Replicación geográfica activa
Se aplica a: ![]() Azure SQL Database
Azure SQL Database
En este artículo se proporciona información general sobre la característica de replicación geográfica activa para Azure SQL Database, que permite replicar continuamente datos de una base de datos principal en una base de datos secundaria legible. La base de datos secundaria legible puede estar en la misma región de Azure que la principal o, lo que es más común, en otra región. Este tipo de base de datos secundaria legible también se conoce como una secundaria geográfica o réplica geográfica.
La replicación geográfica activa está configurada por base de datos. Para conmutar por error un grupo de bases de datos o si la aplicación requiere un punto de conexión estable, considera en su lugar Grupos de conmutación por error.
También puede Migrar base de datos SQL con replicación geográfica activa.
Información general
La replicación geográfica activa está diseñada como una solución de continuidad empresarial. La replicación geográfica activa permite recuperar rápidamente bases de datos individuales en caso de catástrofe regional o de interrupción del servicio a gran escala. Una vez configurada la replicación geográfica, puede iniciar una conmutación por error geográfica a una base de datos geográfica secundaria que se encuentre en otra región de Azure. La conmutación por error geográfica la inicia mediante programación la aplicación, o bien lo hace manualmente el usuario.
En el siguiente diagrama se ilustra una configuración típica de una aplicación de nube con redundancia geográfica mediante la replicación geográfica activa.
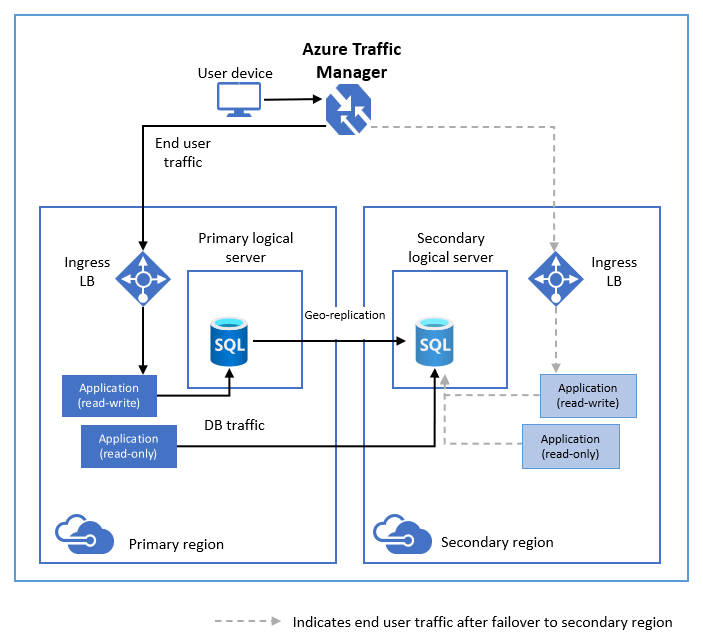
Si por algún motivo se produce un error en la base de datos principal, puede iniciar una conmutación por error geográfica a cualquiera de las bases de datos secundarias. Cuando una base de datos secundaria se promociona al rol de principal, las restantes bases de datos secundarias se vinculan automáticamente a la nueva principal.
Para administrar la replicación geográfica e iniciar una conmutación por error geográfica puede usar cualquiera de los siguientes métodos:
- Azure Portal
- PowerShell: base de datos única
- PowerShell: grupo elástico
- Transact-SQL: base de datos única o grupo elástico
- API REST: base de datos única
La replicación geográfica activa usa la tecnología de grupos de disponibilidad Always On para replicar de forma asincrónica el registro de transacciones generado en la réplica principal en todas las réplicas geográficas. Mientras que, en cualquier momento dado, una base de datos secundaria puede ir ligeramente por detrás de la base de datos principal, se garantiza que los datos de la base secundaria van a ser coherentes, desde un punto de vista transaccional. En otras palabras, los cambios realizados por transacciones no confirmadas no se ven.
Nota:
La replicación geográfica activa replica los cambios mediante la transmisión en secuencias del registro de transacciones de la base de datos desde la réplica principal a las secundarias. No está relacionada con la replicación transaccional, que replica los cambios mediante la ejecución de comandos DML (INSERT, UPDATE, DELETE) en suscriptores.
La replicación geográfica proporciona redundancia regional. La redundancia regional permite a las aplicaciones se recuperen rápidamente de la pérdida permanente de toda una región de Azure, o de partes de ella, causada por desastres naturales, errores humanos catastróficos o actos malintencionados. El RPO de la replicación geográfica se puede encontrar en Introducción a la continuidad empresarial con Azure SQL Database.
En la siguiente ilustración, se muestra un ejemplo de replicación geográfica activa configurada con una base de datos principal en la región Oeste 2 de EE. UU. y una secundaria en la región Este de EE. UU.

Además de para la recuperación ante desastres, la replicación geográfica activa se puede usar en los siguientes escenarios:
- Migración de bases de datos: puede usar la replicación geográfica activa para migrar una base de datos de un servidor a otro con un tiempo de inactividad mínimo.
- Actualizaciones de aplicaciones: puede crear una base de datos secundaria adicional como copia de conmutación por recuperación durante las actualizaciones de aplicaciones.
Para lograr una continuidad empresarial completa, agregar redundancia regional de base de datos es solo una parte de la solución. Para recuperar una aplicación (un servicio) de un extremo a otro tras un error catastrófico, es necesario recuperar todos los componentes que constituyen el servicio y cualquier servicio dependiente. Algunos ejemplos de estos componentes son el software cliente (por ejemplo, un explorador con JavaScript personalizado), los front-end web, el almacenamiento y DNS. Es fundamental que todos los componentes sean resistentes a los mismos errores y que estén disponibles en el plazo del objetivo de tiempo de recuperación (RTO) de la aplicación. Por lo tanto, debe identificar todos los servicios dependientes y comprender las garantías y capacidades que ofrecen. A continuación, debe seguir los pasos adecuados para asegurarse de que el servicio funcione durante la conmutación por error de los servicios de los que depende. Para obtener más información sobre cómo diseñar soluciones para la recuperación ante desastres, consulte Diseño de servicios disponibles globalmente con Azure SQL Database.
Terminología y funcionalidades
Replicación asincrónica automática
Solo puede crear una base de datos geográfica secundaria para una base de datos existente. Esta base de datos se puede crear en cualquier servidor lógico, que no sea el servidor con la base de datos principal. Una vez creada, la réplica geográfica secundaria se rellena con los datos de la base de datos principal. Este proceso se conoce como propagación. Tras crear y propagar la base de datos secundaria geográfica, las actualizaciones de la base de datos principal se replican de forma automática y asincrónica en la réplica secundaria geográfica. La replicación asincrónica significa que las transacciones se confirman en la base de datos principal antes de replicarse.
Réplicas geográficas secundarias legibles
Una aplicación puede acceder a una réplica secundaria geográfica para ejecutar consultas de solo lectura con las mismas entidades de seguridad que se usan para acceder a la base de datos principal o con otras. Para más información, consulte Uso de réplicas de solo lectura para descargar cargas de trabajo de consulta de solo lectura.
Importante
Puede usar la replicación geográfica para crear réplicas secundarias en la misma región que la principal. Estas réplicas secundarias se pueden usar estas secundarias para satisfacer escenarios de escalado horizontal de lectura en la misma región. Sin embargo, una réplica secundaria en la misma región no proporciona resistencia adicional a errores catastróficos o interrupciones a gran escala y, por tanto, no es un destino de conmutación por error adecuado para fines de recuperación ante desastres. Tampoco garantiza el aislamiento de la zona de disponibilidad. Use la configuración con redundancia de zona de los niveles de servicio Crítico para la empresa o Prémium con o la configuración con redundancia de zona del nivel de servicio De uso general para lograr el aislamiento de la zona de disponibilidad.
Conmutación por error (sin pérdida de datos)
La conmutación por error cambia los roles de las bases de datos geográficas principales y secundarias después de completar la sincronización de datos completa de modo que no haya pérdida de datos. La duración de la conmutación por depende del tamaño del registro de transacciones de la principal que debe sincronizarse con la base de datos geográfica secundaria. La conmutación por error está diseñada para los siguientes escenarios:
- Realizar simulacros de recuperación ante desastres en producción cuando no es aceptable la pérdida de datos
- Reubicar la base de datos en otra región
- Devolver la base de datos a la región primaria después de que se ha solucionado la interrupción (conmutación por recuperación).
Conmutación por error forzada (posible pérdida de datos)
La conmutación por error forzada cambia inmediatamente la base de datos geográfica secundaria al rol de principal sin esperar a la sincronización con la principal. Se pierden todas las transacciones confirmadas en la base de datos principal que no se hayan replicado aún en la secundaria. Esta operación está diseñada como método de recuperación durante las interrupciones cuando no se puede acceder a la base de datos principal, pero la disponibilidad de la base de datos debe restaurarse rápidamente. Cuando la base de datos principal original esté de nuevo en línea, se reconecta automáticamente, se vuelve a inicializar mediante los datos actuales de la principal, y se convierte en la nueva base de datos geográfica secundaria.
Importante
Después de la conmutación por error forzada o no forzada, el punto de conexión de la nueva base de datos principal cambia, ya que la nueva base de datos principal se encuentra ahora en otro servidor lógico.
Varias bases de datos geográficas secundarias legibles
Se pueden crear hasta cuatro bases de datos geográficas secundarias para una principal. Si solo hay una base de datos secundaria y se produce un error, la aplicación está expuesta a un mayor riesgo hasta que se crea otra. Si existen varias bases de datos secundarias, la aplicación sigue estando protegida aunque se produzca un error en una de ellas. También se pueden usar bases de datos secundarias adicionales para escalar horizontalmente cargas de trabajo de solo lectura.
Sugerencia
Si usa la replicación geográfica activa para compilar una aplicación distribuida globalmente y necesita proporcionar acceso de solo lectura a los datos en más de cuatro regiones, puede crear una base de datos secundaria a partir de otra base de datos secundaria (este proceso se conoce como encadenamiento) para crear réplicas geográficas adicionales. El retraso de la replicación en las réplicas geográficas encadenadas puede ser mayor que en las réplicas geográficas conectadas directamente a la base de datos principal. La configuración de topologías de replicación geográfica encadenada solo se admite mediante programación, no desde Azure Portal.
Replicación geográfica de bases de datos en un grupo elástico
Cada base de datos geográfica secundaria puede ser una base de datos única o una de un grupo elástico. La opción de un grupo elástico para cada base de datos geográfica secundaria es independiente, no depende de la configuración de ninguna otra réplica de la topología (principal o secundaria). Cada grupo elástico se encuentra dentro de un único servidor lógico. Dado que los nombres de base de datos de un servidor lógico deben ser únicos, varias bases de datos geográficas secundarias de la misma base de datos principal nunca pueden compartir un grupo elástico.
Conmutación por error y conmutación por recuperación geográfica controladas por el usuario
Cualquier base de datos geográfica secundaria que haya finalizado la inicialización inicial se puede cambiar explícitamente al rol principal (conmutado por error) en cualquier momento por parte de la aplicación o el usuario. Durante una interrupción en la que la principal no es accesible, solo se puede usar la conmutación por error forzada, que asciende inmediatamente una base de datos secundaria geográfica para que sea la nueva principal. Cuando se mitiga la interrupción, el sistema convierte automáticamente la base de datos principal recuperada en geográfica secundaria y la pone al día con la nueva principal. Dada la naturaleza asincrónica de la replicación geográfica, es posible que las transacciones recientes se pierdan durante las conmutaciones por error forzadas si se produce un error en la principal antes de que estas transacciones se repliquen en una base de datos geográfica secundaria. Cuando una base de datos principal con varias bases de datos geográficas secundarias realiza una conmutación por error, el sistema vuelve a configurar automáticamente las relaciones de replicación y vincula las bases de datos geográficas secundarias restantes a la base de datos principal recién promovida sin necesidad de que intervenga el usuario. Tras la interrupción que ha provocado la mitigación de la conmutación por error geográfica, sería conveniente devolver la base de datos principal a su región original. Para ello, realiza una conmutación por error manual.
Réplica en espera
Si la réplica secundaria solo se usa para la recuperación ante desastres (DR) y no tiene ninguna carga de trabajo de lectura o escritura, puede designar la réplica como en espera para ahorrar en los costos de licencia.
Preparación para la conmutación por error geográfica
Para asegurarse de que la aplicación puede acceder de inmediato a la nueva base de datos principal después de la conmutación por error geográfica, compruebe que tanto la autenticación como el acceso de red al servidor secundaria están configurados correctamente. Para obtener más información, consulte Configuración y administración de la seguridad de Azure SQL Database para la restauración geográfica o la conmutación por error. Valide también que la directiva de retención de copia de seguridad de la base de datos secundaria coincide con la de la principal. Esta configuración no forma parte de la base de datos y no se replica desde la base de datos principal. De forma predeterminada, la base de datos geográfica secundaria se configura con un período de retención de restauración a un momento dado predeterminado de siete días. Para más información, consulte Copias de seguridad automatizadas en Azure SQL Database.
Importante
Si la base de datos es miembro de un grupo de conmutación por error, no puede iniciar su conmutación por error mediante el comando de conmutación por error de replicación geográfica. Use el comando de conmutación por error para el grupo. Si necesita realizar la conmutación por error de una base de datos individual, primero debe quitarla del grupo de conmutación por error. Consulta Grupos de conmutación por error para más información.
Configuración de una base de datos geográfica secundaria
Es necesario que la base de datos principal y la geográfica secundaria tengan el mismo nivel de servicio. También se recomienda encarecidamente que la base de datos geográfica secundaria se cree con la misma redundancia de almacenamiento de copia de seguridad, nivel de proceso (aprovisionado o sin servidor) y tamaño de proceso (unidades de transacción de base de datos o núcleos virtuales) que la principal. Si la base de datos principal sufre una carga de trabajo de escritura intensiva, es posible que una base de datos geográfica secundaria con un tamaño de proceso menor no pueda mantenerla, lo que provoca un retraso de replicación en la base de datos geográfica secundaria y, finalmente, podría provocar la falta de disponibilidad de la base de datos geográfica secundaria. Para mitigar estos riesgos, una replicación geográfica activa reducirá (limitará) la velocidad de los registros de transacciones de la base de datos principal, en caso de que sea necesario para permitir que sus bases de datos secundarias se pongan al día.
Otra consecuencia de una configuración de una base de datos geográfica secundaria no equilibrada es que después de una conmutación por error, el rendimiento de la aplicación puede verse afectado por a una capacidad de proceso insuficiente de la nueva base de datos principal. En ese caso, es necesario escalar verticalmente la base de datos para tener suficientes recursos, lo que puede tardar mucho tiempo y requiere una conmutación por error de alta disponibilidad al final del proceso de escalado vertical, lo que interrumpirá las cargas de trabajo de la aplicación.
Si decide crear la base de datos geográfica secundaria con una configuración diferente, debe supervisar la tasa de E/S del registro en la base de datos principal a lo largo del tiempo. Esto le permite calcular el tamaño de proceso mínimo de la base de datos geográfica secundaria necesario para mantener la carga de replicación. Por ejemplo, si la base de datos principal es P6 (1000 DTU) y su E/S de registro es 50 % de forma sostenida, la base de datos geográfica secundaria debe ser, al menos, P4 (500 DTU). Para recuperar datos históricos de E/S del registro, use la vista sys.resource_stats. Para recuperar los datos de E/S de registro recientes con una granularidad mayor que refleje mejor los picos a corto plazo, utilice la vista sys.dm_db_resource_stats.
Sugerencia
La limitación de E/S del registro de transacciones puede producirse:
- Si la base de datos secundaria geográfica tiene un tamaño de proceso inferior al principal. Busque el tipo de espera HADR_THROTTLE_LOG_RATE_MISMATCHED_SLO en las vistas de base de datos sys.dm_exec_requests y sys.dm_os_wait_stats.
- Motivos no relacionados con el tamaño de proceso. Para más información, lo que incluye los tipos de espera para diferentes tipos de limitaciones de la E/S del registro, consulte Gobernanza de la velocidad del registro de transacciones.
De forma predeterminada, la redundancia del almacenamiento de copia de seguridad de la base de datos geográfica secundaria es la misma que la de la base de datos principal. Puede configurar una base de datos geográfica secundaria con una redundancia de almacenamiento de copia de seguridad diferente. Las copias de seguridad siempre se realizan en la base de datos principal. Si la secundaria está configurada con una redundancia de almacenamiento de copia de seguridad diferente, después de una conmutación por error geográfica cuando la base de datos geográfica secundaria se promueve a la principal, las nuevas copias de seguridad se almacenarán y facturarán según el tipo de almacenamiento (RA-GRS, ZRS, LRS) seleccionado en la nueva base de datos principal (anteriormente secundaria).
Ahorre en costos con una réplica en espera
Si la réplica secundaria solo se usa para la recuperación ante desastres (DR) y no tiene ninguna carga de trabajo de lectura o escritura, puede ahorrar en los costos de licencias mediante la designación de la base de datos para espera al configurar una nueva relación de replicación geográfica activa.
Para más información, consulte Réplica en espera sin licencia.
Replicación geográfica entre suscripciones
Puede usar Azure Portal para configurar la replicación geográfica activa entre suscripciones siempre que ambas suscripciones estén en el mismo inquilino de Microsoft Entra.
- Para crear una réplica secundaria geográfica en una suscripción diferente de la suscripción principal en otro inquilino de Microsoft Entra, use la autenticación de SQL y T-SQL. No se admite la autenticación de Microsoft Entra para la replicación geográfica entre suscripciones cuando un servidor lógico está en un inquilino de Azure diferente
- Las operaciones de replicación geográfica entre suscripciones, incluidas la configuración y la conmutación por error geográfica, también se admiten mediante la API de REST para crear o actualizar bases de datos.
No se admite la creación de una base de datos geográfica secundaria entre suscripciones en un servidor lógico que esté en el mismo o en otro inquilino de Microsoft Entra cuando la autenticación exclusiva de Microsoft Entra está habilitada en el servidor lógico principal o secundario y la creación se intenta mediante un usuario de Microsoft Entra ID.
Para obtener instrucciones paso a paso y métodos, consulte Tutorial: Configuración de la replicación geográfica activa y la conmutación por error (Azure SQL Database).
Puntos de conexión privados
Al conectarse al servidor principal mediante un punto de conexión privado, no se admite la adición de una ubicación geográfica secundaria con T-SQL.
- Si el punto de conexión privado está configurado, pero se permite el acceso a la red pública, se admite la adición de una ubicación geográfica secundaria al conectarse al servidor principal desde una dirección IP pública.
- Una vez que se haya agregado la ubicación geográfica secundaria, se puede denegar el acceso a redes públicas.
Mantenimiento de las credenciales y las reglas de firewall sincronizadas
Al usar el acceso de la red pública para conectarse a la base de datos, se recomienda usar reglas de firewall de IP de nivel de base de datos para bases de datos con replicación geográfica. Estas reglas se replican con la base de datos, lo que garantiza que todas las bases de datos geográficas secundarias tienen las mismas reglas de firewall de IP que la principal. Este enfoque elimina la necesidad de que los clientes configuren y mantengan manualmente las reglas de firewall en los servidores que hospedan tanto la base de datos principal como las secundarias. Del mismo modo, la utilización de usuarios de bases de datos independientes para el acceso a datos garantiza que tanto la base de datos principal como las secundarias siempre tienen las mismas credenciales de autenticación. De esta forma, después de una conmutación por error geográfica, no hay interrupciones debido a errores de coincidencia de credenciales de autenticación. Si usa inicios de sesión y usuarios (en lugar de usuarios contenidos), debe realizar pasos adicionales para asegurarse de que existan los mismos inicios de sesión para la base de datos secundaria. Para obtener más información, consulte Configuración y administración de la seguridad de Azure SQL Database para la restauración geográfica o la conmutación por error.
Modificación de la escala de una base de datos principal
Puede escalar verticalmente o reducir verticalmente la base de datos principal a un tamaño de proceso diferente (en el mismo nivel de servicio) sin desconectar las secundarias. Cuando se escala verticalmente, se recomienda escalar verticalmente primero la secundaria geográfica y, después, escalar verticalmente la principal. Al reducir verticalmente, invierta el orden: primero escale verticalmente la principal y, a continuación, escale verticalmente la secundaria.
Para obtener información sobre los grupos de conmutación por error, revise el escalado de una réplica en un grupo de conmutación por error.
Evitación la pérdida de datos críticos
Debido a la elevada latencia de las redes de área extensa, la replicación geográfica usa un mecanismo de replicación asincrónica. La replicación asincrónica hace que la posibilidad de perder datos sea inevitable si se produce un error en la principal. Para proteger las transacciones críticas contra la pérdida de datos, un desarrollador de aplicaciones puede llamar al procedimiento almacenado sp_wait_for_database_copy_sync inmediatamente después de confirmar la transacción. La llamada a sp_wait_for_database_copy_sync bloquea el subproceso de llamada hasta que se transmite y protege la última transacción confirmada en el registro de transacciones de la base de datos secundaria. Pero no espera a que las transacciones transmitidas se reproduzcan (vuelvan a hacerse) en la secundaria. sp_wait_for_database_copy_sync está limitado a un vínculo de replicación geográfica específico. Cualquier usuario con derechos de conexión para la base de datos principal puede llamar a este procedimiento.
Nota:
sp_wait_for_database_copy_sync evita la pérdida de datos después de la conmutación por error geográfica para transacciones específicas, pero no garantiza la sincronización completa para el acceso de lectura. El retraso provocado por una llamada al procedimiento sp_wait_for_database_copy_sync puede ser considerable y depende del tamaño del registro de transacciones que todavía no se transmiten en la principal en el momento de la llamada.
Supervisión del retardo de la replicación geográfica
Para supervisar el retardo con respecto a RPO, utilice la columna replication_lag_sec de sys.dm_geo_replication_link_status en la base de datos principal. Muestra el retardo, en segundos, entre las transacciones confirmadas en la base de datos principal y las reforzadas en el registro de transacciones de la secundaria. Por ejemplo, si el retardo es de un segundo, significa que si la principal se ve afectada por una interrupción en este momento y se inicia una migración tras error geográfica, se perderán las transacciones confirmadas en el último segundo.
Para medir el retardo con respecto a los cambios en la base de datos principal que se han protegido en la base de datos geográfica secundaria, compare el tiempo de last_commit en la base de datos geográfica secundaria con el mismo valor en la principal.
Sugerencia
Si en la base de datos principal replication_lag_sec tiene el valor NULL, significa que la base de datos principal no sabe actualmente lo lejos que está una base de datos geográfica secundaria. Esto ocurre típicamente después de reiniciar el proceso y debería ser una condición temporal. Considere la posibilidad de enviar una alerta si replication_lag_sec devuelve NULL durante un período prolongado. Puede indicar que la base de datos geográfica secundaria no se puede comunicar con la principal debido a un error de conectividad.
También hay condiciones que podrían provocar que la diferencia entre el tiempo de last_commit en la base de datos geográfica secundaria y en la principal llegue a ser considerable. Por ejemplo, si se realiza una confirmación en la base de datos principal después de un largo período sin cambios, la diferencia saltará a un valor grande antes de volver rápidamente a cero. Considere la posibilidad de enviar una alerta si la diferencia entre estos dos valores permanece grande durante mucho tiempo.
Administración mediante programación de la replicación geográfica activa
La replicación geográfica activa también se puede administrar mediante programación con T-SQL, Azure PowerShell y API REST. En las tablas siguientes se describe el conjunto de comandos disponibles. La replicación geográfica activa incluye un conjunto de API de Azure Resource Manager para la administración, en el que se incluyen la API REST de Azure SQL Database y los cmdlets de Azure PowerShell. Estas API admiten el control de acceso basado en roles de Azure (Azure RBAC). Para más información sobre cómo implementar los roles de acceso, consulte Control de acceso basado en roles de Azure (Azure RBAC).
Importante
Estos comandos de T-SQL solo se aplican a la replicación geográfica activa, no a los grupos de conmutación por error.
| Comando | Descripción |
|---|---|
| ALTER DATABASE | El argumento ADD SECONDARY ON SERVER se usa para crear una base de datos secundaria para una base de datos existente e iniciar la replicación de datos. |
| ALTER DATABASE | FAILOVER o FORCE_FAILOVER_ALLOW_DATA_LOSS se usan para cambiar una base de datos de secundaria a principal e iniciar la conmutación por error. |
| ALTER DATABASE | REMOVE SECONDARY ON SERVER se usa para finalizar una replicación de datos entre una instancia de SQL Database y la base de datos secundaria especificada. |
| sys.geo_replication_links | Devuelve información sobre todos los vínculos de replicación existentes para cada base de datos en un servidor. |
| sys.dm_geo_replication_link_status | Obtiene la hora de la última replicación, el retraso de la última replicación y otro tipo de información sobre el vínculo de replicación para una base de datos determinada. |
| sys.dm_operation_status | Muestra el estado de todas las operaciones de base de datos, entre las que se incluyen los cambios en los vínculos de replicación. |
| sys.sp_wait_for_database_copy_sync | Hace que la aplicación espere hasta que todas las transacciones confirmadas se refuercen en el registro de transacciones de una base de datos secundaria geográfica. |
Contenido relacionado
Configuración de replicación geográfica activa:
- Para una base de datos mediante Azure Portal
- Para una base de datos única con PowerShell
- Para una base de datos agrupada mediante PowerShell
Otro contenido de continuidad empresarial: