Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
SE APLICA A: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Sugerencia
Data Factory en Microsoft Fabric es la próxima generación de Azure Data Factory, con una arquitectura más sencilla, inteligencia artificial integrada y nuevas características. Si no está familiarizado con la integración de datos, comience con Fabric Data Factory. Las cargas de trabajo de ADF existentes pueden actualizarse a Fabric para acceder a nuevas funcionalidades en ciencia de datos, análisis en tiempo real e informes.
La preparación de datos implica transformar y reformatar los datos desde su origen para que sean más adecuados y útiles para varias aplicaciones posteriores.
Las organizaciones deben poder explorar sus datos empresariales críticos para prepararlos y manejarlos con el fin de proporcionar un análisis preciso de los datos complejos que crecen cada día. La preparación de datos es necesaria para que las organizaciones puedan usar los datos en diversos procesos empresariales y reducir el plazo de amortización.
Data Factory le permite preparar datos sin código a escala en la nube de forma iterativa mediante Power Query. Data Factory se integra con Power Query Online y hace que las funciones M de Power Query estén disponibles como una actividad de canalización.
Data Factory traduce M generado por el editor de Mashup en línea de Power Query en código spark para la ejecución de escala en la nube mediante la traducción de M a flujos de datos de Azure Data Factory. La limpieza de datos con Power Query y flujos de datos es especialmente útil para ingenieros de datos o "integradores de datos ciudadanos".
Casos de uso
Exploración y preparación rápidas de datos interactivos
Varios ingenieros de datos e integradores de datos de ciudadanos pueden explorar y preparar interactivamente conjuntos de datos a escala de nube. Con el aumento del volumen, la variedad y la velocidad de los datos en los lagos de datos, los usuarios necesitan una manera eficaz de explorar y preparar los conjuntos de datos. Por ejemplo, puede que necesite crear un conjunto de datos que "tenga toda la información demográfica de los clientes para los nuevos clientes desde 2017". No está asignando a un destino conocido. Está explorando, limpiando y transformando, y preparando los conjuntos de datos para que cumplan un requisito antes de publicarlos en el lago. La manipulación de datos se utiliza a menudo en escenarios de análisis menos formales. Los conjuntos de datos preparados se pueden usar para realizar transformaciones y operaciones de aprendizaje automático de nivel inferior.
Preparación de datos ágil sin código
Los integradores de datos de los ciudadanos invierten más del 60 % de su tiempo en buscar y preparar los datos. Buscan hacerlo sin código para mejorar la productividad operativa. Permitir a los integradores de datos ciudadanos enriquecer, dar forma y publicar datos mediante herramientas conocidas como Power Query Online de forma escalable mejora drásticamente su productividad. El procesamiento en Azure Data Factory habilita el familiar editor de mashup de Power Query Online para que los integradores de datos ciudadanos puedan corregir rápidamente errores, estandarizar datos y producir datos de alta calidad para respaldar decisiones empresariales.
Exploración y validación de datos
Analice visualmente los datos sin código para quitar los valores atípicos y las anomalías, y hacer que cumplan con una forma para el análisis rápido.
Fuentes admitidas
| Conector | Formato de datos | Tipo de autenticación |
|---|---|---|
| Azure Blob Storage | CSV, Parquet, Excel | Clave de cuenta, entidad de servicio, MSI |
| Azure Data Lake Storage Gen1 | CSV, Parquet, Excel | Principal de servicio, MSI |
| Azure Data Lake Storage Gen2 | CSV, Parquet, Excel | Clave de cuenta, entidad de servicio, MSI |
| Azure SQL Database | - | Autenticación SQL, MSI, entidad de servicio |
| Azure Synapse Analytics | - | Autenticación SQL, MSI, entidad de servicio |
Editor de mashup
Al crear una actividad de Power Query, todos los conjuntos de datos de origen se convierten en consultas de conjuntos de datos y se colocan en la carpeta ADFResource. De forma predeterminada, UserQuery apuntará a la primera consulta del conjunto de datos. Todas las transformaciones deben realizarse en UserQuery, ya que no se admiten ni se conservan los cambios en las consultas del conjunto de datos. Actualmente no se admiten las opciones para cambiar el nombre o agregar y eliminar consultas.
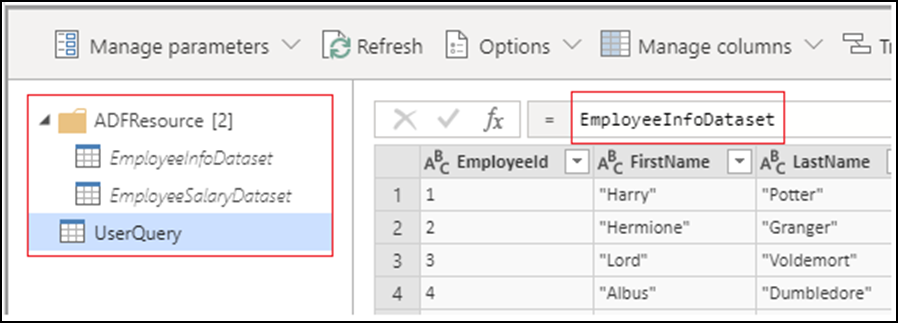
Actualmente no se admiten todas las funciones de Power Query M para la limpieza y transformación de datos, a pesar de estar disponibles durante la creación. Al compilar las actividades de Power Query, se le pedirá el siguiente mensaje de error si no se admite una función:
The Power Query Spark Runtime does not support the function
Para obtener más información sobre las transformaciones admitidas, consulte Power Query funciones de limpieza de datos.
Contenido relacionado
Obtenga información sobre cómo crear una consola de combinación de Power Query para la limpieza y transformación de datos.