Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En la fase anterior de este tutorial, instalamos PyTorch en la máquina. Ahora lo usaremos para configurar el código con los datos que utilizaremos para crear el modelo.
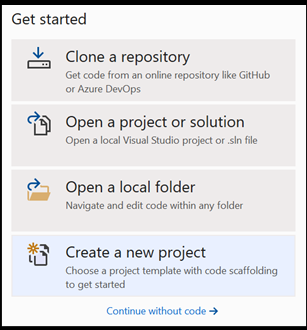
Abra un nuevo proyecto en Visual Studio.
- Abra Visual Studio y elija
create a new project.
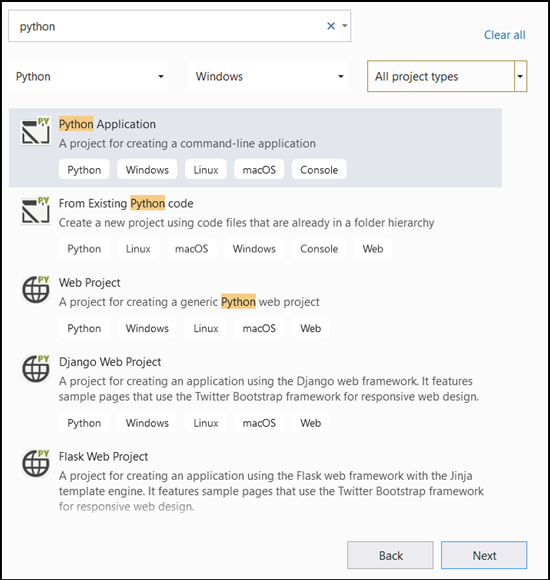
- En la barra de búsqueda, escriba
Pythony seleccionePython Applicationcomo plantilla de proyecto.
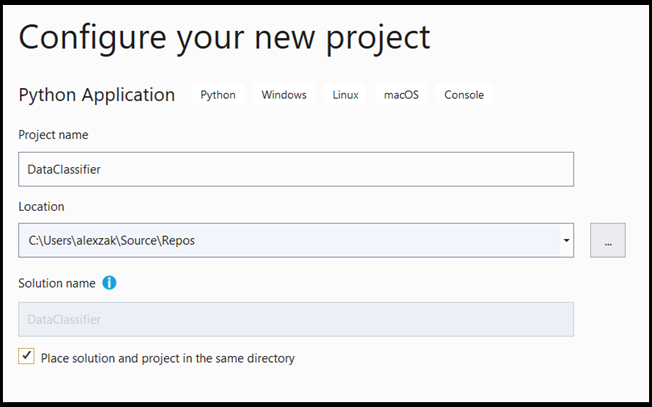
- En la ventana de configuración:
- Dé un nombre al proyecto. Aquí, lo llamamos DataClassifier.
- Elija la ubicación del proyecto.
- Si usa VS2019, asegúrese de que
Create directory for solutionestá activado. - Si está usando VS2017, asegúrese de que
Place solution and project in the same directoryno esté activado.
Presione create para crear el proyecto.
Creación de un intérprete de Python
En esta sección debe definir un nuevo intérprete de Python. Recuerde que debe incluir el paquete de PyTorch que instaló recientemente.
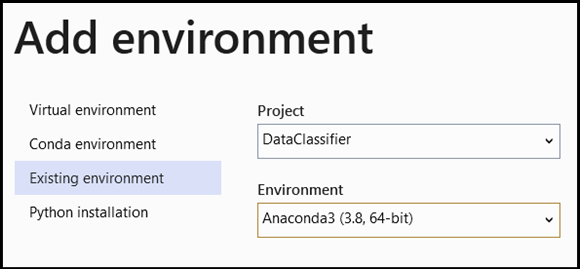
- Vaya a la selección del intérprete y seleccione
Add Environment:

- En la ventana
Add Environment, seleccioneExisting environmenty elijaAnaconda3 (3.6, 64-bit). Esta opción incluye el paquete de PyTorch.
Para probar el nuevo intérprete de Python y el paquete de PyTorch, escriba el código siguiente en el archivo DataClassifier.py:
from __future__ import print_function
import torch
x=torch.rand(2, 3)
print(x)
El resultado debe ser un tensor aleatorio de 5 x 3 similar al siguiente.
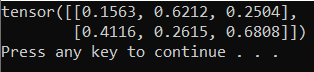
Nota:
¿Quiere saber más sobre el tema? Visite el sitio web oficial de PyTorch.
Descripción de los datos
Entrenaremos el modelo con el conjunto de datos de flores Iris de Fisher. Este famoso conjunto de datos incluye 50 registros para cada una de las tres especies iris: Iris setosa, Iris virginica e Iris versicolor.
Se han publicado varias versiones del conjunto de datos. Puede encontrar el conjunto de datos iris en el repositorio de Machine Learning de UCI, importar el conjunto de datos directamente desde la biblioteca scikit-learn de Python o usar cualquier otra versión publicada anteriormente. Para obtener información sobre el conjunto de datos de flores iris, visite su página de Wikipedia.
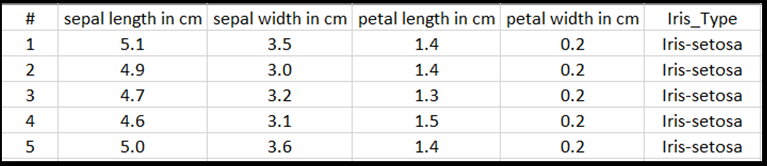
En este tutorial, para mostrar cómo entrenar el modelo con el tipo tabular de entrada, usará el conjunto de datos Iris exportado al archivo de Excel.
Cada línea de la tabla de excel mostrará cuatro características de Irises: longitud del sépalo en cm, ancho del sépalo en cm, longitud pétala en cm y ancho de pétalo en cm. Estas características servirán como entrada. La última columna incluye el tipo Iris relacionado con estos parámetros y representará la salida de regresión. En total, el conjunto de datos incluye 150 entradas de cuatro características, cada una de ellas coincide con el tipo iris correspondiente.
El análisis de regresión examina la relación entre las variables de entrada y el resultado. En función de la entrada, el modelo aprenderá a predecir el tipo correcto de salida: uno de los tres tipos iris: Iris-setosa, Iris-versicolor, Iris-virginica.
Importante
Si decide usar cualquier otro conjunto de datos para crear su propio modelo, deberá especificar las variables de entrada del modelo y la salida según su escenario.
Cargue el conjunto de datos.
Descargue el conjunto de datos iris en formato excel. Puedes encontrarlo aquí.
En el archivo
DataClassifier.pyde la carpeta Archivos del Explorador de Soluciones, agregue la siguiente instrucción 'import' para acceder a todos los paquetes que necesitaremos.
import torch
import pandas as pd
import torch.nn as nn
from torch.utils.data import random_split, DataLoader, TensorDataset
import torch.nn.functional as F
import numpy as np
import torch.optim as optim
from torch.optim import Adam
Como puede ver, usará el paquete pandas (análisis de datos de Python) para cargar y manipular datos y paquete torch.nn que contiene módulos y clases extensibles para crear redes neuronales.
- Cargue los datos en la memoria y compruebe el número de clases. Se esperan 50 elementos de cada tipo de Iris. Asegúrese de especificar la ubicación del conjunto de datos en el equipo.
Agregue el siguiente código al archivo DataClassifier.py.
# Loading the Data
df = pd.read_excel(r'C:…\Iris_dataset.xlsx')
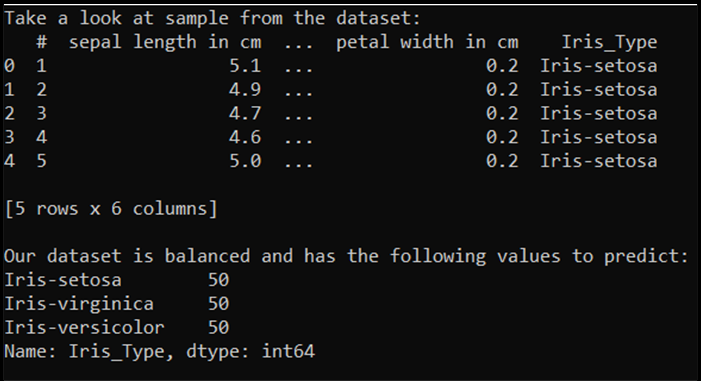
print('Take a look at sample from the dataset:')
print(df.head())
# Let's verify if our data is balanced and what types of species we have
print('\nOur dataset is balanced and has the following values to predict:')
print(df['Iris_Type'].value_counts())
Cuando se ejecuta este código, la salida esperada es la siguiente:
Para poder usar el conjunto de datos y entrenar el modelo, es necesario definir la entrada y la salida. La entrada incluye 150 líneas de características y la salida es la columna tipo Iris. La red neuronal que usaremos requiere variables numéricas, por lo que convertirá la variable de salida a un formato numérico.
- Cree una nueva columna en el conjunto de datos que representará la salida en un formato numérico y defina una entrada y salida de regresión.
Agregue el siguiente código al archivo DataClassifier.py.
# Convert Iris species into numeric types: Iris-setosa=0, Iris-versicolor=1, Iris-virginica=2.
labels = {'Iris-setosa':0, 'Iris-versicolor':1, 'Iris-virginica':2}
df['IrisType_num'] = df['Iris_Type'] # Create a new column "IrisType_num"
df.IrisType_num = [labels[item] for item in df.IrisType_num] # Convert the values to numeric ones
# Define input and output datasets
input = df.iloc[:, 1:-2] # We drop the first column and the two last ones.
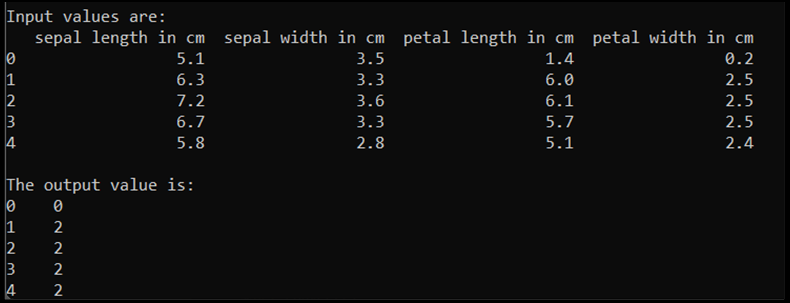
print('\nInput values are:')
print(input.head())
output = df.loc[:, 'IrisType_num'] # Output Y is the last column
print('\nThe output value is:')
print(output.head())
Cuando se ejecuta este código, la salida esperada es la siguiente:
Para entrenar el modelo, es necesario convertir la entrada y salida del modelo al formato Tensor:
- Convertir a Tensor:
Agregue el siguiente código al archivo DataClassifier.py.
# Convert Input and Output data to Tensors and create a TensorDataset
input = torch.Tensor(input.to_numpy()) # Create tensor of type torch.float32
print('\nInput format: ', input.shape, input.dtype) # Input format: torch.Size([150, 4]) torch.float32
output = torch.tensor(output.to_numpy()) # Create tensor type torch.int64
print('Output format: ', output.shape, output.dtype) # Output format: torch.Size([150]) torch.int64
data = TensorDataset(input, output) # Create a torch.utils.data.TensorDataset object for further data manipulation
Si ejecutamos el código, la salida esperada mostrará el formato de entrada y salida, como se indica a continuación:

Hay 150 valores de entrada. Aproximadamente el 60 % serán datos de entrenamiento del modelo. Mantendrá el 20 % para la validación y el 30 % para una prueba.
En este tutorial, el tamaño del lote de un conjunto de datos de entrenamiento se define como 10. Hay 95 elementos en el conjunto de entrenamiento, lo que significa que, en promedio, hay 9 lotes completos para recorrer en iteración el conjunto de entrenamiento una vez (una época). Mantendrá el tamaño del lote de los conjuntos de validación y pruebas en 1.
- Divida los datos para entrenar, validar y probar conjuntos:
Agregue el siguiente código al archivo DataClassifier.py.
# Split to Train, Validate and Test sets using random_split
train_batch_size = 10
number_rows = len(input) # The size of our dataset or the number of rows in excel table.
test_split = int(number_rows*0.3)
validate_split = int(number_rows*0.2)
train_split = number_rows - test_split - validate_split
train_set, validate_set, test_set = random_split(
data, [train_split, validate_split, test_split])
# Create Dataloader to read the data within batch sizes and put into memory.
train_loader = DataLoader(train_set, batch_size = train_batch_size, shuffle = True)
validate_loader = DataLoader(validate_set, batch_size = 1)
test_loader = DataLoader(test_set, batch_size = 1)
Pasos siguientes
Con los datos listos para usar, es el momento de entrenar nuestro modelo de PyTorch.