Entrenamiento de su modelo de voz profesional
En este artículo aprenderá a entrenar una instancia de voz neuronal personalizada mediante el portal de Speech Studio.
Importante
El entrenamiento de voz neuronal personalizada actualmente solo está disponible en algunas regiones. Una vez entrenado el modelo de voz en una región compatible, puede copiarlo en un recurso de Voz que se encuentre en otra región, según sea necesario. Para más información, consulte las notas al pie de página de la tabla del servicio Voz.
La duración del entrenamiento varía en función de la cantidad de datos que use. En entrenar una voz neuronal personalizada se tarda una media de 40 horas de proceso. Los usuarios que tengan una suscripción estándar (S0) pueden entrenar cuatro voces simultáneamente. Si alcanza el límite, espere hasta que al menos uno de los modelos de voz finalice el aprendizaje e inténtelo de nuevo.
Nota:
Aunque el número total de horas necesarias por método de entrenamiento varía, se aplica el mismo precio unitario a cada uno. Para obtener más información, vea los detalles de precios de entrenamiento neuronal personalizado.
Elección de un método de entrenamiento
Después de validar los archivos de datos, puede usarlos para crear su modelo de voz neuronal personalizada. Al crear una voz neuronal personalizada, puede elegir entrenarla con uno de los métodos siguientes:
Neuronal: cree una voz en el mismo idioma de sus datos de entrenamiento.
Neuronal: multilingüe: cree una voz que hable un idioma diferente al de sus datos de entrenamiento. Comience con 300 expresiones. Por ejemplo, con los datos de entrenamiento
zh-CN, puede crear una voz que hableen-US.El idioma de los datos de entrenamiento y el de destino deben ser uno de los idiomas compatibles con el entrenamiento de voz multilingüe. No es necesario preparar datos de entrenamiento en el idioma de destino, pero el script de prueba sí que debe estar escrito en el idioma de destino.
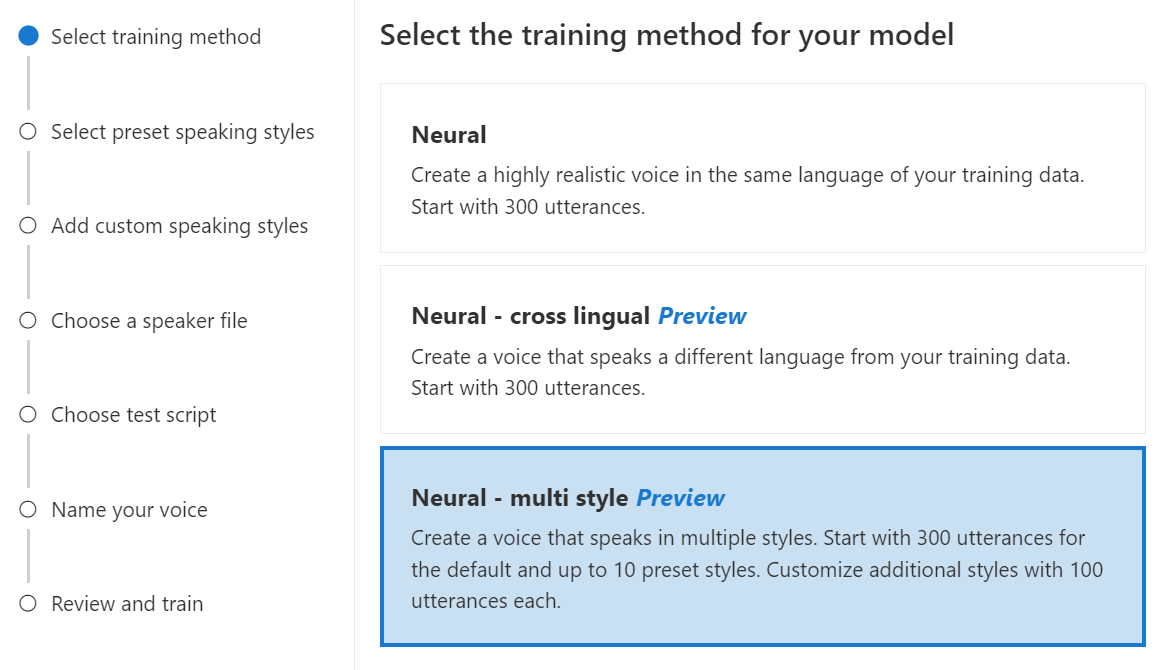
Neuronal: varios estilos: cree una voz neuronal personalizada cuya habla incorpore varios estilos y emociones, sin agregar nuevos datos de entrenamiento. Las voces de varios estilos son útiles para personajes de videojuegos, bots de chat de conversación, audiolibros, lectores de contenido y mucho más.
Para crear una voz de varios estilos, debe preparar un conjunto de datos de entrenamiento generales, al menos 300 expresiones. Seleccione uno o varios de los estilos de habla de destino preestablecidos. También puede crear múltiples estilos personalizados proporcionando ejemplos de estilo, de al menos 100 expresiones por estilo, como datos de entrenamiento adicionales para la misma voz. Los estilos preestablecidos admitidos varían según los distintos idiomas. Consulte Estilos preestablecidos disponibles en diferentes idiomas.
El idioma de los datos de entrenamiento debe ser uno de los idiomas compatibles con el entrenamiento de voz neuronal personalizada, multilingüe o de varios estilos.
Entrenamiento del modelo de voz neuronal personalizada
Para crear una voz neuronal personalizada en Speech Studio, siga estos pasos para uno de los métodos siguientes:
Inicie sesión en Speech Studio.
Seleccione voz personalizada><Nombre de su proyecto>>Entrenar modelo>Entrenar un nuevo modelo.
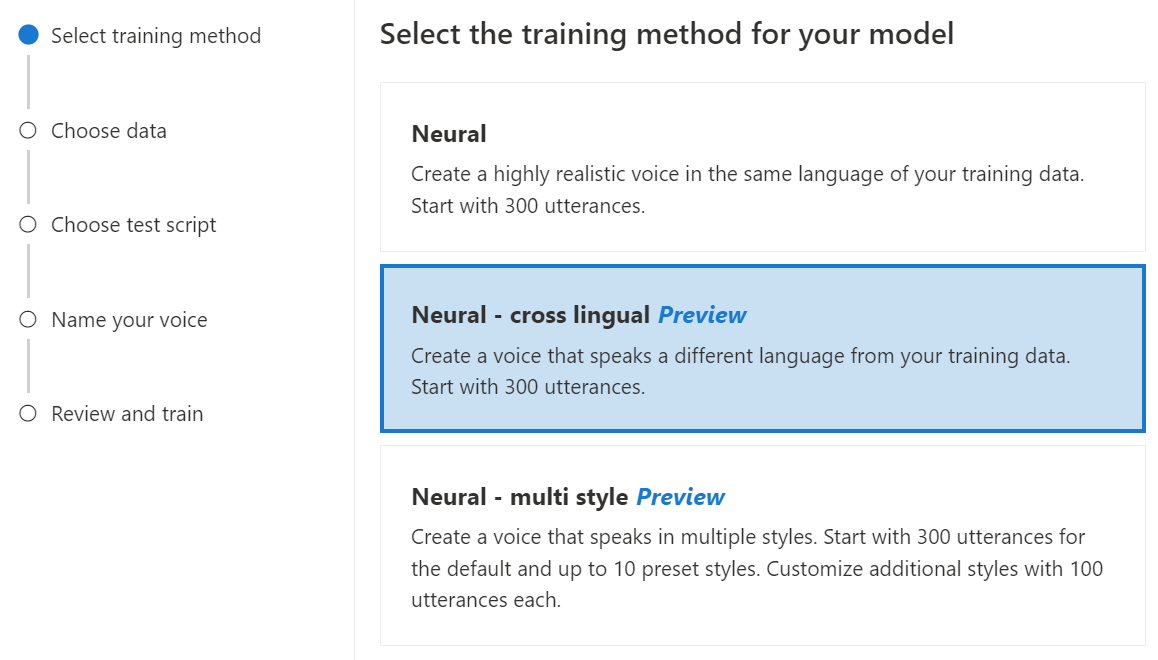
Seleccione Neuronal como método de entrenamiento para el modelo y, después, seleccione Siguiente. Para usar un método de entrenamiento diferente, vea Neuronal: multilingüe o Neuronal: varios estilos.
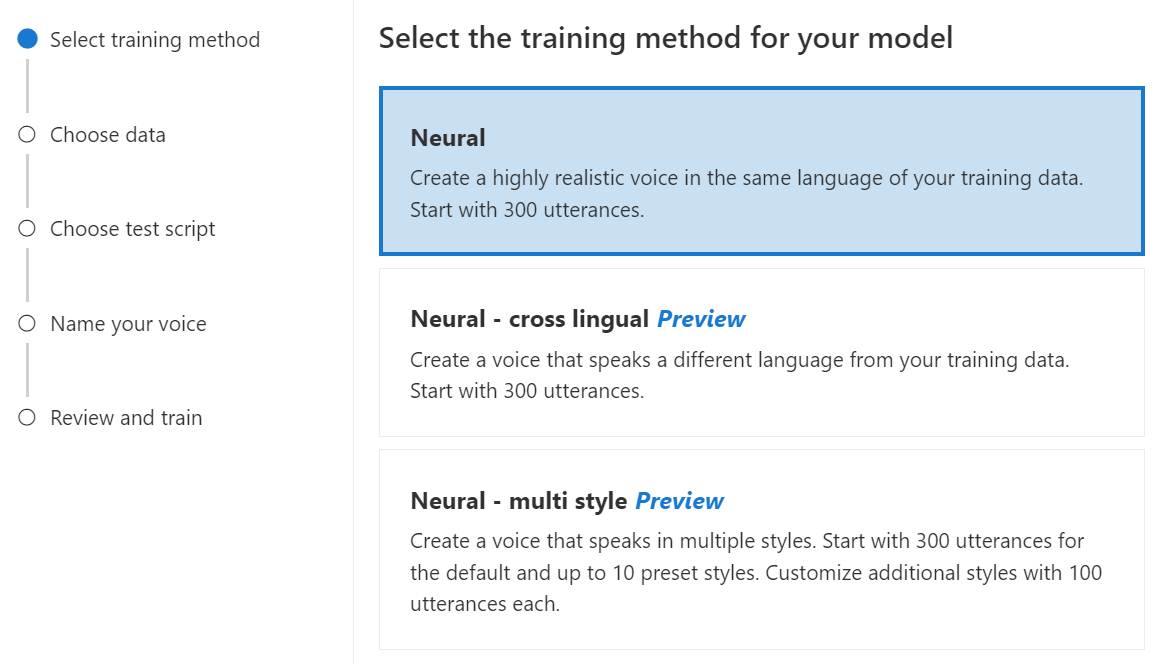
Seleccione una versión de la receta de entrenamiento para el modelo. La versión más reciente se seleccionará de forma predeterminada. Las características admitidas y el tiempo de entrenamiento pueden variar según la versión. Normalmente, se recomienda la versión más reciente. En algunos casos, puede elegir una versión anterior para reducir el tiempo de entrenamiento. Consulte Formación bilingüe para obtener más información sobre la formación bilingüe y las diferencias entre configuraciones regionales.
Seleccione los datos que quiere usar para el entrenamiento. Los nombres de audio duplicados se quitan del entrenamiento. Asegúrese de que los datos que seleccione no contengan los mismos nombres de audio en varios archivos .zip.
Solo puede seleccionar conjuntos de datos procesados correctamente para el entrenamiento. Si no ve el conjunto de entrenamiento en la lista, compruebe el estado de procesamiento de datos.
Seleccione un archivo de hablante con la declaración de actor de voz que corresponda al hablante en los datos de entrenamiento.
Seleccione Next (Siguiente).
Cada entrenamiento genera 100 archivos de audio de muestra automáticamente para ayudarle a probar el modelo con un script predeterminado.
De forma opcional, también puede seleccionar Agregar mi propio script de prueba y proporcionar su propio script de prueba con hasta 100 expresiones para probar el modelo sin costo adicional. Los archivos de audio generados son una combinación de los scripts de prueba automáticos y los personalizados. Para obtener más información, vea los requisitos del script de prueba.
Escriba un Nombre que le permitan identificar el modelo. Elija un nombre con cuidado. El nombre del modelo se usa como nombre de voz en la solicitud de síntesis de voz mediante el SDK y la entrada SSML. Solo se permiten letras, números y algunos signos de puntuación. Use nombres diferentes para los modelos de voz neuronal diferentes.
Opcionalmente, escriba la Descripción para ayudarle a identificar el modelo. Un uso habitual de la descripción es registrar los nombres de los datos que se usaron para crear el modelo.
Seleccione Siguiente.
Revise la configuración y seleccione la casilla para aceptar las condiciones de uso.
Seleccione Enviar para empezar a entrenar el modelo.
Formación bilingüe
Si selecciona el tipo de formación neuronal, puede entrenar una voz para hablar en varios idiomas. Tanto zh-CN como zh-TW regionales admiten la formación bilingüe para que la voz hable tanto en chino como en inglés. En función de los datos de entrenamiento, la voz sintetizada puede hablar inglés con un acento nativo inglés o inglés con el mismo acento que los datos de formación.
Nota:
Para habilitar una voz en la configuración regional zh-CN para hablar inglés con el mismo acento que los datos de ejemplo, debe elegir Chinese (Mandarin, Simplified), English bilingual al crear un proyecto o especificar la configuración regional zh-CN (English bilingual) para los datos del conjunto de entrenamiento a través de la API de REST.
En la siguiente tabla se muestran las diferencias entre las dos configuraciones regionales:
| Configuración regional de Speech Studio | Configuración regional de la API de REST | Soporte bilingüe |
|---|---|---|
Chinese (Mandarin, Simplified) |
zh-CN |
Si los datos de ejemplo incluyen el inglés, la voz sintetizada habla inglés con un acento nativo en inglés, en lugar del mismo acento que los datos de muestra, independientemente de la cantidad de datos en inglés. |
Chinese (Mandarin, Simplified), English bilingual |
zh-CN (English bilingual) |
Si desea que la voz sintetizada hable inglés con el mismo acento que los datos de ejemplo, se recomienda incluir más del 10 % de los datos en inglés en el conjunto de entrenamiento. De lo contrario, es posible que el acento de habla inglesa no sea ideal. |
Chinese (Taiwanese Mandarin, Traditional) |
zh-TW |
Si desea entrenar una voz sintetizada capaz de hablar inglés con el mismo acento que los datos de ejemplo, asegúrese de proporcionar más del 10 % de datos en inglés en el conjunto de entrenamiento. De lo contrario, el valor predeterminado es un acento nativo inglés. El umbral del 10 % se calcula en función de los datos aceptados después de la carga correcta, no los datos antes de cargarlos. Si algunos datos cargados en inglés se rechazan debido a defectos y no cumplen el umbral del 10 %, la voz sintetizada tiene como valor predeterminado un acento nativo inglés. |
Estilos preestablecidos disponibles en distintos idiomas
En la tabla siguiente se resumen los distintos estilos preestablecidos según los distintos idiomas.
| Estilo del habla | Idioma (local) |
|---|---|
| Enfadado | Inglés (Estados Unidos) (en-US)Japonés (Japón) ( ja-JP) 1Chino (mandarín, simplificado) ( zh-CN) 1 |
| Tranquilo | Chino (mandarín, simplificado) (zh-CN) 1 |
| chat | Chino (mandarín, simplificado) (zh-CN) 1 |
| Alegre | Inglés (Estados Unidos) (en-US)Japonés (Japón) ( ja-JP) 1Chino (mandarín, simplificado) ( zh-CN) 1 |
| Contrariado | Chino (mandarín, simplificado) (zh-CN) 1 |
| Emocionado | Inglés (Estados Unidos) (en-US) |
| Temeroso | Chino (mandarín, simplificado) (zh-CN) 1 |
| Amigable | Inglés (Estados Unidos) (en-US) |
| Esperanzado | Inglés (Estados Unidos) (en-US) |
| Triste | Inglés (Estados Unidos) (en-US)Japonés (Japón) ( ja-JP) 1Chino (mandarín, simplificado) ( zh-CN) 1 |
| Gritando | Inglés (Estados Unidos) (en-US) |
| Serio | Chino (mandarín, simplificado) (zh-CN) 1 |
| Aterrorizado | Inglés (Estados Unidos) (en-US) |
| antipático | Inglés (Estados Unidos) (en-US) |
| Susurrando | Inglés (Estados Unidos) (en-US) |
1 El estilo de voz neuronal está disponible en versión preliminar pública. Los estilos en versión preliminar pública solo están disponibles en estas regiones de servicio: Este de EE. UU., Oeste de Europa y Sudeste de Asia.
En la tabla Entrenar modelo se muestra una nueva entrada que corresponde a este modelo recién creado. El estado refleja el proceso de conversión de los datos en un modelo de voz, tal como se describe en esta tabla:
| State | Significado |
|---|---|
| Processing | Se está creando el modelo de voz. |
| Correcto | El modelo de voz se ha creado y se puede implementar. |
| Con error | Se ha producido un error del modelo de voz en el entrenamiento. Las causas del error podrían ser, por ejemplo, problemas de datos no detectados o problemas de red. |
| Canceled | Se canceló el entrenamiento del modelo de voz. |
Mientras el estado del modelo sea Procesando, puede seleccionar Cancelar entrenamiento si quiere cancelar el modelo de voz. No se le cobrará por este entrenamiento cancelado.
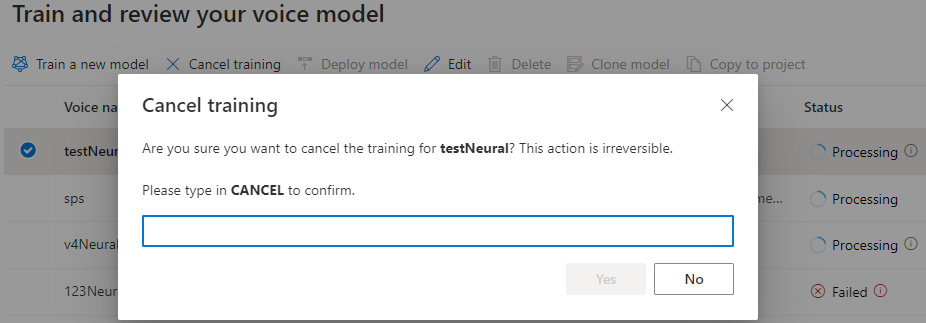
Cuando termine de entrenar el modelo con éxito, podrá revisar los detalles del modelo y Probar su modelo de voz.
Puede usar la herramienta Creación de contenido de audio en Speech Studio para crear audio y ajustar la voz implementada. Si es aplicable a la voz, puede seleccionar uno de varios estilos.
Cambio de nombre del modelo
Si quiere cambiar el nombre del modelo que ha creado, seleccione Clonar modelo para crear un clon del modelo con un nombre nuevo en el proyecto actual.
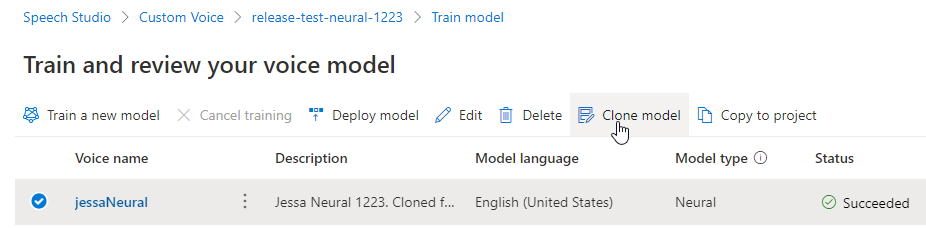
Escriba el nombre nuevo en la ventana Clonar modelo de voz y luego seleccione Enviar. El texto Neuronal se agregará automáticamente como sufijo al nombre del modelo nuevo.
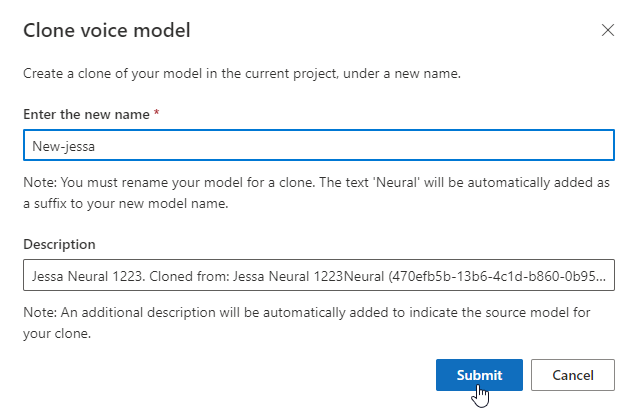
Prueba del modelo de voz
Una vez que el modelo de voz se haya creado correctamente, puede usar los archivos de audio de muestra generados para probarlo antes de implementarlo.
La calidad de la voz depende de muchos factores, como:
- El tamaño del conjunto de entrenamiento.
- La calidad de la grabación.
- La precisión del archivo de transcripción.
- La correspondencia de la voz grabada en los datos de entrenamiento con la personalidad de la voz diseñada para el caso de uso previsto.
Seleccione DefaultTests en Pruebas para escuchar los archivos de audio de ejemplo. Los ejemplos de prueba predeterminados incluyen 100 archivos de audio de ejemplo generados automáticamente durante el entrenamiento para ayudarle a probar el modelo. Además de estos 100 archivos de audio proporcionados de manera predeterminada, sus propias expresiones de script de prueba también se agregan a la configuración de DefaultTests. Esta adición es como máximo 100 expresiones. No se le cobrará por las pruebas con DefaultTests.
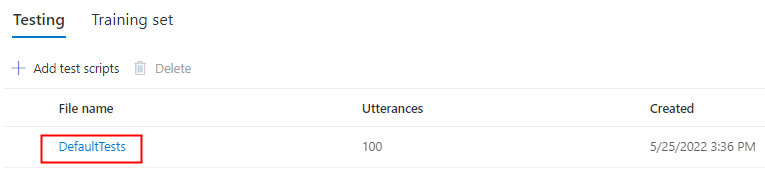
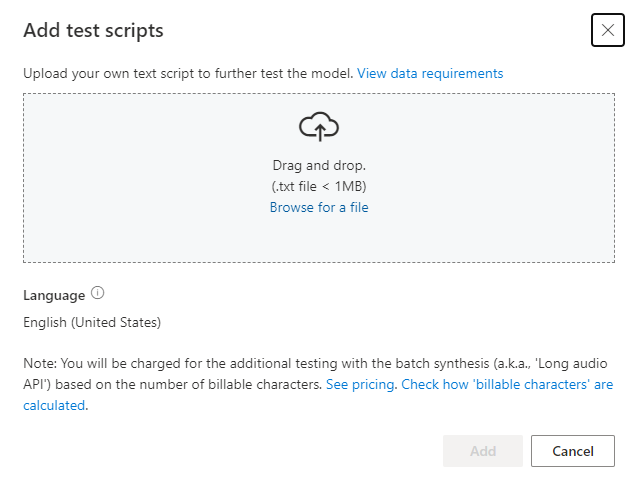
Si quiere cargar su propio script de prueba para probar mejor el modelo, seleccione Agregar scripts de prueba para cargarlo.
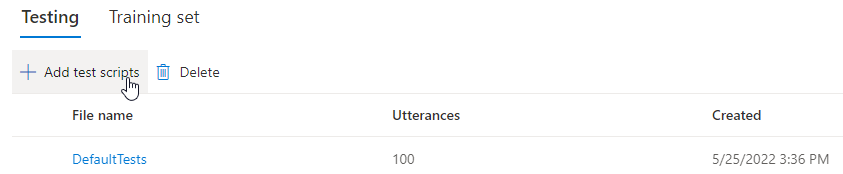
Antes de cargar el script de prueba, compruebe los requisitos del script de prueba. Se le cobrará por las pruebas adicionales con la síntesis por lotes en función del número de caracteres facturables. Consulte Precios de Voz de Azure AI.
En Agregar scripts de prueba, seleccione Buscar un archivo para seleccionar su propio script y luego Agregar para cargarlo.
Requisitos del script de prueba
El script de prueba debe ser un archivo .txt de menos de 1 MB. Entre los formatos de codificación compatibles se incluyen ANSI/ASCII, UTF-8, UTF-8-BOM, UTF-16-LE o UTF-16-BE.
A diferencia de los archivos de transcripción de entrenamiento, el script de prueba debería excluir el id. de la expresión, que es el nombre de archivo de cada expresión. De lo contrario, estos identificadores se pronunciarán.
Este es un conjunto de expresiones de ejemplo en un archivo .txt:
This is the waistline, and it's falling.
We have trouble scoring.
It was Janet Maslin.
Cada párrafo de la expresión genera un audio independiente. Si desea combinar todas las frases en un solo audio, únalas todas en un párrafo.
Nota:
Los archivos de audio generados son una combinación de los scripts de prueba automáticos y los personalizados.
Actualización de la versión del motor del modelo de voz
Los motores de texto a voz de Azure se actualizan de vez en cuando para capturar el modelo de lenguaje más reciente que define la pronunciación del lenguaje. Después de entrenar la voz, puede aplicarla al nuevo modelo de lenguaje mediante una actualización a la versión más reciente del motor.
Cuando haya un nuevo motor disponible, se le pedirá que actualice el modelo de voz neuronal.

Vaya a la página de detalles del modelo y siga las instrucciones en pantalla para instalar el motor más reciente.
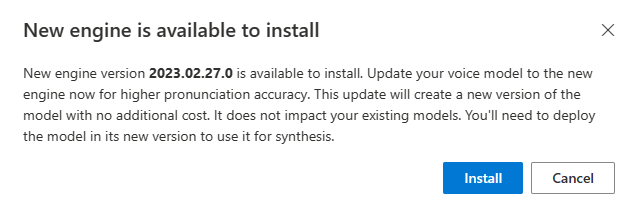
Como alternativa, seleccione Instalar el motor más reciente más adelante para actualizar el modelo a la versión más reciente del motor.
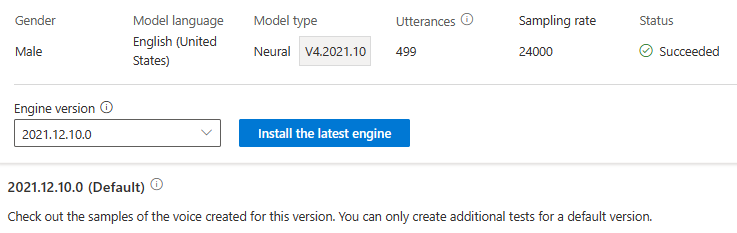
No se le cobrará por actualizar el motor. También se mantendrán las versiones anteriores.
Puede comprobar todas las versiones del motor del modelo en la lista Versión del motor o quitar una si ya no la necesita.
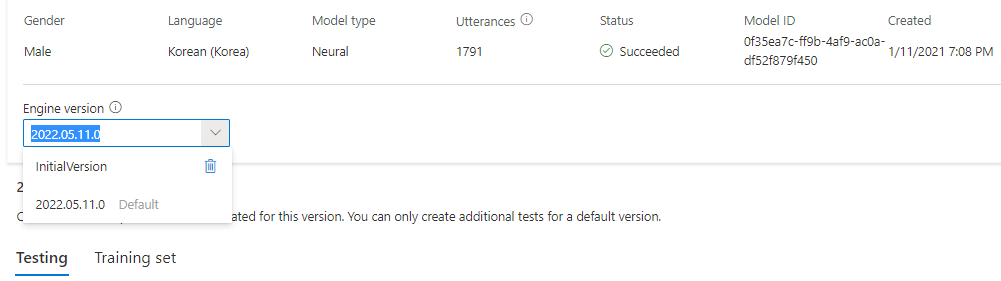
La versión actualizada se establecerá automáticamente como predeterminada. No obstante, puede cambiar la versión predeterminada seleccionando una versión en la lista desplegable y luego Establecer como predeterminada.
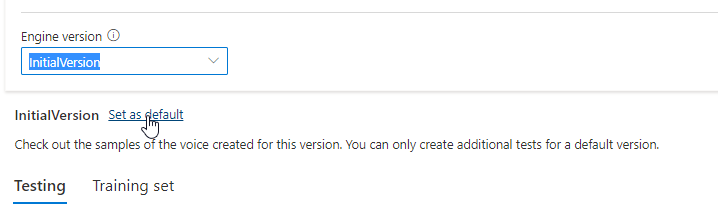

Si quiere probar cada versión del motor de su modelo de voz, puede seleccionar una versión de la lista, después seleccione DefaultTests en Pruebas para escuchar los archivos de audio de muestra. Si quiere cargar sus propios scripts de prueba para seguir probando la versión actual de su motor, asegúrese primero de que la versión está establecida de forma predeterminada y después siga los pasos que se indican en Pruebe su modelo de voz.
Al actualizar el motor, se crea una nueva versión del modelo sin coste adicional. Después de actualizar la versión del motor para el modelo de voz, debe implementar la nueva versión para crear un nuevo punto de conexión. Solo es posible implementar la versión predeterminada.
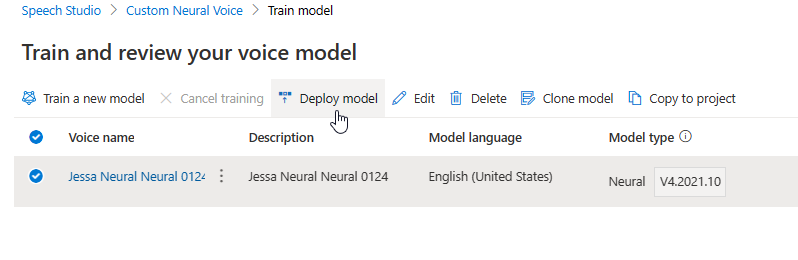
Después de crear un nuevo punto de conexión, debe transferir el tráfico al nuevo punto de conexión del producto.
Para más información sobre las funcionalidades y los límites de esta característica, y el procedimiento recomendado para mejorar la calidad del modelo, consulte Características y limitaciones para usar voz neuronal personalizada.
Copia del modelo de voz en otro proyecto
Puede copiar el modelo de voz en otro proyecto de la misma región u otra región. Por ejemplo, un modelo de voz neuronal que se entrenó en una región puede copiarse en un proyecto de otra región.
Nota
El entrenamiento de voz neuronal personalizada actualmente solo está disponible en algunas regiones. Puede copiar un modelo de voz neuronal de esas regiones a otras regiones. Para obtener más información, consulte las regiones para la voz neuronal personalizada.
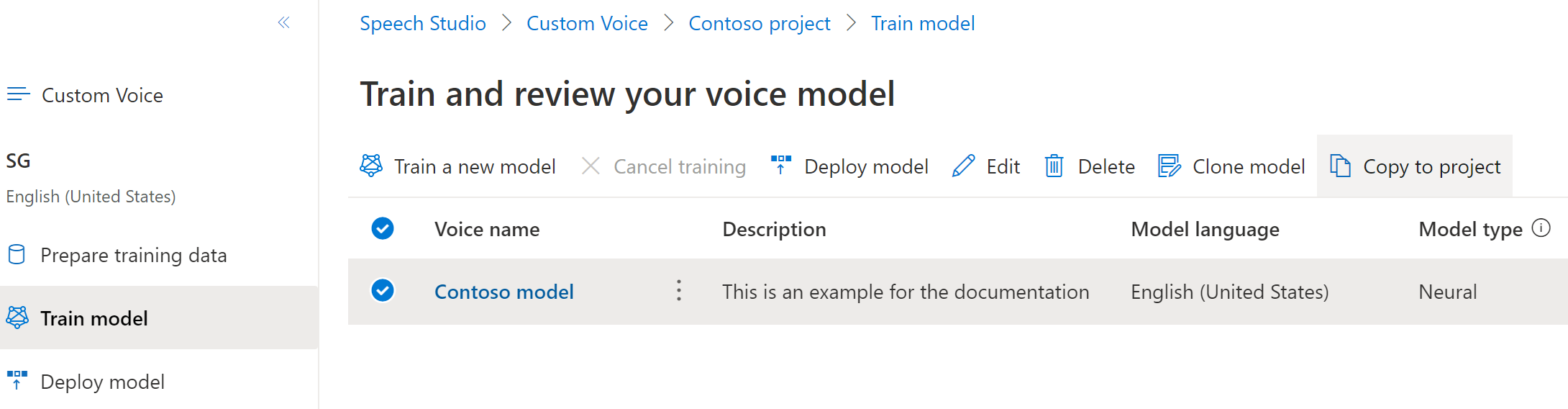
Para copiar el modelo de voz neuronal personalizada en otro proyecto:
En la pestaña Entrenar modelo, seleccione un modelo de voz que quiera copiar y, a continuación, seleccione Copiar a proyecto.
Seleccione la Región, el Recurso de voz y el Proyecto donde quiere copiar el modelo. Debe tener un recurso de voz y un proyecto en la región de destino; de lo contrario, debe crearlos antes.
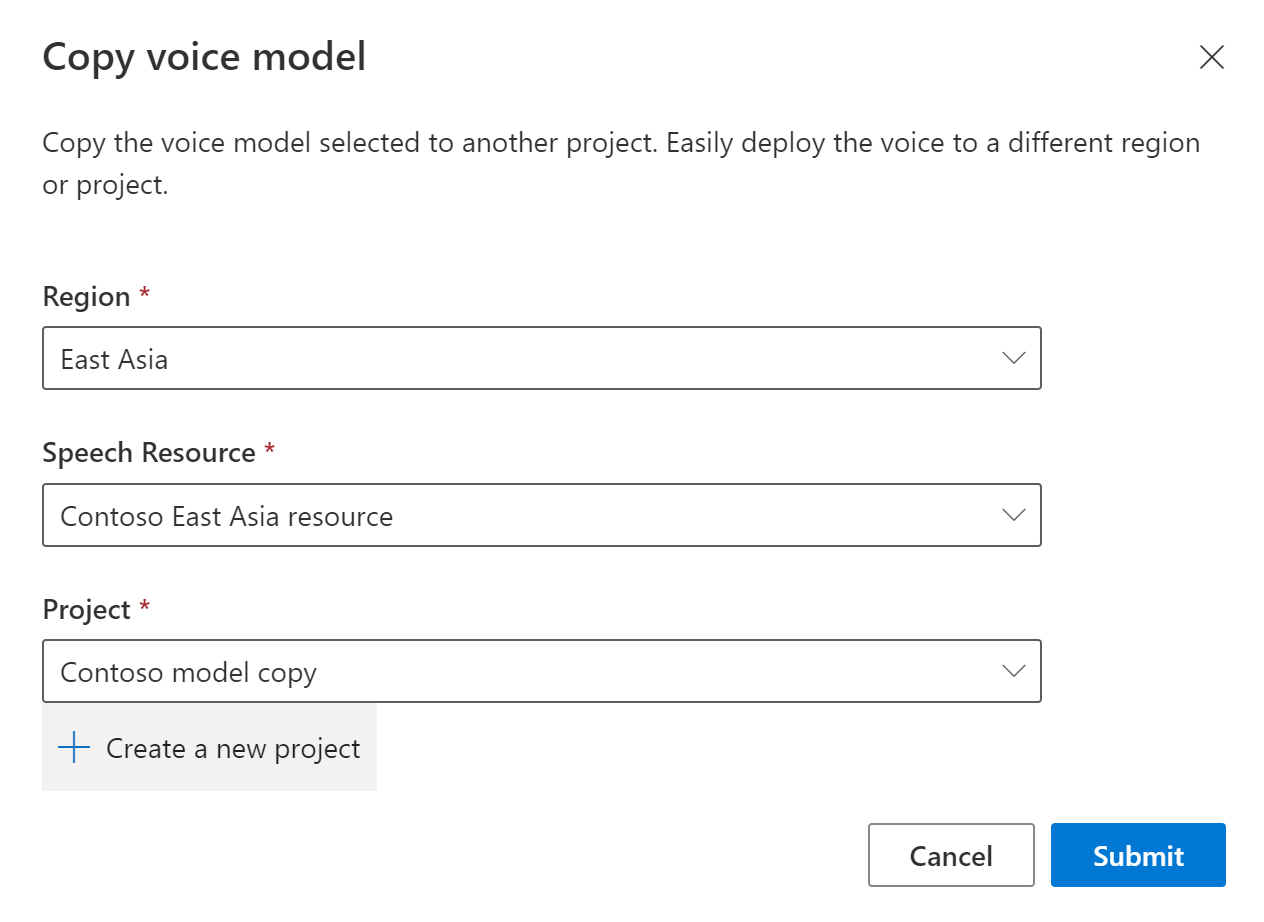
Seleccione Enviar para copiar el modelo.
Seleccione Ver modelo bajo el mensaje de notificación de copia correcta.
Vaya al proyecto donde ha copiado el modelo para implementar la copia del modelo.
Pasos siguientes
En este artículo, aprenderá a entrenar una voz neuronal personalizada a través de la API de voz personalizada.
Importante
El entrenamiento de voz neuronal personalizada actualmente solo está disponible en algunas regiones. Una vez entrenado el modelo de voz en una región compatible, puede copiarlo en un recurso de Voz que se encuentre en otra región, según sea necesario. Para más información, consulte las notas al pie de página de la tabla del servicio Voz.
La duración del entrenamiento varía en función de la cantidad de datos que use. En entrenar una voz neuronal personalizada se tarda una media de 40 horas de proceso. Los usuarios que tengan una suscripción estándar (S0) pueden entrenar cuatro voces simultáneamente. Si alcanza el límite, espere hasta que al menos uno de los modelos de voz finalice el aprendizaje e inténtelo de nuevo.
Nota:
Aunque el número total de horas necesarias por método de entrenamiento varía, se aplica el mismo precio unitario a cada uno. Para obtener más información, vea los detalles de precios de entrenamiento neuronal personalizado.
Elección de un método de entrenamiento
Después de validar los archivos de datos, puede usarlos para crear su modelo de voz neuronal personalizada. Al crear una voz neuronal personalizada, puede elegir entrenarla con uno de los métodos siguientes:
Neuronal: cree una voz en el mismo idioma de sus datos de entrenamiento.
Neuronal: multilingüe: cree una voz que hable un idioma diferente al de sus datos de entrenamiento. Comience con 300 expresiones. Por ejemplo, con los datos de entrenamiento
fr-FR, puede crear una voz que hableen-US.El idioma de los datos de entrenamiento y el de destino deben ser uno de los idiomas compatibles con el entrenamiento de voz multilingüe. No es necesario preparar datos de entrenamiento en el idioma de destino, pero el script de prueba sí que debe estar escrito en el idioma de destino.
Neuronal: varios estilos: cree una voz neuronal personalizada cuya habla incorpore varios estilos y emociones, sin agregar nuevos datos de entrenamiento. Las voces de varios estilos son útiles para personajes de videojuegos, bots de chat de conversación, audiolibros, lectores de contenido y mucho más.
Para crear una voz de varios estilos, debe preparar un conjunto de datos de entrenamiento generales, al menos 300 expresiones. Seleccione uno o varios de los estilos de habla de destino preestablecidos. También puede crear múltiples estilos personalizados proporcionando ejemplos de estilo, de al menos 100 expresiones por estilo, como datos de entrenamiento adicionales para la misma voz. Los estilos preestablecidos admitidos varían según los distintos idiomas. Consulte Estilos preestablecidos disponibles en diferentes idiomas.
El idioma de los datos de entrenamiento debe ser uno de los idiomas compatibles con el entrenamiento de voz neuronal personalizada, multilingüe o de varios estilos.
Creación de un modelo de voz
Para crear una voz neuronal, use la operación Models_Create de la API de voz personalizada. Construya el cuerpo de la solicitud según las instrucciones siguientes:
- Establezca la propiedad
projectIdrequerida. Consulte Creación de un proyecto. - Establezca la propiedad
consentIdrequerida. Consulte Agregar consentimiento de actor de voz. - Establezca la propiedad
trainingSetIdrequerida. Consulte Creación de un conjunto de entrenamiento. - Establezca la propiedad
kindde receta necesaria enDefaultpara el entrenamiento de voz neuronal. El tipo de receta indica el método de entrenamiento y no se puede cambiar más adelante. Para usar un método de entrenamiento diferente, vea Neuronal: multilingüe o Neuronal: varios estilos. Consulte Formación bilingüe para obtener más información sobre la formación bilingüe y las diferencias entre configuraciones regionales. - Establezca la propiedad
voiceNamerequerida. El nombre de voz debe terminar con "Neuronal" y no se puede cambiar más adelante. Elija un nombre con cuidado. El nombre de voz se usa en la solicitud de síntesis de voz por el SDK y la entrada SSML. Solo se permiten letras, números y algunos signos de puntuación. Use nombres diferentes para los modelos de voz neuronal diferentes. - Opcionalmente, establezca la propiedad
descriptionpara la descripción de voz. La descripción de voz se puede cambiar más adelante.
Haz una solicitud HTTP PUT usando el URI como se muestra en el siguiente ejemplo de Models_Create.
- Reemplace
YourResourceKeypor su clave de recurso de Voz. - Reemplace
YourResourceRegionpor la región del recurso de voz. - Reemplace
JessicaModelIdpor un identificador de modelo de su elección. El identificador que distingue mayúsculas de minúsculas se usará en el URI del modelo y no se puede cambiar más adelante.
curl -v -X PUT -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId"
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/models/JessicaModelId?api-version=2023-12-01-preview"
Debe recibir un cuerpo de respuesta en el formato siguiente:
{
"id": "JessicaModelId",
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default",
"version": "V7.2023.03"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId",
"locale": "en-US",
"engineVersion": "2023.07.04.0",
"status": "NotStarted",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
Formación bilingüe
Si selecciona el tipo de formación neuronal, puede entrenar una voz para hablar en varios idiomas. Tanto zh-CN como zh-TW regionales admiten la formación bilingüe para que la voz hable tanto en chino como en inglés. En función de los datos de entrenamiento, la voz sintetizada puede hablar inglés con un acento nativo inglés o inglés con el mismo acento que los datos de formación.
Nota:
Para habilitar una voz en la configuración regional zh-CN para hablar inglés con el mismo acento que los datos de ejemplo, debe elegir Chinese (Mandarin, Simplified), English bilingual al crear un proyecto o especificar la configuración regional zh-CN (English bilingual) para los datos del conjunto de entrenamiento a través de la API de REST.
En la siguiente tabla se muestran las diferencias entre las dos configuraciones regionales:
| Configuración regional de Speech Studio | Configuración regional de la API de REST | Soporte bilingüe |
|---|---|---|
Chinese (Mandarin, Simplified) |
zh-CN |
Si los datos de ejemplo incluyen el inglés, la voz sintetizada habla inglés con un acento nativo en inglés, en lugar del mismo acento que los datos de muestra, independientemente de la cantidad de datos en inglés. |
Chinese (Mandarin, Simplified), English bilingual |
zh-CN (English bilingual) |
Si desea que la voz sintetizada hable inglés con el mismo acento que los datos de ejemplo, se recomienda incluir más del 10 % de los datos en inglés en el conjunto de entrenamiento. De lo contrario, es posible que el acento de habla inglesa no sea ideal. |
Chinese (Taiwanese Mandarin, Traditional) |
zh-TW |
Si desea entrenar una voz sintetizada capaz de hablar inglés con el mismo acento que los datos de ejemplo, asegúrese de proporcionar más del 10 % de datos en inglés en el conjunto de entrenamiento. De lo contrario, el valor predeterminado es un acento nativo inglés. El umbral del 10 % se calcula en función de los datos aceptados después de la carga correcta, no los datos antes de cargarlos. Si algunos datos cargados en inglés se rechazan debido a defectos y no cumplen el umbral del 10 %, la voz sintetizada tiene como valor predeterminado un acento nativo inglés. |
Estilos preestablecidos disponibles en distintos idiomas
En la tabla siguiente se resumen los distintos estilos preestablecidos según los distintos idiomas.
| Estilo del habla | Idioma (local) |
|---|---|
| Enfadado | Inglés (Estados Unidos) (en-US)Japonés (Japón) ( ja-JP) 1Chino (mandarín, simplificado) ( zh-CN) 1 |
| Tranquilo | Chino (mandarín, simplificado) (zh-CN) 1 |
| chat | Chino (mandarín, simplificado) (zh-CN) 1 |
| Alegre | Inglés (Estados Unidos) (en-US)Japonés (Japón) ( ja-JP) 1Chino (mandarín, simplificado) ( zh-CN) 1 |
| Contrariado | Chino (mandarín, simplificado) (zh-CN) 1 |
| Emocionado | Inglés (Estados Unidos) (en-US) |
| Temeroso | Chino (mandarín, simplificado) (zh-CN) 1 |
| Amigable | Inglés (Estados Unidos) (en-US) |
| Esperanzado | Inglés (Estados Unidos) (en-US) |
| Triste | Inglés (Estados Unidos) (en-US)Japonés (Japón) ( ja-JP) 1Chino (mandarín, simplificado) ( zh-CN) 1 |
| Gritando | Inglés (Estados Unidos) (en-US) |
| Serio | Chino (mandarín, simplificado) (zh-CN) 1 |
| Aterrorizado | Inglés (Estados Unidos) (en-US) |
| antipático | Inglés (Estados Unidos) (en-US) |
| Susurrando | Inglés (Estados Unidos) (en-US) |
1 El estilo de voz neuronal está disponible en versión preliminar pública. Los estilos en versión preliminar pública solo están disponibles en estas regiones de servicio: Este de EE. UU., Oeste de Europa y Sudeste de Asia.
Obtención del estado del entrenamiento
Para obtener el estado de entrenamiento de un modelo de voz, use la operación Models_Get de la API de voz personalizada. Construya el URI de solicitud según las instrucciones siguientes:
Haga una solicitud HTTP GET con el URI, tal como se muestra en el siguiente ejemplo Models_Get.
- Reemplace
YourResourceKeypor su clave de recurso de Voz. - Reemplace
YourResourceRegionpor la región del recurso de voz. - Reemplace
JessicaModelIdsi especificó un identificador de modelo diferente en el paso anterior.
curl -v -X GET "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/models/JessicaModelId?api-version=2023-12-01-preview" -H "Ocp-Apim-Subscription-Key: YourResourceKey"
Debe recibir un cuerpo de respuesta en el siguiente formato.
Nota:
La receta kind y otras propiedades dependen de cómo entrene la voz. En este ejemplo, el tipo de receta es Default para el entrenamiento de voz neuronal.
{
"id": "JessicaModelId",
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default",
"version": "V7.2023.03"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId",
"locale": "en-US",
"engineVersion": "2023.07.04.0",
"status": "Succeeded",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
Es posible que tenga que esperar varios minutos antes de que se complete el entrenamiento. Finalmente, el estado cambiará a Succeeded o Failed.