Consideraciones de diseño para plataformas de datos de autoservicio
La malla de datos es un enfoque interesante para el diseño y el desarrollo de la arquitectura de datos. A diferencia de la arquitectura de datos tradicional, la malla de datos separa la responsabilidad entre los dominios de datos funcionales que se centran en la creación de productos de datos y un equipo de plataforma que se centra en las funcionalidades técnicas. Esta separación de responsabilidades debe reflejarse en su plataforma. Debe lograr un equilibrio entre proporcionar funcionalidades independientes del dominio y permitir que los equipos de dominio modelen, procesen y distribuyan sus datos en toda la organización.
Elegir el nivel adecuado de granularidad y reglas de dominio para desacoplar mediante plataformas no es fácil. Este artículo contiene varios escenarios que proporcionan instrucciones detalladas.
Análisis a escala de nube
Cuando quiera crear una malla de datos con Azure, se recomienda adoptar análisis a escala de nube. Este marco es una arquitectura de referencia implementable y viene con plantillas de código abierto y procedimientos recomendados. La arquitectura de análisis a escala de nube tiene dos bloques de creación principales que son fundamentales para todas las opciones de implementación:
- Zona de aterrizaje de la administración de datos: La base de su arquitectura de datos. Contiene todas las funcionalidades críticas para la administración de datos, como el catálogo de datos, el linaje de datos, el catálogo de API, la administración de datos maestros, etc.
- Zonas de aterrizaje de datos: suscripciones que hospedan sus soluciones de análisis e inteligencia artificial. Incluyen funcionalidades clave para hospedar una plataforma de análisis.
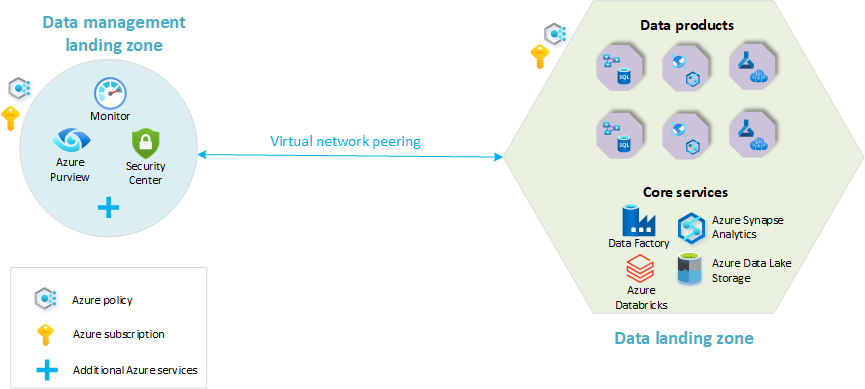
En el diagrama siguiente, se muestra una visión general de una plataforma del escenario de análisis a escala de nube con una zona de aterrizaje de administración de datos y una sola zona de aterrizaje de datos. En este diagrama no se representan todos los servicios de Azure. Se ha simplificado para resaltar los conceptos básicos de la organización de los recursos dentro de la arquitectura.
El marco de análisis basado en la nube no es explícito en cuanto al tipo exacto de arquitectura de datos que debe proporcionar. Puede usarlo para muchas soluciones comunes de análisis a escala de nube, incluidos almacenes de datos (empresariales), lagos de datos, casas de lagos de datos y mallas de datos. Todas las soluciones de ejemplo de este artículo usan la arquitectura de malla de datos.
Comprenda que todas las arquitecturas cumplen los principios de malla de datos: propiedad del dominio, datos como producto, plataforma de datos de autoservicio y gobernanza de cálculo federada. Las diferentes rutas de acceso pueden conducir a una malla de datos. No hay ninguna respuesta correcta o incorrecta. Debe hacer las ventajas adecuadas para las necesidades de su organización.
Zona de aterrizaje de datos única
El patrón de implementación más sencillo para crear una arquitectura de malla de datos implica una zona de aterrizaje de administración de datos y una zona de aterrizaje de datos. La arquitectura de datos en este escenario sería similar a la siguiente:

En este modelo, todos los dominios de datos funcionales residen en la misma zona de aterrizaje de datos. Una sola suscripción contiene un conjunto estándar de servicios. Los grupos de recursos separan distintos dominios de datos y productos de datos. Los servicios de datos estándar, como Azure Data Lake Store, Azure Logic Apps y Azure Synapse Analytics, se aplican a todos los dominios.
Todos los dominios de datos siguen los principios de malla de datos: los datos siguen la propiedad del dominio y los datos se tratan como productos. La plataforma es totalmente de autoservicio, aunque hay variaciones limitadas de los servicios. Todos los dominios deben cumplir firmemente los mismos principios de administración de datos y cumplirlos.
Esta opción de implementación puede ser útil para empresas más pequeñas o proyectos de greenfield que quieran adoptar la malla de datos sin complicar demasiado las cosas. Esta implementación también puede ser un punto de partida para una organización que tiene en mente crear algo más complejo. En este caso, planifique la expansión en varias zonas de aterrizaje más adelante.
Zonas de aterrizaje en línea con el sistema de origen y el consumidor
En el modelo anterior, no hemos tenido en cuenta otras suscripciones ni aplicaciones locales. Puede modificar ligeramente el modelo anterior agregando una zona de aterrizaje alineada con el sistema de origen para administrar todos los datos entrantes. La incorporación de datos es un proceso difícil, por lo que resulta útil tener dos zonas de aterrizaje de datos. La incorporación sigue siendo una de las partes más complicadas del uso de datos en gran tamaño. La incorporación también suele requerir herramientas adicionales para abordar la integración, ya que sus desafíos difieren de los de la integración. Ayuda a distinguir entre proporcionar datos y consumir datos.

En la arquitectura de la izquierda de este diagrama, los servicios facilitan toda la incorporación de datos, como CDC, servicios para extraer API o servicios de lago de datos para compilar conjuntos de datos dinámicamente. Los servicios de esta plataforma pueden extraer datos de entornos locales o en la nube, o de proveedores de SaaS. Este tipo de plataforma suele tener más sobrecarga, ya que hay más acoplamiento con aplicaciones operativas subyacentes. Es posible que quiera tratar esto de forma diferente a cualquier uso de datos.
En la arquitectura de la derecha del diagrama, la organización optimiza el consumo y tiene servicios centrados en convertir los datos en valor. Estos servicios pueden incluir aprendizaje automático, informes, etc.
Estos dominios de arquitectura siguen todos los principios de la malla de datos. Los dominios toman posesión de los datos y pueden distribuir directamente los datos a otros dominios.
Zonas de aterrizaje de datos especiales, genéricos y concentradores
La siguiente opción de implementación es otra iteración del diseño anterior. Esta implementación sigue una topología de malla regulada: los datos se distribuyen a través de un centro de conectividad central, en el que los datos se particionan por dominio, aislados lógicamente y no están integrados. El centro de conectividad de este modelo usa su propia zona de aterrizaje de datos (independiente del dominio) y puede ser propiedad de un equipo central de gobernanza de datos que supervisa qué datos se distribuyen a qué otros dominios. El centro de conectividad también incluye servicios que facilitan la incorporación de datos.

En el caso de los dominios que requieren servicios estándar para consumir, usar, analizar y crear nuevos datos, use la zona de aterrizaje de datos genérica. Una sola suscripción contiene un conjunto estándar de servicios. Aplique también la virtualización de datos, ya que la mayoría de los productos de datos ya se conservan en el centro de conectividad y no necesita más duplicación de datos.
Esta implementación permite «especiales»: zonas de aterrizaje adicionales que se pueden aprovisionar cuando no es posible agrupar dominios lógicamente. Podrían ser necesarios cuando se aplican límites regionales o legales, o cuando sus dominios tienen requisitos únicos y contrastados. También es posible que los necesite en situaciones en las que se aplique una sólida gobernanza subsidiaria global con excepciones para las actividades en el extranjero.
Si su organización necesita controlar qué datos se distribuyen y consumen en qué dominios, la implementación del centro de conectividad es una buena opción. También es una opción si va a solucionar problemas de variante temporal y no volátiles para consumidores de datos de gran tamaño. Puede estandarizar fuertemente el diseño de productos de datos, lo que permite que los dominios viajen en el tiempo y realicen redistribuciones. Este modelo es especialmente común en el sector financiero.
Zonas de aterrizaje de datos alineadas funcional y regionalmente
El aprovisionamiento de varias zonas de aterrizaje de datos puede ayudarle a agrupar dominios funcionales basados en la cohesión y la eficiencia para trabajar y compartir datos. Todas las zonas de aterrizaje de datos se adhieren a la misma auditoría y controles, pero todavía puede tener flexibilidad y diseño de cambios entre diferentes zonas de aterrizaje de datos.

Varios aspectos determinan qué dominios de datos funcionales se deben agrupar lógicamente y crear candidatos para una zona de aterrizaje de datos compartida. Por ejemplo, los límites regionales pueden dar lugar a su implementación de los mismos planos técnicos. La propiedad, la seguridad o los límites legales pueden obligarle a separar dominios. La flexibilidad, el ritmo de cambio y la separación o la venta de sus funcionalidades también son factores importantes.
Encontrará más instrucciones y procedimientos recomendados en dominios de datos.
Las distintas zonas de aterrizaje no son independientes. No pueden conectarse a lagos de datos alojados en otras zonas. Esto permite que los dominios colaboren en toda la empresa. También puede aplicar persistencia políglota para mezclar diferentes tecnologías de almacén de datos. También se puede aplicar la persistencia políglota para mezclar diferentes tecnologías de almacenamiento de datos.
Al implementar varias zonas de aterrizaje de datos, sepa que hay sobrecarga de administración asociada a cada zona de aterrizaje de datos. Debe aplicar el emparejamiento de VNet entre todas las zonas de aterrizaje de datos, debe administrar puntos de conexión privados adicionales, etc.
La implementación de varias zonas de aterrizaje de datos es una buena opción si su arquitectura de datos es grande. Puede agregar más zonas de aterrizaje a la arquitectura para satisfacer las necesidades comunes de varios dominios. Estas zonas de aterrizaje usarán el emparejamiento de red virtual para conectarse a la zona de aterrizaje de administración de datos y a todas las demás zonas de aterrizaje. El emparejamiento permite compartir conjuntos de datos y recursos entre sus zonas de aterrizaje. La división de datos entre zonas independientes le permite distribuir cargas de trabajo entre las suscripciones y los recursos de Azure. Este enfoque ayuda a implementar orgánicamente la malla de datos.
Empresa a gran escala que requiere diferentes zonas de administración de datos
Las grandes empresas que operan a escala global pueden tener requisitos de administración de datos contrastados entre diferentes partes de su organización. Puede implementar varias zonas de administración de datos y de aterrizaje de datos juntas para solucionar este problema. En el diagrama siguiente se muestra un ejemplo de este tipo de arquitectura:

Varias zonas de aterrizaje de administración de datos deben justificar la sobrecarga y la complejidad de la integración. Por ejemplo, otra zona de aterrizaje de administración de datos podría tener sentido en situaciones en las que los (meta)datos de la organización no deben ser vistos por ajeno a la organización.
Conclusión
La transición hacia la malla de datos es un cambio cultural que implica matices, inconvenientes y consideraciones. Aproveche los análisis a escala de nube para disponer de procedimientos recomendados y recursos ejecutables. Las arquitecturas de referencia de este artículo ofrecen puntos de partida para iniciar la implementación.