El procesamiento de lenguaje natural (NLP) tiene muchos usos: el análisis de sentimiento, la detección de temas, la detección de idioma, la extracción de frases clave y la clasificación de documentos.
En concreto, el procesamiento de lenguaje natural se puede usar para:
- Clasificar documentos. Por ejemplo, es posible etiquetar documentos como confidenciales o no deseados.
- Realizar búsquedas o procesamiento a posteriori. La salida del procesamiento de lenguaje natural se puede usar para estos fines.
- Resumir texto mediante la identificación de las entidades que están presentes en el documento.
- Etiquetar documentos con palabras clave. Para las palabras clave, el procesamiento de lenguaje natural puede usar entidades identificadas.
- Realizar búsquedas y recuperaciones basadas en contenido. Esta funcionalidad es posible gracias al etiquetado.
- Resumir los temas importantes de un documento. El procesamiento de lenguaje natural puede combinar las entidades identificadas para formar temas.
- Clasificar documentos para facilitar el desplazamiento por ellos. Para ello, el procesamiento de lenguaje natural usa los temas detectados.
- Enumerar documentos relacionados basados en un tema seleccionado. Para ello, el procesamiento de lenguaje natural usa los temas detectados.
- Puntuar texto en función de la opinión. Esta funcionalidad permite evaluar el tono positivo o negativo de un documento.
Apache®, Apache Spark y el logotipo de la llama son marcas registradas o marcas comerciales de Apache Software Foundation en Estados Unidos y otros países. El uso de estas marcas no implica la aprobación de Apache Software Foundation.
Posibles casos de uso
Entre los escenarios empresariales que pueden beneficiarse del procesamiento de lenguaje natural personalizado se incluyen:
- Inteligencia de documentos para documentos manuscritos o creados por máquinas en el sector financiero, de atención sanitaria, comercio minorista, gobierno y otros sectores.
- Tareas del procesamiento de lenguaje natural independientes del sector para el procesamiento de texto, como el reconocimiento de entidades de nombres (NER), la clasificación, la creación de resúmenes y la extracción de relaciones. Estas tareas automatizan el proceso de recuperación, identificación y análisis de la información de los documentos, como el texto y los datos no estructurados. Algunos ejemplos de estas tareas incluyen los modelos de estratificación de riesgos, la clasificación ontológica y los resúmenes comerciales.
- Creación de grafos de conocimientos y recuperación de información para la búsqueda semántica. Esta funcionalidad permite crear grafos de conocimientos médicos que admitan el descubrimiento de fármacos y los ensayos clínicos.
- La traducción del texto de sistemas de inteligencia artificial conversacional en aplicaciones orientadas al cliente en los sectores minorista, financiero y de viajes, entre otros.
Apache Spark como marco del procesamiento del lenguaje natural personalizado
Apache Spark es una plataforma de procesamiento paralelo que admite el procesamiento en memoria para mejorar el rendimiento de aplicaciones de análisis de macrodatos. Azure Synapse Analytics, Azure HDInsight y Azure Databricks ofrecen acceso a Spark y aprovechan su potencia de procesamiento.
En el caso de las cargas de trabajo del NLP personalizadas, Spark NLP sirve como marco eficaz para procesar una gran cantidad de texto. Esta biblioteca de NLP de código abierto proporciona bibliotecas de Python, Java y Scala que ofrecen toda la funcionalidad de las bibliotecas de NLP tradicionales, como spaCy, NLTK, Stanford CoreNLP y Open NLP. Spark NLP también ofrece funcionalidades como la revisión ortográfica, el análisis de sentimiento y la clasificación de documentos. Spark NLP supone una mejora con respecto a los esfuerzos anteriores, ya que proporciona precisión, velocidad y escalabilidad de última generación.
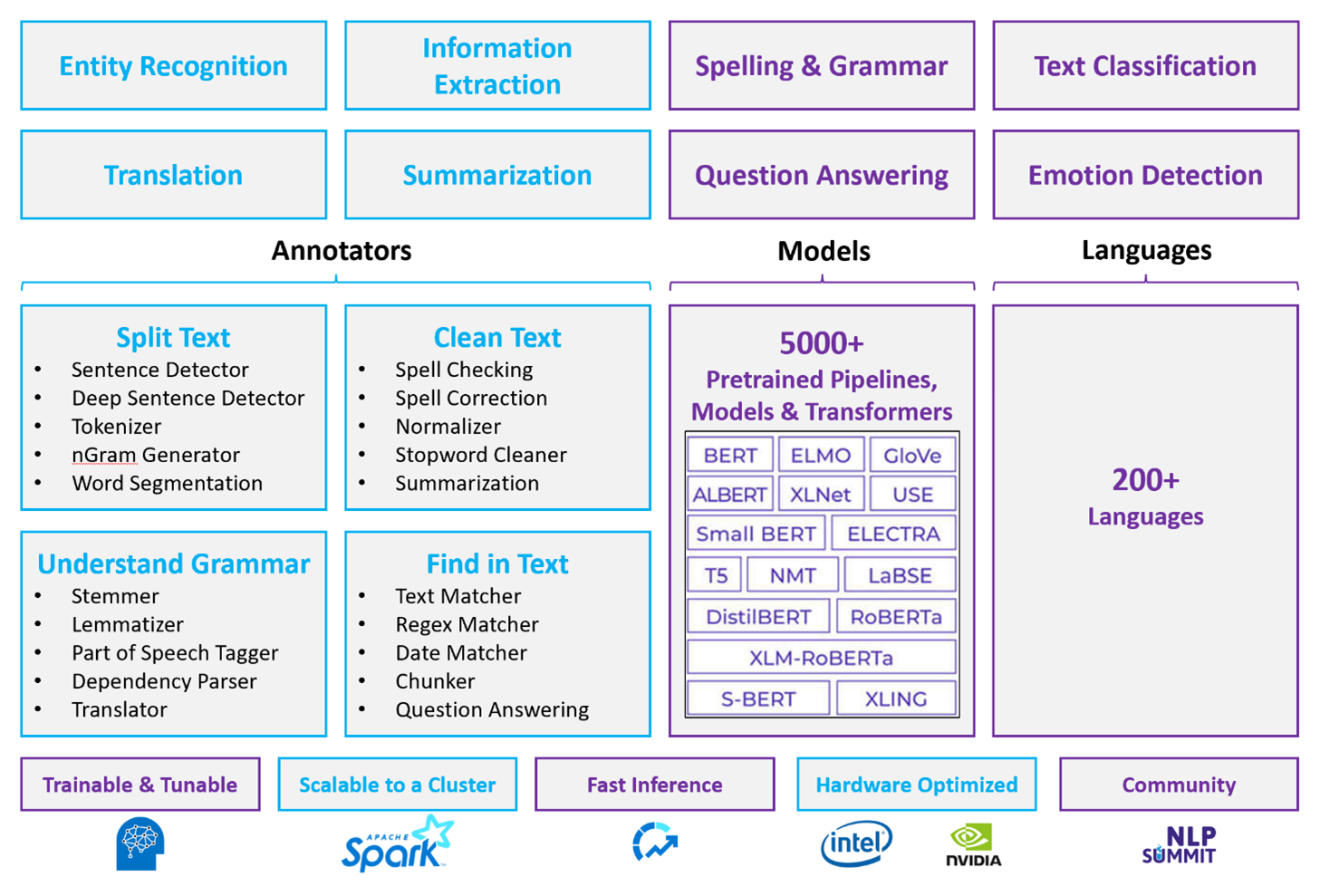
Recientes pruebas comparativas que han visto la luz muestran que el Spark NLP es entre 38 y 80 veces más rápido que spaCy y que tiene una precisión similar a la hora de entrenar modelos personalizados. Spark NLP es la única biblioteca de código abierto que puede usar un clúster de Spark distribuido. Spark NLP es una extensión nativa de Spark ML que funciona directamente en tramas de datos. En consecuencia, las velocidades de un clúster dan como resultado otro orden de magnitud de ganancia de rendimiento. Dado que cada canalización de Spark NLP es una canalización de Spark ML, Spark NLP es adecuada para crear canalizaciones de NLP y de aprendizaje automático unificadas, como la clasificación de documentos, la predicción de riesgos y las canalizaciones de recomendación.
Además de un rendimiento excelente, Spark NLP también ofrece una precisión de última generación en cada vez más tareas del lenguaje natural personalizado. El equipo de Spark NLP lee periódicamente los últimos documentos académicos relevantes e implementa los modelos de última generación. En los últimos dos o tres años, los modelos con mejor rendimiento han usado el aprendizaje profundo. La biblioteca incluye modelos de aprendizaje profundo creados previamente para el reconocimiento de entidades con nombre, la clasificación de documentos, la detección de sentimiento y emociones, y la detección de oraciones. La biblioteca también incluye docenas de modelos de idioma previamente entrenados que incluyen compatibilidad con la inserción de palabras, fragmentos, oraciones y documentos.
La biblioteca tiene compilaciones optimizadas para CPU, GPU y los chips Intel Xeon más recientes. Puede escalar los procesos de entrenamiento e inferencia para sacar partido de los clústeres de Spark. Estos procesos se pueden ejecutar en producción en las plataformas de análisis más usadas.
Desafíos
- El procesamiento de una colección de documentos de texto con formato libre requiere una considerable cantidad de recursos computacionales. El procesamiento también consume mucho tiempo. Estos procesos suelen implicar la implementación del proceso de la GPU.
- Sin un formato de documento estándar, es posible que resulte difícil lograr unos resultados coherentes y precisos cuando se procesa texto con formato libre para extraer datos concretos de un documento. Por ejemplo, imagine una representación textual de una factura: puede ser difícil crear un proceso que extraiga correctamente el número y la fecha de factura cuando las facturas provienen de varios proveedores.
Principales criterios de selección
En Azure, los servicios de Spark como Azure Databricks, Azure Synapse Analytics y Azure HDInsight proporcionan funcionalidad de NLP cuando se usan con Spark NLP. Azure Cognitive Services es otra opción para la funcionalidad de NLP. Para decidir qué servicio debe usar, hágase estas preguntas:
¿Desea usar modelos creados o entrenados previamente? En caso afirmativo, considere la posibilidad de usar las API que ofrece Azure Cognitive Services. O bien, descargue el modelo que prefiera a través de Spark NLP.
¿Necesita entrenar modelos personalizados en un corpus grande de datos de texto? Si la respuesta es afirmativa, considere la posibilidad de usar Azure Databricks, Azure Synapse Analytics o Azure HDInsight con Spark NLP.
¿Necesita funcionalidades de procesamiento de lenguaje natural de bajo nivel como tokenización, lematización y frecuencia de términos o frecuencia inversa de documento (TF/IDF)? Si la respuesta es afirmativa, considere la posibilidad de usar Azure Databricks, Azure Synapse Analytics o Azure HDInsight con Spark NLP. O bien, use una biblioteca de software de código abierto en la herramienta de procesamiento que prefiera.
¿Necesita capacidades de procesamiento de lenguaje natural simples y de alto nivel como identificación de entidades e intenciones, detección de temas, corrector ortográfico o análisis de opiniones? En caso afirmativo, considere la posibilidad de usar las API que ofrece Cognitive Services. O bien, descargue el modelo que prefiera a través de Spark NLP.
Matriz de funcionalidades
En las tablas siguientes se resumen las principales diferencias en cuanto a funcionalidades de los distintos servicios de NLP.
Funcionalidades generales
| Capacidad | Servicio Spark (Azure Databricks, Azure Synapse Analytics, Azure HDInsight) con Spark NLP | Azure Cognitive Services |
|---|---|---|
| Proporciona modelos previamente entrenados como un servicio | Sí | Sí |
| API DE REST | Sí | Sí |
| Programación | Python, Scala | Para saber cuáles son los idiomas que se admiten, consulte Recursos adicionales |
| Admite el procesamiento de conjuntos de macrodatos y documentos de gran tamaño | Sí | No |
Funcionalidades del procesamiento de lenguaje natural de bajo nivel
| Funcionalidad de los anotadores | Servicio Spark (Azure Databricks, Azure Synapse Analytics, Azure HDInsight) con Spark NLP | Azure Cognitive Services |
|---|---|---|
| Detector de frases | Sí | No |
| Detector de frases profundas | Sí | Sí |
| Tokenizador | Sí | Sí |
| Generador de eneagramas | Sí | No |
| Segmentación de palabras | Sí | Sí |
| Lematizador | Sí | No |
| Lematizador | Sí | No |
| Etiquetado de categorías gramaticales | Sí | No |
| Analizador de dependencias | Sí | No |
| Traducción | Sí | No |
| Limpiador de palabras irrelevantes | Sí | No |
| Corrección ortográfica | Sí | No |
| Normalizador | Sí | Sí |
| Buscador de coincidencias de texto | Sí | No |
| TF/IDF | Sí | No |
| Buscador de expresiones regulares | Sí | Insertado en Language Understanding Service (LUIS). No se admite en Conversational Language Understanding (CLU), que reemplaza a LUIS. |
| Buscador de fechas | Sí | Posible en LUIS y CLU mediante reconocedores de DateTime |
| Fragmentador | Sí | No |
Funcionalidades del procesamiento de lenguaje natural de alto nivel
| Capacidad | Servicio Spark (Azure Databricks, Azure Synapse Analytics, Azure HDInsight) con Spark NLP | Azure Cognitive Services |
|---|---|---|
| Corrector ortográfico | Sí | No |
| Resumen | Sí | Sí |
| Respuesta a preguntas | Sí | Sí |
| Detección de opiniones | Sí | Sí |
| Detección de emociones | Sí | Admite la minería de opiniones |
| Clasificación de tokens | Sí | Sí, mediante modelos personalizados |
| Clasificación de textos | Sí | Sí, mediante modelos personalizados |
| Representación de texto | Sí | No |
| NER | Sí | Sí: el análisis de texto proporciona un conjunto de NER y los modelos personalizados están en el reconocimiento de entidades |
| Reconocimiento de entidades | Sí | Sí, mediante modelos personalizados |
| Detección de idiomas | Sí | Sí |
| Admite otros idiomas, además del inglés | Sí, admite más de 200 idiomas | Sí, admite más de 97 idiomas |
Configuración de Spark NLP en Azure
Para instalar Spark NLP, use el siguiente código, pero reemplace <version> por el número de versión más reciente. Para más información, consulte la documentación de Spark NLP.
# Install Spark NLP from PyPI.
pip install spark-nlp==<version>
# Install Spark NLP from Anacodna or Conda.
conda install -c johnsnowlabs spark-nlp
# Load Spark NLP with Spark Shell.
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP with PySpark.
pyspark --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP with Spark Submit.
spark-submit --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP as an external JAR after compiling and building Spark NLP by using sbt assembly.
spark-shell --jars spark-nlp-assembly-3 <version>.jar
Desarrollo de canalizaciones de NLP
Para establecer el orden de ejecución de una canalización de NLP, Spark NLP sigue el mismo concepto de desarrollo que los modelos de aprendizaje automático tradicionales de Spark ML. Sin embargo, Spark NLP aplica técnicas de procesamiento de lenguaje natural.
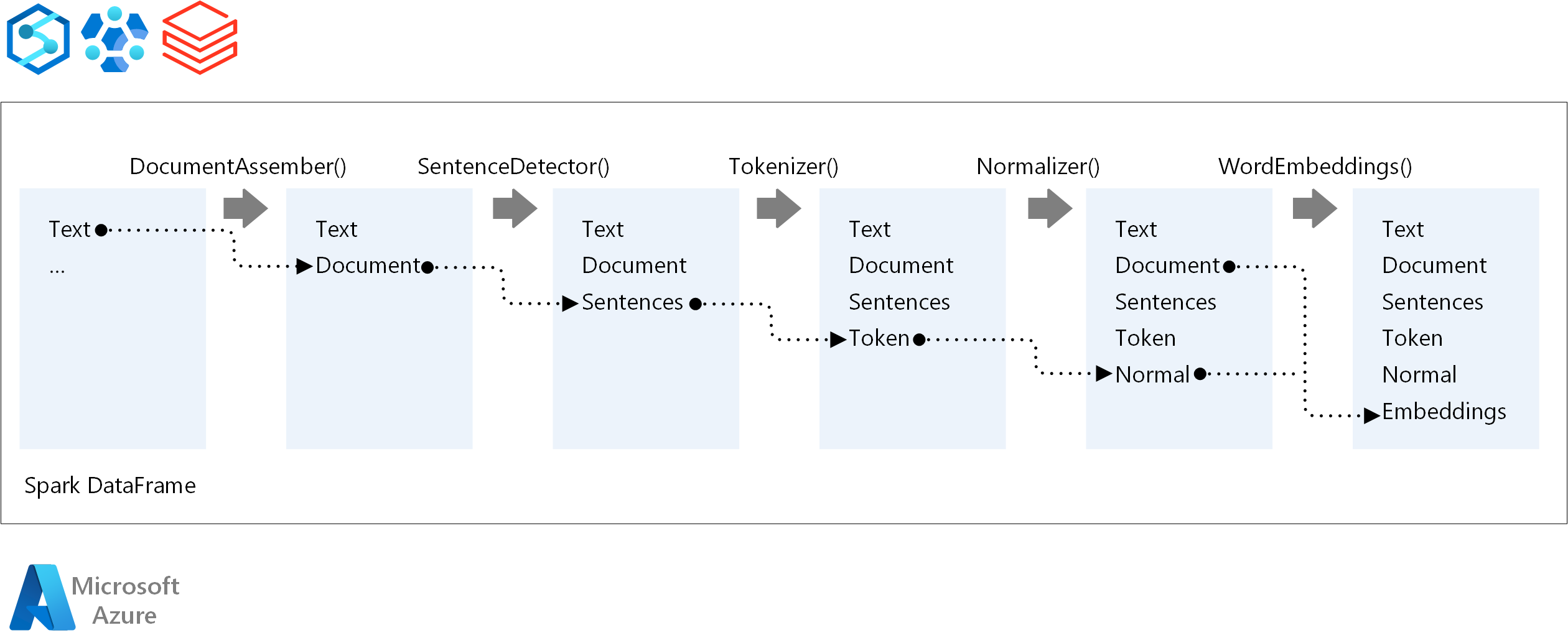
Los principales componentes de una canalización de Spark NLP son:
DocumentAssembler: transformador que prepara los datos, para que los cambia a un formato que Spark NLP pueda procesar. Esta fase es el punto de entrada de cada canalización de Spark NLP. DocumentAssembler puede leer una columna
StringoArray[String]. Puede usarsetCleanupModepara preprocesar el texto. De forma predeterminada, este modo está desactivado.SentenceDetector: anotador que detecta los límites de las frases mediante el enfoque que se proporciona. Este anotador puede devolver cada frase extraída en
Array. También puede devolver cada oración en una fila diferente. Para ello hay que establecerexplodeSentencesen true.Tokenizador: anotador que separa el texto sin formato en tokens o unidades como palabras, números y símbolos, y devuelve los tokens en una estructura
TokenizedSentence. Esta clase no está ajustada. Si se ajusta un tokenizador, elRuleFactoryinterno usa la configuración de entrada para configurar reglas de tokenización. El tokenizador usa estándares abiertos para identificar tokens. Si la configuración predeterminada no cubre sus necesidades, puede agregar reglas para personalizar el tokenizador.Normalizador: anotador que limpia los tokens. El normalizador requiere lemas. El normalizador usa expresiones regulares y un diccionario para transformar texto y quitar caracteres malsonantes.
WordEmbeddings: busca anotadores que asignan tokens a vectores. Puede usar
setStoragePathpara especificar un diccionario de búsqueda de tokens personalizado para las inserciones. Cada línea del diccionario debe contener un token y su representación vectorial, separados por espacios. Si no se encuentra ningún token en el diccionario, el resultado es un vector cero de la misma dimensión.
Spark NLP usa canalizaciones de Spark MLlib, que MLflow admite de forma nativa. MLflow es una plataforma de código abierto para el ciclo de vida del aprendizaje automático. Sus componentes incluyen:
- Seguimiento de Mlflow: registra experimentos y proporciona una manera de consultar los resultados.
- Proyectos de MLflow: permite ejecutar código de ciencia de datos en cualquier plataforma.
- Modelos de MLflow: implementa modelos en diversos entornos.
- Registro de modelos: administra los modelos que se almacenan en un repositorio central.
MLflow se integra en Azure Databricks. MLflow se puede instalar en cualquier otro entorno de Spark para realizar un seguimiento de los experimentos y administrarlos. También puede usar el registro de modelos de MLflow para que los modelos estén disponibles para producción.
Colaboradores
Microsoft mantiene este artículo. Originalmente lo escribieron los siguientes colaboradores.
Creadores de entidad de seguridad:
- Moritz Steller | Arquitecto sénior de soluciones en la nube
- Zoiner Tejada | Director ejecutivo y arquitecto
Pasos siguientes
Documentación de Spark NLP:
Componentes de Azure:
Recursos de Learn:
Recursos relacionados
- Procesamiento de lenguaje natural personalizado a gran escala en Azure
- Elección de una tecnología de servicios cognitivos de Microsoft
- Comparación de productos y tecnologías de aprendizaje automático de Microsoft
- MLflow y Azure Machine Learning
- Enriquecimiento mediante inteligencia artificial con procesamiento de imágenes y lenguaje natural en Azure Cognitive Search
- Análisis de fuentes de noticias con análisis casi en tiempo real mediante el procesamiento de imágenes y lenguaje natural
- Sugerencia de etiquetas de contenido con NLP mediante aprendizaje profundo.