Tutorial: Uso de Azure Functions y Python para procesar documentos almacenados
Se puede usar Document Intelligence como parte de una canalización de procesamiento de datos automatizada que haya compilado con Azure Functions. En esta guía se muestra cómo usar Azure Functions para procesar documentos que se han cargado en un contenedor de Azure Blob Storage. Este flujo de trabajo extrae datos de tabla de los documentos almacenados mediante el modelo de diseño de Document Intelligence y guarda los datos de la tabla en un archivo .csv en Azure. A continuación, puede mostrar los datos mediante Microsoft Power BI (no se explica en este documento).

En este tutorial aprenderá a:
- Cree una cuenta de Azure Storage.
- Cree un proyecto de Azure Functions.
- Extraer datos del diseño de los formularios cargados.
- Cargar datos extraídos del diseño en Azure Storage.
Prerrequisitos
Una suscripción a Azure - Cree una de forma gratuita
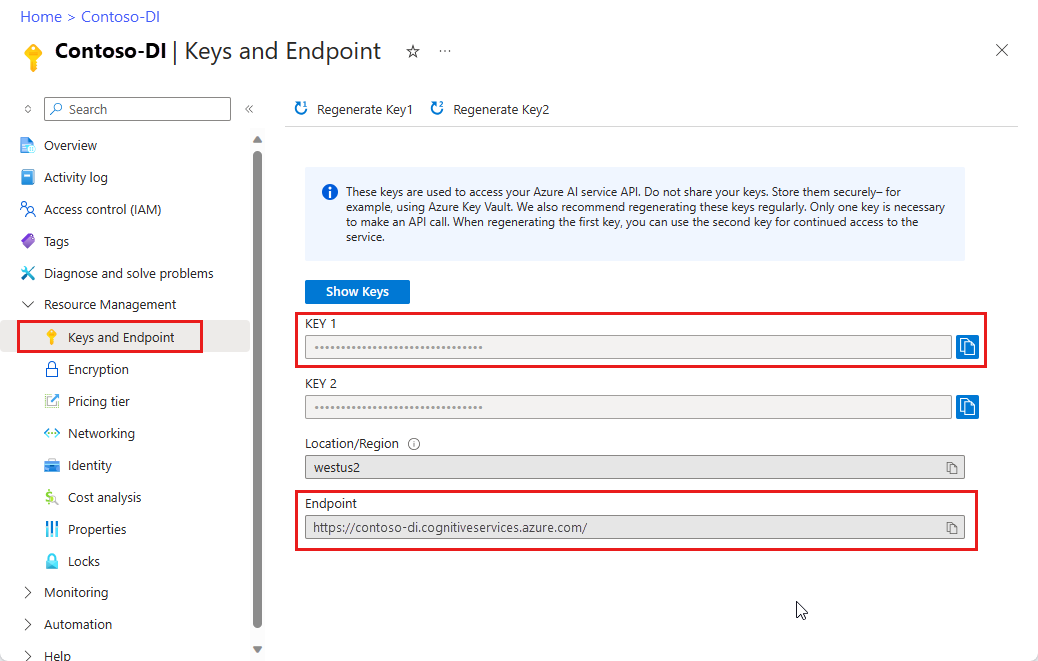
Un recurso de Document Intelligence. Una vez que tenga la suscripción de Azure,cree un recurso de Document Intelligence en Azure Portal para obtener la clave y el punto de conexión. Puede usar el plan de tarifa gratis (
F0) para probar el servicio y actualizarlo más adelante a un plan de pago para producción.Una vez implementado el recurso, seleccione Ir al recurso. Necesitará la clave y el punto de conexión del recurso que ha creado para conectar la aplicación a la API de Document Intelligence. En una sección posterior de este mismo tutorial, pegará la clave y el punto de conexión en el código siguiente:
Python 3.6.x, 3.7.x, 3.8.x o 3.9.x (Python 3.10.x no se admite para este proyecto).
La versión más reciente de Visual Studio Code (VS Code) con las siguientes extensiones instaladas:
Extensión de Azure Functions. Tras la instalación, debería ver el logotipo de Azure en el panel de navegación izquierdo.
Azure Functions Core Tools versión 3.x (la versión 4.x no es compatible con este proyecto).
Extensión de Python para Visual Studio Code. Para más información, vea Introducción a Python en VS Code
Explorador de Azure Storage instalado.
Un documento PDF local que analizará. Puede usar nuestro documento PDF de ejemplo para este proyecto.
Creación de una cuenta de Azure Storage
Cree una cuenta de Azure Storage de uso general v2 en Azure Portal. Si no sabe cómo crear una cuenta de almacenamiento de Azure con un contenedor de almacenamiento, siga estos inicios rápidos:
- Crear una cuenta de almacenamiento. Al crear la cuenta de almacenamiento, seleccione el rendimiento Estándar en el campo Detalles de instancia>Rendimiento.
- Cree un contenedor. Al crear un contenedor, establezca Nivel de acceso público en Contenedor (acceso de lectura anónimo para contenedores y archivos) en la ventana Nuevo contenedor.
En el panel izquierdo, seleccione la pestaña Uso compartido de recursos (CORS) y quite la directiva CORS existente, si hay alguna.
Una vez implementada la cuenta de almacenamiento, cree dos contenedores de almacenamiento de blobs vacíos, con los nombres input y output.
Creación de un proyecto de Azure Functions
Cree una carpeta denominada functions-app para contener el proyecto y elija Seleccionar.
Abra Visual Studio Code y abra la paleta de comandos (Ctrl+Mayús+P). Busque y elija Python:Select Interpreter → elija un intérprete de Python instalado que tenga la versión 3.6.x, 3.7.x, 3.8.x o 3.9.x. Esta selección agregará la ruta de acceso del intérprete de Python seleccionada al proyecto.
Seleccione el logotipo de Azure en el panel de navegación izquierdo.
Verá los recursos de Azure existentes en la vista Recursos.
Seleccione la suscripción de Azure que usa para este proyecto; posteriormente, debería ver la aplicación de funciones de Azure.

Seleccione la sección Área de trabajo (local) que se encuentra debajo de los recursos enumerados. Seleccione el símbolo más y elija el botón Crear función.

Cuando se le solicite, elija Crear nuevo proyecto y vaya al directorio function-app. Elija Seleccionar.
Se le pedirá que configure varios valores:
Seleccione un lenguaje → elija Python.
Seleccione un intérprete de Python para crear un entorno virtual → seleccione el intérprete que estableció como valor predeterminado anteriormente.
Seleccione una plantilla → elija el desencadenador de Azure Blob Storage y asígnele un nombre o acepte el nombre predeterminado. Presione Entrar para confirmar.
Seleccione un valor → elija ➕Crear nuevo valor de aplicación local en el menú desplegable.
Seleccione una suscripción → elija la suscripción de Azure con la cuenta de almacenamiento que creó → seleccione la cuenta de almacenamiento →, posteriormente, seleccione el nombre del contenedor de entrada de almacenamiento (en este caso,
input/{name}). Presione Entrar para confirmar.Seleccione cómo quiere abrir el proyecto → elija Abrir el proyecto en la ventana actual en el menú desplegable.
Cuando haya completado estos pasos, VS Code agregará un nuevo proyecto de Azure Functions con un script de Python __init__.py. Este script se desencadenará cuando se cargue un archivo en el contenedor de almacenamiento test:
import logging
import azure.functions as func
def main(myblob: func.InputStream):
logging.info(f"Python blob trigger function processed blob \n"
f"Name: {myblob.name}\n"
f"Blob Size: {myblob.length} bytes")
Probar la función
Presione F5 para ejecutar la función básica. VS Code le pedirá que seleccione una cuenta de almacenamiento con la que interactuar.
Seleccione la cuenta de almacenamiento que ha creado y continúe.
Abra el Explorador de Azure Storage y cargue el documento PDF de ejemplo en el contenedor input. Posteriormente, compruebe el terminal de VS Code. El script debe registrar que la carga del archivo PDF lo desencadenó.

Detenga el script antes de continuar.
Incorporación de código de procesamiento de documentos
A continuación, agregará su propio código al script de Python para llamar al servicio de Document Intelligence y analizar los documentos cargados mediante el modelo de diseño de Document Intelligence.
En VS Code, navegue hasta el archivo requirements.txt de la función. Este archivo define las dependencias para el script. Agregue los siguientes paquetes de Python al archivo:
cryptography azure-functions azure-storage-blob azure-identity requests pandas numpyA continuación, abra el script __init__.py. Agregue las instrucciones siguientes
import:import logging from azure.storage.blob import BlobServiceClient import azure.functions as func import json import time from requests import get, post import os import requests from collections import OrderedDict import numpy as np import pandas as pdPuede dejar la función
maingenerada tal cual está. Agregará el código personalizado dentro de esta función.# This part is automatically generated def main(myblob: func.InputStream): logging.info(f"Python blob trigger function processed blob \n" f"Name: {myblob.name}\n" f"Blob Size: {myblob.length} bytes")El siguiente bloque de código llama a la API de análisis de diseño de Document Intelligence en el documento cargado. Rellene los valores de punto de conexión y clave.
# This is the call to the Document Intelligence endpoint endpoint = r"Your Document Intelligence Endpoint" apim_key = "Your Document Intelligence Key" post_url = endpoint + "/formrecognizer/v2.1/layout/analyze" source = myblob.read() headers = { # Request headers 'Content-Type': 'application/pdf', 'Ocp-Apim-Subscription-Key': apim_key, } text1=os.path.basename(myblob.name)Importante
Recuerde quitar la clave del código cuando haya terminado y no hacerla nunca pública. En el caso de producción, use una forma segura de almacenar sus credenciales y acceder a ellas, como Azure Key Vault. Para obtener más información, consulteSeguridad de servicios de Azure AI.
A continuación, agregue el código para consultar al servicio y obtener los datos devueltos.
resp = requests.post(url=post_url, data=source, headers=headers) if resp.status_code != 202: print("POST analyze failed:\n%s" % resp.text) quit() print("POST analyze succeeded:\n%s" % resp.headers) get_url = resp.headers["operation-location"] wait_sec = 25 time.sleep(wait_sec) # The layout API is async therefore the wait statement resp = requests.get(url=get_url, headers={"Ocp-Apim-Subscription-Key": apim_key}) resp_json = json.loads(resp.text) status = resp_json["status"] if status == "succeeded": print("POST Layout Analysis succeeded:\n%s") results = resp_json else: print("GET Layout results failed:\n%s") quit() results = resp_jsonAgregue el siguiente código para conectarse al contenedor output de Azure Storage. Escriba sus propios valores para el nombre y la clave de la cuenta de almacenamiento. Puede obtener la clave en la pestaña Claves de acceso del recurso de almacenamiento en Azure Portal.
# This is the connection to the blob storage, with the Azure Python SDK blob_service_client = BlobServiceClient.from_connection_string("DefaultEndpointsProtocol=https;AccountName="Storage Account Name";AccountKey="storage account key";EndpointSuffix=core.windows.net") container_client=blob_service_client.get_container_client("output")El código siguiente analiza la respuesta que devuelve Document Intelligence, crea un archivo. csv y lo carga en el contenedor de salida.
Importante
Probablemente tendrá que editar este código para que coincida con la estructura de sus documentos.
# The code below extracts the json format into tabular data. # Please note that you need to adjust the code below to your form structure. # It probably won't work out-of-the-box for your specific form. pages = results["analyzeResult"]["pageResults"] def make_page(p): res=[] res_table=[] y=0 page = pages[p] for tab in page["tables"]: for cell in tab["cells"]: res.append(cell) res_table.append(y) y=y+1 res_table=pd.DataFrame(res_table) res=pd.DataFrame(res) res["table_num"]=res_table[0] h=res.drop(columns=["boundingBox","elements"]) h.loc[:,"rownum"]=range(0,len(h)) num_table=max(h["table_num"]) return h, num_table, p h, num_table, p= make_page(0) for k in range(num_table+1): new_table=h[h.table_num==k] new_table.loc[:,"rownum"]=range(0,len(new_table)) row_table=pages[p]["tables"][k]["rows"] col_table=pages[p]["tables"][k]["columns"] b=np.zeros((row_table,col_table)) b=pd.DataFrame(b) s=0 for i,j in zip(new_table["rowIndex"],new_table["columnIndex"]): b.loc[i,j]=new_table.loc[new_table.loc[s,"rownum"],"text"] s=s+1Por último, el último bloque de código carga la tabla y los datos de texto que se extrajeron en el elemento de almacenamiento de blobs.
# Here is the upload to the blob storage tab1_csv=b.to_csv(header=False,index=False,mode='w') name1=(os.path.splitext(text1)[0]) +'.csv' container_client.upload_blob(name=name1,data=tab1_csv)
Ejecución de la función
Presione F5 para ejecutar la función nuevamente.
Use el Explorador de Azure Storage para cargar un formulario PDF de ejemplo en el contenedor de almacenamiento input. Esta acción debe desencadenar la ejecución del script y, a continuación, se deberá mostrar el archivo .csv resultante (mostrado como una tabla) en el contenedor output.
Puede conectar este contenedor a Power BI para crear visualizaciones enriquecidas de los datos que contiene.
Pasos siguientes
En este tutorial, aprendió a usar una función de Azure escrita en Python para procesar automáticamente los documentos PDF cargados y devolver el contenido con un formato más fácil de usar. A continuación, obtenga información sobre cómo usar Power BI para mostrar esos datos.
- ¿Qué es Document Intelligence?
- Más información acerca del modelo de diseño