¿Qué es un lago de datos?
Un lago de datos es un repositorio de almacenamiento que contiene una gran cantidad de datos en su formato nativo y sin procesar. Los lagos de datos están optimizados para escalar a terabytes y petabytes de datos. Los datos provienen típicamente de múltiples orígenes heterogéneos y pueden ser estructurados, semiestructurados o no estructurados. La idea con los lagos de datos es almacenar todo en su estado original, no transformado. Este enfoque difiere del almacenamiento de datos tradicional, que transforma y procesa los datos en el momento de la ingesta.
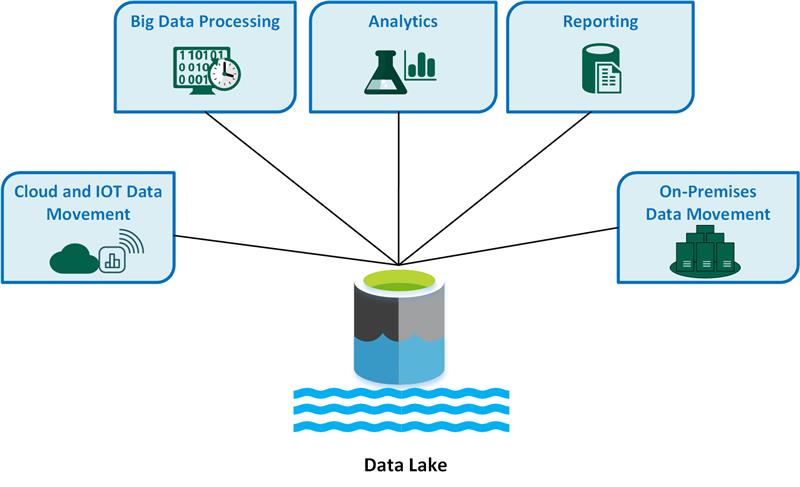
A continuación se muestran los casos de uso clave de lago de datos:
- Movimiento de datos en la nube y IoT
- Procesamiento de macrodatos
- Análisis
- Generación de informes
- Movimiento de datos locales
Ventajas de un lago de datos:
- Los datos nunca se desechan, porque se almacenan en su formato sin procesar. Esto es especialmente útil en un entorno de macrodatos, cuando es posible que no se conozca de antemano qué información está disponible a partir de los datos.
- Los usuarios pueden explorar los datos y crear sus propias consultas.
- Puede ser más rápido que las herramientas de extracción, transformación y carga de datos tradicionales.
- Es más flexible que un almacenamiento de datos, porque puede almacenar datos no estructurados y semiestructurados.
Una solución completa de lagos de datos consta de almacenamiento y procesamiento. El almacenamiento del lago de datos está diseñado para la tolerancia a errores, una escalabilidad infinita e ingesta de datos de alto rendimiento con diferentes formas y tamaños. El procesamiento del lago de datos implica uno o varios motores de procesamiento creados teniendo en cuenta estos objetivos y pueden operar en los datos almacenados en un lago de datos a escala.
Cuándo usar un lago de datos
Entre los usos típicos de un lago de datos se incluye la exploración de datos, el análisis de datos y el aprendizaje automático.
Un lago de datos también puede actuar como origen de datos para un almacenamiento de datos. Con este enfoque, los datos sin procesar se ingieren en el lago de datos y, después, se transforman en un formato estructurado consultable. Normalmente, esta transformación usa una canalización ETL (extracción, carga y transformación), donde los datos se ingieren y se transforman en su lugar. Los datos de origen que ya son relacionales pueden ir directamente al almacenamiento de datos, mediante un proceso ETL, omitiendo el lago de datos.
Los almacenes del lago de datos a menudo se usan en streaming de eventos o en escenarios de IoT, porque pueden guardar grandes cantidades de datos relacionales y no relacionales sin transformación o definición de esquema. Se crean para controlar grandes volúmenes de pequeñas operaciones de escritura en una latencia baja y se optimizan para que el rendimiento sea masivo.
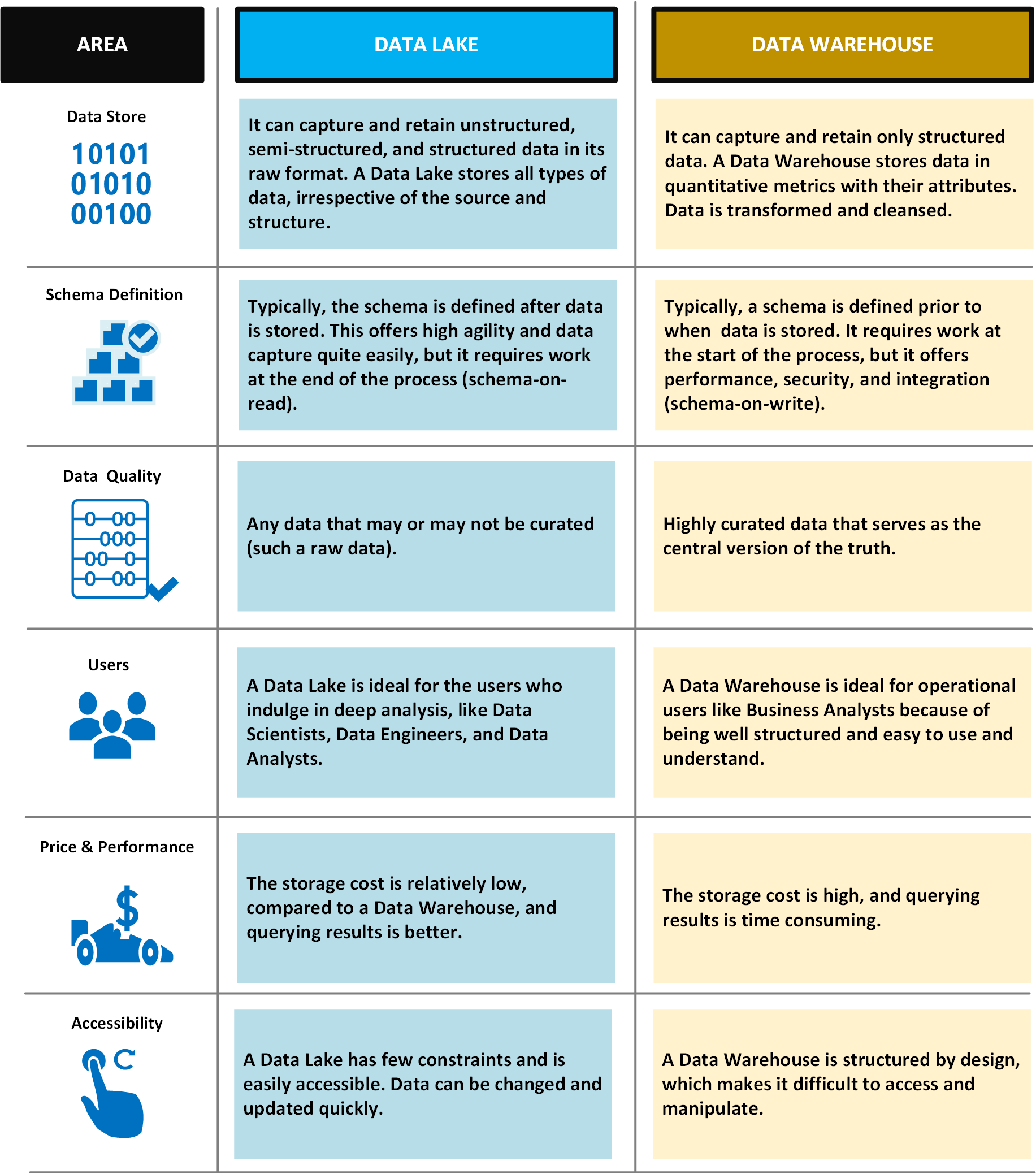
En la tabla siguiente se comparan lagos de datos y almacenamientos de datos:
Desafíos
- La falta de un esquema o de metadatos descriptivos puede hacer que los datos sean difíciles de consumir o de consultar.
- La falta de coherencia semántica en los datos puede dificultar la realización de análisis de los mismos, a menos que los usuarios estén altamente capacitados en analítica de datos.
- Puede ser difícil garantizar la calidad de los datos que entran en el lago de datos.
- Sin una gobernanza adecuada, el control del acceso y las cuestiones de privacidad pueden constituir problemas. ¿Qué información está entrando en el lago de datos, quién puede acceder a esos datos y para qué usos?
- Es posible que un lago de datos no sea la mejor forma de integrar datos que ya son relacionales.
- Por sí solo, un lago de datos no proporciona vistas integradas u holísticas a través de la organización.
- Un lago de datos puede convertirse en un volcado de datos que nunca se analiza o se extrae para obtener información.
Opciones de tecnología
Cree soluciones de lago de datos con los siguientes servicios ofrecidos por Azure:
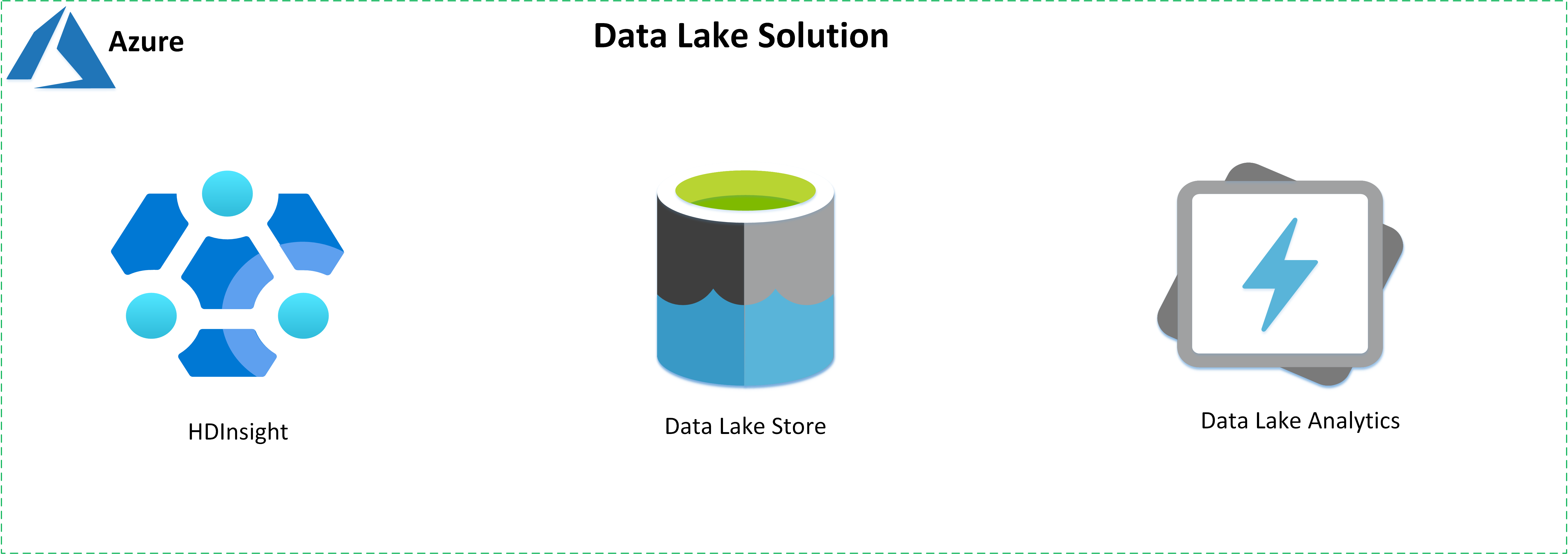
- Azure HDInsight es un servicio de análisis, de código abierto, espectro completo y administrado en la nube para empresas.
- Azure Data Lake Store es un repositorio de hiperescala compatible con Hadoop.
- Azure Data Lake Analytics es un servicio de trabajos de análisis a petición que simplifica el análisis de macrodatos.
Colaboradores
Microsoft mantiene este artículo. Originalmente lo escribieron los siguientes colaboradores.
Autor principal:
- Avijit Prasad | Consultor de la nube
Pasos siguientes
- ¿Qué es Azure HDInsight?
- Introducción a Azure Data Lake Storage
- Documentación de Azure Data Lake Analytics
- Introducción a Azure Data Lake Storage (módulo de entrenamiento)
- ¿Qué es un lago de datos?
Recursos relacionados
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente las Cuestiones de GitHub como mecanismo de retroalimentación para el contenido y lo sustituiremos por un nuevo sistema de retroalimentación. Para más información, consulta: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de