Mejora de la resistencia mediante la replicación del área de trabajo de Log Analytics entre regiones (versión preliminar)
La replicación del área de trabajo de Log Analytics entre regiones mejora la resistencia al permitirle cambiar al área de trabajo replicada y continuar las operaciones si se produce un error regional. En este artículo se explica cómo funciona la replicación del área de trabajo de Log Analytics, cómo replicar el área de trabajo, cómo cambiar de área de trabajo y cómo volver a decidir cuándo cambiar entre las áreas de trabajo replicadas.
Este es un vídeo que proporciona información general rápida sobre cómo funciona la replicación del área de trabajo de Log Analytics:
Importante
Aunque a veces se usa el término conmutación por error, por ejemplo, en la llamada API, la conmutación por error también se usa normalmente para describir un proceso automático. Por lo tanto, en este artículo se usa el término conmutación manual para resaltar que el cambio al área de trabajo replicada es una acción que se desencadena manualmente.
Permisos necesarios
| Acción | Permisos requeridos |
|---|---|
| Habilitación de la replicación del área de trabajo | Los permisos Microsoft.OperationalInsights/workspaces/write y Microsoft.Insights/dataCollectionEndpoints/write, como los proporcionados por el rol integrado de Colaborador de supervisión, por ejemplo |
| Conmutar manualmente y volver a conmutar (desencadenador de conmutación por error y conmutación por recuperación) | Los permisos Microsoft.OperationalInsights/locations/workspaces/failover, Microsoft.OperationalInsights/workspaces/failback y Microsoft.Insights/dataCollectionEndpoints/triggerFailover/action como los proporcionados por el rol integrado de Colaborador de supervisión, por ejemplo |
| Comprobación del estado del área de trabajo | Los permisos Microsoft.OperationalInsights/workspaces/read del área de trabajo de Log Analytics, según lo proporcionado por el rol integrado de colaborador de supervisión, por ejemplo |
Funcionamiento de la replicación del área de trabajo de Log Analytics
El área de trabajo y la región originales se conocen como las principales. El área de trabajo replicada y la región alternativa se conocen como las secundarias.
El proceso de replicación del área de trabajo crea una instancia del área de trabajo en la región secundaria. El proceso crea el área de trabajo secundaria con la misma configuración que el área de trabajo principal y Azure Monitor actualiza automáticamente el área de trabajo secundaria con los cambios futuros que realice en la configuración del área de trabajo principal.
El área de trabajo secundaria es un área de trabajo "fantasma" solo con fines de resistencia. No puede ver el área de trabajo secundaria en Azure Portal y no puede administrarla ni acceder a ella directamente.
Al habilitar la replicación del área de trabajo, Azure Monitor también envía nuevos registros ingeridos al área de trabajo principal a la región secundaria. Los registros que ingiere en el área de trabajo antes de habilitar la replicación del área de trabajo no se copian.
Si una interrupción afecta a la región primaria, puede cambiar y volver a enrutar todas las solicitudes de ingesta y consulta a la región secundaria. Una vez que Azure mitiga la interrupción y el área de trabajo principal vuelve a estar en buen estado, puede hacer la conmutación manual a la región primaria.
Al hacer la conmutación manual, el área de trabajo secundaria se activa y la principal se vuelve inactiva. Después, Azure Monitor ingiere nuevos datos a través de la canalización de ingesta en la región secundaria, en lugar de la región primaria. Al cambiar a la región secundaria, Azure Monitor replica todos los datos que ingiere de la región secundaria a la región primaria. El proceso es asincrónico y no afecta a la latencia de ingesta.
Importante
Después de cambiar a la región secundaria, si la región primaria no puede procesar los datos de registro entrantes, Azure Monitor almacena en búfer los datos de la región secundaria durante un máximo de 11 días. Durante los primeros cuatro días, Azure Monitor vuelve a adjuntar automáticamente para replicar los datos periódicamente.

Regiones admitidas
La replicación del área de trabajo se admite actualmente para áreas de trabajo en un conjunto limitado de regiones, organizados por grupos de regiones (grupos de regiones geográficamente adyacentes). Al habilitar la replicación, seleccione una ubicación secundaria en la lista de regiones admitidas en el mismo grupo de regiones que la ubicación principal del área de trabajo. Por ejemplo, un área de trabajo de Oeste de Europa se puede replicar en Norte de Europa, pero no en Oeste de EE. UU. 2, ya que estas regiones se encuentran en grupos de regiones diferentes.
Actualmente se admiten estos grupos de regiones y regiones:
| Grupo de regiones | Regions | Notas |
|---|---|---|
| Norteamérica | Este de EE. UU. | La replicación no se admite desde o hacia la región Este de EE. UU. 2. |
| Este de EE. UU. 2 | La replicación no se admite desde o hacia la región Este de EE. UU. | |
| Oeste de EE. UU. | ||
| Oeste de EE. UU. 2 | ||
| Centro de EE. UU. | ||
| Centro-sur de EE. UU. | ||
| Canadá central | ||
| Europa | Oeste de Europa | |
| Norte de Europa | ||
| Sur de Reino Unido | ||
| Oeste de Reino Unido | ||
| Centro-oeste de Alemania | ||
| Centro de Francia |
Requisitos de residencia de datos
Los distintos clientes tienen requisitos de residencia de datos diferentes, por lo que es importante controlar dónde se almacenan los datos. Azure Monitor procesa y almacena los registros en las regiones primarias y secundarias que elija. Para obtener más información, consulte Regiones admitidas.
Compatibilidad con Sentinel y otros servicios
Varios servicios y características que usan áreas de trabajo de Log Analytics son compatibles con la replicación y conmutación manual del área de trabajo. Estos servicios y características siguen funcionando al hacer la conmutación manual al área de trabajo secundaria.
Por ejemplo, los problemas de red regionales que provocan la latencia de ingesta de registros pueden afectar a los clientes de Sentinel. Los clientes que usan áreas de trabajo replicadas pueden hacer la conmutación manual a su región secundaria para seguir trabajando con su área de trabajo de Log Analytics y Sentinel. Sin embargo, si el problema de red afecta al estado del servicio Sentinel, hacer conmutación manual a otra región no mitiga el problema.
Algunas experiencias de Azure Monitor, incluidas Application Insights y VM Insights, solo son compatibles parcialmente con la replicación y conmutación manual del área de trabajo. Para obtener la lista completa, consulte Restricciones y limitaciones.
Habilitar y deshabilitar la replicación del área de trabajo
Habilite y deshabilite la replicación del área de trabajo mediante un comando REST. El comando desencadena una operación de larga duración, lo que significa que la nueva configuración puede tardar unos minutos en aplicarse. Después de habilitar la replicación, puede tardar hasta una hora en que todas las tablas (tipos de datos) empiecen a replicarse y algunos tipos de datos podrían empezar a replicarse antes que otros. Los cambios realizados en esquemas de tabla después de habilitar la replicación del área de trabajo (por ejemplo, nuevas tablas de registro personalizadas o campos personalizados que cree o registros de diagnóstico configurados para nuevos tipos de recursos) pueden tardar hasta una hora en iniciar la replicación.
Importante
Actualmente no se admite la replicación de áreas de trabajo de Log Analytics vinculadas a un clúster dedicado.
Habilitación de la replicación del área de trabajo
Para habilitar la replicación en el área de trabajo de Log Analytics, use este comando PUT:
PUT
https://management.azure.com/subscriptions/<subscription_id>/resourcegroups/<resourcegroup_name>/providers/microsoft.operationalinsights/workspaces/<workspace_name>?api-version=2023-01-01-preview
body:
{
"properties": {
"replication": {
"enabled": true,
"location": "<secondary_region>"
}
},
"location": "<primary_region>"
}
Donde:
<subscription_id>: identificador de suscripción relacionado con el área de trabajo.<resourcegroup_name>: el grupo de recursos que contiene el recurso del área de trabajo de Log Analytics.<workspace_name>: el nombre del área de trabajo.<primary_region>: la región primaria del área de trabajo de Log Analytics.<secondary_region>: la región en la que Azure Monitor crea el área de trabajo secundaria.
Para conocer los valores de location admitidos, consulte Regiones admitidas.
El comando PUT es una operación de larga duración que puede tardar algún tiempo en completarse. Una llamada correcta devuelve un código de estado 200. Puede realizar un seguimiento del estado de aprovisionamiento de la solicitud, como se describe en Comprobación del estado de aprovisionamiento de solicitudes.
Comprobación del estado de aprovisionamiento de solicitudes
Para comprobar el estado de aprovisionamiento de la solicitud, ejecute este comando GET:
GET
https://management.azure.com/subscriptions/<subscription_id>/resourceGroups/<resourcegroup_name>/providers/Microsoft.OperationalInsights/workspaces/<workspace_name>?api-version=2023-01-01-preview
Donde:
<subscription_id>: identificador de suscripción relacionado con el área de trabajo.<resourcegroup_name>: el grupo de recursos que contiene el recurso del área de trabajo de Log Analytics.<workspace_name>: el nombre del área de trabajo de Log Analytics.
Use el comando GET para comprobar que el estado de aprovisionamiento del área de trabajo cambia de Updating a Succeeded y la región secundaria se establece según lo previsto.
Nota:
Al habilitar la replicación de áreas de trabajo que interactúan con Sentinel, puede tardar hasta 12 días en replicar completamente la lista de reproducción y los datos de Inteligencia sobre amenazas en el área de trabajo secundaria.
Asociación de reglas de recopilación de datos con el punto de conexión de recopilación de datos del sistema
Use reglas de recopilación de datos (DCR) para recopilar datos de registro mediante el agente de Azure Monitor y la API de ingesta de registros.
Si tiene reglas de recopilación de datos que envían datos al área de trabajo principal, debe asociar las reglas a un sistema de punto de conexión de recopilación de datos (DCE), que Azure Monitor crea al habilitar la replicación del área de trabajo. El nombre del punto de conexión de recopilación de datos del sistema es idéntico al identificador del área de trabajo. Solo las reglas de recopilación de datos asociadas al punto de conexión de recopilación de datos del sistema del área de trabajo habilitan la replicación y la conmutación manual. Este comportamiento le permite especificar el conjunto de flujos de registro que se van a replicar, lo que le ayuda a controlar los costos de replicación.
Para replicar los datos que recopile mediante reglas de recopilación de datos, asocie las reglas de recopilación de datos al punto de conexión de recopilación de datos del sistema para el área de trabajo de Log Analytics:
En Azure Portal, seleccione Reglas de recopilación de datos.
En la pantalla Reglas de recopilación de datos, seleccione una regla de recopilación de datos que envíe datos al área de trabajo principal de Log Analytics.
En la página Información generalde regla de recopilación de datos, seleccione Configurar DCE y seleccione el punto de conexión de recopilación de datos del sistema en la lista disponible:
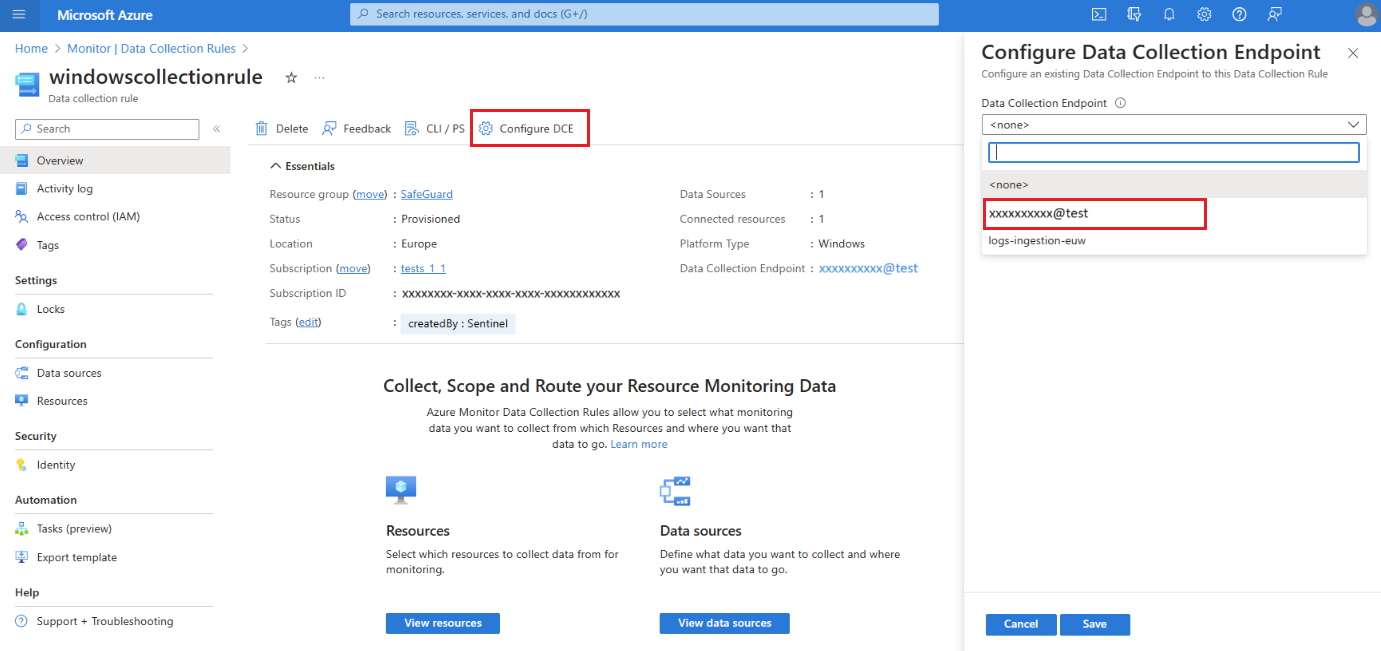 Para obtener más información sobre el DCE del sistema, compruebe las propiedades del objeto del área de trabajo.
Para obtener más información sobre el DCE del sistema, compruebe las propiedades del objeto del área de trabajo.

Importante
Las reglas de recopilación de datos conectadas al punto de conexión de recopilación de datos del sistema de un área de trabajo solo pueden tener como destino esa área de trabajo específica. Las reglas de recopilación de datos no deben establecer como destino otros destinos, como otras áreas de trabajo o cuentas de Azure Storage.
Deshabilitar la replicación del área de trabajo
Para deshabilitar la replicación de un área de trabajo, use este comando PUT:
PUT
https://management.azure.com/subscriptions/<subscription_id>/resourcegroups/<resourcegroup_name>/providers/microsoft.operationalinsights/workspaces/<workspace_name>?api-version=2023-01-01-preview
body:
{
"properties": {
"replication": {
"enabled": false
}
},
"location": "<primary_region>"
}
Donde:
<subscription_id>: identificador de suscripción relacionado con el área de trabajo.<resourcegroup_name>: el grupo de recursos que contiene el recurso del área de trabajo.<workspace_name>: el nombre del área de trabajo.<primary_region>: la región primaria del área de trabajo.
El comando PUT es una operación de larga duración que puede tardar algún tiempo en completarse. Una llamada correcta devuelve un código de estado 200. Puede realizar un seguimiento del estado de aprovisionamiento de la solicitud, como se describe en Comprobación del estado de aprovisionamiento de solicitudes.
Supervisión del estado del área de trabajo y del servicio
La latencia de ingesta o los errores de consulta son ejemplos de problemas que a menudo se pueden controlar mediante la conmutación por error a la región secundaria. Estos problemas se pueden detectar mediante notificaciones de Service Health y consultas de registro.
Las notificaciones de Service Health son útiles para problemas relacionados con el servicio. Para identificar problemas que afectan a su área de trabajo específica (y posiblemente no a todo el servicio), puede usar otras medidas:
- Creación de alertas basadas en el estado de los recursos del área de trabajo
- Establezca sus propios umbrales para métricas de estado del área de trabajo
- Cree sus propias consultas de supervisión para servir como indicadores de estado personalizados para el área de trabajo, como se describe en Supervisar el rendimiento del área de trabajo mediante consultas, para:
- Medición de la latencia de ingesta por tabla
- Identificar si el origen de la latencia son los agentes de recopilación o la canalización de ingesta
- Supervisión de anomalías de volumen de ingesta por tabla y recurso
- Supervisión de la tasa de éxito de consultas por tabla, usuario o recurso
- Creación de alertas basadas en las consultas
Nota:
También puede usar consultas de registro para supervisar el área de trabajo secundaria, pero tenga en cuenta que la replicación de registros se realiza en operaciones por lotes. La latencia medida puede fluctuar y no indica ningún problema de estado con el área de trabajo secundaria. Para obtener más información, consulte Auditar el área de trabajo inactiva.
Cambiar al área de trabajo secundaria
Durante la conmutación manual, la mayoría de las operaciones funcionan igual que cuando se usa el área de trabajo principal y la región. Sin embargo, algunas operaciones tienen un comportamiento ligeramente diferente o están bloqueadas. Para obtener más información, consulte Restricciones y limitaciones.
¿Cuándo debo hacer la conmutación manual?
Usted decide cuándo hacer la conmutación manual al área de trabajo secundaria y volver al área de trabajo principal en función del seguimiento continuo del estado y rendimiento, así como los estándares y requisitos del sistema.
Hay varios puntos que se deben tener en cuenta en el plan de conmutación, como se describe en las siguientes subsecciones.
Tipo de problema y ámbito
El proceso de conmutación manual enruta las solicitudes de ingesta y consulta a la región secundaria, que normalmente omite cualquier componente defectuoso que esté causando latencia o error en la región primaria. Como resultado, es probable que la conmutación manual no sea útil si:
- Hay un problema entre regiones con un recurso subyacente. Por ejemplo, si se produce un error en los mismos tipos de recursos en las regiones primarias y secundarias.
- Experimenta un problema relacionado con la administración del área de trabajo, como cambiar la retención del área de trabajo. Las operaciones de administración del área de trabajo siempre se controlan en la región primaria. Durante la conmutación, se bloquean las operaciones de administración del área de trabajo.
Duración del problema
La conmutación no es instantánea. El proceso de reenrutar solicitudes se basa en las actualizaciones de DNS, que algunos clientes toman en cuestión de minutos, mientras que otros pueden tardar más tiempo. Por lo tanto, resulta útil comprender si el problema se puede resolver en unos minutos. Si el problema observado es coherente o continuo, no espere para realizar la conmutación manual. Estos son algunos ejemplos:
Ingesta: los problemas con la canalización de ingesta de la región primaria pueden afectar a la replicación de datos en el área de trabajo secundaria. Durante la conmutación, los registros se envían en su lugar a la canalización de ingesta en la región secundaria.
Consulta: si las consultas del área de trabajo principal producen un error o tiempo de espera, las alertas de Búsqueda de registros pueden verse afectadas. En este escenario, cambie al área de trabajo secundaria para asegurarse de que todas las alertas se desencadenen correctamente.
Datos del área de trabajo secundaria
Los registros ingeridos en el área de trabajo principal antes de habilitar la replicación no se copian en el área de trabajo secundaria. Si ha habilitado la replicación del área de trabajo hace tres horas y ahora cambia al área de trabajo secundaria, las consultas solo pueden devolver datos de las últimas tres horas.
Antes de cambiar las regiones durante la conmutación manual, el área de trabajo secundaria debe contener un volumen útil de registros. Se recomienda esperar al menos una semana después de habilitar la replicación antes de desencadenar la conmutación manual. Los siete días permiten que los datos suficientes estén disponibles en la región secundaria.
Desencadenar conmutación manual
Antes de hacer la conmutación manual, confirme que la operación de replicación del área de trabajo se completó correctamente. La conmutación manual solo se realiza correctamente cuando el área de trabajo secundaria está configurada correctamente.
Para hacer la conmutación manual al área de trabajo secundaria, use este comando POST:
POST
https://management.azure.com/subscriptions/<subscription_id>/resourceGroups/<resourcegroup_name>/providers/Microsoft.OperationalInsights/locations/<secondary_region>/workspaces/<workspace_name>/failover?api-version=2023-01-01-preview
Donde:
<subscription_id>: identificador de suscripción relacionado con el área de trabajo.<resourcegroup_name>: el grupo de recursos que contiene el recurso del área de trabajo.<secondary_region>: la región a la que se va a cambiar durante la conmutación manual.<workspace_name>: nombre del área de trabajo a la que se va a cambiar durante la conmutación manual.
El comando POST es una operación de larga duración que puede tardar algún tiempo en completarse. Una llamada correcta devuelve un código de estado 202. Puede realizar un seguimiento del estado de aprovisionamiento de la solicitud, como se describe en Comprobación del estado de aprovisionamiento de solicitudes.
Conmutación de regreso al área de trabajo principal
El proceso de conmutación de regreso cancela el reenrutamiento de consultas y solicitudes de ingesta de registros al área de trabajo secundaria. Al hacer la conmutación de regreso, Azure Monitor vuelve a enrutar las consultas y las solicitudes de ingesta de registros al área de trabajo principal.
Al hacer conmutación manual a la región secundaria, Azure Monitor replica los registros del área de trabajo secundaria en el área de trabajo principal. Si una interrupción afecta al proceso de ingesta de registros en la región primaria, Azure Monitor puede tardar tiempo en completar la ingesta de los registros replicados en el área de trabajo principal.
¿Cuándo debo hacer la conmutación de regreso?
Hay varios puntos que se deben tener en cuenta en el plan de conmutación de regreso, como se describe en las siguientes subsecciones.
Estado de replicación del registro
Antes de volver, compruebe que Azure Monitor completó la replicación de todos los registros ingeridos durante la conmutación manual a la región primaria. Si hace la conmutación de regreso antes de que todos los registros se repliquen en el área de trabajo principal, las consultas podrían devolver resultados parciales hasta que se complete la ingesta de registros.
Puede consultar el área de trabajo principal en Azure Portal para la región inactiva, como se describe en Auditar el área de trabajo inactiva.
Estado del área de trabajo principal
Hay dos elementos de mantenimiento importantes para comprobar la preparación de la conmutación de regreso al área de trabajo principal:
- Confirme que no hay ninguna notificación pendiente de Service Health para el área de trabajo principal y la región.
- Confirme que el área de trabajo principal está ingierendo registros y procesando consultas según lo previsto.
Para obtener ejemplos de cómo consultar el área de trabajo principal cuando el área de trabajo secundaria está activa y omitir el reenrutamiento de solicitudes al área de trabajo secundaria, consulte Auditar el área de trabajo inactiva.
Desencadenar conmutación de regreso
Antes de hacer la conmutación de regreso, confirme el estado del área de trabajo principal y complete la replicación de registros.
El proceso de conmutación de regreso actualiza los registros DNS. Después de actualizar los registros DNS, todos los clientes pueden tardar tiempo en recibir la configuración de DNS actualizada y reanudar el enrutamiento al área de trabajo principal.
Para volver al área de trabajo principal, use este comando POST:
POST
https://management.azure.com/subscriptions/<subscription_id>/resourceGroups/<resourcegroup_name>/providers/Microsoft.OperationalInsights/workspaces/<workspace_name>/failback?api-version=2023-01-01-preview
Donde:
<subscription_id>: identificador de suscripción relacionado con el área de trabajo.<resourcegroup_name>: el grupo de recursos que contiene el recurso del área de trabajo.<workspace_name>: nombre del área de trabajo a la que se va a cambiar durante la conmutación de regreso.
El comando POST es una operación de larga duración que puede tardar algún tiempo en completarse. Una llamada correcta devuelve un código de estado 202. Puede realizar un seguimiento del estado de aprovisionamiento de la solicitud, como se describe en Comprobación del estado de aprovisionamiento de solicitudes.
Auditar el área de trabajo inactiva
De forma predeterminada, la región activa del área de trabajo es la región en la que se crea el área de trabajo y la región inactiva es la región secundaria, en la que Azure Monitor crea el área de trabajo replicada.
Al desencadenar la conmutación por error, esto cambia: la región secundaria se activa y la región primaria se desactiva. Decimos que se desactiva porque no es el destino directo de la ingesta de registros y las solicitudes de consulta.
Es útil consultar la región inactiva antes de cambiar entre regiones para comprobar que el área de trabajo de la región inactiva tiene los registros que espera ver allí.
Consultar región inactiva
Para consultar datos de registro en la región inactiva, use este comando GET:
GET
api.loganalytics.azure.com/v1/workspaces/<workspace id>/query?query=<query>×pan=<timespan-in-ISO8601-format>&overrideWorkspaceRegion=<primary|secondary>
Por ejemplo, para ejecutar una consulta sencilla como Perf | count para el último día en la región secundaria, use:
GET
api.loganalytics.azure.com/v1/workspaces/<workspace id>/query?query=Perf%20|%20count×pan=P1D&overrideWorkspaceRegion=secondary
Puede confirmar que Azure Monitor ejecuta la consulta en la región prevista comprobando estos campos en la tabla LAQueryLogs, que se crea al habilitar la auditoría de consultas en el área de trabajo de Log Analytics:
isWorkspaceInFailover: indica si el área de trabajo estaba en modo de conmutación manual durante la consulta. El tipo de datos es booleano (True, False).workspaceRegion: la región del área de trabajo de destino de la consulta. El tipo de datos es String.
Supervisión del rendimiento del área de trabajo mediante consultas
Se recomienda usar las consultas de esta sección para crear reglas de alerta que le notifiquen sobre posibles problemas de estado o rendimiento del área de trabajo. Sin embargo, la decisión de hacer conmutación manual requiere su cuidadosa consideración y no debe realizarse automáticamente.
En la regla de consulta, puede definir una condición para cambiar al área de trabajo secundaria después de un número especificado de infracciones. Para obtener más información, consulte Crear o editar una regla de alertas de búsqueda de registros.
Dos medidas significativas del rendimiento del área de trabajo incluyen latencia de ingesta y volumen de ingesta. En las secciones siguientes se exploran estas opciones de supervisión.
Supervisión de la latencia de ingesta de un extremo a otro
La latencia de ingesta mide el tiempo necesario para ingerir registros en el área de trabajo. La medida de tiempo se inicia cuando se produce el evento registrado inicial y finaliza cuando el registro se almacena en el área de trabajo. La latencia total de ingesta se compone de dos partes:
- Latencia del agente: el tiempo requerido por el agente para notificar un evento.
- Latencia de la canalización de ingesta (back-end): el tiempo necesario para que la canalización de ingesta procese los registros y los escriba en el área de trabajo.
Los distintos tipos de datos tienen una latencia de ingesta diferente. Puede medir la ingesta de cada tipo de datos por separado, o crear una consulta genérica para todos los tipos, y una consulta más detallada para tipos específicos que son de mayor importancia para usted. Se recomienda medir el percentil 90 de la latencia de ingesta, que es más sensible al cambio que el promedio o el percentil 50 (mediana).
En las secciones siguientes se muestra cómo usar consultas para comprobar la latencia de ingesta del área de trabajo.
Evaluación de la latencia de ingesta de línea base de tablas específicas
Comience por determinar la latencia de línea base de tablas específicas durante varios días.
Esta consulta de ejemplo crea un gráfico del percentil 90 de latencia de ingesta en la tabla Perf:
// Assess the ingestion latency baseline for a specific data type
Perf
| where TimeGenerated > ago(3d)
| project TimeGenerated,
IngestionDurationSeconds = (ingestion_time()-TimeGenerated)/1s
| summarize LatencyIngestion90Percentile=percentile(IngestionDurationSeconds, 90) by bin(TimeGenerated, 1h)
| render timechart
Después de ejecutar la consulta, revise los resultados y el gráfico representado para determinar la latencia esperada para esa tabla.
Supervisión y alerta sobre la latencia de ingesta actual
Después de establecer la latencia de ingesta de línea base para una tabla específica, cree una regla de alertas de búsqueda de registros para la tabla en función de los cambios en la latencia durante un breve período de tiempo.
Esta consulta calcula la latencia de ingesta en los últimos 20 minutos:
// Track the recent ingestion latency (in seconds) of a specific table
Perf
| where TimeGenerated > ago(20m)
| extend IngestionDurationSeconds = (ingestion_time()-TimeGenerated)/1s
| summarize Ingestion90Percent_seconds=percentile(IngestionDurationSeconds, 90)
Dado que puede esperar algunas fluctuaciones, cree una condición de regla de alerta para comprobar si la consulta devuelve un valor significativamente mayor que la línea base.
Determinar el origen de la latencia de ingesta
Cuando observe que la latencia total de ingesta está subiendo, puede usar consultas para determinar si el origen de la latencia son los agentes o la canalización de ingesta.
Esta consulta representa la latencia del percentil 90 de los agentes y de la canalización, por separado:
// Assess agent and pipeline (backend) latency
Perf
| where TimeGenerated > ago(1h)
| extend AgentLatencySeconds = (_TimeReceived-TimeGenerated)/1s,
PipelineLatencySeconds=(ingestion_time()-_TimeReceived)/1s
| summarize percentile(AgentLatencySeconds,90), percentile(PipelineLatencySeconds,90) by bin(TimeGenerated,5m)
| render columnchart
Nota:
Aunque el gráfico muestra los datos del percentil 90 como columnas apiladas, la suma de los datos de los dos gráficos no es igual al percentil 90 de ingesta total.
Supervisión del volumen de ingesta
Las medidas de volumen de ingesta pueden ayudar a identificar cambios inesperados en el volumen de ingesta total o específico de la tabla para el área de trabajo. Las medidas de volumen de consulta pueden ayudarle a identificar problemas de rendimiento con la ingesta de registros. Algunas medidas de volumen útiles incluyen:
- Volumen total de ingesta por tabla
- Volumen de ingesta constante (sin cambios)
- Anomalías de ingesta: picos y caídas en el volumen de ingesta
En las secciones siguientes se muestra cómo usar consultas para comprobar el volumen de ingesta del área de trabajo.
Supervisión del volumen total de ingesta por tabla
Puede definir una consulta para supervisar el volumen de ingesta por tabla en el área de trabajo. La consulta puede incluir una alerta que comprueba si hay cambios inesperados en los volúmenes totales o específicos de la tabla.
Esta consulta calcula el volumen total de ingesta en la última hora por tabla en megabytes por segundo (MB):
// Calculate total ingestion volume over the past hour per table
Usage
| where TimeGenerated > ago(1h)
| summarize BillableDataMB = sum(_BilledSize)/1.E6 by bin(TimeGenerated,1h), DataType
Comprobación de la ingestión sin cambios
Si ingiere registros a través de agentes, puede usar el latido del agente para detectar la conectividad. Un latido todavía puede revelar una detención en la ingesta de registros en el área de trabajo. Cuando los datos de la consulta revelan una ingesta de modo sin cambios, puede definir una condición para desencadenar una respuesta deseada.
La consulta siguiente comprueba el latido del agente para detectar problemas de conectividad:
// Count agent heartbeats in the last ten minutes
Heartbeat
| where TimeGenerated>ago(10m)
| count
Supervisión de anomalías de ingesta
Puede identificar picos y caídas en los datos del volumen de ingesta del área de trabajo de varias maneras. Use la función series_decompose_anomalies() para extraer anomalías de los volúmenes de ingesta que supervisa en el área de trabajo o cree su propio detector de anomalías para admitir escenarios de área de trabajo únicos.
Identificación de anomalías mediante series_decompose_anomalies
La función series_decompose_anomalies() identifica anomalías en una serie de valores de datos. Esta consulta calcula el volumen de ingesta por hora de cada tabla del área de trabajo de Log Analytics y usa series_decompose_anomalies() para identificar anomalías:
// Calculate hourly ingestion volume per table and identify anomalies
Usage
| where TimeGenerated > ago(24h)
| project TimeGenerated, DataType, Quantity
| summarize IngestionVolumeMB=sum(Quantity) by bin(TimeGenerated, 1h), DataType
| summarize
Timestamp=make_list(TimeGenerated),
IngestionVolumeMB=make_list(IngestionVolumeMB)
by DataType
| extend series_decompose_anomalies(IngestionVolumeMB)
| mv-expand
Timestamp,
IngestionVolumeMB,
series_decompose_anomalies_IngestionVolumeMB_ad_flag,
series_decompose_anomalies_IngestionVolumeMB_ad_score,
series_decompose_anomalies_IngestionVolumeMB_baseline
| where series_decompose_anomalies_IngestionVolumeMB_ad_flag != 0
Para más información sobre cómo usar series_decompose_anomalies() para detectar anomalías en los datos de registro, consulte Detección y análisis de anomalías mediante funcionalidades de aprendizaje automático de KQL en Azure Monitor.
Creación de su propio detector de anomalías
Puede crear un detector de anomalías personalizado para admitir los requisitos de escenario para la configuración del área de trabajo. En esta sección se proporciona un ejemplo para demostrar el proceso.
La consulta siguiente calcula:
- Volumen de ingesta esperado: por hora, por tabla (basado en el valor medio de medianas, pero puede personalizar la lógica)
- Volumen de ingesta real: por hora, por tabla
Para filtrar diferencias insignificantes entre el volumen de ingesta esperado y real, la consulta aplica dos filtros:
- Tasa de cambio: más del 150 % o inferior al 66 % del volumen esperado, por tabla
- Volumen de cambios: indica si el volumen aumentado o reducido es superior al 0,1 % del volumen mensual de esa tabla
// Calculate expected vs actual hourly ingestion per table
let TimeRange=24h;
let MonthlyIngestionByType=
Usage
| where TimeGenerated > ago(30d)
| summarize MonthlyIngestionMB=sum(Quantity) by DataType;
// Calculate the expected ingestion volume by median of hourly medians
let ExpectedIngestionVolumeByType=
Usage
| where TimeGenerated > ago(TimeRange)
| project TimeGenerated, DataType, Quantity
| summarize IngestionMedian=percentile(Quantity, 50) by bin(TimeGenerated, 1h), DataType
| summarize ExpectedIngestionVolumeMB=percentile(IngestionMedian, 50) by DataType;
Usage
| where TimeGenerated > ago(TimeRange)
| project TimeGenerated, DataType, Quantity
| summarize IngestionVolumeMB=sum(Quantity) by bin(TimeGenerated, 1h), DataType
| join kind=inner (ExpectedIngestionVolumeByType) on DataType
| extend GapVolumeMB = round(IngestionVolumeMB-ExpectedIngestionVolumeMB,2)
| where GapVolumeMB != 0
| extend Trend=iff(GapVolumeMB > 0, "Up", "Down")
| extend IngestedVsExpectedAsPercent = round(IngestionVolumeMB * 100 / ExpectedIngestionVolumeMB, 2)
| join kind=inner (MonthlyIngestionByType) on DataType
| extend GapAsPercentOfMonthlyIngestion = round(abs(GapVolumeMB) * 100 / MonthlyIngestionMB, 2)
| project-away DataType1, DataType2
// Determine whether the spike/deep is substantial: over 150% or under 66% of the expected volume for this data type
| where IngestedVsExpectedAsPercent > 150 or IngestedVsExpectedAsPercent < 66
// Determine whether the gap volume is significant: over 0.1% of the total monthly ingestion volume to this workspace
| where GapAsPercentOfMonthlyIngestion > 0.1
| project
Timestamp=format_datetime(todatetime(TimeGenerated), 'yyyy-MM-dd HH:mm:ss'),
Trend,
IngestionVolumeMB,
ExpectedIngestionVolumeMB,
IngestedVsExpectedAsPercent,
GapAsPercentOfMonthlyIngestion
Supervisión del éxito y el error de la consulta
Cada consulta devuelve un código de respuesta que indica éxito o error. Cuando se produce un error en la consulta, la respuesta también incluye los tipos de error. Un aumento elevado de errores puede indicar un problema con la disponibilidad del área de trabajo o el rendimiento del servicio.
Esta consulta cuenta cuántas consultas devolvieron un código de error del servidor:
// Count query errors
LAQueryLogs
| where ResponseCode>=500 and ResponseCode<600
| count
Restricciones y limitaciones
Actualmente no se admite la replicación de áreas de trabajo de Log Analytics vinculadas a un clúster dedicado.
La operación de purga, que elimina los registros de un área de trabajo, quita los registros pertinentes de las áreas de trabajo principal y secundaria. Si una de las instancias del área de trabajo no está disponible, se produce un error en la operación de purga.
Actualmente no se admite la replicación de reglas de alerta entre regiones. Dado que Azure Monitor admite la consulta de la región inactiva, las alertas basadas en consultas siguen funcionando cuando se cambia entre regiones a menos que el servicio Alertas de la región activa no funcione correctamente o las reglas de alerta no estén disponibles.
Al habilitar la replicación de áreas de trabajo que interactúan con Sentinel, puede tardar hasta 12 días en replicar completamente la lista de reproducción y los datos de Inteligencia sobre amenazas en el área de trabajo secundaria.
Durante la conmutación, no se admiten las operaciones de administración del área de trabajo, entre las que se incluyen:
- Cambio de la retención del área de trabajo, el plan de tarifa, el límite diario, etc.
- Cambiar la configuración de red
- Cambio del esquema a través de nuevos registros personalizados o la conexión de registros de plataforma desde nuevos proveedores de recursos, como el envío de registros de diagnóstico desde un nuevo tipo de recurso
La funcionalidad de destino de la solución del agente heredado de Log Analytics no se admite durante la conmutación manual. Por lo tanto, durante la conmutación, los datos de la solución se ingieren de todos los agentes.
El proceso de conmutación por error actualiza los registros del sistema de nombres de dominio (DNS) para volver a enrutar todas las solicitudes de ingesta a la región secundaria para su procesamiento. Algunos clientes HTTP tienen "conexiones permanentes" y pueden tardar más tiempo en recoger el DNS actualizado. Durante la conmutación, estos clientes pueden intentar ingerir registros a través de la región primaria durante algún tiempo. Es posible que esté ingiriendo registros en el área de trabajo principal mediante varios clientes, como el agente heredado de Log Analytics, el agente de Azure Monitor, el código (mediante la API de ingesta de registros o la API de recopilación de datos HTTP heredada) y otros servicios, como Sentinel.
Actualmente, estas características no se admiten o solo se admiten parcialmente:
Característica Soporte técnico Planes de tabla auxiliar No admitida. Azure Monitor no replica datos en tablas con el plan de registro auxiliar en el área de trabajo secundaria. Por lo tanto, estos datos no están protegidos contra la pérdida de datos en caso de un error regional y no están disponibles al cambiar al área de trabajo secundaria. Buscar trabajos, Restaurar Parcialmente compatible: las operaciones de búsqueda y restauración crean tablas y las rellenan con resultados de búsqueda o datos restaurados. Después de habilitar la replicación del área de trabajo, las nuevas tablas creadas para estas operaciones se replican en el área de trabajo secundaria. Las tablas rellenadas antes de habilitar la replicación no se replican. Si estas operaciones están en curso al hacer la conmutación manual, el resultado es inesperado. Es posible que se complete correctamente, pero no se replique, o que se produzca un error, según el estado del área de trabajo y el tiempo exacto. Application Insights sobre áreas de trabajo de Log Analytics No compatible VM Insights No compatible Información sobre Container No compatible Vínculos privados No se admite durante la conmutación por error