Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Se aplica a: SQL Server
En este artículo se proporcionan pasos de solución de problemas para un problema de rendimiento en el que una consulta se ejecuta más lentamente en un servidor que en otro servidor.
Síntomas
Supongamos que hay dos servidores con SQL Server instalado. Una de las instancias de SQL Server contiene una copia de una base de datos en la otra instancia de SQL Server. Al ejecutar una consulta en las bases de datos de ambos servidores, la consulta se ejecuta más lentamente en un servidor que el otro.
Los pasos siguientes pueden ayudar a solucionar este problema.
Paso 1: Determinar si es un problema común con varias consultas
Use uno de los dos métodos siguientes para comparar el rendimiento de dos o más consultas en los dos servidores:
Pruebe manualmente las consultas en ambos servidores:
- Elija varias consultas para realizar pruebas con prioridad en las consultas que son:
- Significativamente más rápido en un servidor que en el otro.
- Importante para el usuario o la aplicación.
- Ejecutado con frecuencia o diseñado para reproducir el problema a petición.
- Lo suficientemente largo como para capturar datos en él (por ejemplo, en lugar de una consulta de 5 milisegundos, elija una consulta de 10 segundos).
- Ejecute las consultas en los dos servidores.
- Compare el tiempo transcurrido (duración) en dos servidores para cada consulta.
- Elija varias consultas para realizar pruebas con prioridad en las consultas que son:
Analice los datos de rendimiento con SQL Nexus.
- Recopile datos de PSSDiag/SQLdiag o SQL LogScout para las consultas de los dos servidores.
- Importe los archivos de datos recopilados con SQL Nexus y compare las consultas de los dos servidores. Para obtener más información, consulte Comparación de rendimiento entre dos colecciones de registros (lentas y rápidas, por ejemplo).
Escenario 1: solo una sola consulta realiza de forma diferente en los dos servidores
Si solo una consulta se realiza de forma diferente, es más probable que el problema sea más específico de la consulta individual en lugar del entorno. En este caso, vaya al Paso 2: Recopilar datos y determinar el tipo de problema de rendimiento.
Escenario 2: Varias consultas realizan de forma diferente en los dos servidores
Si varias consultas se ejecutan más lentamente en un servidor que el otro, la causa más probable es las diferencias en el servidor o el entorno de datos. Vaya a Diagnosticar diferencias de entorno y vea si la comparación entre los dos servidores es válida.
Paso 2: Recopilar datos y determinar el tipo de problema de rendimiento
Recopilar tiempo transcurrido, tiempo de CPU y lecturas lógicas
Para recopilar el tiempo transcurrido y el tiempo de CPU de la consulta en ambos servidores, use uno de los métodos siguientes que mejor se adapte a su situación:
Para ejecutar instrucciones actualmente, compruebe las columnas total_elapsed_time y cpu_time en sys.dm_exec_requests. Ejecute la consulta siguiente para obtener los datos:
SELECT req.session_id , req.total_elapsed_time AS duration_ms , req.cpu_time AS cpu_time_ms , req.total_elapsed_time - req.cpu_time AS wait_time , req.logical_reads , SUBSTRING (REPLACE (REPLACE (SUBSTRING (ST.text, (req.statement_start_offset/2) + 1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text) ELSE req.statement_end_offset END - req.statement_start_offset)/2) + 1) , CHAR(10), ' '), CHAR(13), ' '), 1, 512) AS statement_text FROM sys.dm_exec_requests AS req CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) AS ST ORDER BY total_elapsed_time DESC;Para las ejecuciones anteriores de la consulta, compruebe las columnas last_elapsed_time y last_worker_time en sys.dm_exec_query_stats. Ejecute la consulta siguiente para obtener los datos:
SELECT t.text, (qs.total_elapsed_time/1000) / qs.execution_count AS avg_elapsed_time, (qs.total_worker_time/1000) / qs.execution_count AS avg_cpu_time, ((qs.total_elapsed_time/1000) / qs.execution_count ) - ((qs.total_worker_time/1000) / qs.execution_count) AS avg_wait_time, qs.total_logical_reads / qs.execution_count AS avg_logical_reads, qs.total_logical_writes / qs.execution_count AS avg_writes, (qs.total_elapsed_time/1000) AS cumulative_elapsed_time_all_executions FROM sys.dm_exec_query_stats qs CROSS apply sys.Dm_exec_sql_text (sql_handle) t WHERE t.text like '<Your Query>%' -- Replace <Your Query> with your query or the beginning part of your query. The special chars like '[','_','%','^' in the query should be escaped. ORDER BY (qs.total_elapsed_time / qs.execution_count) DESCNota:
Si
avg_wait_timemuestra un valor negativo, se trata de una consulta paralela.Si puede ejecutar la consulta a petición en SQL Server Management Studio (SSMS) o Azure Data Studio, ejecútelo con SET STATISTICS TIME
ONy SET STATISTICS IOON.SET STATISTICS TIME ON SET STATISTICS IO ON <YourQuery> SET STATISTICS IO OFF SET STATISTICS TIME OFFA continuación, en Mensajes, verá el tiempo de CPU, el tiempo transcurrido y las lecturas lógicas como esta:
Table 'tblTest'. Scan count 1, logical reads 3, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0. SQL Server Execution Times: CPU time = 460 ms, elapsed time = 470 ms.Si puede recopilar un plan de consulta, compruebe los datos de las propiedades del plan de ejecución.
Ejecute la consulta con Incluir plan de ejecución real activado.
Seleccione el operador más a la izquierda en Plan de ejecución.
En Propiedades, expanda la propiedad QueryTimeStats .
Compruebe ElapsedTime y CpuTime.
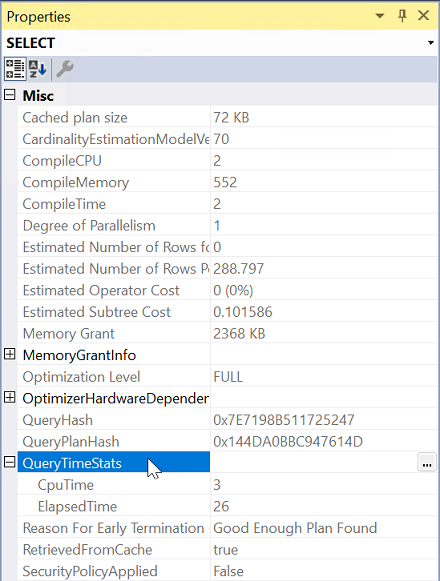
Compare el tiempo transcurrido y el tiempo de CPU de la consulta para determinar el tipo de problema para ambos servidores.
Tipo 1: enlazado a CPU (ejecutor)
Si el tiempo de CPU está cerca, es igual a o superior al tiempo transcurrido, puede tratarlo como una consulta enlazada a la CPU. Por ejemplo, si el tiempo transcurrido es de 3000 milisegundos (ms) y el tiempo de CPU es de 2900 ms, significa que la mayor parte del tiempo transcurrido se dedica a la CPU. A continuación, podemos decir que es una consulta enlazada a la CPU.
Ejemplos de consultas en ejecución (enlazadas a CPU):
| Tiempo transcurrido (ms) | Tiempo de CPU (ms) | Lecturas (lógicas) |
|---|---|---|
| 3200 | 3000 | 300000 |
| 1080 | 1 000 | 20 |
Lecturas lógicas: leer páginas de datos o índices en la memoria caché, son los controladores más frecuentes del uso de CPU en SQL Server. Podría haber escenarios en los que el uso de CPU procede de otros orígenes: un bucle while (en T-SQL u otro código como XProcs o objetos CRL de SQL). En el segundo ejemplo de la tabla se muestra este escenario, donde la mayoría de la CPU no procede de las lecturas.
Nota:
Si el tiempo de CPU es mayor que la duración, indica que se ejecuta una consulta paralela; varios subprocesos usan la CPU al mismo tiempo. Para obtener más información, consulte Consultas paralelas: ejecutor o waiter.
Tipo 2: Esperando un cuello de botella (waiter)
Una consulta está esperando un cuello de botella si el tiempo transcurrido es significativamente mayor que el tiempo de CPU. El tiempo transcurrido incluye el tiempo que ejecuta la consulta en la CPU (tiempo de CPU) y el tiempo en espera de que se libere un recurso (tiempo de espera). Por ejemplo, si el tiempo transcurrido es de 2000 ms y el tiempo de CPU es de 300 ms, el tiempo de espera es de 1700 ms (2000 - 300 = 1700). Para obtener más información, vea Tipos de esperas.
Ejemplos de consultas en espera:
| Tiempo transcurrido (ms) | Tiempo de CPU (ms) | Lecturas (lógicas) |
|---|---|---|
| 2000 | 300 | 28000 |
| 10080 | 700 | 80000 |
Consultas paralelas: ejecutor o waiter
Las consultas paralelas pueden usar más tiempo de CPU que la duración total. El objetivo del paralelismo es permitir que varios subprocesos ejecuten partes de una consulta simultáneamente. En un segundo de la hora del reloj, una consulta puede usar ocho segundos de tiempo de CPU ejecutando ocho subprocesos paralelos. Por lo tanto, resulta difícil determinar un límite de CPU o una consulta en espera en función del tiempo transcurrido y la diferencia de tiempo de CPU. Sin embargo, como regla general, siga los principios enumerados en las dos secciones anteriores. El resumen es:
- Si el tiempo transcurrido es mucho mayor que el tiempo de CPU, considere que es un waiter.
- Si el tiempo de CPU es mucho mayor que el tiempo transcurrido, tenga en cuenta que es un ejecutor.
Ejemplos de consultas paralelas:
| Tiempo transcurrido (ms) | Tiempo de CPU (ms) | Lecturas (lógicas) |
|---|---|---|
| 1200 | 8100 | 850000 |
| 3080 | 12300 | 1 500 000 |
Paso 3: Comparar datos de ambos servidores, averiguar el escenario y solucionar el problema
Supongamos que hay dos máquinas denominadas Server1 y Server2. Y la consulta se ejecuta más lentamente en Server1 que en Server2. Compare las horas de ambos servidores y, a continuación, siga las acciones del escenario que mejor coincidan con las de las secciones siguientes.
Escenario 1: La consulta en Server1 usa más tiempo de CPU y las lecturas lógicas son superiores en Server1 que en Server2
Si el tiempo de CPU en Server1 es mucho mayor que en Server2 y el tiempo transcurrido coincide con el tiempo de CPU estrechamente en ambos servidores, no hay esperas principales ni cuellos de botella. Es probable que el aumento del tiempo de CPU en Server1 se deba a un aumento en las lecturas lógicas. Un cambio significativo en las lecturas lógicas suele indicar una diferencia en los planes de consulta. Por ejemplo:
| Server | Tiempo transcurrido (ms) | Tiempo de CPU (ms) | Lecturas (lógicas) |
|---|---|---|---|
| Server1 | 3100 | 3000 | 300000 |
| Server2 | 1100 | 1 000 | 90200 |
Acción: Comprobación de los planes de ejecución y los entornos
- Compare los planes de ejecución de la consulta en ambos servidores. Para ello, use uno de los dos métodos:
- Compare visualmente los planes de ejecución. Para obtener más información, vea Mostrar un plan de ejecución real.
- Guarde los planes de ejecución y compárelos mediante la característica Comparación de planes de SQL Server Management Studio.
- Comparación de entornos. Los distintos entornos pueden provocar diferencias en el plan de consulta o diferencias directas en el uso de cpu. Los entornos incluyen versiones de servidor, opciones de configuración de base de datos o servidor, marcas de seguimiento, recuento de CPU o velocidad del reloj, y máquina virtual frente a máquina física. Consulte Diagnóstico de diferencias en el plan de consulta para obtener más información.
Escenario 2: La consulta es un waiter en Server1, pero no en Server2
Si los tiempos de CPU de la consulta en ambos servidores son similares, pero el tiempo transcurrido en Server1 es mucho mayor que en Server2, la consulta en Server1 tarda mucho más tiempo en esperar en un cuello de botella. Por ejemplo:
| Server | Tiempo transcurrido (ms) | Tiempo de CPU (ms) | Lecturas (lógicas) |
|---|---|---|---|
| Server1 | 4500 | 1 000 | 90200 |
| Server2 | 1100 | 1 000 | 90200 |
- Tiempo de espera en Server1: 4500 - 1000 = 3500 ms
- Tiempo de espera en Server2: 1100 - 1000 = 100 ms
Acción: Comprobación de tipos de espera en Server1
Identifique y elimine el cuello de botella en Server1. Algunos ejemplos de esperas son bloqueo (esperas de bloqueo), esperas de bloqueo temporal, esperas de E/S de disco, esperas de red y esperas de memoria. Para solucionar problemas comunes de cuello de botella, vaya a Diagnosticar esperas o cuellos de botella.
Escenario 3: Las consultas de ambos servidores son esperadores, pero los tipos de espera o las horas son diferentes
Por ejemplo:
| Server | Tiempo transcurrido (ms) | Tiempo de CPU (ms) | Lecturas (lógicas) |
|---|---|---|---|
| Server1 | 8000 | 1000 | 90200 |
| Server2 | 3000 | 1 000 | 90200 |
- Tiempo de espera en Server1: 8000 - 1000 = 7000 ms
- Tiempo de espera en Server2: 3000 - 1000 = 2000 ms
En este caso, los tiempos de CPU son similares en ambos servidores, lo que indica que es probable que los planes de consulta sean los mismos. Las consultas se realizarían igualmente en ambos servidores si no esperan los cuellos de botella. Por lo tanto, las diferencias de duración proceden de las diferentes cantidades de tiempo de espera. Por ejemplo, la consulta espera bloqueos en Server1 durante 7000 ms mientras espera en E/S en Server2 para 2000 ms.
Acción: Comprobación de tipos de espera en ambos servidores
Solucione cada cuello de botella que espere individualmente en cada servidor y acelere las ejecuciones en ambos servidores. La solución de este problema es de trabajo intensivo porque necesita eliminar cuellos de botella en ambos servidores y hacer que el rendimiento sea comparable. Para solucionar problemas comunes de cuello de botella, vaya a Diagnosticar esperas o cuellos de botella.
Escenario 4: La consulta en Server1 usa más tiempo de CPU que en Server2, pero las lecturas lógicas están cerca
Por ejemplo:
| Server | Tiempo transcurrido (ms) | Tiempo de CPU (ms) | Lecturas (lógicas) |
|---|---|---|---|
| Server1 | 3000 | 3000 | 90200 |
| Server2 | 1 000 | 1 000 | 90200 |
Si los datos coinciden con las condiciones siguientes:
- La hora de CPU en Server1 es mucho mayor que en Server2.
- El tiempo transcurrido coincide con el tiempo de CPU estrechamente en cada servidor, lo que indica que no hay esperas.
- Las lecturas lógicas, normalmente el controlador más alto del tiempo de CPU, son similares en ambos servidores.
A continuación, el tiempo adicional de CPU procede de otras actividades enlazadas a la CPU. Este escenario es el más raro de todos los escenarios.
Causas: Seguimiento, UDF e integración clR
Este problema puede deberse a:
- Seguimiento de XEvents/SQL Server, especialmente con el filtrado en columnas de texto (nombre de base de datos, nombre de inicio de sesión, texto de consulta, etc.). Si el seguimiento está habilitado en un servidor, pero no en el otro, podría ser el motivo de la diferencia.
- Funciones definidas por el usuario (UDF) u otro código T-SQL que realiza operaciones enlazadas a la CPU. Normalmente, esto sería la causa cuando otras condiciones son diferentes en Server1 y Server2, como el tamaño de los datos, la velocidad del reloj de CPU o el plan de energía.
- Integración clR de SQL Server o procedimientos almacenados extendidos (XP) que pueden impulsar la CPU, pero que no realizan lecturas lógicas. Las diferencias en los archivos DLL pueden provocar tiempos de CPU diferentes.
- Diferencia en la funcionalidad de SQL Server enlazada a la CPU (por ejemplo, código de manipulación de cadenas).
Acción: Comprobación de seguimientos y consultas
Compruebe los seguimientos en ambos servidores para ver lo siguiente:
- Si hay algún seguimiento habilitado en Server1, pero no en Server2.
- Si hay algún seguimiento habilitado, deshabilite el seguimiento y vuelva a ejecutar la consulta en Server1.
- Si la consulta se ejecuta más rápido esta vez, habilite el seguimiento, pero quite los filtros de texto, si hay alguno.
Compruebe si la consulta usa UDF que realizan manipulaciones de cadenas o realizan un procesamiento exhaustivo en columnas de datos de la
SELECTlista.Compruebe si la consulta contiene bucles, recursiones de función o anidamientos.
Diagnóstico de diferencias de entorno
Compruebe las siguientes preguntas y determine si la comparación entre los dos servidores es válida.
¿Las dos instancias de SQL Server son la misma versión o compilación?
Si no es así, podría haber algunas correcciones que provocaron las diferencias. Ejecute la consulta siguiente para obtener información de versión en ambos servidores:
SELECT @@VERSION¿Es similar la cantidad de memoria física en ambos servidores?
Si un servidor tiene 64 GB de memoria mientras que el otro tiene 256 GB de memoria, sería una diferencia significativa. Con más memoria disponible para almacenar en caché páginas de datos o índices y planes de consulta, la consulta podría optimizarse de forma diferente en función de la disponibilidad de recursos de hardware.
¿Son similares las configuraciones de hardware relacionadas con la CPU en ambos servidores? Por ejemplo:
El número de CPU varía entre las máquinas (24 CPU en una máquina frente a 96 CPU en la otra).
Planes de energía, equilibrados frente a alto rendimiento.
Máquina virtual (VM) frente a máquina física (sin sistema operativo).
Hyper-V frente a VMware: diferencia en la configuración.
Diferencia de velocidad del reloj (menor velocidad del reloj frente a mayor velocidad del reloj). Por ejemplo, 2 GHz frente a 3,5 GHz puede marcar una diferencia. Para obtener la velocidad del reloj en un servidor, ejecute el siguiente comando de PowerShell:
Get-CimInstance Win32_Processor | Select-Object -Expand MaxClockSpeed
Use una de las dos maneras siguientes para probar la velocidad de CPU de los servidores. Si no producen resultados comparables, el problema está fuera de SQL Server. Podría ser una diferencia de plan de energía, menos CPU, problemas de software de máquina virtual o diferencia de velocidad del reloj.
Ejecute el siguiente script de PowerShell en ambos servidores y compare las salidas.
$bf = [System.DateTime]::Now for ($i = 0; $i -le 20000000; $i++) {} $af = [System.DateTime]::Now Write-Host ($af - $bf).Milliseconds " milliseconds" Write-Host ($af - $bf).Seconds " Seconds"Ejecute el siguiente código de Transact-SQL en ambos servidores y compare las salidas.
SET NOCOUNT ON DECLARE @spins INT = 0 DECLARE @start_time DATETIME = GETDATE(), @time_millisecond INT WHILE (@spins < 20000000) BEGIN SET @spins = @spins +1 END SELECT @time_millisecond = DATEDIFF(millisecond, @start_time, getdate()) SELECT @spins Spins, @time_millisecond Time_ms, @spins / @time_millisecond Spins_Per_ms
Diagnóstico de esperas o cuellos de botella
Para optimizar una consulta que está esperando cuellos de botella, identifique cuánto tiempo es la espera y dónde está el cuello de botella (el tipo de espera). Una vez confirmado el tipo de espera, reduzca el tiempo de espera o elimine la espera por completo.
Para calcular el tiempo de espera aproximado, resta el tiempo de CPU (tiempo de trabajo) del tiempo transcurrido de una consulta. Normalmente, el tiempo de CPU es el tiempo de ejecución real y la parte restante de la duración de la consulta está esperando.
Ejemplos de cómo calcular la duración aproximada de la espera:
| Tiempo transcurrido (ms) | Tiempo de CPU (ms) | Tiempo de espera (ms) |
|---|---|---|
| 3200 | 3000 | 200 |
| 7080 | 1 000 | 6080 |
Identificación del cuello de botella o espera
Para identificar consultas históricas de larga espera (por ejemplo, >el 20 % del tiempo de espera total transcurrido es el tiempo de espera), ejecute la consulta siguiente. Esta consulta usa estadísticas de rendimiento para los planes de consulta almacenados en caché desde el inicio de SQL Server.
SELECT t.text, qs.total_elapsed_time / qs.execution_count AS avg_elapsed_time, qs.total_worker_time / qs.execution_count AS avg_cpu_time, (qs.total_elapsed_time - qs.total_worker_time) / qs.execution_count AS avg_wait_time, qs.total_logical_reads / qs.execution_count AS avg_logical_reads, qs.total_logical_writes / qs.execution_count AS avg_writes, qs.total_elapsed_time AS cumulative_elapsed_time FROM sys.dm_exec_query_stats qs CROSS apply sys.Dm_exec_sql_text (sql_handle) t WHERE (qs.total_elapsed_time - qs.total_worker_time) / qs.total_elapsed_time > 0.2 ORDER BY qs.total_elapsed_time / qs.execution_count DESCPara identificar las consultas que se ejecutan actualmente con esperas de más de 500 ms, ejecute la consulta siguiente:
SELECT r.session_id, r.wait_type, r.wait_time AS wait_time_ms FROM sys.dm_exec_requests r JOIN sys.dm_exec_sessions s ON r.session_id = s.session_id WHERE wait_time > 500 AND is_user_process = 1Si puede recopilar un plan de consulta, compruebe WaitStats de las propiedades del plan de ejecución en SSMS:
- Ejecute la consulta con Incluir plan de ejecución real activado.
- Haga clic con el botón derecho en el operador de la izquierda en la pestaña Plan de ejecución.
- Seleccione Propiedades y, a continuación, propiedad WaitStats .
- Compruebe waitTimeMs y WaitType.
Si está familiarizado con los escenarios PSSDiag/SQLdiag o SQL LogScout LightPerf/GeneralPerf, considere la posibilidad de usar cualquiera de ellos para recopilar estadísticas de rendimiento e identificar consultas en espera en la instancia de SQL Server. Puede importar los archivos de datos recopilados y analizar los datos de rendimiento con SQL Nexus.
Referencias para ayudar a eliminar o reducir las esperas
Las causas y resoluciones de cada tipo de espera varían. No hay ningún método general para resolver todos los tipos de espera. Estos son los artículos para solucionar y resolver problemas comunes de tipo de espera:
- Comprender y resolver problemas de bloqueo (LCK_M_*)
- Descripción y resolución de problemas de bloqueo en Azure SQL Database
- Solución de problemas lentos de rendimiento de SQL Server causados por problemas de E/S (PAGEIOLATCH_*, WRITELOG, IO_COMPLETION, BACKUPIO)
- Resolución de la contención de inserción de la última página de PAGELATCH_EX en SQL Server
- Memoria concede explicaciones y soluciones (RESOURCE_SEMAPHORE)
- Solución de problemas de consultas lentas resultantes de ASYNC_NETWORK_IO tipo de espera
- Solución de problemas de tipo de espera de alta HADR_SYNC_COMMIT con grupos de disponibilidad AlwaysOn
- Cómo funciona: CMEMTHREAD y depurarlos
- Hacer que el paralelismo sea accionable (CXPACKET y CXCONSUMER)
- Espera de THREADPOOL
Para obtener descripciones de muchos tipos de espera y lo que indican, consulte la tabla en Tipos de esperas.
Diagnóstico de diferencias en el plan de consulta
Estas son algunas causas comunes de las diferencias en los planes de consulta:
Diferencias de tamaño de datos o valores de datos
¿Se usa la misma base de datos en ambos servidores, con la misma copia de seguridad de la base de datos? ¿Se han modificado los datos en un servidor en comparación con el otro? Las diferencias de datos pueden dar lugar a diferentes planes de consulta. Por ejemplo, la combinación de la tabla T1 (1000 filas) con la tabla T2 (2000 000 filas) es diferente de combinar la tabla T1 (100 filas) con la tabla T2 (2000 000 000 filas). El tipo y la velocidad de la
JOINoperación pueden ser significativamente diferentes.Diferencias de estadísticas
¿Se han actualizado las estadísticas en una base de datos y no en la otra? ¿Se han actualizado las estadísticas con una frecuencia de muestreo diferente (por ejemplo, un 30 % frente al 100 % de examen completo)? Asegúrese de actualizar las estadísticas en ambos lados con la misma frecuencia de muestreo.
Diferencias de nivel de compatibilidad de base de datos
Compruebe si los niveles de compatibilidad de las bases de datos son diferentes entre los dos servidores. Para obtener el nivel de compatibilidad de la base de datos, ejecute la consulta siguiente:
SELECT name, compatibility_level FROM sys.databases WHERE name = '<YourDatabase>'Diferencias de versión o compilación del servidor
¿Las versiones o compilaciones de SQL Server son diferentes entre los dos servidores? Por ejemplo, ¿es un servidor SQL Server versión 2014 y la otra versión de SQL Server 2016? Podría haber cambios en el producto que pueden provocar cambios en la selección de un plan de consulta. Asegúrese de comparar la misma versión y compilación de SQL Server.
SELECT ServerProperty('ProductVersion')Diferencias de versión del estimador de cardinalidad (CE)
Compruebe si el estimador de cardinalidad heredado está activado en el nivel de base de datos. Para obtener más información sobre CE, vea Estimación de cardinalidad (SQL Server) .
SELECT name, value, is_value_default FROM sys.database_scoped_configurations WHERE name = 'LEGACY_CARDINALITY_ESTIMATION'Revisiones del optimizador habilitadas o deshabilitadas
Si las revisiones del optimizador de consultas están habilitadas en un servidor pero deshabilitadas en la otra, se pueden generar planes de consulta diferentes. Para obtener más información, consulte El modelo de mantenimiento 4199 del optimizador de consultas de SQL Server.
Para obtener el estado de las revisiones del optimizador de consultas, ejecute la consulta siguiente:
-- Check at server level for TF 4199 DBCC TRACESTATUS (-1) -- Check at database level USE <YourDatabase> SELECT name, value, is_value_default FROM sys.database_scoped_configurations WHERE name = 'QUERY_OPTIMIZER_HOTFIXES'Diferencias de marcas de seguimiento
Algunas marcas de seguimiento afectan a la selección del plan de consulta. Compruebe si hay marcas de seguimiento habilitadas en un servidor que no están habilitados en el otro. Ejecute la consulta siguiente en ambos servidores y compare los resultados:
-- Check at server level for trace flags DBCC TRACESTATUS (-1)Diferencias de hardware (recuento de CPU, tamaño de memoria)
Para obtener la información de hardware, ejecute la consulta siguiente:
SELECT cpu_count, physical_memory_kb/1024/1024 PhysicalMemory_GB FROM sys.dm_os_sys_infoDiferencias de hardware según el optimizador de consultas
Compruebe el
OptimizerHardwareDependentPropertiesvalor de un plan de consulta y compruebe si las diferencias de hardware se consideran significativas para distintos planes.WITH xmlnamespaces(DEFAULT 'http://schemas.microsoft.com/sqlserver/2004/07/showplan') SELECT txt.text, t.OptHardw.value('@EstimatedAvailableMemoryGrant', 'INT') AS EstimatedAvailableMemoryGrant , t.OptHardw.value('@EstimatedPagesCached', 'INT') AS EstimatedPagesCached, t.OptHardw.value('@EstimatedAvailableDegreeOfParallelism', 'INT') AS EstimatedAvailDegreeOfParallelism, t.OptHardw.value('@MaxCompileMemory', 'INT') AS MaxCompileMemory FROM sys.dm_exec_cached_plans AS cp CROSS APPLY sys.dm_exec_query_plan(cp.plan_handle) AS qp CROSS APPLY qp.query_plan.nodes('//OptimizerHardwareDependentProperties') AS t(OptHardw) CROSS APPLY sys.dm_exec_sql_text (CP.plan_handle) txt WHERE text Like '%<Part of Your Query>%'Tiempo de espera del optimizador
¿Hay un problema de tiempo de espera del optimizador? El optimizador de consultas puede dejar de evaluar las opciones del plan si la consulta que se ejecuta es demasiado compleja. Cuando se detiene, elige el plan con el costo más bajo disponible en el momento. Esto puede dar lugar a lo que parece una opción de plan arbitraria en un servidor frente a otro.
Opciones de Set
Algunas opciones SET afectan al plan, como SET ARITHABORT. Para obtener más información, consulte OPCIONES SET.
Diferencias de sugerencias de consulta
¿Una consulta usa sugerencias de consulta y la otra no? Compruebe manualmente el texto de la consulta para establecer la presencia de sugerencias de consulta.
Planes sensibles a parámetros (problema de examen de parámetros)
¿Está probando la consulta con los mismos valores de parámetro exactamente? Si no es así, puede empezar allí. ¿El plan se compiló anteriormente en un servidor basado en un valor de parámetro diferente? Pruebe las dos consultas mediante la sugerencia de consulta RECOMPILE para asegurarse de que no se realiza ninguna reutilización del plan. Para obtener más información, consulte Investigar y resolver problemas confidenciales de parámetros.
Diferentes opciones de base de datos o opciones de configuración con ámbito
¿Se usan las mismas opciones de base de datos o opciones de configuración con ámbito en ambos servidores? Algunas opciones de base de datos pueden influir en las opciones del plan. Por ejemplo, la compatibilidad de la base de datos, la CE heredada frente a la ce predeterminada y el examen de parámetros. Ejecute la consulta siguiente desde un servidor para comparar las opciones de base de datos usadas en los dos servidores:
-- On Server1 add a linked server to Server2 EXEC master.dbo.sp_addlinkedserver @server = N'Server2', @srvproduct=N'SQL Server' -- Run a join between the two servers to compare settings side by side SELECT s1.name AS srv1_config_name, s2.name AS srv2_config_name, s1.value_in_use AS srv1_value_in_use, s2.value_in_use AS srv2_value_in_use, Variance = CASE WHEN ISNULL(s1.value_in_use, '##') != ISNULL(s2.value_in_use,'##') THEN 'Different' ELSE '' END FROM sys.configurations s1 FULL OUTER JOIN [server2].master.sys.configurations s2 ON s1.name = s2.name SELECT s1.name AS srv1_config_name, s2.name AS srv2_config_name, s1.value srv1_value_in_use, s2.value srv2_value_in_use, s1.is_value_default, s2.is_value_default, Variance = CASE WHEN ISNULL(s1.value, '##') != ISNULL(s2.value, '##') THEN 'Different' ELSE '' END FROM sys.database_scoped_configurations s1 FULL OUTER JOIN [server2].master.sys.database_scoped_configurations s2 ON s1.name = s2.nameGuías de plan
¿Se usan guías de plan para las consultas en un servidor, pero no en el otro? Ejecute la consulta siguiente para establecer diferencias:
SELECT * FROM sys.plan_guides