Uso de Azure Databricks en el análisis a escala de la nube en Azure
Azure Databricks es una plataforma de análisis de datos optimizada para la plataforma Microsoft Azure Cloud Services. Azure Databricks ofrece dos entornos para desarrollar aplicaciones con un uso intensivo de datos:
SQL de Azure Databricks permite ejecutar consultas SQL ad hoc rápidas en el lago de datos.
Ingeniería y ciencia de datos de Azure Databricks (a veces llamada simplemente "área de trabajo") es una plataforma de análisis basada en Apache Spark. Está integrada con Azure para proporcionar una configuración con un solo clic, flujos de trabajo optimizados y un área de trabajo interactiva que permite la colaboración entre ingenieros de datos, científicos de datos e ingenieros de aprendizaje automático.
En el caso del análisis a escala de la nube, nos centraremos en la ingeniería y ciencia de datos de Azure Databricks.
Información general
Para cada zona de aterrizaje de datos que implemente, tiene la opción de implementar dos áreas de trabajo compartidas. Una para la ingesta independiente de datos y otra para el análisis.
- El área de trabajo de ingeniería de Azure Databricks para la ingesta y el procesamiento se conectaría a Azure Data Lake mediante las entidades de servicio de Azure. Es llamada por la ingesta independiente de datos.
- El área de trabajo de análisis de Azure Databricks se podría aprovisionar para todos los científicos de datos y los equipos de operaciones de datos. Esta área de trabajo se conectaría a Azure Data Lake mediante la autenticación transferida de Microsoft Entra. Comparta el área de trabajo de análisis y ciencia de datos de Azure Databricks análisis y ciencia de datos en la zona de aterrizaje de datos con todos los usuarios que tengan acceso al área de trabajo.
Si tiene un motor de ingesta de datos independiente automatizado, el área de trabajo de ingeniería de Azure Databricks usa la instancia de Azure Key Vault creada en el grupo de recursos de servicios de metadatos de Azure para ejecutar canalizaciones de ingesta de datos, de datos sin procesar a datos enriquecidos.
El área de trabajo de análisis de Azure Databricks debe tener directivas de clúster que le exijan crear clústeres de alta simultaneidad. Este tipo de clúster permite explorar el lago de datos mediante el tránsito de credenciales de Microsoft Entra. Para obtener más información, consulte Control de acceso y configuraciones de lago de datos en Azure Data Lake Storage.
Configuración de Azure Databricks
La implementación de Azure Databricks se basa parcialmente en parámetros a través de una plantilla de Azure Resource Manager y de scripts YAML, pero también se requiere alguna intervención manual para configurar todas las áreas de trabajo.
Todas las áreas de trabajo de Azure Databricks deben usar el plan prémium, que proporciona las siguientes características necesarias:
- Escalado automático optimizado del proceso
- Autenticación de tránsito de credenciales de Microsoft Entra
- Autenticación condicional
- Control de acceso basado en roles para cuadernos, clústeres, trabajos y tablas
- Registros de auditoría
Para alinearse con el análisis a escala de la nube, se recomienda que todas las áreas de trabajo tengan configuradas las siguientes opciones de implementación predeterminadas:
- Las áreas de trabajo de Azure Databricks se conectan a una instancia de metastore de Apache Hive externa en la zona de aterrizaje de datos.
- Configure cada área de trabajo para enviar el registro de diagnóstico de Databricks a Azure Log Analytics en databricks-monitoring-rg.
- Implemente directivas de clúster para limitar la capacidad de crear clústeres basados en un conjunto de reglas. Para más información, consulte Administración de directivas de clúster.
- Defina varias directivas de clúster. Como parte del proceso de incorporación, asigne cada permiso del grupo de destino para que lo use el equipo de operaciones de la zona de aterrizaje de datos. De forma predeterminada, el permiso de creación del clúster solo se concede al equipo de operaciones. A los distintos equipos o grupos se les concede permiso para usar directivas de clúster.
- Use directivas de clúster junto con grupos de Azure Databricks para reducir los tiempos de inicio y escalado automático del clúster mediante el mantenimiento de un conjunto de instancias inactivas y listas para usar. Para obtener más información, vea Grupos.
- Recupere todos los secretos operativos de Azure Databricks, como las credenciales de SPN y las cadenas de conexión, de una instancia de Azure Key Vault.
- Configure una aplicación empresarial independiente por área de trabajo para su uso con SCIM (sistema para la administración de identidades entre dominios). Vínculo al área de trabajo de Azure Databricks para controlar el acceso y los permisos a cada área de trabajo. Para obtener más información, vea Aprovisionamiento de usuarios y grupos mediante SCIM y Configuración del aprovisionamiento de SCIM para Microsoft Entra ID.
Advertencia
Si no se configura el área de trabajo de Azure Databricks para usar la interfaz de SCIM de Azure Databricks, la forma de proporcionar controles de seguridad se verá afectada. Pasa de un proceso automatizado a un proceso manual y interrumpe todas las canalizaciones de CI/CD de la implementación.
Las siguientes opciones de control de acceso se establecen para todas las áreas de trabajo de Databricks:
- Control de visibilidad del área de trabajo: habilitado (valor predeterminado: deshabilitado)
- Control de visibilidad del clúster: habilitado (valor predeterminado: deshabilitado)
- Control de visibilidad del trabajo: habilitado (valor predeterminado: deshabilitado)
Es posible que desee habilitar las siguientes opciones para el área de trabajo de análisis de Azure Databricks:
- Exportación de cuadernos: deshabilitado (valor predeterminado: habilitado)
- Características del Portapapeles de tablas de cuadernos: deshabilitado (valor predeterminado: habilitado)
- Control de acceso a tablas: habilitado (valor predeterminado: deshabilitado)
- Acceso condicional de Microsoft Entra
Implementación de Azure Databricks
Si implementa las áreas de trabajo de Azure Databricks como parte de una nueva implementación de la zona de aterrizaje de datos. En la imagen siguiente se muestra un ejemplo de flujo de trabajo de implementación de un entorno de Azure Databricks en análisis a escala de la nube.
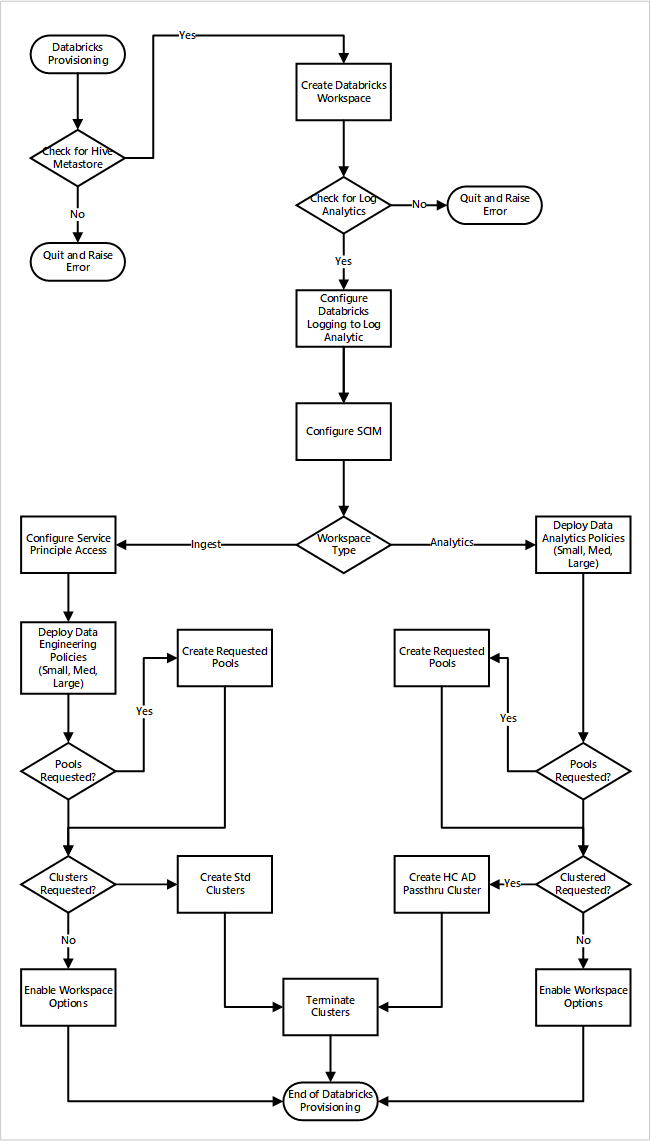
- El proceso de aprovisionamiento primero se asegura de que existe una instancia de metastore de Apache Hive en la zona de aterrizaje de datos. Si no encuentra la instancia de metastore de Apache Hive, se cierra y genera un error.
- Tras encontrar correctamente la instancia de metastore de Apache Hive, se crea un área de trabajo.
- El proceso comprueba si hay un área de trabajo de Log Analytics en la zona de aterrizaje de datos. Si no encuentra el área de trabajo de Log Analytics, se cierra y genera un error.
- Para cada área de trabajo, crea una aplicación de Microsoft Entra y configura SCIM.
Para el área de trabajo de ingesta de Azure Databricks:
- El proceso configura el área de trabajo con el acceso a la entidad de servicio.
- Se implementan directivas de ingeniería de datos definidas por el equipo de operaciones de la plataforma de datos.
- Si el equipo de operaciones de la zona de aterrizaje de datos ha solicitado grupos o clústeres de Databricks, se pueden integrar en el proceso de implementación.
- Habilita las opciones del área de trabajo específicas del área de trabajo de ingeniería de Azure Databricks.
Para el área de trabajo de análisis de Azure Databricks:
- El proceso implementa directivas de análisis de datos definidas por el equipo de operaciones de la plataforma de datos.
- Si el equipo de operaciones de la zona de aterrizaje de datos ha solicitado grupos o clústeres de Databricks, se pueden integrar en el proceso de implementación.
- Habilita las opciones del área de trabajo específicas del área de trabajo de ingeniería de Azure Databricks.
Metastore de Hive externo
En una implementación de área de trabajo de Azure Databricks:
- Un nuevo script de inicialización global configura metastore de Apache Hive para todos los clústeres. Este script se administra mediante la nueva API de scripts de inicialización globales.
La nueva API de scripts de inicialización globales está en versión preliminar pública. Las características de versión preliminar pública de Azure Databricks están listas para entornos de producción y el equipo de soporte técnico las admite. Para obtener más información, consulte Versiones preliminares de Azure Databricks.
- Esta solución usa Azure Database for MySQL para almacenar la instancia de metastore de Apache Hive. Esta base de datos se eligió por su rentabilidad y su alta compatibilidad con Apache Hive.
Pasos siguientes
El análisis a escala de la nube tiene en cuenta las directrices siguientes para la integración de Azure Databricks: