Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo se proporcionan instrucciones para solucionar problemas en los que una consulta de Microsoft SQL Server tarda un tiempo excesivo en finalizar (horas o días).
Síntomas
Este artículo se centra en las consultas que parecen ejecutarse o compilar sin fin. Es decir, su uso de CPU sigue aumentando. Este artículo no se aplica a las consultas bloqueadas ni a la espera de un recurso que nunca se ha publicado. En esos casos, el uso de la CPU permanece constante o cambia ligeramente.
Importante
Si se deja una consulta para continuar ejecutándose, es posible que termine. Este proceso puede tardar unos segundos o varios días. En algunas situaciones, la consulta podría ser realmente infinita, por ejemplo, cuando un bucle WHILE no sale. El término "sin fin" se usa aquí para describir la percepción de una consulta que no finaliza.
Causa
Entre las causas comunes de las consultas de larga duración (sin fin) se incluyen las siguientes:
-
Combinaciones de bucle anidado (NL) en tablas muy grandes: Debido a la naturaleza de las combinaciones NL, una consulta que combina tablas que tienen muchas filas puede ejecutarse durante mucho tiempo. Para obtener más información, consulte Combinaciones.
- Un ejemplo de una combinación NL es el uso de
TOP,FASToEXISTS. Incluso si una combinación hash o combinación de mezcla puede ser más rápida, el optimizador no puede usar ninguno de los operadores debido al objetivo de fila. - Otro ejemplo de una combinación NL es el uso de un predicado de combinación de desigualdad en una consulta. Por ejemplo:
SELECT .. FROM tab1 AS a JOIN tab 2 AS b ON a.id > b.id. El optimizador tampoco puede usar combinaciones Merge o Hash aquí.
- Un ejemplo de una combinación NL es el uso de
- Estadísticas obsoletas: Las consultas que eligen un plan en función de las estadísticas obsoletas pueden ser poco óptimas y tardar mucho tiempo en ejecutarse.
- Bucles infinitos: Las consultas T-SQL que usan bucles WHILE podrían escribirse incorrectamente. El código resultante nunca deja el bucle y se ejecuta sin fin. Estas consultas son verdaderamente interminables. Se ejecutan hasta que se matan manualmente.
- Consultas complejas que tienen muchas combinaciones y tablas grandes: Las consultas que implican muchas tablas combinadas normalmente tienen planes de consulta complejos que pueden tardar mucho tiempo en ejecutarse. Este escenario es común en las consultas analíticas que no filtran las filas y que implican un gran número de tablas.
- Faltan índices: Las consultas se pueden ejecutar significativamente más rápido si se usan índices adecuados en tablas. Los índices permiten seleccionar un subconjunto de los datos para proporcionar acceso más rápido.
Solución
Paso 1: Detección de consultas sin fin
Busque una consulta sin fin que se ejecute en el sistema. Debe determinar si una consulta tiene un tiempo de ejecución largo, un tiempo de espera largo (bloqueado en un cuello de botella) o un tiempo de compilación largo.
1.1 Ejecución de un diagnóstico
Ejecute la siguiente consulta de diagnóstico en la instancia de SQL Server donde está activa la consulta sin fin:
DECLARE @cntr INT = 0
WHILE (@cntr < 3)
BEGIN
SELECT TOP 10 s.session_id,
r.status,
CAST(r.cpu_time / (1000 * 60.0) AS DECIMAL(10,2)) AS cpu_time_minutes,
CAST(r.total_elapsed_time / (1000 * 60.0) AS DECIMAL(10,2)) AS elapsed_minutes,
r.logical_reads,
r.wait_time,
r.wait_type,
r.wait_resource,
r.reads,
r.writes,
SUBSTRING(st.TEXT, (r.statement_start_offset / 2) + 1,
((CASE r.statement_end_offset
WHEN -1 THEN DATALENGTH(st.TEXT)
ELSE r.statement_end_offset
END - r.statement_start_offset) / 2) + 1) AS statement_text,
COALESCE(QUOTENAME(DB_NAME(st.dbid)) + N'.' + QUOTENAME(OBJECT_SCHEMA_NAME(st.objectid, st.dbid))
+ N'.' + QUOTENAME(OBJECT_NAME(st.objectid, st.dbid)), '') AS command_text,
r.command,
s.login_name,
s.host_name,
s.program_name,
s.last_request_end_time,
s.login_time,
r.open_transaction_count,
atrn.name as transaction_name,
atrn.transaction_id,
atrn.transaction_state
FROM sys.dm_exec_sessions AS s
JOIN sys.dm_exec_requests AS r ON r.session_id = s.session_id
CROSS APPLY sys.Dm_exec_sql_text(r.sql_handle) AS st
LEFT JOIN (sys.dm_tran_session_transactions AS stran
JOIN sys.dm_tran_active_transactions AS atrn
ON stran.transaction_id = atrn.transaction_id)
ON stran.session_id =s.session_id
WHERE r.session_id != @@SPID
ORDER BY r.cpu_time DESC
SET @cntr = @cntr + 1
WAITFOR DELAY '00:00:05'
END
1.2 Examen de la salida
Hay varios escenarios que pueden hacer que una consulta se ejecute durante mucho tiempo: ejecución larga, larga espera y compilación larga. Para obtener más información sobre por qué una consulta puede ejecutarse lentamente, vea Running vs Waiting: why are slow queries? (Ejecución frente a espera: ¿por qué las consultas son lentas?
Tiempo de ejecución largo
Los pasos de solución de problemas de este artículo son aplicables cuando recibe una salida similar a la siguiente, donde el tiempo de CPU aumenta proporcionalmente al tiempo transcurrido sin tiempos de espera significativos.
| session_id | status | cpu_time_minutes | elapsed_time_minutes | logical_reads | wait_time_minutes | wait_type |
|---|---|---|---|---|---|---|
| 56 | en ejecución | 64.40 | 23.50 | 0 | 0.00 | NULL |
La consulta se está ejecutando continuamente si tiene:
- Un aumento del tiempo de CPU
- Un estado de
runningorunnable - Tiempo de espera mínimo o cero
- Sin wait_type
En esta situación, la consulta está leyendo filas, combinación, procesamiento de resultados, cálculo o formato. Estas actividades son todas las acciones enlazadas a cpu.
Nota:
Los cambios en logical_reads no son relevantes en este caso porque algunas solicitudes T-SQL enlazadas a la CPU, como realizar cálculos o un WHILE bucle, podrían no realizar ninguna lectura lógica en absoluto.
Si la consulta lenta cumple estos criterios, céntrese en reducir su tiempo de ejecución. Normalmente, reducir el tiempo de ejecución implica reducir el número de filas que la consulta tiene que procesar durante toda su vida aplicando índices, reescribiendo la consulta o actualizando estadísticas. Para obtener más información, consulte la sección Resolución .
Tiempo de espera largo
Este artículo no es aplicable a escenarios de espera prolongada. En un escenario de espera, puede recibir una salida similar al ejemplo siguiente en el que el uso de la CPU no cambia o cambia ligeramente porque la sesión está esperando un recurso:
| session_id | status | cpu_time_minutes | elapsed_time_minutes | logical_reads | wait_time_minutes | wait_type |
|---|---|---|---|---|---|---|
| 56 | suspended | 0,03 | 4.20 | 50 | 4.10 | LCK_M_U |
El tipo de espera indica que la sesión está esperando un recurso. Un tiempo transcurrido largo y un tiempo de espera largo indican que la sesión está esperando la mayor parte de su vida para este recurso. El tiempo de CPU corto de Тhe indica que poco tiempo se ha dedicado realmente a procesar la consulta.
Para solucionar problemas de consultas que son largas debido a esperas, consulte Solución de problemas de consultas de ejecución lenta en SQL Server.
Tiempo de compilación largo
En raras ocasiones, es posible que observe que el uso de la CPU aumenta continuamente con el tiempo, pero no está controlado por la ejecución de la consulta. En su lugar, una compilación excesivamente larga (el análisis y la compilación de una consulta) podría ser la causa. En estos casos, compruebe la transaction_name columna de salida para ver un valor de sqlsource_transform. Este nombre de transacción indica una compilación.
Paso 2: Recopilar registros de diagnóstico manualmente
Después de determinar que existe una consulta sin fin en el sistema, puede recopilar los datos del plan de la consulta para solucionar problemas. Para recopilar los datos, use uno de los métodos siguientes, en función de la versión de SQL Server.
- SQL Server 2008: SQL Server 2014 (anterior a SP2)
- SQL Server 2014 (posterior a SP2) y SQL Server 2016 (anterior a SP1)
- SQL Server 2016 (posterior a SP1) y SQL Server 2017
- SQL Server 2019 y versiones posteriores
Para recopilar datos de diagnóstico mediante SQL Server Management Studio (SSMS), siga estos pasos:
Capture el XML del plan de ejecución de consultas estimado.
Revise el plan de consulta para saber si los datos muestran indicaciones obvias de lo que está causando la lentitud. Entre los ejemplos de indicaciones típicas se incluyen:
- Exámenes de tabla o índice (examine las filas estimadas)
- Bucles anidados controlados por un conjunto de datos de tabla externa enorme
- Bucles anidados que tienen una rama grande en el lado interno del bucle
- Colas de tablas
- Funciones de la
SELECTlista que tardan mucho tiempo en procesar cada fila
Si la consulta se ejecuta más rápido en cualquier momento, puede capturar las ejecuciones "rápidas" (plan de ejecución XML real) para comparar los resultados.
Uso de LOGScout de SQL para capturar consultas sin fin
Puede usar SQL LogScout para capturar registros mientras se ejecuta una consulta sin fin. Use el escenario de consulta nunca final con el comando siguiente:
.\SQL_LogScout.ps1 -Scenario "NeverEndingQuery" -ServerName "SQLInstance"
Nota:
Este proceso de captura de registros requiere que la consulta larga consuma al menos 60 segundos de tiempo de CPU.
LogScout de SQL captura al menos tres planes de consulta para cada consulta de consumo elevado de CPU. Puede encontrar nombres de archivo similares a servername_datetime_NeverEnding_statistics_QueryPlansXml_Startup_sessionId_#.sqlplan. Puede usar estos archivos en el paso siguiente al revisar los planes para identificar el motivo de la ejecución prolongada de consultas.
Paso 3: Revisar los planes recopilados
En esta sección se describe cómo revisar los datos recopilados. Usa los varios planes de consulta XML (mediante la extensión .sqlplan) que se recopilan en Microsoft SQL Server 2016 SP1 y versiones posteriores.
Para comparar los planes de ejecución , siga estos pasos:
Abra un archivo de plan de ejecución de consultas guardado anteriormente (
.sqlplan).Haga clic con el botón derecho en un área en blanco del plan de ejecución y seleccione Comparar plan de presentación.
Elija el segundo archivo de plan de consulta que desea comparar.
Busque flechas gruesas que indican un gran número de filas que fluyen entre operadores. A continuación, seleccione el operador antes o después de la flecha y compare el número de filas reales entre los dos planes.
Compare los planes segundo y tercero para saber si el mayor flujo de filas se produce en los mismos operadores.
Por ejemplo:
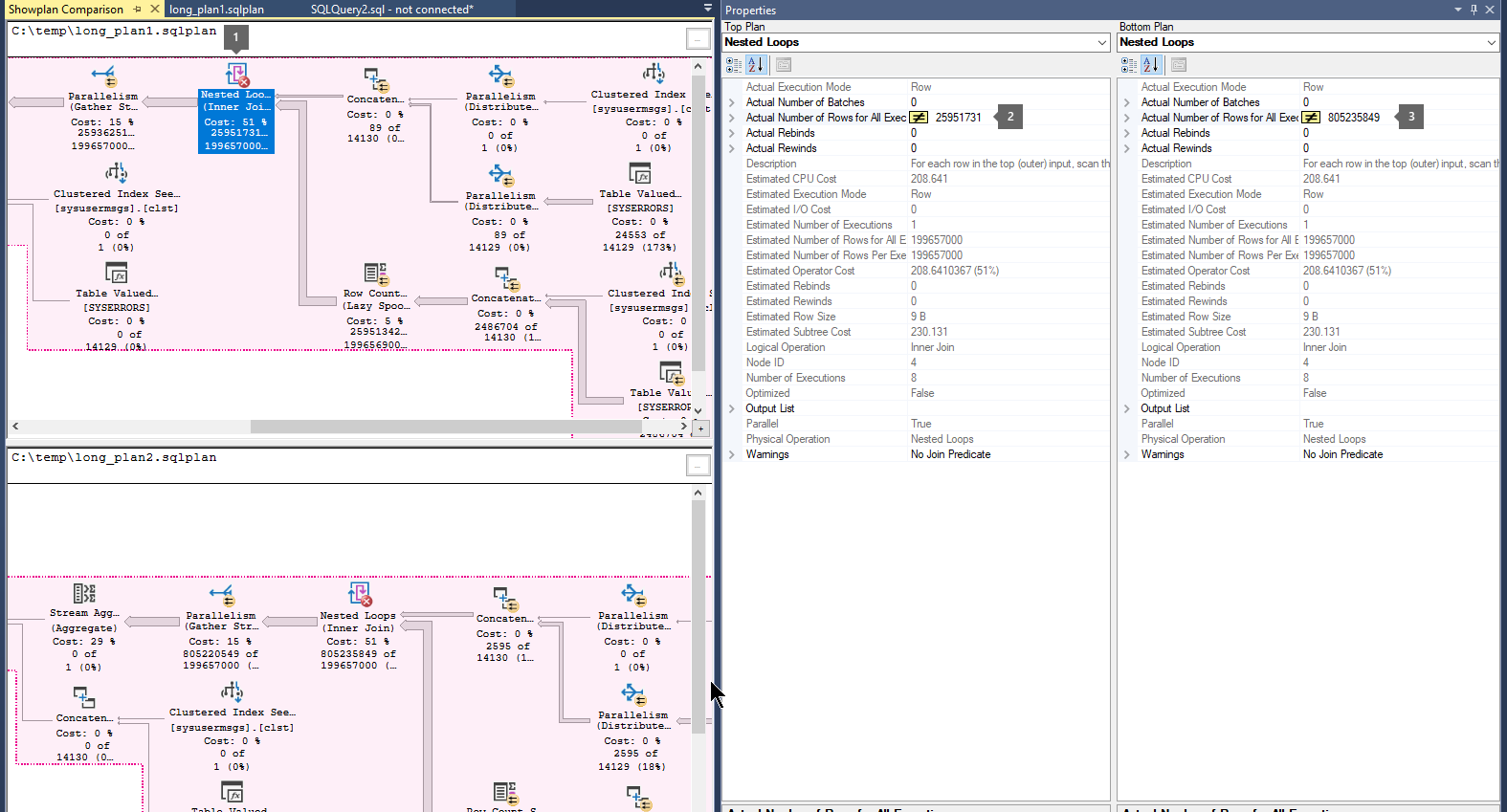

Paso 4: Resolución
Asegúrese de que las estadísticas se actualizan para las tablas que se usan en la consulta.
Busque las recomendaciones de índice que faltan en el plan de consulta y aplique las que encuentre.
Simplifique la consulta:
- Use predicados más selectivos
WHEREpara reducir los datos procesados por adelantado. - Divida.
- Seleccione algunas partes en tablas temporales y acompáñelas más adelante.
- Quite
TOP,EXISTSyFAST(T-SQL) en las consultas que se ejecutan durante mucho tiempo debido a un objetivo de fila del optimizador.- Como alternativa, use la
DISABLE_OPTIMIZER_ROWGOALsugerencia . Para obtener más información, consulte Objetivos de fila no autorizados.
- Como alternativa, use la
- Evite usar expresiones de tabla comunes (CTE) en tales casos porque combinan instrucciones en una sola consulta grande.
- Use predicados más selectivos
Pruebe a usar sugerencias de consulta para generar un plan mejor:
-
HASH JOINoMERGE JOINsugerencia - Sugerencia
FORCE ORDER - Sugerencia
FORCESEEK RECOMPILE- USE
PLAN N'<xml_plan>'(si tiene un plan de consulta rápido que puede forzar)
-
Use Almacén de consultas (QDS) para forzar un buen plan conocido si existe dicho plan y si la versión de SQL Server admite Almacén de consultas.