Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Use Azure Batch para ejecutar aplicaciones de informática de alto rendimiento (HPC) en paralelo y a gran escala, de manera eficaz en Azure. En este tutorial se explica un ejemplo de Python para ejecutar una carga de trabajo paralela mediante Batch. Aprenderá lo que es un flujo de trabajo de aplicación de Batch común y a interactuar con los recursos de Batch y Storage mediante programación.
- Autenticarse en las cuentas de Batch y Storage.
- Cargar archivos de entrada en Storage.
- Crear un grupo de nodos de proceso para ejecutar una aplicación.
- Crear un proceso de trabajo y asignar tareas para procesar archivos de entrada.
- Supervise la ejecución de las tareas.
- Recuperación de archivos de salida.
En este tutorial, convertiremos archivos multimedia MP4 a formato MP3 en paralelo con la herramienta de código de abierto ffmpeg.
Si no tiene una cuenta de Azure, cree una cuenta gratuita antes de comenzar.
Prerrequisitos
Una cuenta de Azure Batch y una cuenta de Azure Storage vinculada. Para crear estas cuentas, consulte las guías de inicio rápido de Batch para Azure Portal o la CLI de Azure.
Concede acceso a tus cuentas de lotes y almacenamiento
Este tutorial muestra cómo autenticarse en Azure Batch y Azure Storage usando Microsoft Entra ID con DefaultAzureCredential. La app no usa claves de cuenta. Antes de ejecutar la aplicación, asegúrate de que la identidad que usas tenga los roles requeridos en ambas cuentas.
Inicia sesión usando la CLI de Azure.
DefaultAzureCredentialDetecta automáticamente este inicio de sesión:az loginAsigna a tu cuenta de usuario un rol que permita operaciones de plano de datos en la cuenta Batch, como Azure Batch Data Contributor. Este rol es necesario para crear grupos, trabajos y tareas. Puedes asignar el rol en la página Control de acceso (IAM) de la cuenta de Batch en el portal de Azure, o usar la CLI de Azure:
az role assignment create \ --assignee "<your-user-principal-name>" \ --role "Azure Batch Data Contributor" \ --scope "/subscriptions/<subscription-id>/resourceGroups/<resource-group>/providers/Microsoft.Batch/batchAccounts/<batch-account-name>"Asigna a tu cuenta de almacenamiento el rol Storage Blob Data Contributor. Este rol debe crear contenedores, subir los archivos de entrada y solicitar la clave de delegación del usuario que firme las URLs de firma de acceso compartido (SAS) utilizadas por las tareas:
az role assignment create \ --assignee "<your-user-principal-name>" \ --role "Storage Blob Data Contributor" \ --scope "/subscriptions/<subscription-id>/resourceGroups/<resource-group>/providers/Microsoft.Storage/storageAccounts/<storage-account-name>"Fíjate en los siguientes valores, que añadirás al archivo config.py de la muestra en la siguiente sección. Puedes encontrarlos en la página de Resumen de cada cuenta en el portal de Azure:
- Nombre de la cuenta de Batch
- URL de cuenta por lotes, por ejemplo
https://mybatchaccount.westus2.batch.azure.com - Nombre de la cuenta de almacenamiento
Note
Puede tardar unos minutos en propagarse la asignación de roles. Si la app falla con un error de autorización inmediatamente después de asignar los roles, espera unos minutos y vuelve a intentarlo.
Descarga y ejecución de la aplicación de ejemplo
Importante
La muestra descargable en el repositorio batch-python-ffmpeg-tutorial se está actualizando para coincidir con este tutorial. Hasta que esa actualización se publique, el repositorio podría seguir conteniendo la autenticación basada en claves anterior y el código de Ubuntu 20.04. El código de este artículo es la fuente de la verdad. Si la muestra descargada no coincide con los fragmentos aquí, sigue el código mostrado en este artículo.
Descarga de la aplicación de ejemplo
Descargue o clone la aplicación de ejemplo desde GitHub. Para clonar el repositorio de la aplicación de ejemplo con un cliente de Git, use el siguiente comando:
git clone https://github.com/Azure-Samples/batch-python-ffmpeg-tutorial.git
Vaya al directorio que contiene el archivo batch_python_tutorial_ffmpeg.py.
En el entorno de Python, instale los paquetes necesarios mediante pip.
pip install -r requirements.txt
Use un editor de código para abrir el archivo config.py. Actualice los valores de cuenta de almacenamiento con los nombres únicos correspondientes. En el ejemplo se usa DefaultAzureCredential para autenticarse, por lo que las claves de cuenta ya no son necesarias. Por ejemplo:
_BATCH_ACCOUNT_NAME = 'yourbatchaccount'
_BATCH_ACCOUNT_URL = 'https://yourbatchaccount.yourbatchregion.batch.azure.com'
_STORAGE_ACCOUNT_NAME = 'mystorageaccount'
Asegúrate de haber iniciado sesión usando az login y que tu identidad tenga los roles descritos en Conceder acceso a tus cuentas de lote y almacenamiento.
DefaultAzureCredentialTambién puede descubrir otras fuentes de credenciales, como una identidad gestionada, Visual Studio Code o variables de entorno.
Ejecución de la aplicación
Para ejecutar el script:
python batch_python_tutorial_ffmpeg.py
Al ejecutar la aplicación de ejemplo, la salida de la consola es similar a la siguiente. Durante la ejecución, se experimenta una pausa en Monitoring all tasks for 'Completed' state, timeout in 00:30:00... mientras se inician los nodos de ejecución del grupo.
Sample start: 11/28/2018 3:20:21 PM
Container [input] created.
Container [output] created.
Uploading file LowPriVMs-1.mp4 to container [input]...
Uploading file LowPriVMs-2.mp4 to container [input]...
Uploading file LowPriVMs-3.mp4 to container [input]...
Uploading file LowPriVMs-4.mp4 to container [input]...
Uploading file LowPriVMs-5.mp4 to container [input]...
Creating pool [LinuxFFmpegPool]...
Creating job [LinuxFFmpegJob]...
Adding 5 tasks to job [LinuxFFmpegJob]...
Monitoring all tasks for 'Completed' state, timeout in 00:30:00...
Success! All tasks reached the 'Completed' state within the specified timeout period.
Deleting container [input]....
Sample end: 11/28/2018 3:29:36 PM
Elapsed time: 00:09:14.3418742
Vaya a la cuenta de Batch en Azure Portal para supervisar el grupo, los nodos de ejecución, el trabajo y las tareas. Por ejemplo, para ver un mapa térmico de los nodos de proceso del grupo, seleccione Grupos>LinuxFfmpegPool.
Con las tareas en ejecución, el mapa térmico es similar al siguiente:
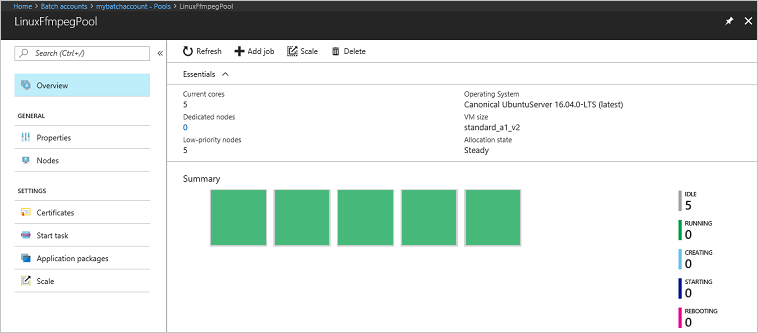
El tiempo de ejecución típico es de aproximadamente 5 minutos cuando se ejecuta la aplicación en su configuración predeterminada. La creación del pool es lo que más tiempo lleva.
Recuperación de archivos de salida
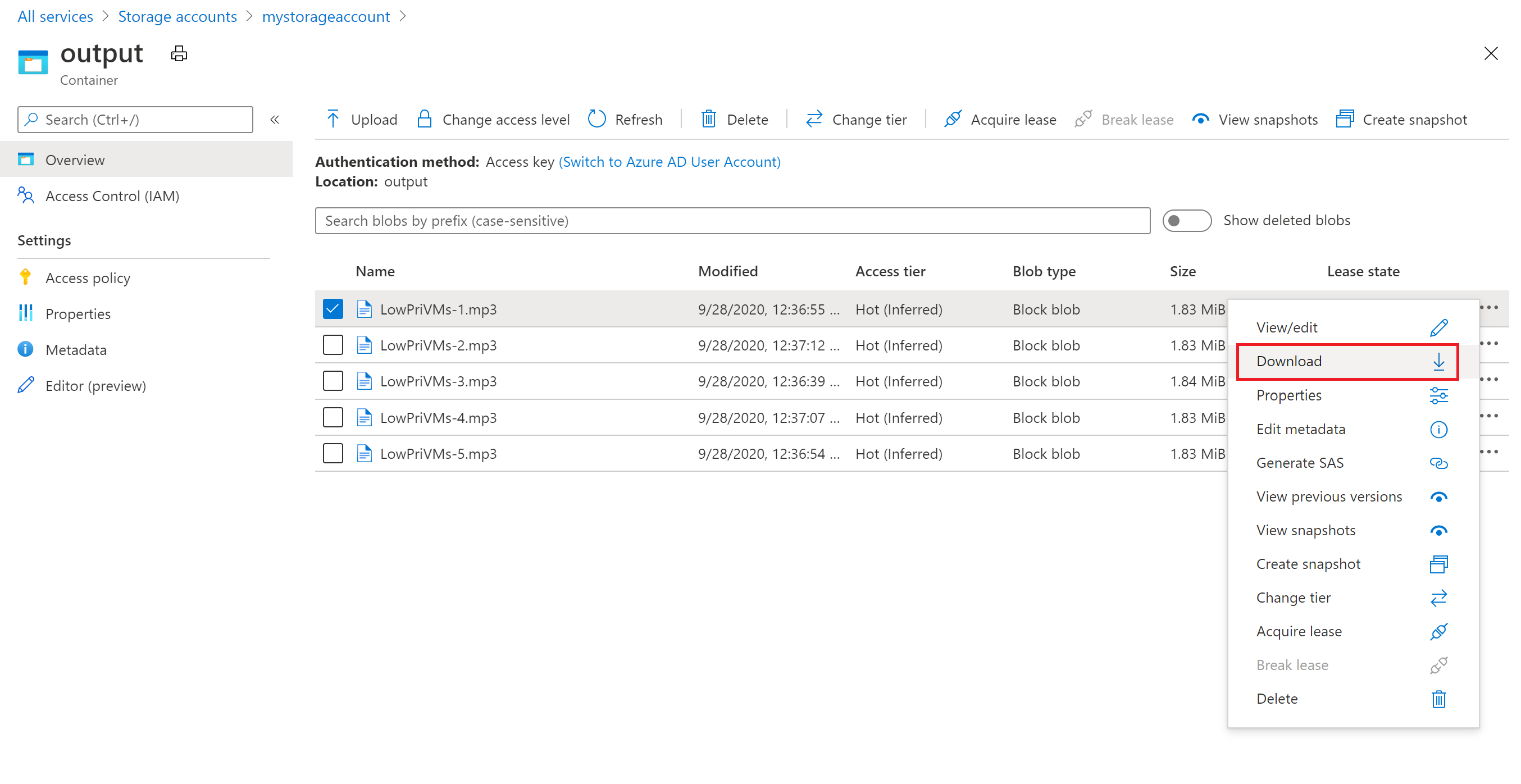
Puede usar Azure Portal para descargar los archivos MP3 de salida generados por las tareas de ffmpeg.
- Haga clic en Todos los servicios>Cuentas de almacenamiento y haga clic en el nombre de la cuenta de almacenamiento.
- Haga clic en Blobs>salida.
- Haga clic con el botón derecho en uno de los archivos MP3 de salida y, después, haga clic en Descargar. Para abrir o guardar el archivo, siga las indicaciones del explorador.
Aunque no se muestra en este ejemplo, los archivos también se pueden descargar mediante programación desde los nodos de proceso o desde el contenedor de almacenamiento.
Revisión del código
En las secciones siguientes se desglosan los pasos que lleva a cabo la aplicación de ejemplo para procesar una carga de trabajo en el servicio Batch. Consulte el código de Python mientras lee el resto de este artículo, ya que no se describe todas las líneas de código del ejemplo.
Autenticación de los clientes de Blob y Batch
El ejemplo se autentica con Storage y Batch mediante DefaultAzureCredential desde el paquete azure-identity .
DefaultAzureCredential intenta varios tipos de credenciales en orden (variables de entorno, identidad administrada, CLI de Azure inicio de sesión, etc.), lo que hace que el mismo código funcione en el desarrollo local y en producción sin almacenar claves de cuenta.
Para interactuar con una cuenta de almacenamiento, la aplicación usa el paquete azure-storage-blob para crear un objeto BlobServiceClient que use la credencial.
La muestra importa los siguientes tipos de identidad y almacenamiento, y lee los nombres de cuenta de config.py:
import config
from azure.identity import DefaultAzureCredential
from azure.storage.blob import (
BlobServiceClient,
BlobSasPermissions,
ContainerSasPermissions,
generate_blob_sas,
generate_container_sas,
)
credential = DefaultAzureCredential()
blob_service_client = BlobServiceClient(
account_url=f"https://{config._STORAGE_ACCOUNT_NAME}.blob.core.windows.net/",
credential=credential)
La aplicación crea un objeto BatchClient para crear y administrar grupos, trabajos y tareas en el servicio Batch. El cliente de Batch usa el mismo DefaultAzureCredential para autenticarse a través de Microsoft Entra ID.
batch_client = BatchClient(
endpoint=config._BATCH_ACCOUNT_URL,
credential=credential)
Los nodos de cómputo por lotes acceden a los contenedores de entrada y salida utilizando URLs de firma de acceso compartido (SAS). Como la app no usa la clave de la cuenta de almacenamiento, no puede firmar tokens SAS con ella. En su lugar, la aplicación solicita una clave de delegación de usuario al servicio Blob, que está firmada con las credenciales de Microsoft Entra de la app, y utiliza esa clave para generar los tokens SAS. Para obtener más información, consulte Creación de una SAS de delegación de usuarios.
start = datetime.datetime.now(datetime.timezone.utc)
expiry = start + datetime.timedelta(hours=4)
user_delegation_key = blob_service_client.get_user_delegation_key(
key_start_time=start, key_expiry_time=expiry)
# Sign the SAS tokens with the same expiry as the user delegation key.
sas_expiry = expiry
Note
La clave de delegación de usuario en este ejemplo es válida durante cuatro horas. Un token SAS firmado con una clave de delegación de usuario no puede tener una duración superior a la de la clave, y una clave de delegación de usuario puede tener una validez máxima de siete días. Para cargas de trabajo de larga duración, solicita una nueva clave y regenera las URLs SAS antes de que expiren.
Carga de archivos de entrada
Después de crear los contenedores de entrada y salida con blob_service_client, la app sube cada archivo MP4 local de la carpeta InputFiles al contenedor de entrada. El siguiente upload_file_to_container asistente sube un único archivo, genera un token SAS de solo lectura para él que está firmado con la clave de delegación de usuario, y devuelve un objeto Batch ResourceFile cuya URL incluye el token SAS para que Batch pueda descargar el archivo posteriormente a un nodo de cómputo. La app llama a este ayudante una vez por cada archivo de entrada:
def upload_file_to_container(blob_service_client, user_delegation_key,
sas_expiry, container_name, file_path):
blob_name = os.path.basename(file_path)
blob_client = blob_service_client.get_blob_client(container_name, blob_name)
with open(file_path, "rb") as data:
blob_client.upload_blob(data, overwrite=True)
sas_token = generate_blob_sas(
account_name=config._STORAGE_ACCOUNT_NAME,
container_name=container_name,
blob_name=blob_name,
user_delegation_key=user_delegation_key,
permission=BlobSasPermissions(read=True),
expiry=sas_expiry)
sas_url = f"{blob_client.url}?{sas_token}"
return models.ResourceFile(http_url=sas_url, file_path=blob_name)
La aplicación también genera una URL SAS para el contenedor de salida que concede acceso de escritura. Las tareas utilizan esta URL para subir sus archivos de salida al almacenamiento:
sas_token = generate_container_sas(
account_name=config._STORAGE_ACCOUNT_NAME,
container_name=output_container_name,
user_delegation_key=user_delegation_key,
permission=ContainerSasPermissions(write=True, create=True, list=True),
expiry=sas_expiry)
output_container_sas_url = (
f"https://{config._STORAGE_ACCOUNT_NAME}.blob.core.windows.net/"
f"{output_container_name}?{sas_token}")
Crear un grupo de nodos de cómputo
A continuación, el ejemplo crea un grupo de nodos de proceso en la cuenta de Batch mediante una llamada a create_pool. Esta función definida usa la clase BatchPoolCreateOptions para establecer el número de nodos, el tamaño de la máquina virtual y una configuración de grupo. En esta configuración, un objeto VirtualMachineConfiguration especifica una BatchVmImageReference para una imagen de Ubuntu Server 22.04 LTS publicada en Azure Marketplace. Batch es compatible con una amplia gama de imágenes de máquina virtual de Azure Marketplace, así como con las imágenes de máquina virtual personalizadas.
El número de nodos y el tamaño de la máquina virtual se establecen mediante constantes definidas. Batch admite nodos dedicados y nodos Spot, y puedes usar cualquiera de ellos o ambos en tus grupos. Los nodos dedicados están reservados para el grupo. Los nodos de acceso puntual se ofrecen a precio reducido por la capacidad sobrante de las máquinas virtuales de Azure. Los nodos de acceso puntual no estarán disponibles si Azure no tiene suficiente capacidad. El ejemplo crea de forma predeterminada un grupo que contiene solo cinco nodos de spot de tamaño Standard_A1_v2.
Además de las propiedades del nodo físico, esta configuración del grupo incluye un objeto BatchStartTask . BatchStartTask se ejecuta en cada nodo a medida que ese nodo se une al grupo y cada vez que se reinicia un nodo. En este ejemplo, BatchStartTask ejecuta comandos de shell de Bash para instalar el paquete ffmpeg y las dependencias en los nodos.
El método create_pool envía el grupo al servicio Batch.
new_pool = models.BatchPoolCreateOptions(
id=pool_id,
virtual_machine_configuration=models.VirtualMachineConfiguration(
image_reference=models.BatchVmImageReference(
publisher="canonical",
offer="0001-com-ubuntu-server-jammy",
sku="22_04-lts",
version="latest"
),
node_agent_sku_id="batch.node.ubuntu 22.04"),
vm_size=_POOL_VM_SIZE,
target_dedicated_nodes=_DEDICATED_POOL_NODE_COUNT,
target_low_priority_nodes=_LOW_PRIORITY_POOL_NODE_COUNT,
start_task=models.BatchStartTask(
command_line="/bin/bash -c \"apt-get update && apt-get install -y ffmpeg\"",
wait_for_success=True,
user_identity=models.UserIdentity(
auto_user=models.AutoUserSpecification(
scope=models.AutoUserScope.POOL,
elevation_level=models.ElevationLevel.ADMIN)),
)
)
batch_client.create_pool(pool=new_pool)
Note
Las imágenes de VM del Marketplace y los agentes de nodos por lotes tienen fechas de finalización de soporte. Las imágenes LTS de Ubuntu Server 20.04 y el batch.node.ubuntu 20.04 agente node ya no son compatibles para nuevos pools de batch. Para enumerar las referencias de imagen y los SKU del agente de nodo que admite actualmente tu cuenta de Batch, llama al método list_supported_images.
Crear un trabajo
Un trabajo de Batch especifica un grupo en el que ejecutar tareas y valores de configuración opcionales, como la prioridad y la programación del trabajo. El ejemplo crea un trabajo al llamar a create_job. Esta función definida usa la clase BatchJobCreateOptions para crear un trabajo en el grupo. El método create_job envía el trabajo al servicio por lotes. Inicialmente, el trabajo no tiene tareas.
job = models.BatchJobCreateOptions(
id=job_id,
pool_info=models.BatchPoolInfo(pool_id=pool_id))
batch_client.create_job(job=job)
Crear tareas
La aplicación crea tareas en el trabajo con una llamada a add_tasks. Esta función definida crea una lista de objetos de tarea mediante la clase BatchTaskCreateOptions . Cada tarea ejecuta ffmpeg para procesar un objeto de entrada resource_files mediante un command_line parámetro . Al crear el grupo, ffmpeg se instaló previamente en todos los nodos. En este caso, la línea de comandos ejecuta ffmpeg para convertir los archivos MP4 de entrada (vídeo) en archivos MP3 (audio).
En el ejemplo se crea un objeto OutputFile para el archivo MP3 después de ejecutar la línea de comandos. Los archivos de salida de cada tarea (uno, en este caso) se cargan en un contenedor de la cuenta de almacenamiento vinculada mediante la propiedad de la output_files tarea.
A continuación, la aplicación agrega tareas al trabajo con el método create_tasks , que los pone en cola para ejecutarse en los nodos de proceso.
tasks = list()
for idx, input_file in enumerate(input_files):
input_file_path = input_file.file_path
output_file_path = "".join((input_file_path).split('.')[:-1]) + '.mp3'
command = "/bin/bash -c \"ffmpeg -i {} {} \"".format(
input_file_path, output_file_path)
tasks.append(models.BatchTaskCreateOptions(
id='Task{}'.format(idx),
command_line=command,
resource_files=[input_file],
output_files=[models.OutputFile(
file_pattern=output_file_path,
destination=models.OutputFileDestination(
container=models.OutputFileBlobContainerDestination(
container_url=output_container_sas_url)),
upload_options=models.OutputFileUploadConfiguration(
upload_condition=models.OutputFileUploadCondition.TASK_SUCCESS))]
)
)
batch_client.create_tasks(job_id=job_id, task_collection=tasks)
Supervisión de tareas
Cuando se agregan tareas a un trabajo, Batch las pone automáticamente en cola y las programa para su ejecución en los nodos de proceso del grupo asociado. Según la configuración que especifique, Batch controla la administración de las colas, la programación, los reintentos y otras labores de administración de tareas.
Hay muchos enfoques para supervisar la ejecución de tareas. La wait_for_tasks_to_complete función de este ejemplo usa el objeto BatchTaskState para supervisar las tareas de un estado determinado, en este caso el estado completado, dentro de un límite de tiempo.
while datetime.datetime.now() < timeout_expiration:
print('.', end='')
sys.stdout.flush()
tasks = batch_client.list_tasks(job_id=job_id)
incomplete_tasks = [task for task in tasks if
task.state != models.BatchTaskState.COMPLETED]
if not incomplete_tasks:
print()
return True
else:
time.sleep(5)
...
Limpieza de recursos
Después de ejecutar las tareas, la aplicación elimina automáticamente el contenedor de almacenamiento de entrada que creó y ofrece la opción de eliminar el grupo y el trabajo de Batch. Los métodos begin_delete_job y begin_delete_pool de la BatchClient clase inician cada uno la operación de eliminación correspondiente cuando confirmas el prompt. Aunque no te cobran por los trabajos y tareas en sí, sí te cobran por los nodos de cómputo. Por tanto, asigna fondos solo cuando sea necesario. Al eliminar el grupo, todos los resultados de las tareas en los nodos también se eliminan. Sin embargo, los archivos de salida permanecen en la cuenta de almacenamiento.
Cuando ya no los necesite, elimine el grupo de recursos, la cuenta de Batch y la de Storage. Para ello, en Azure Portal, seleccione el grupo de recursos de la cuenta de Batch y elija Eliminar grupo de recursos.
Pasos siguientes
En este tutorial, ha aprendido a:
- Autenticarse en las cuentas de Batch y Storage.
- Cargar archivos de entrada en Storage.
- Crear un grupo de nodos de proceso para ejecutar una aplicación.
- Crear un proceso de trabajo y asignar tareas para procesar archivos de entrada.
- Supervise la ejecución de las tareas.
- Recuperación de archivos de salida.
Para obtener más ejemplos de uso de la API de Python para programar y procesar cargas de trabajo de Batch, consulte los ejemplos de Python de Batch en GitHub.