archivos. Por tanto, la tarea de combinar dos grandes entradas se ha reducido a varias instancias más pequeñas de las mismas tareas. A continuación se aplica la combinación hash a cada pareja de archivos de la partición.
Combinación hash recursiva
Si la entrada de generación es tan grande que las entradas para una mezcla externa estándar requerirían varios niveles de mezcla, son necesarios varios pasos de particiones y varios niveles de particiones. Si solo algunas de las particiones son grandes, los pasos de particiones adicionales solo se utilizan para estas particiones específicas. Para que todos los pasos de las particiones sean lo más rápidos posible, se utilizan grandes operaciones asincrónicas de E/S de forma que un solo subproceso pueda mantener ocupadas varias unidades de disco.
Note
Si la entrada de generación solo es un poco más grande que la memoria disponible, se combinan elementos de una combinación hash en memoria y una combinación hash aplazada en un solo paso, para producir una combinación hash híbrida.
No siempre es posible durante la optimización para determinar qué combinación hash se usa. Por tanto, SQL Server comienza utilizando una combinación hash en memoria y, gradualmente, pasa a una combinación hash aplazada y a una combinación hash recursiva, según el tamaño de la entrada de generación.
Si el optimizador de consultas prevé erróneamente cuál de las dos entradas será más pequeña y, por tanto, debería haber sido la entrada de generación, se invierten dinámicamente los roles de generación y sondeo. La combinación hash se asegura de usar el archivo de desbordamiento menor como entrada de generación. Esta técnica se denomina “inversión de roles”. La inversión de roles tiene lugar en una combinación hash después de al menos un volcado en el disco.
Note
La inversión de roles funciona independientemente de cualquier estructura o sugerencia de consulta. La inversión de roles no se muestra en el plan de consulta; cuando se produce, es transparente para el usuario.
Rescate hash
El término salida hash algunas veces se utiliza para describir combinaciones hash aplazadas o recursivas.
Note
Las combinaciones hash recursivas o las salidas hash reducen el rendimiento del servidor. Si ve muchos eventos Hash Warning en un seguimiento, actualice las estadísticas en las columnas que se están combinando.
Para obtener más información sobre el salida hash, vea Hash Warning [clase de eventos].
Combinaciones adaptables
Las combinaciones adaptables en modo por lotes permiten elegir un método Combinación hash o Combinación de bucles anidados que se aplace hasta después de que se haya examinado la primera entrada. El operador de combinaciones adaptables define un umbral que se usa para decidir cuándo cambiar a un plan de bucles anidados. Por lo tanto, un plan de consulta puede cambiar dinámicamente a una mejor estrategia de combinación durante la ejecución sin tener que sea necesaria una nueva compilación.
Tip
La cargas de trabajo con oscilaciones frecuentes entre análisis de entrada de combinación pequeños y grandes son las que más se benefician de esta característica.
La decisión de runtime se basa en estos pasos:
- Si el recuento de filas de la entrada de combinación de compilación es lo suficientemente pequeño como para que una combinación de bucles anidados sea una opción más óptima que una combinación hash, el plan cambia a un algoritmo de bucles anidados.
- Si la entrada de combinación de compilación supera un umbral de recuento de filas determinado, no se produce ningún cambio y el plan continúa con una combinación hash.
La siguiente consulta se usa para mostrar un ejemplo de combinación adaptable:
SELECT [fo].[Order Key], [si].[Lead Time Days], [fo].[Quantity]
FROM [Fact].[Order] AS [fo]
INNER JOIN [Dimension].[Stock Item] AS [si]
ON [fo].[Stock Item Key] = [si].[Stock Item Key]
WHERE [fo].[Quantity] = 360;
La consulta devuelve 336 filas. Al habilitar las estadísticas de consultas activas se ve el siguiente plan:

En el plan, tenga en cuenta lo siguiente:
- Una exploración de índice de almacén de columnas que se usa para proporcionar filas para la fase de compilación de combinación hash.
- El nuevo operador de combinación adaptable. Este operador define un umbral que se usa para decidir cuándo cambiar a un plan de bucle anidado. En este ejemplo, el umbral es 78 filas. Todo lo que tenga > = 78 filas usará una combinación hash. Si es inferior al umbral, se usará una combinación de bucles anidados.
- Dado que la consulta devuelve 336 filas, esto superó el umbral, por lo que la segunda rama representa la fase de sondeo de una operación de combinación hash estándar. Las estadísticas de consultas dinámicas muestran las filas que pasan por los operadores, en este caso "672 de 672".
- La última rama es la búsqueda en índice agrupado que usa la combinación de bucles anidados si no se ha superado el umbral. Vemos "0 de 336" filas mostradas (la rama no se usa).
Ahora se contrasta el plan con la misma consulta, pero cuando el valor Quantity solo tiene una fila en la tabla:
SELECT [fo].[Order Key], [si].[Lead Time Days], [fo].[Quantity]
FROM [Fact].[Order] AS [fo]
INNER JOIN [Dimension].[Stock Item] AS [si]
ON [fo].[Stock Item Key] = [si].[Stock Item Key]
WHERE [fo].[Quantity] = 361;
La consulta devuelve una fila. Al habilitar las estadísticas de consultas activas se ve el siguiente plan:
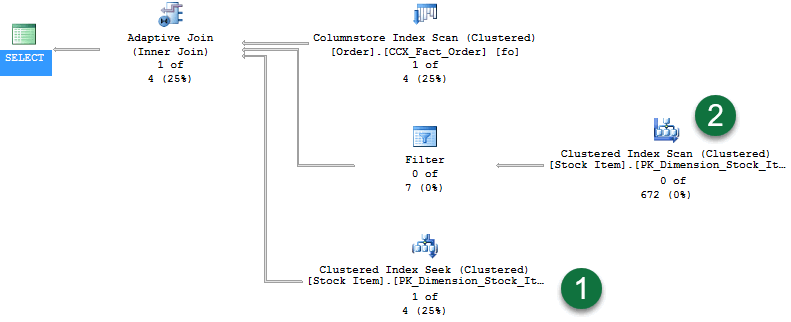
En el plan, tenga en cuenta lo siguiente:
- Con una fila devuelta, ahora pasan filas por la búsqueda en índice clúster.
- Y como la fase de compilación de combinación hash no continúa, no hay filas que fluyan a través de la segunda rama.
Comentarios sobre las combinaciones adaptables
Las combinaciones adaptables tienen unos requisitos de memoria superiores a un plan equivalente de combinación de bucle anidado de índice. La memoria adicional se solicita como si los bucles anidados fuesen una combinación hash. También hay sobrecarga para la fase de compilación como una operación de detención y uso frente a una combinación equivalente de streaming de bucles anidados. Ese costo adicional va acompañado de flexibilidad en escenarios donde los recuentos de filas pueden fluctuar en la entrada de compilación.
Las combinaciones adaptables en modo por lotes funcionan para la ejecución inicial de una instrucción y, una vez compiladas, las ejecuciones consecutivas seguirán siendo adaptables según el umbral de combinación adaptable compilado y las filas de runtime que fluyen a través de la fase de compilación de la entrada externa.
Si una combinación adaptable cambia a una operación de bucles anidados, usa las filas ya leídas por la compilación de combinación hash. El operador no vuelve a leer las filas de la referencia externa.
Seguimiento de la actividad de combinación adaptable
El operador de combinación adaptable tiene los siguientes atributos de operador de plan:
| Atributo Plan | Description |
|---|---|
| AdaptiveThresholdRows | Muestra el uso de umbral para cambiar de una combinación hash a una combinación de bucle anidado. |
| EstimatedJoinType | El tipo de combinación probable. |
| ActualJoinType | En un plan real, se muestra qué algoritmo de combinación se ha elegido finalmente según el umbral. |
El plan estimado muestra la forma del plan de combinación adaptable, junto con un umbral de combinación adaptable definido y un tipo de combinación estimado.
Tip
El Almacén de consultas captura y puede aplicar un plan de combinación adaptable de modo de proceso por lotes.
Instrucciones aptas de combinación adaptable
Algunas condiciones convierten a una combinación lógica en apta como combinación adaptable de modo de proceso por lotes:
- El nivel de compatibilidad de la base de datos es 140 o superior.
- La consulta es una instrucción
SELECT(las instrucciones de modificación de datos no son aptas actualmente). - La combinación puede ser ejecutada tanto por una combinación de bucles anidados indexada como por un algoritmo físico de combinación hash.
- La combinación hash usa el modo por lote, habilitado a través de la presencia de un índice de almacén de columnas en la consulta general, una tabla indizada de almacén de columnas a la que hace referencia directamente la combinación o mediante el uso del modo por lote en el almacén de filas.
- Las soluciones alternativas generadas de la combinación de bucles anidados y la combinación hash deben tener el mismo primer elemento secundario (referencia externa).
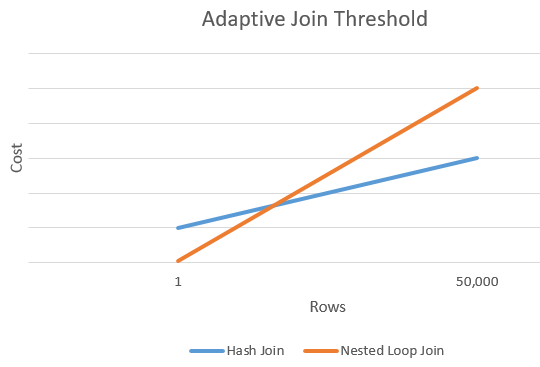
Filas de umbral adaptable
El gráfico siguiente muestra una intersección de ejemplo entre el costo de una combinación hash y el de una alternativa de combinación de bucles anidados. En este punto de intersección, se determina el umbral que a su vez determina el algoritmo real usado para la operación de combinación.
Deshabilitación de combinaciones adaptables sin cambiar el nivel de compatibilidad
Las combinaciones adaptables se pueden deshabilitar en el ámbito de la base de datos o de la instrucción mientras se mantiene el nivel 140 o superior de compatibilidad de la base de datos.
Para deshabilitar las combinaciones adaptables para todas las ejecuciones de consultas que se originan en la base de datos, ejecute lo siguiente en el contexto de la base de datos aplicable:
-- SQL Server 2017
ALTER DATABASE SCOPED CONFIGURATION SET DISABLE_BATCH_MODE_ADAPTIVE_JOINS = ON;
-- Azure SQL Database, SQL Server 2019 and later versions
ALTER DATABASE SCOPED CONFIGURATION SET BATCH_MODE_ADAPTIVE_JOINS = OFF;
Cuando está habilitada, esta configuración aparece como habilitada en sys.database_scoped_configurations.
Para volver a habilitar las combinaciones adaptables para todas las ejecuciones de consultas que se originan en la base de datos, ejecute lo siguiente en el contexto de la base de datos aplicable:
-- SQL Server 2017
ALTER DATABASE SCOPED CONFIGURATION SET DISABLE_BATCH_MODE_ADAPTIVE_JOINS = OFF;
-- Azure SQL Database, SQL Server 2019 and later versions
ALTER DATABASE SCOPED CONFIGURATION SET BATCH_MODE_ADAPTIVE_JOINS = ON;
Las combinaciones adaptables también se pueden deshabilitar para una consulta específica si se designa DISABLE_BATCH_MODE_ADAPTIVE_JOINS como una sugerencia de consulta USE HINT. Por ejemplo:
SELECT s.CustomerID,
s.CustomerName,
sc.CustomerCategoryName
FROM Sales.Customers AS s
LEFT OUTER JOIN Sales.CustomerCategories AS sc
ON s.CustomerCategoryID = sc.CustomerCategoryID
OPTION (USE HINT('DISABLE_BATCH_MODE_ADAPTIVE_JOINS'));
Note
Una USE HINT sugerencia de consulta tiene prioridad sobre una configuración con ámbito de base de datos o una configuración de marca de seguimiento.
Valores y combinaciones NULL
Cuando hay valores NULL en las columnas de las tablas que se van a combinar, los valores NULL no coinciden entre sí. La presencia de valores NULL en una columna de una de las tablas que se está combinando solo se puede indicar si se usa una combinación externa (a menos que la cláusula WHERE excluya los valores NULL).
Estas son dos tablas que cada una tiene NULL en la columna que participará en la combinación:
table1 table2
a b c d
------- ------ ------- ------
1 one NULL two
NULL three 4 four
4 join4
Una combinación que compara los valores de la columna a con la columna c no obtiene una coincidencia en las columnas que tienen valores de NULL:
SELECT *
FROM table1 t1 JOIN table2 t2
ON t1.a = t2.c
ORDER BY t1.a;
GO
Solo se devuelve una fila con el valor 4 en columnas a y c:
a b c d
----------- ------ ----------- ------
4 join4 4 four
(1 row(s) affected)
Los valores NULL devueltos de una tabla base también son difíciles de distinguir de los valores NULL devueltos en una combinación externa. Por ejemplo, la siguiente instrucción SELECT realiza una combinación externa izquierda en las dos tablas:
SELECT *
FROM table1 t1 LEFT OUTER JOIN table2 t2
ON t1.a = t2.c
ORDER BY t1.a;
GO
Este es el conjunto de resultados.
a b c d
----------- ------ ----------- ------
NULL three NULL NULL
1 one NULL NULL
4 join4 4 four
(3 row(s) affected)
Los resultados no facilitan la distinción de un NULL elemento en los datos de un NULL que representa un error al unirse. Cuando NULL los valores están presentes en los datos que se combinan, normalmente es preferible omitirlos de los resultados mediante una combinación normal.