Introducción a los grupos de migración tras error y procedimientos recomendados (Azure SQL Database)
Se aplica a: ![]() Azure SQL Database
Azure SQL Database
La característica de los grupos de conmutación por error permite administrar la replicación y la conmutación por error de algunas bases de datos de un servidor lógico o de todas ellas a otro servidor lógico en otra región. En este artículo se proporciona información general sobre la característica de grupo de conmutación por error con procedimientos recomendados y recomendaciones para su uso con Azure SQL Database.
Para empezar a utilizar la característica, consulta Configuración de grupos de conmutación por error.
Nota:
Este artículo abarca los grupos de conmutación por error para Azure SQL Database. Para Azure SQL Managed Instance, consulta Grupos de conmutación por error en Azure SQL Managed Instance.
Para obtener más información sobre la recuperación ante desastres de la base de datos de Azure SQL, vea este vídeo:
Información general
La característica de los grupos de conmutación por error permite administrar la replicación y la conmutación por error en otra región de Azure de las bases de datos. Puedes incluir un grupo de bases de datos o todas las bases de datos de usuarios de un servidor lógico para que se repliquen en otro servidor lógico. Se trata de una abstracción declarativa sobre la característica de replicación geográfica activa, diseñada para simplificar la implementación y administración de bases de datos con replicación geográfica a gran escala.
Para obtener información sobre RPO y RTO de la conmutación por error geográfica, consulta Introducción a la continuidad empresarial.
Redireccionamiento de punto de conexión
Los grupos de conmutación por error proporcionan puntos de conexión de agentes de escucha de lectura-escritura y de solo lectura que no se modifican durante las conmutaciones por error con replicación geográfica. No es necesario cambiar la cadena de conexión de la aplicación después de una conmutación por error geográfica, porque las conexiones se enrutan automáticamente a la región primaria actual. Una conmutación por error geográfica cambia todas las bases de datos secundarias del grupo al rol principal. Después de que la conmutación por error geográfica finaliza, el registro de DNS se actualiza automáticamente para redirigir los puntos de conexión a la nueva región.
Descarga de cargas de trabajo de solo lectura
Para reducir el tráfico a sus bases de datos principales, también puede utilizar las bases de datos secundarias de un grupo de conmutación por error para descargar cargas de trabajo de solo lectura. Utilice el cliente de escucha de solo lectura para dirigir el tráfico de solo lectura a una base de datos secundaria legible.
Recuperación de una aplicación
Para lograr una continuidad empresarial completa, agregar redundancia de base de datos regional es solo una parte de la solución. Para recuperar una aplicación (un servicio) de un extremo a otro tras un error catastrófico, es necesario recuperar todos los componentes que constituyen el servicio y cualquier servicio dependiente. Algunos ejemplos de estos componentes son el software cliente (por ejemplo, un explorador con JavaScript personalizado), los front-end web, el almacenamiento y DNS. Es fundamental que todos los componentes sean resistentes a los mismos errores y que estén disponibles en el plazo del objetivo de tiempo de recuperación (RTO) de la aplicación. Por lo tanto, debe identificar todos los servicios dependientes y comprender las garantías y capacidades que ofrecen. A continuación, debe seguir los pasos adecuados para asegurarse de que el servicio funcione durante la conmutación por error de los servicios de los que depende.
Directiva de conmutación por error
Los grupos de conmutación por error admiten dos directivas de conmutación por error:
- Administrada por el cliente (recomendado): los clientes pueden realizar una conmutación por error de un grupo cuando observen una interrupción inesperada que afecta a una o varias bases de datos del grupo de conmutación por error. Al usar herramientas de línea de comandos como PowerShell, la CLI de Azure o la API de REST, el valor de la directiva de conmutación por error administrada por el cliente es
manual. - Administrada por Microsoft: en caso de una interrupción generalizada que afecta a una región primaria, Microsoft inicia la conmutación por error de todos los grupos de conmutación por error afectados que tienen configurada su directiva de conmutación por error como administrada por Microsoft. La conmutación por error administrada por Microsoft no se iniciará para grupos de conmutación por error individuales ni para un subconjunto de grupos de conmutación por error de una región. Al usar herramientas de línea de comandos como PowerShell, la CLI de Azure o la API de REST, el valor de la directiva de conmutación por error administrada por Microsoft es
automatic.
Cada directiva de conmutación por error tiene un conjunto único de casos de uso y las expectativas correspondientes sobre el ámbito de conmutación por error y la pérdida de datos, como se resume en la tabla siguiente:
| Directiva de conmutación por error | Ámbito de la conmutación por error | Caso de uso | Posible pérdida de datos |
|---|---|---|---|
| Administrado por el cliente (Recomendado) |
Grupos de conmutación por error | Una o varias bases de datos de un grupo de conmutación por error se ven afectadas por una interrupción y dejan de estar disponibles. Puedes optar por conmutar por error. | Sí |
| Administrado por Microsoft | Todos los grupos de conmutación por error de la región | Una interrupción generalizada en un centro de datos, una zona de disponibilidad o una región provoca la falta de disponibilidad de las bases de datos y el equipo del servicio Microsoft Azure SQL decide desencadenar una conmutación por error forzada. Usa esta opción solo cuando desees delegar la responsabilidad de recuperación ante desastres en Microsoft y la aplicación es tolerante a RTO (tiempo de inactividad) de al menos una hora o más. |
Sí |
Administrado por el cliente
En raras ocasiones, la disponibilidad integrada o la alta disponibilidad no es suficiente para mitigar una interrupción y las bases de datos de un grupo de conmutación por error podrían no estar disponibles durante una duración que no es aceptable para el acuerdo de nivel de servicio (SLA) de las aplicaciones que usan las bases de datos. Las bases de datos pueden no estar disponibles debido a un problema localizado que afecta a solo unas pocas bases de datos o podrían estar en el centro de datos, la zona de disponibilidad o el nivel de región. En cualquiera de estos casos, para restaurar la continuidad empresarial, puedes iniciar una conmutación por error forzada.
Se recomienda encarecidamente establecer la directiva de conmutación por error como administrada por el cliente, ya que mantienes el control de cuándo iniciar una conmutación por error y restaurar la continuidad empresarial. Puedes iniciar una conmutación por error cuando observe una interrupción inesperada que afecte a una o varias bases de datos del grupo de conmutación por error.
Administrado por Microsoft
Con una directiva de conmutación por error administrada por Microsoft, la responsabilidad de recuperación ante desastres se delega al servicio Azure SQL. Para que el servicio Azure SQL inicie una conmutación por error forzada, se deben cumplir las siguientes condiciones:
- Interrupción del nivel de centro de datos, zona de disponibilidad o región causada por un evento de desastre natural, cambios en la configuración, errores de software o errores de componentes de hardware y muchas bases de datos de la región afectadas.
- El período de gracia ha expirado. Dado que la comprobación de la escala de la interrupción y la rapidez con que se puede mitigar conllevan acciones humanas, el período de gracia no se puede establecer por debajo de una hora.
Cuando se cumplen estas condiciones, el servicio Azure SQL inicia conmutaciones por error forzadas para todos los grupos de conmutación por error de la región que tienen la directiva de conmutación por error establecida en Administrada por Microsoft.
Importante
Use la directiva de conmutación por error administrada por el cliente para probar e implementar el plan de recuperación ante desastres. No confíe en la conmutación por error administrada por Microsoft, que solo ejecutaría Microsoft en circunstancias extremas. Se iniciaría una conmutación por error administrada por Microsoft para todos los grupos de conmutación por error de la región que tienen la directiva de conmutación por error establecida en administrado por Microsoft. No se puede iniciar para un grupo de conmutación por error individual. Si necesita la capacidad de conmutar por error de forma selectiva el grupo de conmutación por error, use la directiva de conmutación por error administrada por el cliente.
Establece la directiva de conmutación por error en Administrada por Microsoft solo cuando:
- Quieras delegar la responsabilidad de recuperación ante desastres en el servicio Azure SQL.
- La aplicación es tolerante a que la base de datos no esté disponible durante al menos una hora o más.
- Es aceptable desencadenar conmutaciones por error forzadas algún tiempo después de que expire el período de gracia, ya que el tiempo real de la conmutación por error forzada puede variar significativamente.
- Es aceptable que todas las bases de datos del grupo de conmutación por error conmuten por error, independientemente de su configuración de redundancia de zona o estado de disponibilidad. Aunque las bases de datos configuradas para la redundancia de zona son resistentes a errores zonales y podrían no verse afectadas por una interrupción, seguirán conmutando por error si forman parte de un grupo de conmutación por error con una directiva de conmutación por error Administrada por Microsoft.
- Es aceptable tener conmutaciones por error forzadas de bases de datos en el grupo de conmutación por error sin tener en cuenta la dependencia de la aplicación en otros servicios o componentes de Azure usados por la aplicación, lo que puede provocar una degradación del rendimiento o una falta de disponibilidad de la aplicación.
- Es aceptable incurrir en una cantidad desconocida de pérdida de datos, ya que el tiempo exacto de la conmutación por error forzada no se puede controlar y omite el estado de sincronización de las bases de datos secundarias.
- Todas las bases de datos principales y secundarias del grupo de conmutación por error, y cualquier relación de replicación geográfica, tienen el mismo nivel de servicio, nivel de proceso (aprovisionado o sin servidor) y tamaño de proceso (DTU o núcleos virtuales). Si el objetivo de nivel de servicio (SLO) de todas las bases de datos no coincide, la directiva de conmutación por error se actualizará finalmente de administrada por Microsoft a administrada por el cliente mediante el servicio Azure SQL.
Cuando Microsoft desencadena una conmutación por error, se agrega una entrada para el nombre de operación de Conmutación por error del grupo de conmutación por error de Azure SQL al registro de actividad de Azure Monitor. La entrada incluye el nombre del grupo de conmutación por error en Recurso y Evento iniciado por muestra un solo guión (-) para indicar que Microsoft inició la conmutación por error. Esta información también se puede encontrar en la página Registro de actividad del nuevo servidor principal o instancia de Azure Portal.
Terminología y funcionalidades
Grupo de conmutación por error (FOG)
Un grupo de conmutación por error es un grupo con nombre de bases de datos administradas por un único servidor lógico en Azure que conmuta por error como una unidad a otra región en caso de que algunas o todas las bases de datos principales estén deshabilitadas por una interrupción en la región primaria.
Importante
El nombre del grupo de conmutación por error debe ser único globalmente en el dominio
.database.windows.net.Servidores
Algunas o todas las bases de datos de usuario de un servidor lógico pueden colocarse en un grupo de conmutación por error. Además, un servidor admite varios grupos de conmutación por error en un único servidor.
Principal
Servidor lógico que hospeda las bases de datos principales en el grupo de conmutación por error.
Secundario
Servidor lógico que hospeda las bases de datos secundarias en el grupo de conmutación por error. La base de datos secundaria no puede estar en la misma región de Azure que la principal.
Conmutación por error (sin pérdida de datos)
La conmutación por error realiza una sincronización de datos completa entre las bases de datos principales y secundarias antes de que el rol principal pase a la secundaria. De esta manera se garantiza que no hay pérdida de datos. La conmutación por error solo es posible cuando se puede acceder a la principal. La conmutación por error se usa en los siguientes escenarios:
- Realizar simulacros de recuperación ante desastres (DR) en producción cuando no es aceptable la pérdida de datos
- Reubicar la carga de trabajo a una región diferente
- Devolver la carga de trabajo a la región primaria después de que se ha corregido la interrupción (conmutación por recuperación)
Conmutación por error forzada (posible pérdida de datos)
La conmutación por error forzada cambia inmediatamente el rol secundario al rol primario sin tener que esperar a que los cambios recientes se propaguen desde el rol primario. Esta operación puede dar lugar a una potencial pérdida de datos. La conmutación por error forzada se usa como método de recuperación durante las interrupciones cuando no es posible acceder a la base de datos principal. Cuando se mitiga la interrupción, la base de datos principal anterior se vuelve a conectar automáticamente y se convierte en una nueva base de datos secundaria. Asimismo, se puede ejecutar una conmutación por error para realizar una conmutación por recuperación y devolver las réplicas a sus roles principal y secundario originales.
Período de gracia con pérdida de datos
Dado que los datos se replican en la base de datos secundaria mediante la replicación asincrónica, la conmutación por error forzada de grupos con directivas de conmutación por error administradas por Microsoft puede provocar la pérdida de datos. Puedes personalizar la directiva de conmutación por error para que refleje la tolerancia de la aplicación a la pérdida de datos. Si configuras
GracePeriodWithDataLossHours, puedes controlar durante cuánto tiempo espera el servicio Azure SQL antes de iniciar la conmutación por error forzada, aunque es probable que genere una pérdida de datos.
Incorporación de bases de datos únicas a un grupo de conmutación por error
Puede poner varias bases de datos únicas en el mismo servidor lógico e incluirlas en el mismo grupo de conmutación por error. Si agregas una base de datos única al grupo de conmutación por error, automáticamente se creará una base de datos secundaria con la misma edición y el mismo tamaño de proceso en el servidor secundario que especificaste cuando se creó el grupo de conmutación por error. Si agrega una base de datos que ya tenga una base de datos secundaria en el servidor secundario, el grupo heredará el vínculo de replicación geográfica. Cuando se agrega una base de datos que ya tiene una base de datos secundaria en un servidor que no forma parte del grupo de conmutación por error, se crea otra base de datos secundaria en el servidor secundario.
Importante
- Asegúrate de que el servidor lógico secundario no tenga una base de datos con el mismo nombre, a menos que sea una base de datos secundaria existente.
- Si una base de datos contiene objetos OLTP en memoria, la base de datos principal y la de réplica geográfica secundaria de destino deben tener niveles de servicio coincidentes, ya que los objetos OLTP en memoria residen en memoria. Un nivel de servicio inferior en la base de datos de réplica geográfica puede dar lugar a problemas de memoria insuficiente. Si esto ocurre, es posible que la réplica geográfica no pueda recuperar la base de datos, lo que provoca una falta de disponibilidad de la base de datos secundaria junto con objetos OLTP en memoria en la base de datos geográfica secundaria. Esto, a su vez, puede hacer que las conmutaciones por error también sean incorrectas. Para evitarlo, asegúrese de que el nivel de servicio de la base de datos secundaria geográfica coincide con el de la base de datos principal. Las actualizaciones de nivel de servicio pueden ser operaciones de tamaño de datos y es posible que tarden en finalizar.
Incorporación de bases de datos de un grupo elástico a un grupo de conmutación por error
Puede poner varias bases de datos en el mismo grupo elástico e incluirlas en el mismo grupo de conmutación por error. Si la base de datos principal está en un grupo elástico, la base de datos secundaria se creará automáticamente en un grupo elástico con el mismo nombre (grupo secundario). Debe asegurarse de que el servidor secundario contiene un grupo elástico con el mismo nombre exacto y suficiente capacidad libre para hospedar las bases de datos secundarias que va a crear el grupo de conmutación por error. Si agrega una base de datos en un grupo que ya tiene una base de datos secundaria en el grupo secundario, el grupo heredará el vínculo de replicación geográfica. Cuando se agrega una base de datos que ya tiene una base de datos secundaria en un servidor que no forma parte del grupo de conmutación por error, se crea otra base de datos secundaria en el grupo secundario.
Agente de escucha de lectura-escritura de grupo de conmutación por error
Un registro CNAME de DNS que apunta a la base de datos principal actual. Se crea automáticamente cuando se crea el grupo de conmutación por error y permite que la carga de trabajo de lectura y escritura se vuelva a conectar de forma transparente a la principal cuando esta cambia después de la conmutación por error. Cuando se crea el grupo de conmutación por error en un servidor, el registro CNAME de DNS para la dirección URL del cliente de escucha tiene el formato
<fog-name>.database.windows.net. Tras la conmutación por error, el registro de DNS se actualiza automáticamente para redirigir al agente de escucha a la nueva principal.Agente de escucha de solo lectura de grupo de conmutación por error
Un registro CNAME de DNS que apunta a la base de datos secundaria actual. Se crea automáticamente cuando se crea el grupo de conmutación por error y permite que la carga de trabajo de SQL de solo lectura se vuelva a conectar de forma transparente a la secundaria cuando la secundaria cambia después de la conmutación por error. Cuando se crea el grupo de conmutación por error en un servidor, el registro CNAME de DNS para la dirección URL del cliente de escucha tiene el formato
<fog-name>.secondary.database.windows.net. De forma predeterminada, la conmutación por error del agente de escucha de solo lectura está deshabilitada, ya que garantiza que el rendimiento de la principal no se vea afectado cuando la base de datos secundaria esté sin conexión. En cambio, también significa que las sesiones de solo lectura no podrán conectarse hasta que se recupere la base de datos secundaria. Si no puedes tolerar tiempo de inactividad en las sesiones de solo lectura pero sí, usar la base de datos principal para el tráfico de solo lectura y el de lectura y escritura a costa de la posible degradación del rendimiento de esta, puedes habilitar la conmutación por error para el agente de escucha de solo lectura mediante la configuración de la propiedadAllowReadOnlyFailoverToPrimary. En ese caso, el tráfico de solo lectura se redirige automáticamente a la base de datos principal si la secundaria no está disponible.Nota:
La propiedad
AllowReadOnlyFailoverToPrimarysolo surte efecto si la directiva de conmutación por error administrada por Microsoft está habilitada y si se ha desencadenado una conmutación por error forzada. En ese caso, si la propiedad se establece en true, la nueva base de datos principal atenderá a las sesiones de lectura y escritura, y de solo lectura.Varios grupos de conmutación por error
Puede configurar varios grupos de conmutación por error para el mismo par de servidores con el fin de controlar el ámbito de las conmutaciones por error geográficas. Cada grupo realiza la conmutación por error por separado. Si la aplicación de inquilino por base de datos se implementa en varias regiones y usa grupos elásticos, puede usar esta funcionalidad para combinar las bases de datos principales y secundarias en cada grupo. De este modo, puedes reducir el impacto de una interrupción a solo algunas bases de datos de inquilino.
Arquitectura del grupo de conmutación por error
Un grupo de conmutación por error en Azure SQL Database puede incluir una o varias bases de datos, utilizadas normalmente por la misma aplicación. Un grupo de conmutación por error debe estar configurado en el servidor principal y se conectará al servidor secundario de una región de Azure diferente. Los grupos de conmutación por error pueden incluir todas las bases de datos o algunas de ellas en el servidor principal. En el siguiente diagrama se ilustra una configuración típica de una aplicación de nube con redundancia geográfica que usa varias bases de datos y un grupo de conmutación por error:
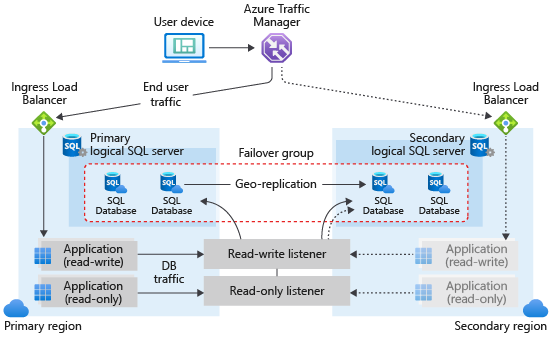
Al diseñar un servicio con la continuidad empresarial en mente, siga las instrucciones generales y los procedimientos recomendados que se describen en este artículo. Al configurar un grupo de conmutación por error, asegúrese de que la autenticación y el acceso a la red de la base de datos secundaria estén configuradas para funcionar correctamente después de la conmutación por error geográfica, cuando la base de datos secundaria geográfica se convierte en la nueva principal. Para obtener más información, consulte Administración de la seguridad de Azure SQL Database después de la recuperación ante desastres. Para más información, consulta Diseño de soluciones en la nube para la recuperación ante desastres.
Uso de regiones emparejadas
Al crear el grupo de conmutación por error entre el servidor principal y secundario, usa regiones emparejadas, ya que los grupos de conmutación por error de las regiones emparejadas tienen un mejor rendimiento en comparación con las regiones no emparejadas.
Siguiendo los procedimientos de implementación seguros, Azure SQL Database normalmente no actualiza las regiones emparejadas al mismo tiempo. Sin embargo, no es posible predecir qué región se actualizará primero, por lo que no se garantiza el orden de implementación. A veces, el servidor principal se actualiza primero y, a veces, se actualiza en segundo lugar.
Si tienes grupos de replicación geográfica o grupos de conmutación por error configurados para bases de datos que no se alinean con el emparejamiento de regiones de Azure, usa diferentes programaciones de ventanas de mantenimiento para las bases de datos principales y secundarias. Por ejemplo, puedes seleccionar la ventana de mantenimiento Día de la semana para la base de datos secundaria y la ventana de mantenimiento Fin de semana para la base de datos principal.
Propagación inicial
Al agregar bases de datos o grupos elásticos a un grupo de conmutación por error, hay una fase de propagación inicial antes de que se inicie la replicación de datos. Esta fase de propagación inicial es la operación más larga y costosa. Una vez completada, se sincronizan los datos y, luego, solo se replican los cambios de datos posteriores. El tiempo que tarda la propagación inicial en completarse depende del tamaño de sus datos, la cantidad de bases de datos replicadas, la carga en las bases de datos primarias y la velocidad del enlace de red entre la base de datos primaria y la secundaria. En circunstancias normales, la velocidad posible de propagación es de hasta 500 GB por hora para Azure SQL Database. La propagación se realiza en paralelo para todas las bases de datos.
Número de bases de datos del grupo de conmutación por error
El número de bases de datos dentro de un grupo de conmutación por error afecta directamente a la duración de las operaciones de conmutación por error y conmutación por error forzada.
- Durante una conmutación por error (también conocida como conmutación por error planeada), se garantiza que todas las bases de datos principales estén totalmente sincronizadas con su secundario y lleguen a un estado listo. Para evitar sobrecargar el plano de control, las bases de datos se preparan en lotes. Por lo tanto, se recomienda limitar el número de bases de datos de un grupo de conmutación por error.
- En el caso de una conmutación por error forzada, la fase de preparación se acelera a medida que no se inicia la sincronización de datos. Para lograr duraciones de conmutación por error más rápidas y predecibles, puede ser beneficioso mantener el número de bases de datos del grupo de conmutación por error en un número menor.
Uso de varios grupos de conmutación por error para conmutar por error varias bases de datos
Se pueden crear uno o más grupos de conmutación por error entre dos servidores en regiones distintas (servidor principal y servidor secundario). Cada grupo puede incluir una o varias bases de datos que se recuperan como unidad en caso de que una o todas las bases de datos principales dejen de estar disponibles debido a una interrupción en la región primaria. La creación de un grupo de conmutación por error crea bases de datos geográficas secundarias con el mismo objetivo de servicio que la principal. Si agrega una relación de replicación geográfica existente a un grupo de conmutación por error, asegúrese de que la base de datos geográfica secundaria esté configurada con el mismo nivel de servicio y tamaño de proceso que la principal.
Uso del cliente de escucha de lectura y escritura (principal)
Para cargas de trabajo de lectura y escritura, use <fog-name>.database.windows.net como nombre del servidor en la cadena de conexión. Las conexiones se dirigen automáticamente a la principal. Este nombre no cambia después de la conmutación por error. Tenga en cuenta que la conmutación por error implica actualizar el registro DNS para que las conexiones de cliente se redirijan a la nueva base de datos principal cuando la caché DNS del cliente se haya actualizado. El período de vida (TTL) del registro DNS del agente de escucha principal y secundario es de 30 segundos.
Uso del cliente de escucha de solo lectura (secundaria)
Si tiene cargas de trabajo de solo lectura aisladas lógicamente que son tolerantes a la latencia de datos, puede ejecutarlas en la base de datos secundaria geográfica. Para sesiones de solo lectura, use <fog-name>.secondary.database.windows.net como nombre del servidor en la cadena de conexión. Las conexiones se dirigen automáticamente a la secundaria geográfica. También se recomienda indicar la intención de lectura en la cadena de conexión mediante ApplicationIntent=ReadOnly.
En los niveles de servicio Prémium, Crítico para la empresa e Hiperescala, SQL Database admite el uso de réplicas de solo lectura para descargar las cargas de trabajo de consulta de solo lectura, mediante el parámetro ApplicationIntent=ReadOnly de la cadena de conexión. Cuando se ha configurado una base de datos secundaria geográfica, puedes usar esta funcionalidad para conectarte a una réplica de solo lectura de la ubicación principal o de la ubicación secundaria geográfica:
Para conectarse a una réplica de solo lectura en la ubicación secundaria, use ApplicationIntent=ReadOnlyy <fog-name>.secondary.database.windows.net.
Posible degradación del rendimiento después de la conmutación por error
Una aplicación de Azure típica usa varios servicios de Azure y consta de varios componentes. La conmutación por error de un grupo se desencadena en función del estado de Azure SQL Database por sí sola. Es posible que otros servicios de Azure de la región primaria no se vean afectados por la interrupción y que sus componentes sigan estando disponibles en esa región. Una vez que las bases de datos principales cambien a la región secundaria de DR, la latencia entre los componentes dependientes puede aumentar. Para evitar el impacto de una mayor latencia en el rendimiento de la aplicación, asegúrese de la redundancia de todos los componentes de la aplicación en la región de DR, siga estas directrices de seguridad de red y organice la conmutación por error geográfica de los componentes de aplicación pertinentes junto con la base de datos.
Posible pérdida de datos después de la conmutación por error forzada
Si se produce una interrupción en la región primaria, es posible que las transacciones recientes no se hayan replicado en la base de datos secundaria geográfica y que se produzca una pérdida de datos si se realiza una conmutación por error forzada.
Importante
Los grupos elásticos con 800 o menos DTU, 8 o menos núcleos virtuales y más de 250 bases de datos pueden encontrar problemas, como conmutaciones por error planeadas más prolongadas y un menor rendimiento. Es más probable que estos problemas sucedan con cargas de trabajo intensivas de escritura, cuando las replicas geográficas están muy separadas por región geográfica, o cuando se utilizan varias réplicas geográficas secundarias para cada base de datos. Un síntoma de estos problemas es un aumento del retraso de replicación geográfica a lo largo del tiempo, lo que puede provocar una pérdida de datos más amplia en una interrupción. Este retardo puede supervisarse con sys.dm_geo_replication_link_status. Si se producen estos problemas, la mitigación incluye escalar verticalmente el grupo para tener más DTU o núcleos virtuales, o bien reducir el número de bases de datos con replicación geográfica del grupo.
Conmutación por recuperación
Cuando los grupos de conmutación por error se configuran con una directiva de conmutación por error administrada por Microsoft, la conmutación por error al servidor geográfico secundario se inicia durante un escenario de desastre según el período de gracia que se definió. La conmutación por recuperación al servidor principal anterior debe iniciarse manualmente.
Permisos y limitaciones
Revisa la guía de configuración del grupo de conmutación por error para obtener una lista de permisos y limitaciones.
Administración mediante programación de grupos de conmutación por error
Los grupos de conmutación por error también se pueden administrar mediante programación con Azure PowerShell, la CLI de Azure y la API de REST. Para más información, consulte Configuración de un grupo de conmutación por error.
Contenido relacionado
- Para los scripts de ejemplo, vea:
- Uso de PowerShell para configurar la replicación geográfica activa para Azure SQL Database
- Uso de PowerShell para configurar la replicación geográfica activa para una base de datos agrupada en Azure SQL Database
- Uso de PowerShell para agregar una instancia de Azure SQL Database a un grupo de conmutación por error
- Para obtener una descripción general y los escenarios de la continuidad empresarial, consulte Continuidad empresarial con Base de datos SQL de Azure
- Para saber en qué consisten las copias de seguridad automatizadas de Azure SQL Database, consulte Información general: copias de seguridad automatizadas de SQL Database.
- Si quiere saber cómo usar las copias de seguridad automatizadas para procesos de recuperación, consulte Recuperación de una base de datos a partir de copias de seguridad iniciadas por un servicio.
- Para obtener información acerca de los requisitos de autenticación para un nuevo servidor principal y la base de datos, consulte Administración de la seguridad de Azure SQL Database después de la recuperación ante desastres.