Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
SE APLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Data Factory en Microsoft Fabric es la próxima generación de Azure Data Factory, con una arquitectura más sencilla, inteligencia artificial integrada y nuevas características. Si no está familiarizado con la integración de datos, comience con Fabric Data Factory. Las cargas de trabajo de ADF existentes pueden actualizarse a Fabric para acceder a nuevas funcionalidades en ciencia de datos, análisis en tiempo real e informes.
La actividad MapReduce de HDInsight en una canalización de Azure Data Factory o Synapse Analytics invoca el programa MapReduce en su propio clúster de HDInsight o en un clúster a petición. Este artículo se basa en el artículo sobre actividades de transformación de datos , que presenta información general de la transformación de datos y las actividades de transformación admitidas.
Para obtener más información, lea los artículos de introducción de Azure Data Factory y Synapse Analytics y realice el tutorial: Tutorial: transformar datos antes de leer este artículo.
Consulte Pig y Hive para obtener detalles sobre cómo ejecutar scripts de Pig/Hive en un clúster de HDInsight desde una canalización, utilizando actividades de Pig y Hive en HDInsight.
Adición de una actividad de MapReduce de HDInsight a una canalización con interfaz de usuario
Para usar una actividad de MapReduce de HDInsight en una canalización, complete los pasos siguientes:
Busque MapReduce en el panel Actividades de canalización y arrastre una actividad de MapReduce al lienzo de canalización.
Seleccione la nueva actividad de MapReduce en el lienzo si aún no lo ha hecho.
Seleccione la pestaña HDI Cluster (Clúster de HDI) para elegir o crear un servicio vinculado a un clúster de HDInsight que se usará para ejecutar la actividad de MapReduce.
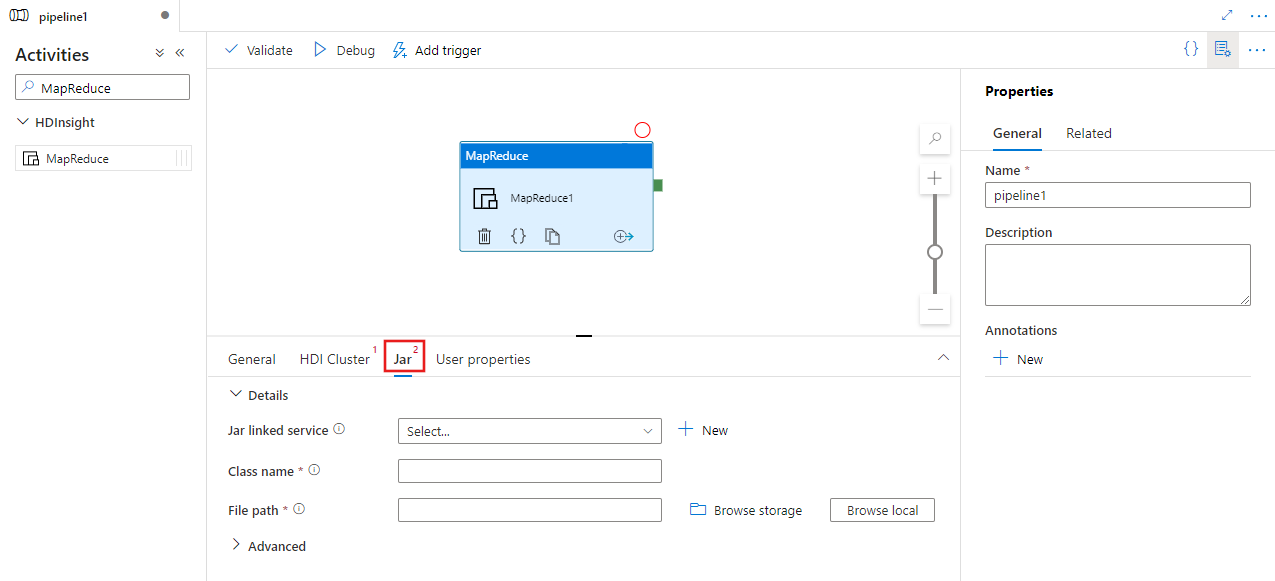
Seleccione la pestaña Jar para seleccionar o crear un nuevo servicio vinculado Jar en una cuenta de Azure Storage que hospedará el script. Especifique el nombre de clase que se va a ejecutar en esa ubicación y una ruta de acceso de archivo dentro de la ubicación de almacenamiento. También puede configurar detalles avanzados, como la ubicación de las bibliotecas Jar, la configuración de depuración y los argumentos y parámetros que se pasarán al script.
Sintaxis
{
"name": "Map Reduce Activity",
"description": "Description",
"type": "HDInsightMapReduce",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"className": "org.myorg.SampleClass",
"jarLinkedService": {
"referenceName": "MyAzureStorageLinkedService",
"type": "LinkedServiceReference"
},
"jarFilePath": "MyAzureStorage/jars/sample.jar",
"getDebugInfo": "Failure",
"arguments": [
"-SampleHadoopJobArgument1"
],
"defines": {
"param1": "param1Value"
}
}
}
Detalles de la sintaxis
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| nombre | Nombre de la actividad | Sí |
| descripción | Texto que describe para qué se usa la actividad. | No |
| tipo | Para la actividad MapReduce, el tipo de actividad es HDinsightMapReduce. | Sí |
| nombreDelServicioVinculado | Referencia al clúster de HDInsight registrado como servicio vinculado. Para obtener más información sobre este servicio vinculado, consulte el artículo Servicios vinculados de cómputo. | Sí |
| className | Nombre de la clase que se va a ejecutar | Sí |
| jarLinkedService | Referencia a un servicio vinculado de Azure Storage usado para almacenar los archivos Jar. Aquí solo se admiten los servicios vinculados Azure Blob Storage y ADLS Gen2. Si no especifica este servicio vinculado, se usará el servicio vinculado de Azure Storage definido en el servicio vinculado de HDInsight. | No |
| jarFilePath | Proporcione la ruta de acceso a los archivos Jar almacenados en el Azure Storage al que hace referencia jarLinkedService. El nombre del archivo es sensible a mayúsculas y minúsculas. | Sí |
| jarlibs | Matriz de cadenas de la ruta de acceso a los archivos de biblioteca Jar a los que hace referencia el trabajo almacenado en el Azure Storage definido en jarLinkedService. El nombre del archivo es sensible a mayúsculas y minúsculas. | No |
| getDebugInfo | Especifica cuándo se copian los archivos de registro en el Azure Storage usado por el clúster de HDInsight (o) especificado por jarLinkedService. Valores permitidos: Ninguno, Siempre o Error. Valor predeterminado: Ninguno. | No |
| argumentos | Especifica una matriz de argumentos para un trabajo de Hadoop. Los argumentos se pasan a cada tarea como línea de comandos. | No |
| defines | Especifique parámetros como pares clave-valor para hacer referencia en el script de Hive. | No |
Ejemplo
Puede usar la actividad MapReduce de HDInsight para ejecutar cualquier archivo jar de MapReduce en un clúster de HDInsight. En la siguiente definición de JSON de ejemplo de una canalización, la actividad de HDInsight se configura para ejecutar un archivo JAR de Mahout.
{
"name": "MapReduce Activity for Mahout",
"description": "Custom MapReduce to generate Mahout result",
"type": "HDInsightMapReduce",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"className": "org.apache.mahout.cf.taste.hadoop.similarity.item.ItemSimilarityJob",
"jarLinkedService": {
"referenceName": "MyStorageLinkedService",
"type": "LinkedServiceReference"
},
"jarFilePath": "adfsamples/Mahout/jars/mahout-examples-0.9.0.2.2.7.1-34.jar",
"arguments": [
"-s",
"SIMILARITY_LOGLIKELIHOOD",
"--input",
"wasb://adfsamples@spestore.blob.core.windows.net/Mahout/input",
"--output",
"wasb://adfsamples@spestore.blob.core.windows.net/Mahout/output/",
"--maxSimilaritiesPerItem",
"500",
"--tempDir",
"wasb://adfsamples@spestore.blob.core.windows.net/Mahout/temp/mahout"
]
}
}
Puede especificar los argumentos para el programa MapReduce en la sección arguments. En tiempo de ejecución, verá unos argumentos adicionales (por ejemplo, mapreduce.job.tags) desde el marco de trabajo MapReduce. Para diferenciar sus argumentos con los argumentos de MapReduce, considere el uso tanto de opción como de valor como argumentos, tal como se muestra en el siguiente ejemplo (-s, --input, --output, etc., son opciones seguidas inmediatamente por sus valores).
Contenido relacionado
Vea los siguientes artículos, en los que se explica cómo transformar datos de otras maneras: