Control de acceso y configuraciones de lago de datos en Azure Data Lake Storage Gen2
Este artículo ayuda a evaluar y comprender los mecanismos de control de acceso en Azure Data Lake Storage Gen2. Estos mecanismos incluyen el control de acceso basado en roles de Azure (RBAC) y las listas de control de acceso (ACL). Aprenderá a:
- Cómo evaluar el acceso entre Azure RBAC y ACL
- Configuración del control de acceso mediante uno o ambos de estos mecanismos
- Cómo aplicar el mecanismo de control de acceso a los patrones de implementación de lago de datos
Necesita conocimientos básicos de contenedores de almacenamiento, grupos de seguridad, RBAC de Azure y ACL. Para enmarcar la discusión, se hace referencia a una estructura genérica de lago de datos de zonas sin procesar, enriquecidas y conservadas.
Puede usar este documento con la administración de acceso a datos.
Usar los roles RBAC de Azure integrados
Azure Storage tiene dos capas de acceso: administración de servicios y datos. Puede acceder a suscripciones y cuentas de almacenamiento a través del nivel de administración de servicios. Acceda a los contenedores, blobs y otros recursos de datos mediante la capa de datos. Por ejemplo, si desea obtener una lista de las cuentas de almacenamiento de Azure, envíe una solicitud al punto de conexión de administración. Si desea una lista de sistemas de archivos, carpetas o archivos de una cuenta de almacenamiento, envíe una solicitud a un punto de conexión de servicio.
Los roles pueden contener los permisos para acceder a la capa de datos o de administración. El rol Lector concede acceso de solo lectura a los recursos de la capa de administración, pero no acceso de lectura a los datos.
Roles como Propietario, Colaborador, Lector y Colaborador de la cuenta de almacenamiento permiten que una entidad de seguridad administre una cuenta de almacenamiento. Pero no proporcionan acceso a los datos de esa cuenta. Solo los roles definidos explícitamente para el acceso a datos permiten a una entidad de seguridad acceder a los datos. Estos roles, excepto el de Lector, obtienen acceso a las claves de almacenamiento para acceder a los datos.
Roles de administración integrados
Los siguientes son los roles de administración integrados.
- Propietario: administra todo, incluido el acceso a los recursos. Este rol proporciona acceso a la clave.
- Colaborador: puede administrar todo, excepto el acceso a los recursos. Este rol proporciona acceso a la clave.
- Colaborador de la cuenta de almacenamiento: administración completa de cuentas de almacenamiento. Este rol proporciona acceso a la clave.
- Lector: lee y enumera los recursos. Este rol no proporciona acceso a la clave.
Roles de datos integrados
Los siguientes son los roles de datos integrados.
- Propietario de datos de Storage Blob: acceso total a los contenedores y datos de Azure Storage Blob, incluida la configuración de propiedad y la administración del control de acceso POSIX.
- Colaborador de datos de Storage Blob: Lee, escribe y elimina blobs y contenedores de Azure Storage.
- Lector de datos de Storage Blob: Lee y enumera blobs y contenedores de Azure Storage.
El propietario de datos de Storage Blob es un rol de superusuario que se le concede acceso total a todas las operaciones de mutación. Estas operaciones incluyen el establecimiento del propietario de un directorio o archivo y las ACL de directorios y archivos de las que no son propietarios. El acceso de superusuario es la única manera autorizada para cambiar el propietario de un recurso.
Nota:
Las asignaciones de RBAC de Azure pueden tardar hasta cinco minutos en propagarse y tener efecto.
Evaluación del acceso
Durante la autorización basada en la entidad de seguridad, el sistema evalúa los permisos en el siguiente orden. Para más información, consulte el diagrama siguiente.
- RBAC de Azure se evalúa primero y tiene prioridad sobre cualquier otra asignación de ACL.
- Si la operación está totalmente autorizada en función de RBAC, las ACL no se evalúan en absoluto.
- Si la operación no está totalmente autorizada, se evalúan las ACL.
Para obtener más información, vea Evaluación de los permisos.
Nota:
Este modelo de permisos solo se aplica a Azure Data Lake Storage. No se aplica al almacenamiento de uso general o blob sin el espacio de nombres jerárquico habilitado.
Esta descripción excluye los métodos de autenticación de SAS y clave compartida. También excluye los escenarios en los que a la entidad de seguridad tiene asignado el rol integrado Propietario de datos de Storage Blob, que proporciona acceso de superusuario.
Establecer allowSharedKeyAccess en false para que la identidad audite el acceso.

Para más información sobre los permisos basados en ACL necesarios para una operación determinada, consulte Listas de control de acceso en Azure Data Lake Storage Gen2.
Nota:
- Las listas de control de acceso solo se aplican a las entidades de seguridad del mismo inquilino, incluidos los usuarios invitados.
- Cualquier usuario con permisos para conectarse a un clúster puede crear puntos de montaje de Azure Databricks. Configure el punto de montaje mediante credenciales de entidad de servicio o la opción de tránsito de Microsoft Entra. En el momento de la creación, no se evalúan los permisos. Los permisos se evalúan cuando una operación usa el punto de montaje. Cualquier usuario que pueda conectarse a un clúster puede intentar usar el punto de montaje.
- Cuando un usuario crea una definición de tabla en Azure Databricks o Azure Synapse Analytics, necesita tener acceso de lectura a los datos subyacentes.
Configuración del acceso a Azure Data Lake Storage
Configure el control de acceso en Azure Data Lake Storage mediante RBAC de Azure, ACL o una combinación de ambos.
Configuración del acceso solo mediante RBAC de Azure
Si el control de acceso de nivel de contenedor es suficiente, las asignaciones de RBAC de Azure ofrecen un enfoque de administración simple para proteger los datos. Se recomienda usar listas de control de acceso para un gran número de recursos de datos restringidos o cuando necesite un control de acceso pormenorizado.
Configuración del acceso solo mediante ACL
A continuación se muestran las recomendaciones de listas de control de acceso para el análisis a escala de nube.
Asigne entradas de control de acceso a un grupo de seguridad en lugar de a un usuario individual o una entidad de servicio. Para más información, consulte Uso de grupos de seguridad frente a usuarios individuales.
Al agregar o quitar usuarios del grupo, no es necesario realizar actualizaciones en Data Lake Storage. Además, el uso de grupos reduce la posibilidad de superar las 32 entradas de control de acceso por ACL de archivo o carpeta. Después de las cuatro entradas predeterminadas, solo quedan 28 entradas para las asignaciones de permisos.
Incluso si usa grupos, podría tener muchas entradas de control de acceso en los niveles superiores del árbol de directorios. Esta situación ocurre cuando se requieren permisos pormenorizados para distintos grupos.

Configuración del acceso mediante RBAC de Azure y listas de control de acceso
Los permisos de Colaborador de datos de Storage Blob y Lector de datos de Storage Blob proporcionan acceso a los datos y no a la cuenta de almacenamiento. Puede conceder acceso en el nivel de cuenta de almacenamiento o en el nivel de contenedor. Si Colaborador de datos de Storage Blob está asignado, no se pueden usar ACL para administrar el acceso. Cuando Lector de datos de Storage Blob está asignado, se pueden conceder permisos de escritura elevados mediante ACL. Para obtener más información, vea Evaluación del acceso.
Este enfoque favorece escenarios en los que la mayoría de los usuarios necesitan acceso de lectura, pero solo unos pocos usuarios necesitan acceso de escritura. Las zonas de lago de datos podrían ser diferentes cuentas de almacenamiento y los recursos de datos podrían ser contenedores diferentes. Las zonas de lago de datos podrían representarse mediante contenedores y recursos de datos representados por carpetas.
Enfoques de grupo de lista de control de acceso anidado
Hay dos enfoques para los grupos de ACL anidados.
Opción 1: el grupo de ejecución primario
Antes de crear archivos y carpetas, comience con un grupo primario. Asigne los permisos de ejecución de ese grupo a las ACL predeterminadas y de acceso en el nivel de contenedor. A continuación, agregue los grupos que requieren acceso a los datos al grupo primario.
Advertencia
No se recomienda usar este patrón, donde hay eliminaciones recursivas, y, en su lugar, se recomienda usar la Opción 2: la lista de control de acceso de otra entrada.
Esta técnica se conoce como grupos de anidamiento. El grupo miembro hereda los permisos del grupo primario, que proporciona permisos de ejecución global a todos los grupos de miembros. El grupo de miembros no necesita permisos de ejecución porque estos permisos se heredan. Un mayor anidamiento podría proporcionar mayor flexibilidad y agilidad. Agregue grupos de seguridad que representen equipos o trabajos automatizados a los grupos de escritores y lectores de acceso a datos.
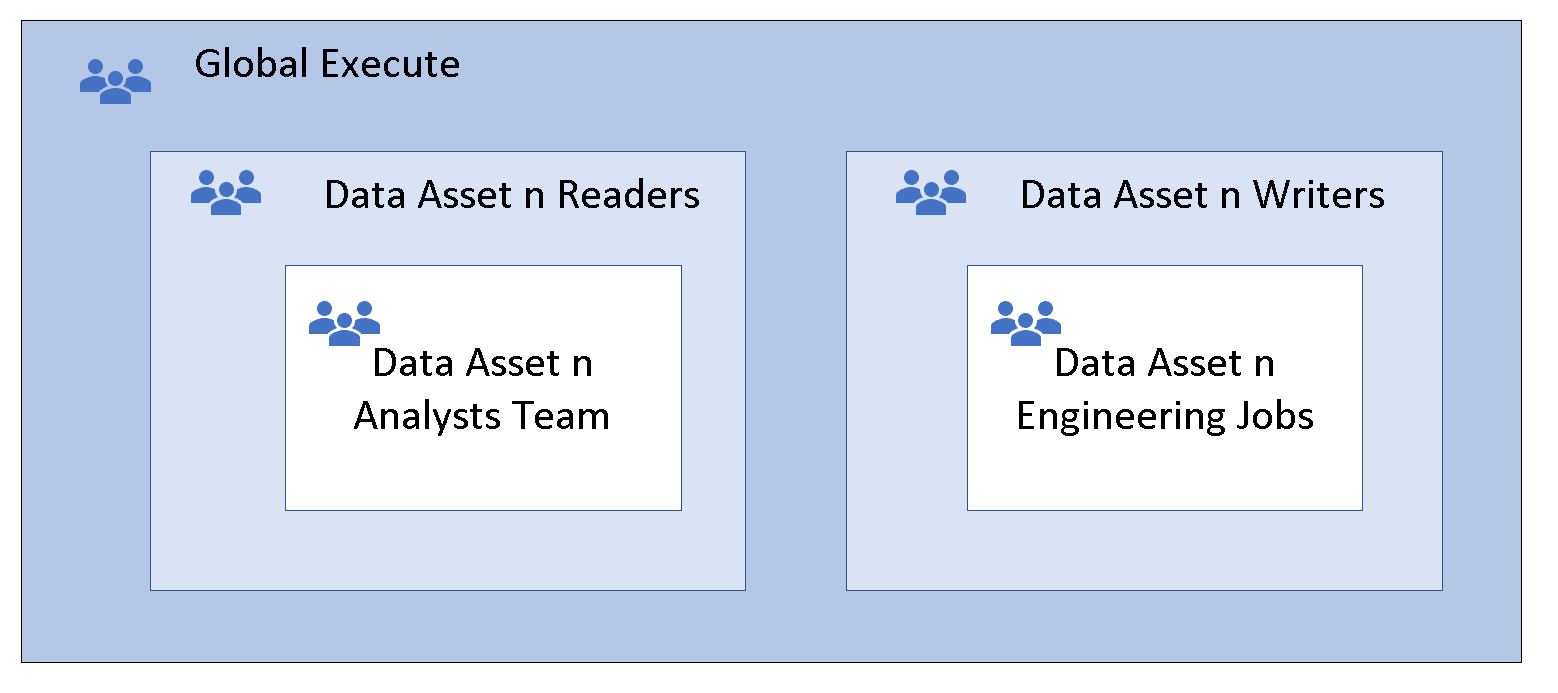
Opción 2: otra entrada de la lista de control de acceso
El enfoque recomendado es usar la otra entrada de ACL establecida en el contenedor o la raíz. Especifique los valores predeterminados y acceda a las ACL como se muestra en la pantalla siguiente. Este enfoque garantiza que todas las partes de la ruta de acceso de la raíz al nivel más bajo tienen permisos de ejecución.
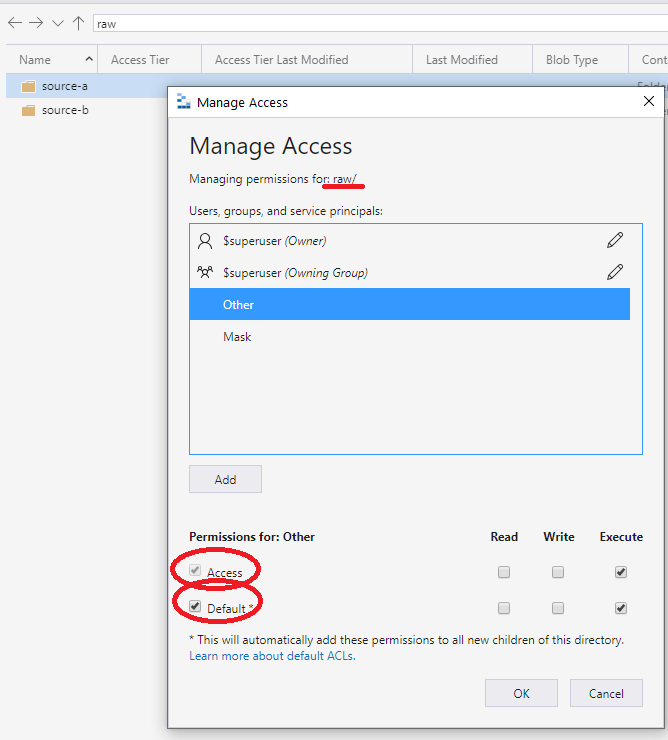
Este permiso de ejecución propaga hacia abajo las carpetas secundarias agregadas. El permiso se propaga a la profundidad donde el grupo de acceso previsto necesita permisos para leer y ejecutar. El nivel está en la parte más baja de la cadena, como se muestra en la siguiente pantalla. Este enfoque concede acceso de grupo para leer los datos. El enfoque funciona de forma similar para el acceso de escritura.
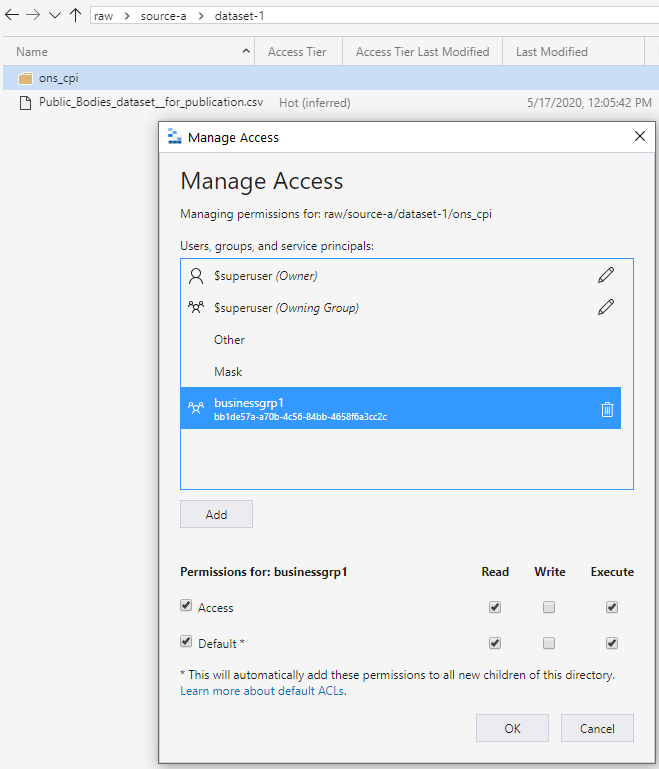
Seguridad recomendada de zonas de lago de datos
Los siguientes usos son los patrones de seguridad recomendados para cada una de las zonas de lago de datos:
- La opción Sin formato solo debe permitir el acceso a los datos mediante nombres de entidad de seguridad (SPN).
- La opción Enriquecido solo debe permitir el acceso a los datos mediante nombres de entidad de seguridad (SPN).
- La opción Mantenido debe permitir el acceso con nombres de entidad de seguridad (SPN) y nombres principales de usuario (UPN).
Escenario de ejemplo para el uso grupos de seguridad de Microsoft Entra
Hay muchas maneras diferentes de configurar grupos. Por ejemplo, imagine que tiene un directorio denominado /LogData que contiene los datos de registro generados por su servidor. Azure Data Factory ingiere los datos en esa carpeta. Los usuarios específicos del equipo de ingeniería de servicios cargan registros y administran otros usuarios de esta carpeta. Los clústeres del área de trabajo de análisis y ciencia de datos de Azure Databricks podrían analizar los registros de esa carpeta.
Para habilitar estas actividades, puede crear un grupo LogsWriter y un grupo LogsReader. Asigne los permisos de clave siguientes:
- Agregue el grupo
LogsWritera la lista de control de acceso del directorio/LogDatacon permisos derwx. - Agregue el grupo
LogsReadera la lista de control de acceso del directorio/LogDatacon permisos der-x. - Agregue el objeto de entidad de servicio o Managed Service Identity (MSI) para Data Factory al grupo
LogsWriters. - Agregue los usuarios del equipo de ingeniería de servicios al grupo
LogsWriter. - Azure Databricks se configura para el tránsito de Microsoft Entra al almacén de Azure Data Lake.
Si un usuario del equipo de ingeniería de servicios se transfiere a otro equipo, quite ese usuario del grupoLogsWriter.
Si no agregó dicho usuario a un grupo, sino que en su lugar agregó una entrada de ACL dedicada para ese usuario, tendrá que quitar esa entrada del directorio /LogData. También tendrá que quitar la entrada de todos los subdirectorios y archivos de toda la jerarquía de directorios del directorio /LogData.
Control de acceso a datos de Azure Synapse Analytics
Para implementar un área de trabajo de Azure Synapse, se requiere una cuenta de Azure Data Lake Storage Gen2. Azure Synapse Analytics usa la cuenta de almacenamiento principal para varios escenarios de integración y almacena datos en un contenedor. El contenedor incluye tablas y registros de aplicaciones de Apache Spark en una carpeta denominada /synapse/{workspaceName} . El área de trabajo también usa un contenedor para administrar las bibliotecas que instala.
Durante la implementación del área de trabajo a través de Azure Portal, proporcione una cuenta de almacenamiento existente o cree una nueva. La cuenta de almacenamiento proporcionada es la cuenta de almacenamiento principal del área de trabajo. El proceso de implementación concede a la identidad del área de trabajo acceso a la cuenta de Data Lake Storage Gen2 especificada mediante el rol Colaborador de datos de Storage Blob.
Si implementa el área de trabajo fuera de Azure Portal, agregue manualmente el área de trabajo de Azure Synapse Analytics al rol Colaborador datos de Storage Blob. Se recomienda asignar el rol Colaborador de datos de Storage Blob en el nivel de contenedor para seguir el principio de privilegios mínimos.
Al ejecutar canalizaciones, flujos de trabajo y cuadernos a través de trabajos, se usa el contexto de permiso de identidad del área de trabajo. Si alguno de los trabajos lee o escribe en el almacenamiento principal del área de trabajo, la identidad del área de trabajo usa los permisos de lectura y escritura concedidos a través del rol Colaborador de datos de Storage Blob.
Cuando los usuarios inician sesión en el área de trabajo para ejecutar scripts o para el desarrollo, los permisos de contexto del usuario permiten el acceso de lectura y escritura en el almacenamiento principal.
Control de acceso a datos específico de Azure Synapse Analytics mediante listas de control de acceso
Al configurar el control de acceso de lago de datos, algunas organizaciones requieren acceso de nivel pormenorizado. Pueden tener datos confidenciales que algunos grupos de la organización no pueden ver. RBAC de Azure permite solo lectura o escritura en el nivel de contenedor y cuenta de almacenamiento. Con las ACL, puede configurar un control de acceso específico en el nivel de carpeta y archivo para permitir la lectura y escritura en un subconjunto de datos para grupos específicos.
Consideraciones al usar tablas de Spark
Cuando se usan tablas de Apache Spark en el grupo de Spark, crea una carpeta de almacenamiento. LA carpeta se encuentra en la raíz del contenedor en el almacenamiento principal del área de trabajo:
synapse/workspaces/{workspaceName}/warehouse
Si tiene previsto crear tablas de Apache Spark en un grupo de Spark de Azure Synapse, conceda permiso de escritura en la carpeta de almacenamiento para el grupo que ejecuta el comando que crea la tabla de Spark. Si el comando se ejecuta a través de un trabajo desencadenado en una canalización, conceda permiso de escritura al MSI del área de trabajo.
En este ejemplo se crea una tabla de Spark:
df.write.saveAsTable("table01")
Para más información, consulte Procedimiento para configurar el control de acceso para el área de trabajo de Synapse.
Resumen del acceso a Azure Data Lake
Ningún enfoque único para administrar el acceso al lago de datos se adapta a todos los usuarios. Una ventaja importante de un lago de datos es proporcionar acceso sin fricción a los datos. En la práctica, las distintas organizaciones desean diferentes niveles de gobernanza y control sobre sus datos. Algunas organizaciones tienen un equipo centralizado para administrar el acceso y aprovisionar grupos bajo estrictos controles internos. Otras organizaciones son más ágiles y tienen control descentralizado. Elija el enfoque que cumpla su nivel de gobernanza. Su elección no debería producir retrasos o fricción innecesarios para obtener acceso a los datos.