Ideas de solución
Este artículo es una idea de solución. Si te gustaría que ampliemos este artículo con más información, como posibles casos de uso, servicios alternativos, consideraciones de implementación o una guía de precios, comunícalo a través de los Comentarios de GitHub.
Implemente una solución de procesamiento de lenguaje natural (NLP) personalizada en Azure. Use Spark NLP para tareas como la detección y el análisis de opiniones y temas.
Apache®, Apache Spark y el logotipo de la llama son marcas registradas o marcas comerciales de Apache Software Foundation en Estados Unidos y otros países. El uso de estas marcas no implica la aprobación de Apache Software Foundation.
Architecture

Descargue un archivo Visio de esta arquitectura.
Flujo de trabajo
- Azure Event Hubs, Azure Data Factory, o ambos servicios, reciben documentos o datos de texto no estructurados.
- Event Hubs y Data Factory almacenan los datos en formato de archivo en Azure Data Lake Storage. Se recomienda configurar una estructura de directorios que cumpla los requisitos empresariales.
- Azure Computer Vision API usa su funcionalidad de reconocimiento óptico de caracteres (OCR) para consumir los datos. A continuación, la API escribe los datos en la capa de bronce. Esta plataforma de consumo usa una arquitectura de lago de datos.
- En la capa de bronce, varias características de Spark NLP preprocesan el texto. Entre los ejemplos se incluyen la división, la corrección ortográfica, la limpieza y la comprensión gramatical. Se recomienda ejecutar la clasificación de documentos en la capa de bronce y, después, escribir los resultados en la capa de plata.
- En la capa de plata, las características avanzadas de Spark NLP realizan tareas de análisis de documentos como el reconocimiento de entidades con nombre, el resumen y la recuperación de la información. En algunas arquitecturas, el resultado se escribe en la capa dorada.
- En la capa dorada, Spark NLP ejecuta varios análisis visuales lingüísticos en los datos de texto. Estos análisis proporcionan información sobre las dependencias del idioma y ayudan con la visualización de etiquetas de NER.
- Los usuarios realizan consultas en los datos de texto de la capa dorada como una trama de datos y ven los resultados en Power BI o aplicaciones web.
Durante los pasos del procesamiento, Azure Databricks, Azure Synapse Analytics y Azure HDInsight se usan con Spark NLP para proporcionar funcionalidad del procesamiento de lenguaje natural.
Componentes
- Data Lake Storage es un sistema de archivos compatible con Hadoop que tiene un espacio de nombres jerárquico integrado y la escala y economía masivas de Azure Blob Storage.
- Azure Synapse Analytics es un servicio de análisis para sistemas de almacenamiento de datos y de macrodatos.
- Azure Databricks es un servicio de análisis para macrodatos que es fácil de usar, facilita la colaboración y se basa en Apache Spark. Azure Databricks está diseñado para la ciencia de datos y la ingeniería de datos.
- Event Hubs ingiere los flujos de datos que generan las aplicaciones cliente. Event Hubs almacena los datos de streaming y conserva la secuencia de los eventos recibidos. Los consumidores pueden conectarse a los puntos de conexión del centro para recuperar mensajes para su procesamiento. Event Hubs se integra con Data Lake Storage, como se muestra en esta solución.
- Azure HDInsight es un servicio de análisis, de código abierto, espectro completo y administrado en la nube para empresas. Puede usar marcos de código abierto con Azure HDInsight como Hadoop, Apache Spark, Apache Hive, LLAP, Apache Kafka, Apache Storm y R.
- Azure Data Factory mueve automáticamente datos entre cuentas de almacenamiento de distintos niveles de seguridad para garantizar la separación de tareas.
- Computer Vision usa las API de reconocimiento de texto reconocer y extraer el texto de las imágenes. Read API usa los modelos de reconocimiento más recientes y está optimizado para documentos grandes y con mucho texto, e imágenes con demasiado grano. OCR API no está optimizada para documentos grandes, pero admite más idiomas que Read API. Esta solución usa OCR para generar datos con el formato hOCR.
Detalles del escenario
El procesamiento de lenguaje natural (NLP) tiene muchos usos: el análisis de sentimiento, la detección de temas, la detección de idioma, la extracción de frases clave y la clasificación de documentos.
Apache Spark es un marco de procesamiento paralelo que admite el procesamiento en memoria para mejorar el rendimiento de aplicaciones de análisis de macrodatos como NLP. Azure Synapse Analytics, Azure HDInsight y Azure Databricks ofrecen acceso a Spark y aprovechan su potencia de procesamiento.
En el caso de las cargas de trabajo del NLP, la biblioteca de código abierto Spark NLP sirve como marco eficaz para procesar una gran cantidad de texto. En este artículo se presenta una solución para NLP personalizada a gran escala en Azure. La solución usa características de Spark NLP para procesar y analizar texto. Para más información sobre Spark NLP, consulte Funcionalidad y canalizaciones de Spark NLP en este mismo artículo.
Posibles casos de uso
Clasificación de documentos: Spark NLP ofrece varias opciones para la clasificación de texto:
- Preprocesamiento de texto en Spark NLP y algoritmos de aprendizaje automático basados en Spark ML
- Preprocesamiento de texto e inserción de palabras en Spark NLP y algoritmos de aprendizaje automático, como GloVe, BERT y ELMo
- Preprocesamiento de texto e inserción de frases en los algoritmos y modelos de aprendizaje automático y de Spark NLP, como el codificador universal de frases
- Preprocesamiento y clasificación de texto en Spark NLP que usa el anotador ClassifierDL y se basa en TensorFlow
Extracción de entidades de nombre (NER): en Spark NLP, con unas pocas líneas de código, puede entrenar un modelo de NER que use BERT y puede lograr una precisión de última generación. NER es una subtarea de extracción de información. NER localiza entidades con nombre en texto no estructurado y las clasifica en categorías predefinidas, como nombres de persona, organizaciones, ubicaciones, códigos médicos, expresiones temporales, cantidades, valores monetarios y porcentajes. Spark NLP usa un modelo de NER de última generación con BERT. El modelo está inspirado en un antiguo modelo de NER, LSTM-CNN bidireccional. Ese modelo usa una nueva arquitectura de red neuronal que detecta automáticamente características a nivel de palabra y de carácter. Para ello, el modelo usa una arquitectura LSTM y CNN bidireccional híbrida, lo que elimina la necesidad de la mayoría de la ingeniería de características.
Detección de sentimiento y emociones: Spark NLP puede detectar automáticamente los aspectos positivos, negativos y neutros del idioma.
Parte de la voz (POS): esta funcionalidad asigna una etiqueta gramatical a cada token en el texto de entrada.
Detección de frases (SD): SD se basa en un modelo de red neuronal de uso general para la detección de los límites de las frases que identifica las frases dentro del texto. Muchas tareas del procesamiento de lenguaje natural toman una frase como una unidad de entrada. Entre los ejemplos de estas tareas se incluyen el etiquetado de POS, el análisis de dependencias, el reconocimiento de entidades con nombre y la traducción automática.
Funcionalidad y canalizaciones de Spark NLP
Spark NLP proporciona bibliotecas de Python, Java y Scala que ofrecen toda la funcionalidad de las bibliotecas de NLP tradicionales, como spaCy, NLTK, Stanford CoreNLP y Open NLP. Spark NLP también ofrece funcionalidades como la revisión ortográfica, el análisis de sentimiento y la clasificación de documentos. Spark NLP supone una mejora con respecto a los esfuerzos anteriores, ya que proporciona precisión, velocidad y escalabilidad de última generación.
Spark NLP es, con mucho, la biblioteca NLP de código abierto más rápida. Recientes pruebas comparativas que han visto la luz muestran que el Spark NLP es entre 38 y 80 veces más rápido que spaCy y que tiene una precisión similar a la hora de entrenar modelos personalizados. Spark NLP es la única biblioteca de código abierto que puede usar un clúster de Spark distribuido. Spark NLP es una extensión nativa de Spark ML que funciona directamente en tramas de datos. En consecuencia, las velocidades de un clúster dan como resultado otro orden de magnitud de ganancia de rendimiento. Dado que cada canalización de Spark NLP es una canalización de Spark ML, Spark NLP es adecuada para crear canalizaciones de NLP y de aprendizaje automático unificadas, como la clasificación de documentos, la predicción de riesgos y las canalizaciones de recomendación.
Además de un rendimiento excelente, Spark NLP también ofrece una precisión de última generación en cada vez más tareas del lenguaje natural personalizado. El equipo de Spark NLP lee periódicamente las publicaciones académicas relevantes más recientes y genera los modelos más precisos.
Para establecer el orden de ejecución de una canalización de NLP, Spark NLP sigue el mismo concepto de desarrollo que los modelos de aprendizaje automático tradicionales de Spark ML. Sin embargo, Spark NLP aplica técnicas de procesamiento de lenguaje natural. En el diagrama siguiente muestran los componentes principales de una canalización de Spark NLP.
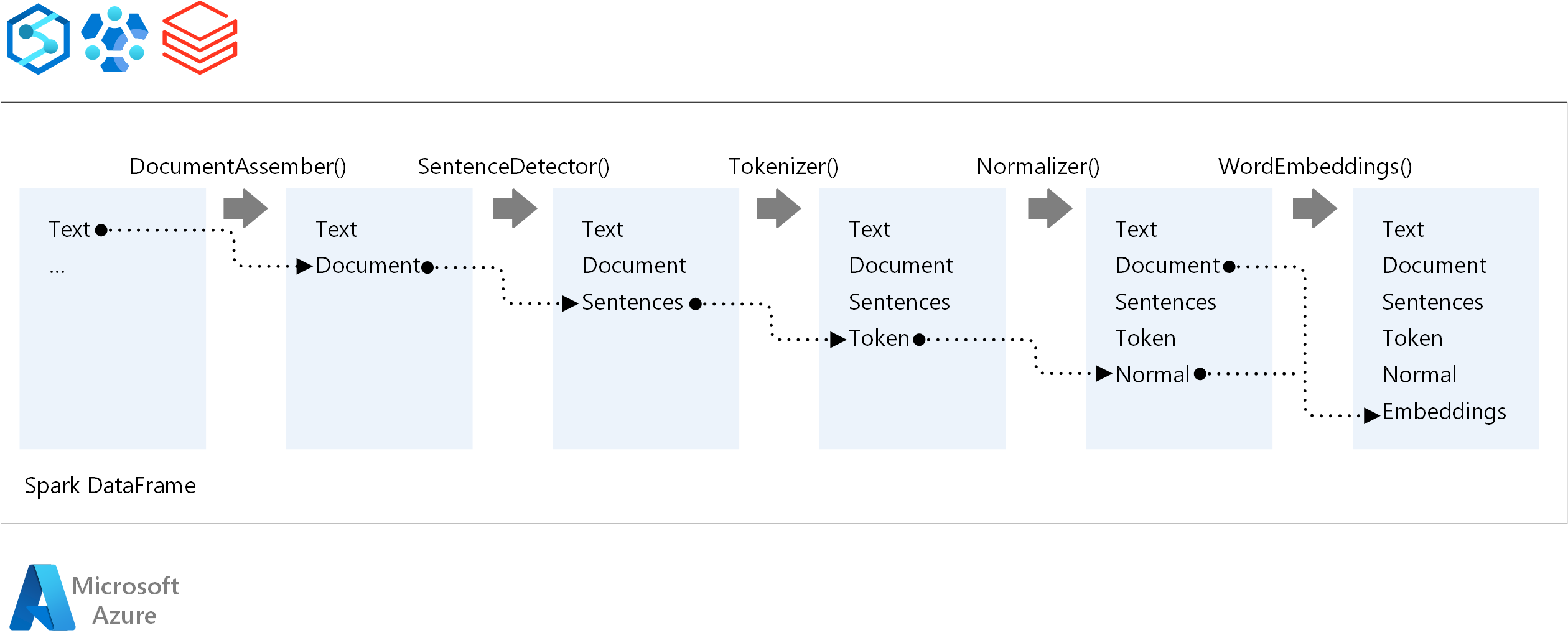
Colaboradores
Microsoft mantiene este artículo. Originalmente lo escribieron los siguientes colaboradores.
Autor principal:
- Moritz Steller | Arquitecto sénior de soluciones en la nube
Pasos siguientes
Documentación de Spark NLP:
Componentes de Azure:
Recursos relacionados
- Tecnología de procesamiento de lenguaje natural
- Enriquecimiento mediante inteligencia artificial con procesamiento de imágenes y lenguaje natural en Azure Cognitive Search
- Análisis de fuentes de noticias con análisis casi en tiempo real mediante el procesamiento de imágenes y lenguaje natural
- Sugerencia de etiquetas de contenido con NLP mediante aprendizaje profundo.