Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este tema se describen las tres fases del proceso de indexación y los componentes principales implicados en cada uno de ellos, se explica el tiempo de la actividad de indexación y se proporcionan algunas notas para los desarrolladores de terceros que desean indexar sus almacenes de datos o formatos de archivo.
Este tema se organiza de la siguiente manera:
- Información general
- Fase 1: Direcciones URL de puesta en cola para la indexación
- Fase 2: Rastreo de direcciones URL
- Fase 3: Actualización del índice
- Cómo se programa la indexación
- Notas a los implementadores
- Temas relacionados
Información general
Windows Search admite la indexación de propiedades y contenido de archivos de diferentes formatos de archivo, como formatos .doc o .jpeg, y almacenes de datos, como el sistema de archivos o los buzones de Windows Outlook. Hay dos tipos de índices: índices de valor que permiten filtrar y ordenar por todo el valor de una propiedad e índices invertidos que indexan palabras dentro de propiedades textuales o contenido. Si tiene un formato de archivo personalizado o un almacén de datos, debe comprender cómo se indexan correctamente los índices de Windows Search para obtener los elementos indexados correctamente.
El proceso de indexación se produce en tres fases controladas por un componente de Windows Search denominado recopilador. En la primera fase, el recopilador agrega direcciones URL a las colas. Las direcciones URL identifican los elementos que se van a indexar y las colas son simplemente listas prioritarias de direcciones URL. En la segunda fase, el recopilador coordina otros componentes de Windows Search y de terceros para acceder a los elementos y recopilar datos sobre ellos. Por último, en la tercera fase, los datos recopilados se agregan al índice.
En el diagrama siguiente se muestran los componentes principales y el flujo de datos a través del proceso de indexación. Hay varios componentes implicados en la recopilación de datos para el índice. Algunas de ellas forman parte de Windows Search y algunas proceden de aplicaciones de terceros. Si tiene un almacén de datos personalizado o un formato de archivo, Windows Search se basa en el controlador de protocolo y filtra para acceder a las direcciones URL y emitir propiedades para la indexación. Los componentes de Windows Search se muestran en azul y los componentes de terceros se muestran en verde.
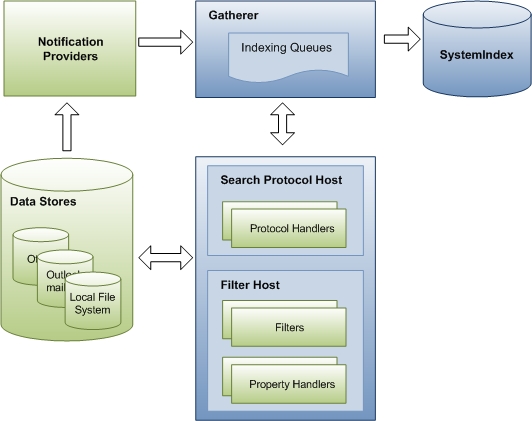
Fase 1: Direcciones URL de puesta en cola para la indexación
En la primera fase de indexación, el recopilador recopila información sobre las actualizaciones de los almacenes de datos, compara esa información con el ámbito de rastreo conocido y, a continuación, crea una cola de direcciones URL para recorrer para recopilar datos para el índice. En el caso de los orígenes que no se basan en la notificación, como las unidades FAT, el recopilador inicia periódicamente un recorrido completo del ámbito de rastreo para que los datos del índice se mantengan actualizados. En el caso de orígenes como NTFS, solo hay un único rastreo y todo lo demás se controla mediante notificaciones del diario de cambios de USN. Tampoco hay rastreo de Microsoft Outlook. En el diagrama siguiente se muestra una vista de alto nivel del proceso de puesta en cola para la indexación que no es de rastreo.
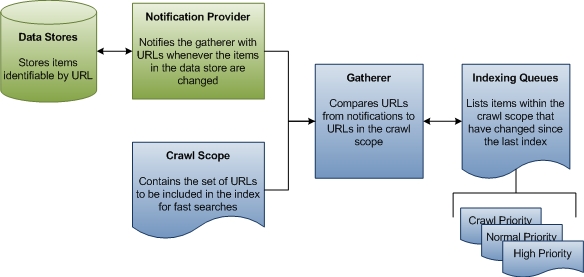
En el resto de esta sección se explica cómo Windows Search determina qué direcciones URL se van a rastrear y define algunos términos importantes a lo largo del proceso.
Ámbito de rastreo El ámbito de rastreo es un conjunto de direcciones URL que windows Search atraviesa para recopilar datos sobre los elementos que el usuario quiere indexar para búsquedas más rápidas. Windows Search agrega algunas direcciones URL al ámbito de rastreo de forma predeterminada, como rutas de acceso a las carpetas Documentos e imágenes de los usuarios. Otras direcciones URL se pueden agregar mediante aplicaciones, usuarios y directiva de grupo de terceros. Por último, tanto los usuarios como los directiva de grupo pueden excluir explícitamente las direcciones URL. Windows Search toma todas las direcciones URL agregadas y quita las direcciones URL excluidas para determinar el ámbito de rastreo. Este es el conjunto de trabajo de direcciones URL desde las que el recopilador comienza su trabajo.
Recolector El recopilador es un componente de Búsqueda de Windows que recopila información sobre las direcciones URL dentro del ámbito de rastreo y crea una cola de direcciones URL para que el indexador se rastree. Cuando se agrega, elimina o actualiza un elemento del ámbito de rastreo, el recopilador recibe las notificaciones del proveedor de notificaciones del almacén de datos. Hay un rastreo inicial donde el recopilador comienza en la raíz del ámbito de rastreo. La dirección URL se pasa al controlador de protocolo y, a continuación, al IFilter adecuado. El filtro suele ser una enumeración de directorios que genera más direcciones URL. Las notificaciones son el estado estable. Normalmente, cada almacén de datos tiene su propio controlador de protocolo que proporciona estas notificaciones. Por ejemplo, en el sistema de archivos local, el Diario de cambios de USN actúa como proveedor de notificaciones para todas las direcciones URL del protocolo file://. De forma similar, Microsoft Outlook actúa como proveedor de notificaciones para todas las direcciones URL en el protocolo mapi://. Cuando un usuario recibe, mueve o elimina el correo electrónico, Outlook notifica al recopilador el estado cambiado del correo electrónico. A partir de estas notificaciones, el recopilador crea colas de indexación de direcciones URL para rastrear.
Indexación de colas Las colas de indexación son listas de direcciones URL que identifican los elementos que deben indexarse o volver a indizarse. El recopilador compara las direcciones URL que recibe de los proveedores de notificaciones a las direcciones URL del ámbito de rastreo. Cada dirección URL de los proveedores de notificaciones que se encuentran dentro del ámbito de rastreo se agrega a una cola que el recopilador usa para priorizar las direcciones URL que se van a procesar a continuación.
Hay tres colas: notificaciones de prioridad alta, notificaciones normales y rastreos periódicos. La cola de prioridad alta es para las notificaciones que se deben procesar inmediatamente. Por ejemplo, cuando un usuario cambia la propiedad de título de un elemento en el Explorador de Windows, la vista Explorador de Windows debe actualizarse inmediatamente después del cambio. La cola de notificaciones normal es para todas las notificaciones de cambio restantes. Las colas de notificación se procesan antes de la cola de rastreo porque es más probable que los elementos modificados sean de interés para un usuario. El recopilador accede a los datos de las direcciones URL de cada cola en el orden primero en salir (FIFO).
Para obtener más información sobre la priorización y las API de eventos introducidas en Windows 7, consulta Indexación de priorización y eventos de conjunto de filas en Windows 7. Para obtener más información sobre la administración y las notificaciones del ámbito de rastreo, consulte Proporcionar notificaciones de cambios y usar el Administrador de ámbitos de rastreo.
Fase 2: Rastreo de direcciones URL
En la segunda fase de la indexación, el recopilador rastrea las colas, el acceso a los almacenes de datos y la recuperación de flujos de elementos. En primer lugar, el recopilador busca el controlador de protocolo adecuado para cada dirección URL. A continuación, el recopilador pasa la dirección URL al controlador de protocolo. El controlador de protocolo accede al elemento y pasa los metadatos del elemento al recopilador. El recopilador usa los metadatos para identificar el filtro correcto.
En el diagrama siguiente se muestra una vista de alto nivel del proceso de rastreo de direcciones URL. Esta fase incluye una coordinación y comunicación considerables entre los componentes.
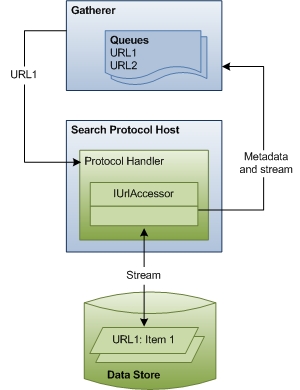
En el resto de esta sección se describe cómo Windows Search accede a los elementos para la indexación y explica los roles de cada uno de los componentes implicados.
Recolector En la fase 2, la fase de rastreo, el recopilador procesa las direcciones URL de las colas, empezando por la cola de alta prioridad. Cada dirección URL se examina para identificar su protocolo. A continuación, el recopilador busca el controlador de protocolo registrado para ese protocolo y lo crea una instancia en el proceso de host del protocolo de búsqueda.
Host de protocolo de búsqueda El host del protocolo de búsqueda es simplemente un proceso de host con conversión boxeada para los controladores de protocolo. Normalmente, Windows Search crea dos procesos de host de este tipo, uno que se ejecuta en el contexto de seguridad del sistema y otro que se ejecuta en el contexto de seguridad del usuario. Esta separación garantiza que los datos específicos de un usuario nunca se ejecuten en el contexto del sistema.
Windows Search también usa el proceso de host para aislar una instancia de un controlador de protocolo de otros procesos o aplicaciones. De este modo, ninguna aplicación externa puede acceder a esa instancia específica del controlador de protocolo y, si el controlador de protocolo produce un error inesperado, solo se ve afectado el proceso de indexación. Dado que el proceso de host ejecuta código de terceros (controladores de protocolo), Windows Search recicla periódicamente el proceso para minimizar el tiempo en que un ataque correcto tiene que aprovechar la información del proceso. Más allá de esto, el host del protocolo de búsqueda no afecta al rastreo de direcciones URL ni a la indexación de elementos.
Controladores de protocolo Los controladores de protocolo proporcionan acceso a los elementos de un almacén de datos mediante el protocolo del almacén de datos. Por ejemplo, el controlador de protocolo NTFS proporciona acceso a los archivos de una unidad local mediante el protocolo file://. El controlador de protocolo sabe cómo recorrer el almacén de datos, identificar elementos nuevos o actualizados y notificar al recopilador. A continuación, cuando se inicia el rastreo, el controlador de protocolo proporciona un objeto IUrlAccessor al recopilador para enlazar a la secuencia subyacente del elemento y devolver metadatos de elemento, como restricciones de seguridad y hora de última modificación.
Nota:
Los controladores de protocolo no son componentes de Windows Search; son componentes del protocolo y el almacén de datos específicos a los que están diseñados para acceder. Si tiene un almacén de datos personalizado que desea indexar, debe implementar un controlador de protocolo. Para obtener más información sobre los controladores de protocolo y cómo implementar uno, consulte Desarrollo de controladores de protocolo.
Metadatos y secuencia Con los metadatos devueltos por el objeto IUrlAccessor del controlador de protocolo, el recopilador identifica el filtro correcto para la dirección URL. El recopilador analiza la extensión de nombre de archivo del elemento y busca el filtro registrado para esa extensión. Si el recopilador no encuentra un filtro, Windows Search usa los metadatos para derivar un conjunto mínimo de información de propiedad del sistema (como System.ItemName) y actualiza el índice. De lo contrario, si el recopilador encuentra el filtro, comienza la tercera fase de indexación.
Fase 3: Actualización del índice
En la tercera fase de indexación, el recopilador crea una instancia del filtro correcto para la dirección URL e inicializa el filtro con la secuencia del objeto IUrlAccessor . A continuación, el filtro obtiene acceso al elemento y devuelve el contenido del índice. Si tiene un formato de archivo personalizado, Windows Search se basa en el filtro para acceder a las direcciones URL y emitir contenido y propiedades para la indexación.
En el diagrama siguiente se muestra una vista general del proceso de acceso a datos. Esta fase incluye una coordinación y comunicación considerables entre los componentes.
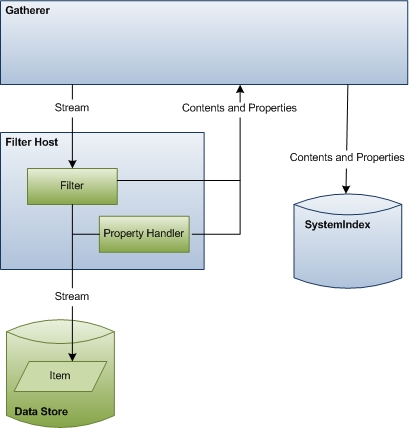
En el resto de esta sección se describe cómo Windows Search accede a los datos de elementos para la indexación y explica los roles de cada uno de los componentes implicados.
Recolector Al principio de esta fase, el rol del recopilador consiste en crear una instancia del filtro correcto para el elemento y pasarlo a la secuencia de elementos. Al final de esta fase, el recopilador toma el contenido y las propiedades emitidos por el controlador de filtros y propiedades y actualiza el índice.
Host de filtro El host de filtro es simplemente un proceso de host para filtros y controladores de propiedades y sirve para un propósito similar al host del protocolo de búsqueda. El proceso de host aísla los filtros y los controladores de propiedades del resto del sistema por las mismas razones de seguridad y estabilidad que los procesos de host de protocolo de búsqueda aíslan los controladores de protocolo. El proceso de host se ejecuta con derechos mínimos (ni siquiera puede acceder al sistema de archivos) y, en ocasiones, se recicla para protegerse frente a ataques de seguridad. Windows Search también supervisa el uso de recursos para que si un filtro consume demasiados recursos, el proceso de host se recicla.
Filtros Los filtros son componentes críticos en el proceso de indexación que emiten información de elementos para el recopilador. Los filtros se denominan después de la interfaz principal usada en su implementación, la interfaz IFilter y, por tanto, a veces se conocen como IFilters . Hay dos tipos de filtros: uno que interactúa con elementos individuales como archivos y otro que interactúa con contenedores como carpetas. Ambos proporcionan datos para el índice.
Con los metadatos devueltos por el objeto IUrlAccessor del controlador de protocolo, el recopilador identifica el filtro correcto para una dirección URL determinada y lo pasa a la secuencia. El recopilador identifica el filtro correcto a través de un controlador de protocolo o mediante la extensión de nombre de archivo, el tipo MIME o el identificador de clase (CLSID). Si la dirección URL apunta a un contenedor, el filtro emite propiedades para el contenedor y enumera los elementos del contenedor (direcciones URL secundarias). Si la dirección URL apunta a un elemento, el filtro devuelve el contenido textual, si alguna lectura de propiedades y es más compleja que los controladores de propiedades. Por lo general, se recomienda que los filtros emitan contenido del elemento mientras los controladores de propiedades emiten propiedades de elemento. Sin embargo, si el filtro necesita trabajar con aplicaciones anteriores que no reconocen controladores de propiedades, también puede implementar el filtro para emitir propiedades.
Nota:
Los filtros no son componentes de Windows Search; son componentes relacionados con el formato de archivo o el contenedor específicos a los que están diseñados para acceder. Para obtener más información sobre los filtros y cómo implementar uno para un formato de archivo personalizado o un contenedor, vea Procedimientos recomendados para crear controladores de filtro en Windows Search.
En la tabla siguiente se enumeran los resultados que el recopilador recibe de un filtro (IFilter) y un controlador de propiedades (IPropertyStore) durante el proceso de indexación.
| Ifilter | IPropertyStore | |
|---|---|---|
| Permitir escritura | No | Sí |
| Combinación de contenido y propiedades | Sí | No |
| Multilingüe | Sí | No |
| Emitir vínculos | Sí | No |
| MIME | Sí | No |
| Límites de texto | Oración, párrafo, capítulo | Ninguna |
| Cliente o servidor | Ambos | Remoto |
| Implementación | Complex | Simple |
Controladores de propiedades Los controladores de propiedades son componentes que leen y escriben propiedades para un formato de archivo determinado. Acceden a elementos y emiten propiedades para el recopilador de la misma manera que los filtros hacen para el contenido. Los controladores de propiedades son más fáciles de implementar que los filtros. Si un formato de archivo basado en texto es muy sencillo o se espera que los archivos sean muy pequeños, el controlador de propiedades puede emitir tanto propiedades como contenido.
Nota:
Los controladores de propiedades no son componentes de Windows Search; son componentes relacionados con el formato de archivo específico al que están diseñados para acceder. Para obtener más información sobre los controladores de propiedades y cómo implementar uno para un formato de archivo personalizado, vea Developing Property Handlers for Windows Search.
Propiedades Windows Search proporciona un sistema de propiedades que incluye una biblioteca grande de propiedades. Cualquier propiedad puede aparecer en cualquier elemento según lo definido por el controlador de filtros o propiedades. Si tiene un formato de archivo personalizado, puede asignar las propiedades del formato de archivo a estas propiedades del sistema y puede crear nuevas propiedades personalizadas. Cuando el controlador de filtros o propiedades emite estas propiedades, el recopilador actualiza el índice para que los usuarios puedan buscar con sus propiedades. Para obtener más información sobre cómo crear y registrar propiedades personalizadas para un formato de archivo, vea Sistema de propiedades.
SystemIndex El índice, denominado SystemIndex, almacena datos indexados y se compone de un almacén de propiedades e índices sobre las propiedades y el contenido de las propiedades del elemento, y un índice invertido para el contenido textual y las propiedades. Una vez que el recopilador actualiza el índice, Windows Search y otras aplicaciones pueden consultar el índice. Para obtener más información sobre las formas de consultar el índice, vea Consultar el índice mediante programación.
Nota:
Recuerde que, al volver a registrar un esquema, es posible que el indexador no respete los cambios realizados en los atributos de las propiedades definidas anteriormente. La solución es recompilar el índice o introducir nuevas propiedades que reflejen los cambios en lugar de actualizar los antiguos (no se recomienda). Para obtener más información, vea Note to Implementers in Properties System Overview.
Cómo se programa la indexación
Cuando Windows Search se instala por primera vez, realiza una indexación completa del ámbito de rastreo, pausando durante períodos de actividad alta de E/S y usuario. El ámbito de rastreo predeterminado consta de las ubicaciones de biblioteca predeterminadas, como Documentos, Música, Imágenes y Vídeos. Las notificaciones se procesan incluso antes de que finalice el rastreo inicial. En ocasiones, el recopilador rastrea las direcciones URL del ámbito de rastreo completo. Estos rastreos completos garantizan que los datos del índice estén actualizados. Por ejemplo, si un proveedor de notificaciones no puede enviar notificaciones o si el servicio Search de Windows finaliza inesperadamente, el recopilador no tendría conocimiento de elementos nuevos o modificados y no indexaría estos elementos. Hay dos tipos de orígenes: solo notificación y notificación habilitada. En ambos orígenes, el recopilador rastrea inicialmente el índice. Después del rastreo inicial, los orígenes de solo notificación nunca volverán a realizar un rastreo completo a menos que se produzca un error, como el diario de cambios de USN . Los orígenes habilitados para notificaciones realizan un rastreo incremental cuando se inicia el indexador, pero luego escuchan las notificaciones mientras se ejecutan. NTFS y Microsoft Outlook solo son notificaciones. Internet Explorer y FAT están habilitadas para notificaciones.
Notas a los implementadores
La calidad de los datos del índice y la eficacia del proceso de indexación dependen en gran medida de la implementación del controlador de propiedades y filtros. Dado que se llama al filtro cada vez que una dirección URL identifica el formato de archivo, el proceso de indexación puede ralentizarse drásticamente si el filtro es ineficaz. Si el controlador de propiedades no asigna correctamente todas las propiedades de archivo a las propiedades del sistema o no emite correctamente estas propiedades, los datos del índice serán incorrectos y las búsquedas posteriores de esas propiedades devolverán resultados incorrectos. Si se produce un error en el controlador de filtros o propiedades, el indexador no podrá indexar los datos.
Las aplicaciones y los procesos distintos de Windows Search se basan en controladores de protocolo, filtros y controladores de propiedades. Las implementaciones pueden afectar a esas aplicaciones de maneras que es posible que no espere. La Guía de desarrollo de Windows Search proporciona consejos sobre las opciones de diseño y las pruebas de cada uno de estos componentes.
Temas relacionados
Indexación, consulta y notificaciones en Windows Search
Proceso de consulta en Windows Search