Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
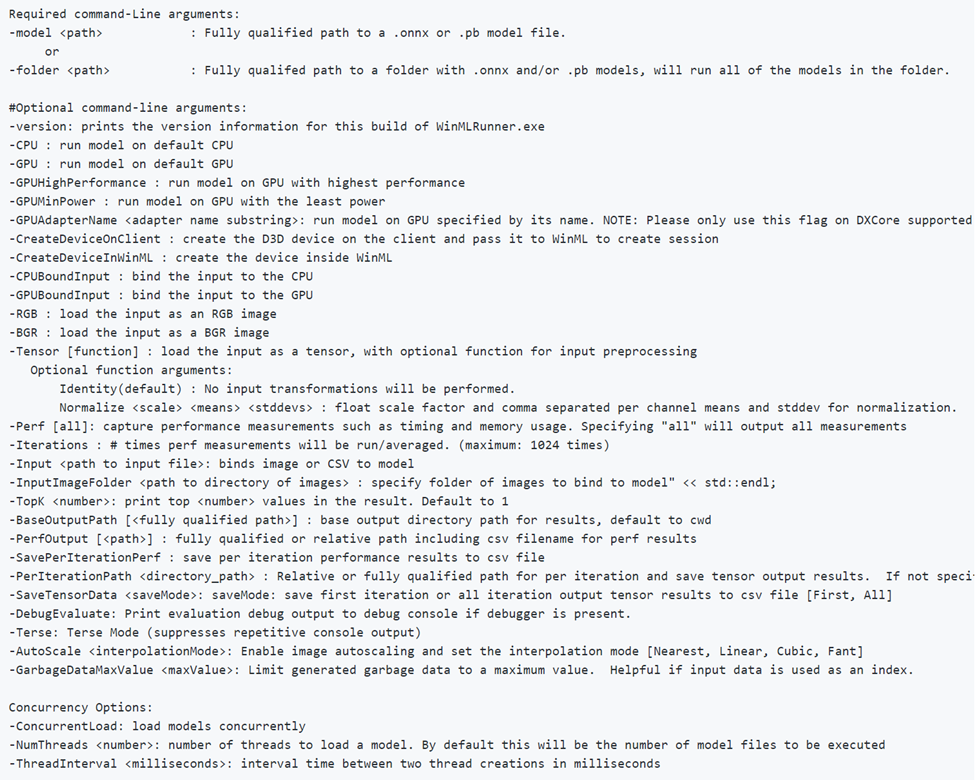
WinMLRunner es una herramienta para probar si un modelo se ejecuta correctamente cuando se evalúa con las API de Windows ML. También puede capturar el tiempo de evaluación y el uso de memoria en la GPU y/o la CPU. Se pueden evaluar modelos en formato .onnx o .pb donde las variables de entrada y salida son tensores o imágenes. Hay 2 formas de usar WinMLRunner:
- Descargue la herramienta de python de línea de comandos.
- Úselo dentro del panel de WinML. Para obtener más información, consulte la documentación del panel de WinML
Ejecución de un modelo
Primero, abra la herramienta Python descargada. Navegue hasta la carpeta que contiene WinMLRunner.exey ejecute el ejecutable como se muestra a continuación. Asegúrese de reemplazar la ubicación de instalación por una que coincida con la suya:
.\WinMLRunner.exe -model SqueezeNet.onnx
También puede ejecutar una carpeta de modelos, con un comando como el siguiente.
WinMLRunner.exe -folder c:\data -perf -iterations 3 -CPU`\
Ejecutar un buen modelo
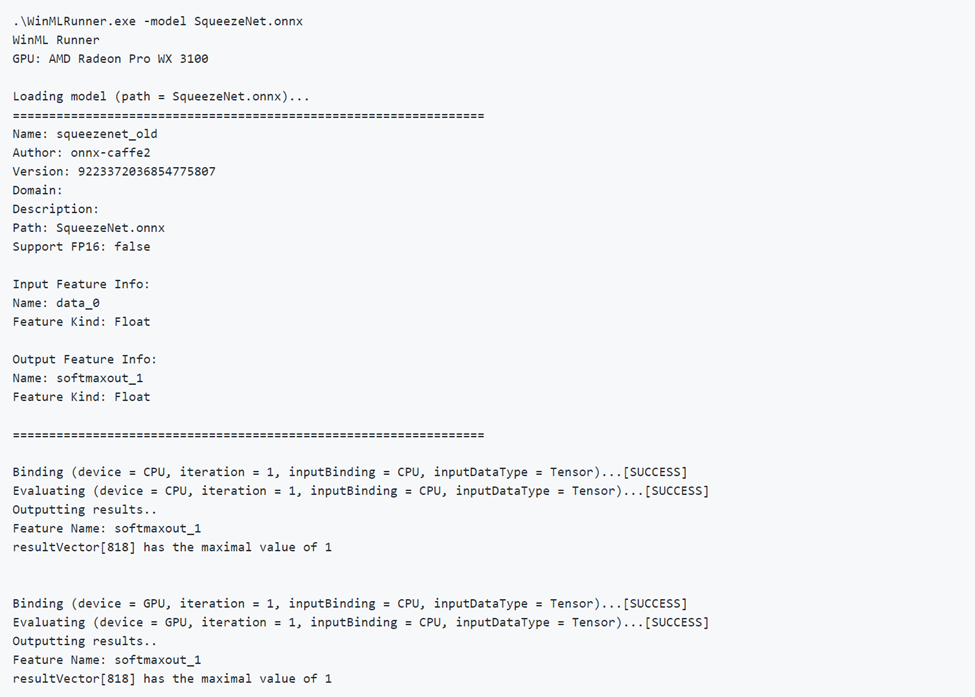
A continuación se muestra un ejemplo de ejecución correcta de un modelo. Observe cómo primero el modelo carga y genera los metadatos del modelo. A continuación, el modelo se ejecuta en la CPU y la GPU por separado, lo que genera el éxito del enlace, el éxito de la evaluación y la salida del modelo.
Ejecución de un modelo incorrecto
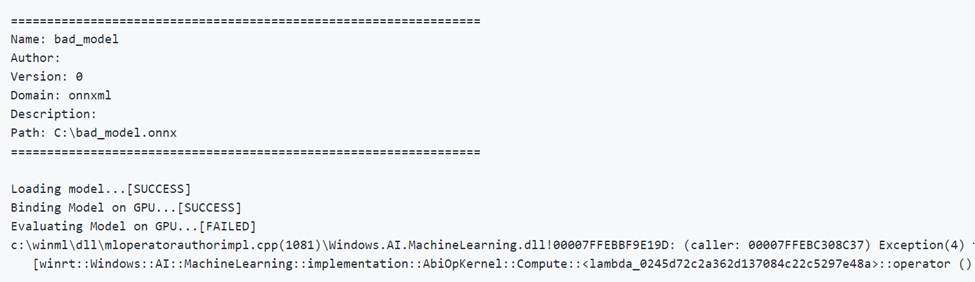
A continuación se muestra un ejemplo de ejecución de un modelo con parámetros incorrectos. Observe la salida FAILED al evaluar en GPU.
Selección y optimización de dispositivos
De forma predeterminada, el modelo se ejecuta en la CPU y la GPU por separado, pero puede especificar un dispositivo con una marca -CPU o -GPU. A continuación, se muestra un ejemplo de cómo ejecutar un modelo 3 veces utilizando solo la CPU:
WinMLRunner.exe -model c:\data\concat.onnx -iterations 3 -CPU
Registro de datos de rendimiento
Utilice la marca -perf para capturar datos de rendimiento. A continuación, se muestra un ejemplo de ejecución de todos los modelos de la carpeta de datos en la CPU y la GPU por separado 3 veces y captura de datos de rendimiento:
WinMLRunner.exe -folder c:\data iterations 3 -perf
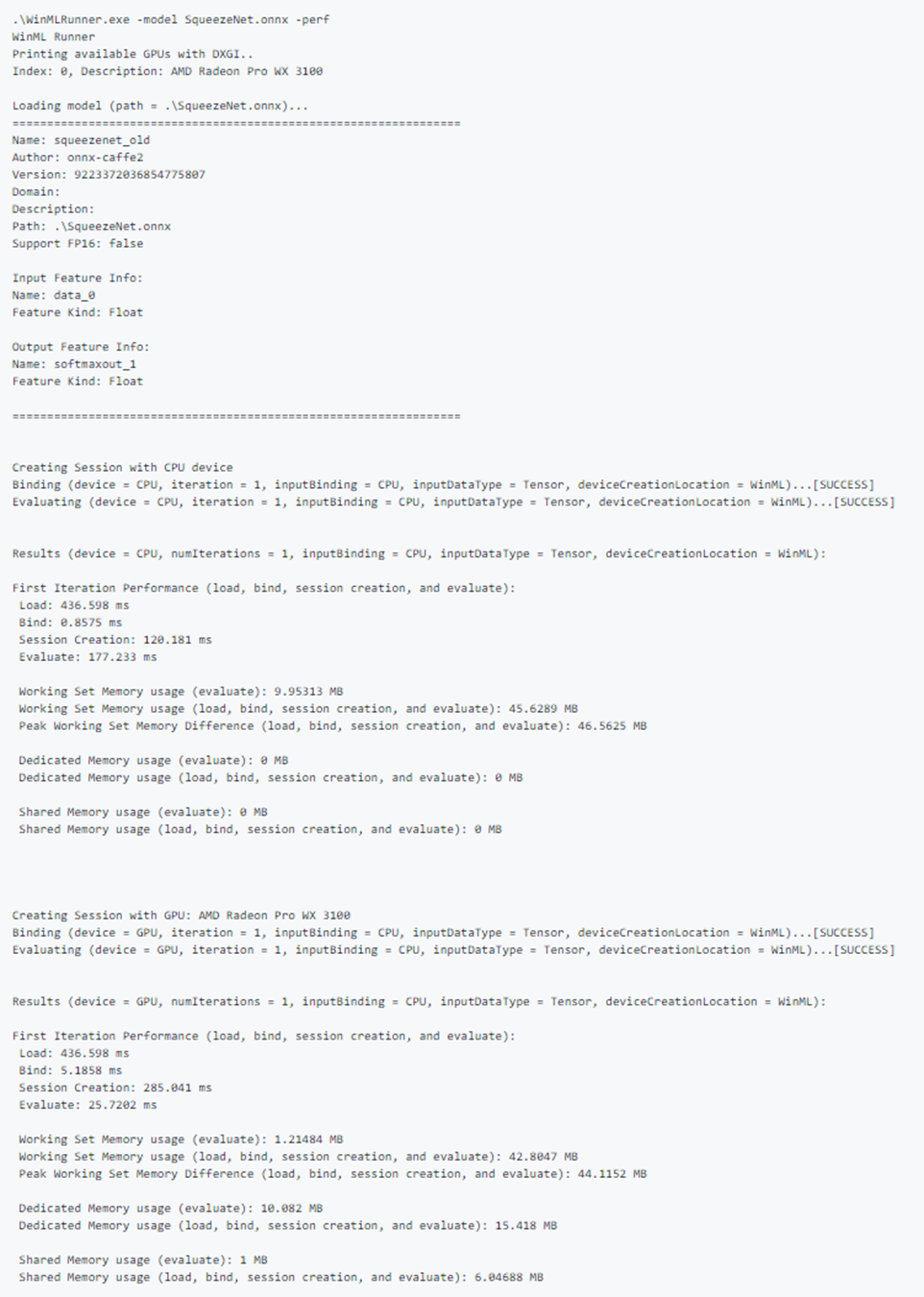
Mediciones de rendimiento
Las siguientes mediciones de rendimiento se generarán en la línea de comandos y en el archivo de .csv para cada operación de carga, enlace y evaluación:
- Tiempo de reloj de pared (ms): el tiempo real transcurrido entre el inicio y el final de una operación.
- Tiempo de GPU (ms): tiempo para que una operación se pase de la CPU a la GPU y se ejecute en la GPU (nota: Load() no se ejecuta en la GPU).
- Tiempo de CPU (ms): tiempo que tarda una operación en ejecutarse en la CPU.
- Uso de memoria dedicada y compartida (MB): Uso medio de memoria de nivel de usuario y kernel (en MB) durante la evaluación en la CPU o GPU.
- Memoria del espacio de trabajo (MB): La cantidad de memoria DRAM que el proceso en la CPU requirió durante la evaluación. Memoria dedicada (MB): la cantidad de memoria que se utilizó en la VRAM de la GPU dedicada.
- Memoria compartida (MB): La cantidad de memoria que la GPU utilizó en la DRAM.
Ejemplo de salida de rendimiento:
Entradas de muestra de prueba
Ejecute un modelo en la CPU y la GPU por separado, y vinculando la entrada a la CPU y la GPU por separado (4 ejecuciones en total):
WinMLRunner.exe -model c:\data\SqueezeNet.onnx -CPU -GPU -CPUBoundInput -GPUBoundInput
Ejecute un modelo en la CPU con la entrada vinculada a la GPU y cargada como una imagen RGB:
WinMLRunner.exe -model c:\data\SqueezeNet.onnx -CPU -GPUBoundInput -RGB
Captura de registros de seguimiento
Si desea capturar registros de seguimiento con la herramienta, puede utilizar los comandos logman junto con el indicador de depuración:
logman start winml -ets -o winmllog.etl -nb 128 640 -bs 128logman update trace winml -p {BCAD6AEE-C08D-4F66-828C-4C43461A033D} 0xffffffffffffffff 0xff -ets WinMLRunner.exe -model C:\Repos\Windows-Machine-Learning\SharedContent\models\SqueezeNet.onnx -debuglogman stop winml -ets
El archivo winmllog.etl aparecerá en el mismo directorio que el WinMLRunner.exe.
Lectura de los registros de seguimiento
Con el traceprt.exe, ejecute el siguiente comando desde la línea de comandos.
tracerpt.exe winmllog.etl -o logdump.csv -of CSV
A continuación, abra el logdump.csv archivo.
Como alternativa, puede usar el Analizador de rendimiento de Windows (desde Visual Studio). Inicie el Analizador de rendimiento de Windows y abra winmllog.etlarchivos .
Tenga en cuenta que -CPU, -GPU, -GPUHighPerformance, -GPUMinPower -BGR, -RGB, -tensor, -CPUBoundInput, -GPUBoundInput no son mutuamente excluyentes (es decir, puede combinar tantos como desee para ejecutar el modelo con diferentes configuraciones).
Carga dinámica de DLL
Si desea ejecutar WinMLRunner con otra versión de WinML (por ejemplo, comparando el rendimiento con una versión anterior o probando una versión más reciente), simplemente coloque los archivos windows.ai.machinelearning.dll y directml.dll en la misma carpeta que WinMLRunner.exe. WinMLRunner buscará primero estos archivos DLL y recurrirá a C:/Windows/System32 si no los encuentra.
Problemas conocidos
- Las entradas de secuencia/mapa aún no son compatibles (el modelo simplemente se omite, por lo que no bloquea otros modelos en una carpeta);
- No podemos ejecutar de forma fiable varios modelos con el argumento -folder con datos reales. Dado que solo podemos especificar 1 entrada, el tamaño de la entrada no coincidiría con la mayoría de los modelos. En este momento, usar el argumento -folder solo funciona bien con datos basura;
- Actualmente no se admite la generación de entradas de basura como Gray o YUV. Idealmente, la canalización de datos basura de WinMLRunner debería admitir todos los tipos de entradas que podemos dar a winml.