Habilitación de la resistencia de aplicaciones con una base de datos de Azure SQL
Tanto la replicación geográfica como los grupos de conmutación por error automática son mecanismos que se usan en una base de datos de Azure SQL para mejorar la disponibilidad y la recuperación ante desastres, pero tienen algunas diferencias clave.
Descripción de la replicación geográfica activa
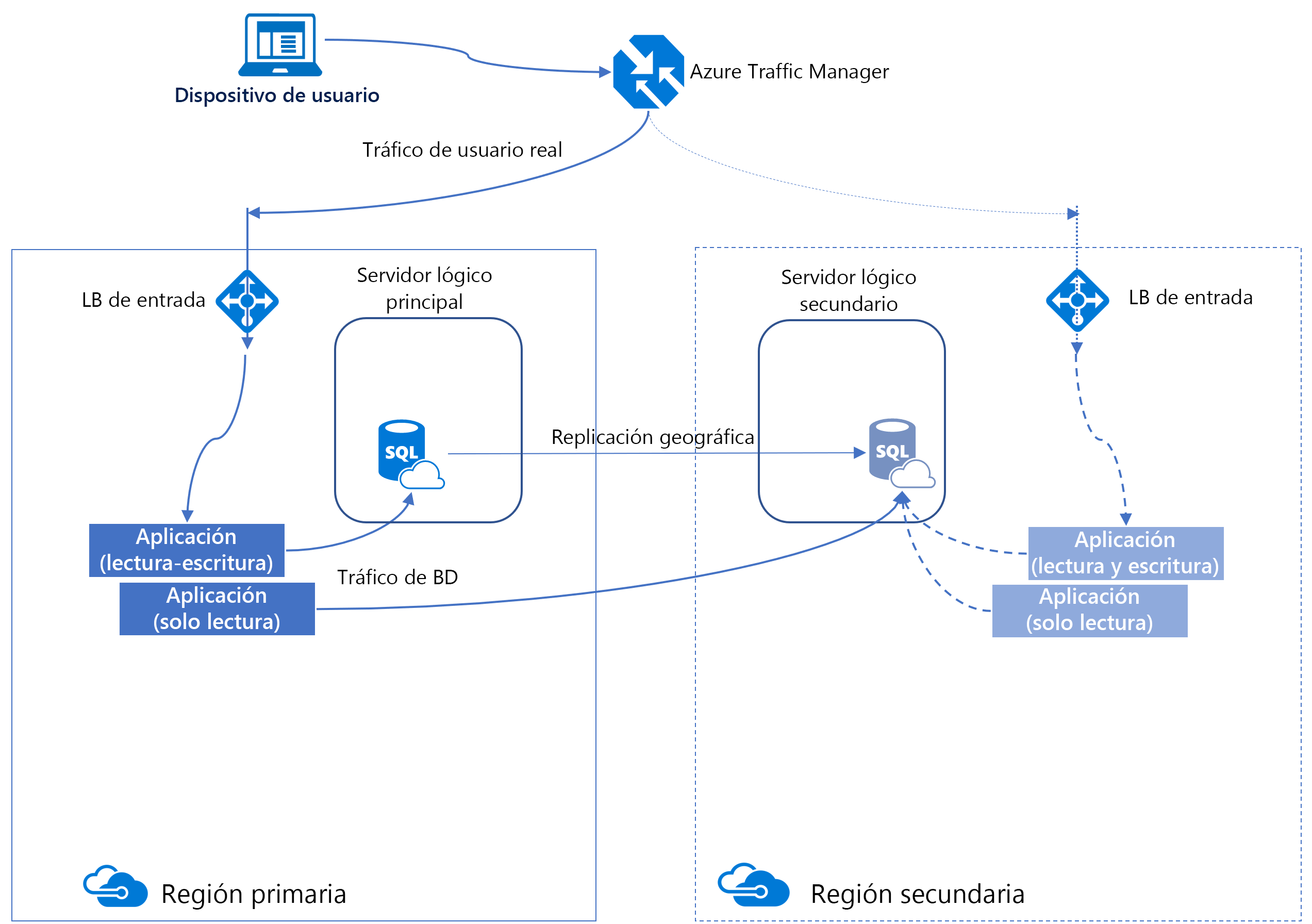
Un método para aumentar la disponibilidad de una base de datos de Azure SQL es usar la replicación geográfica activa. La replicación geográfica activa está diseñada como una solución de continuidad empresarial que permite crear bases de datos secundarias legibles de bases de datos individuales en un servidor de la misma región o diferente. Admite hasta cuatro réplicas secundarias y se configura por base de datos.
En segundo plano, Azure usa grupos de disponibilidad para proporcionar esta funcionalidad. Con la replicación geográfica activa, los clientes pueden conmutar por error las bases de datos principales mediante programación o de forma manual a las regiones secundarias durante el desastre principal.
Para evitar la sobrecarga de replicación de una carga de trabajo de escritura grande que pueda afectar al rendimiento de la replicación, se recomienda configurar la base de datos geográfica secundaria con el mismo nivel de servicio y el mismo tamaño de proceso que la principal.
Puede configurar de forma manual la replicación geográfica para una base de datos de Azure SQL accediendo a la página de base de datos y seleccionando Réplicas en la sección Administración de datos.

Una vez creada la réplica secundaria, puede iniciar manualmente una conmutación por error. Esto cambia los roles, haciendo que la secundaria sea la nueva principal y, la principal anterior, la nueva secundaria.

La replicación geográfica es asincrónica, lo que significa que puede haber algún retraso de datos entre la base de datos principal y la secundaria. Además, la cadena de conexión de la aplicación debe actualizarse después de una conmutación por error.
Configuración de la replicación geográfica entre suscripciones
En algunos escenarios es posible que tenga que configurar una réplica secundaria en una suscripción distinta a la de la base de datos principal. Aquí es donde entra en juego la replicación geográfica entre suscripciones. Esta característica permite configurar una réplica secundaria en otra suscripción, lo que proporciona mayor flexibilidad y opciones de recuperación ante desastres mejoradas. Mediante la replicación geográfica entre suscripciones, puede asegurarse de que los datos están protegidos y son accesibles incluso si una suscripción encuentra problemas. Esta configuración es útil para las organizaciones con varias suscripciones o aquellas que buscan implementar un plan de continuidad empresarial sólido.
Para obtener más información sobre los pasos necesarios para configurar una replicación geográfica entre suscripciones, consulte Replicación geográfica entre suscripciones.
Habilitación de grupos de conmutación por error automática
Un grupo de conmutación por error automática es una característica de disponibilidad que se puede usar con Azure SQL Database y Azure SQL Managed Instance. Los grupos de conmutación por error automática le permiten administrar cómo se replican la bases de datos en otra región y le permiten administrar cómo se debe producir la conmutación por error. El nombre asignado al grupo de conmutación por error automática debe ser único en el dominio *.database.windows.net.
Los grupos de conmutación por error automática ofrecen funcionalidad similar al grupo de disponibilidad a través de un agente de escucha, lo que permite las actividades de lectura y escritura y de solo lectura. Esta funcionalidad difiere ligeramente de la replicación geográfica activa. Hay dos tipos de agentes de escucha: uno para el tráfico de lectura y escritura y otro para el tráfico de solo lectura. Durante una conmutación por error, las actualizaciones de DNS permiten a los clientes conectarse al nombre del agente de escucha sin necesidad de información adicional. El servidor de bases de datos con las copias de lectura y escritura es el principal, mientras que el servidor que recibe transacciones del servidor principal es el secundario.
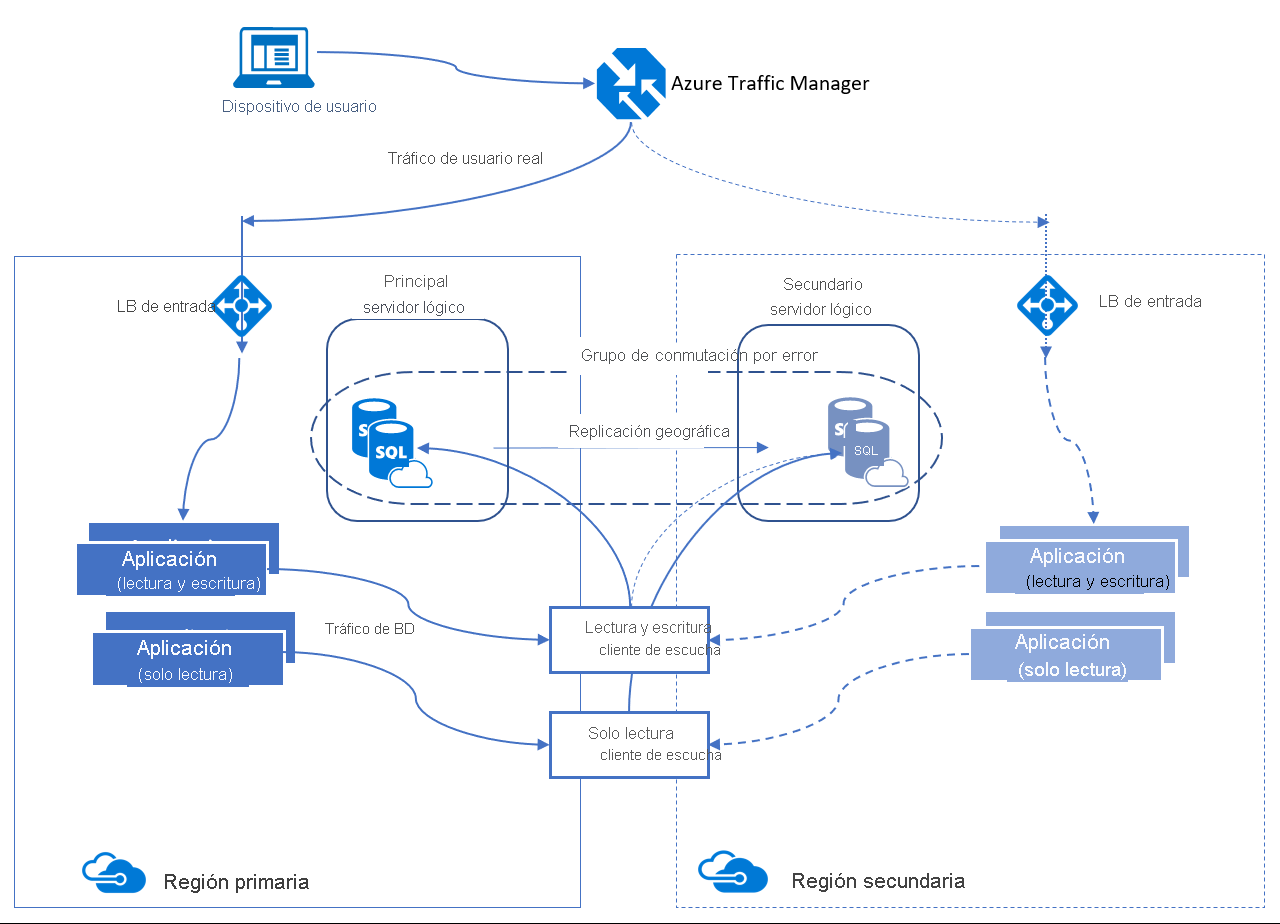
Los grupos de conmutación por error automática tienen dos directivas distintas que pueden configurarse.
- Administrada por el cliente (recomendado): los clientes pueden iniciar de forma manual una conmutación por error cuando detectan una interrupción inesperada que afecta a una o varias bases de datos del grupo de conmutación por error. Esta conmutación por error manual se puede realizar mediante herramientas de línea de comandos como PowerShell, la CLI de Azure o la API de REST.
- Administrada por Microsoft: Microsoft las inicia automáticamente durante una interrupción generalizada que afecta a una región primaria. Esta conmutación automática por error se aplica a todos los grupos de conmutación por error afectados con su directiva de conmutación por error establecida en administrada por Microsoft.
Las conmutaciones por error no planeadas pueden provocar la pérdida de datos si se fuerzan y si el servidor secundario no está totalmente sincronizado con el principal. La configuración de GracePeriodWithDataLossHours controla cuánto tiempo espera Azure antes de realizar la conmutación por error. El valor predeterminado es de una hora. Si tiene un objetivo de punto de recuperación ajustado y no puede permitirse una pérdida de datos importante, establezca el valor más alto. Aunque Azure espera más tiempo antes de realizar la conmutación por error, este enfoque puede hacer que se pierdan menos datos, ya que la base de datos secundaria tiene más tiempo para sincronizarse completamente con la principal.
Además, un grupo de conmutación por error automática puede incluir una o varias bases de datos, con el mismo tamaño y edición en los servidores primarios y secundarios. La base de datos del servidor secundario se crea automáticamente a través de un proceso denominado propagación, que puede tardar algún tiempo en función del tamaño de la base de datos. Es importante planear en consecuencia y tener en cuenta factores como la velocidad de red.
Cómo elegir
La replicación geográfica es adecuada para escenarios en los que se necesitan varias réplicas legibles y la conmutación por error manual es aceptable, mientras que los grupos de conmutación por error automática son ideales para escenarios que requieren conmutación por error automática y replicación sincrónica para un grupo de bases de datos.
En la siguiente tabla se comparan las características de la replicación geográfica y los grupos de conmutación por error automática, junto con otros detalles pertinentes.
| Característica | Replicación geográfica | Grupos de conmutación por error automática |
|---|---|---|
| Número de réplicas | Admite hasta cuatro réplicas secundarias. | Solo admite una réplica secundaria |
| Nivel de configuración | Configurada por base de datos. | Configurada para un grupo de bases de datos |
| Tipo de replicación | Asincrónica, lo que significa que puede haber algún retraso de datos entre las bases de datos principal y secundaria | Sincrónica, lo que garantiza que la base de datos secundaria esté siempre sincronizada con la principal. |
| Conmutación por error | Requiere conmutación por error manual. La cadena de conexión de la aplicación debe actualizarse después de una conmutación por error | Admite la conmutación por error automática y manual, sin necesidad de cambiar las cadenas de conexión después de una conmutación por error |
| Legibilidad | Proporciona bases de datos secundarias legibles. | Proporciona bases de datos secundarias legibles y sirve como espera activa para la conmutación por error |
| Caso de uso | Adecuada para escenarios que necesitan varias réplicas legibles y conmutación por error manual | Ideal para escenarios que requieren conmutación automática por error y replicación sincrónica para un grupo de bases de datos |