Creación de particiones en Azure Cosmos DB for Apache Cassandra
SE APLICA A: ![]() Cassandra
Cassandra
En este artículo se describe cómo funciona la creación de particiones en Azure Cosmos DB for Apache Cassandra.
API para Cassandra usa la creación de particiones para escalar las tablas de un espacio de claves a fin de satisfacer las necesidades de rendimiento de la aplicación. Las particiones se crean en función del valor de una clave de partición que está asociada con cada registro de una tabla. Todos los registros de una partición tienen el mismo valor de clave de partición. Azure Cosmos DB administra de forma transparente y automática la ubicación de las particiones en los recursos físicos para satisfacer de manera eficaz las necesidades de escalabilidad y rendimiento de la tabla. A medida que aumentan los requisitos de rendimiento y almacenamiento de una aplicación, Azure Cosmos DB mueve y equilibra los datos entre un número mayor de máquinas físicas.
Desde la perspectiva del desarrollador, la creación de particiones se comporta de la misma manera en Azure Cosmos DB for Apache Cassandra que en Apache Cassandra nativo. Sin embargo, hay algunas diferencias en segundo plano.
Diferencias entre Apache Cassandra y Azure Cosmos DB
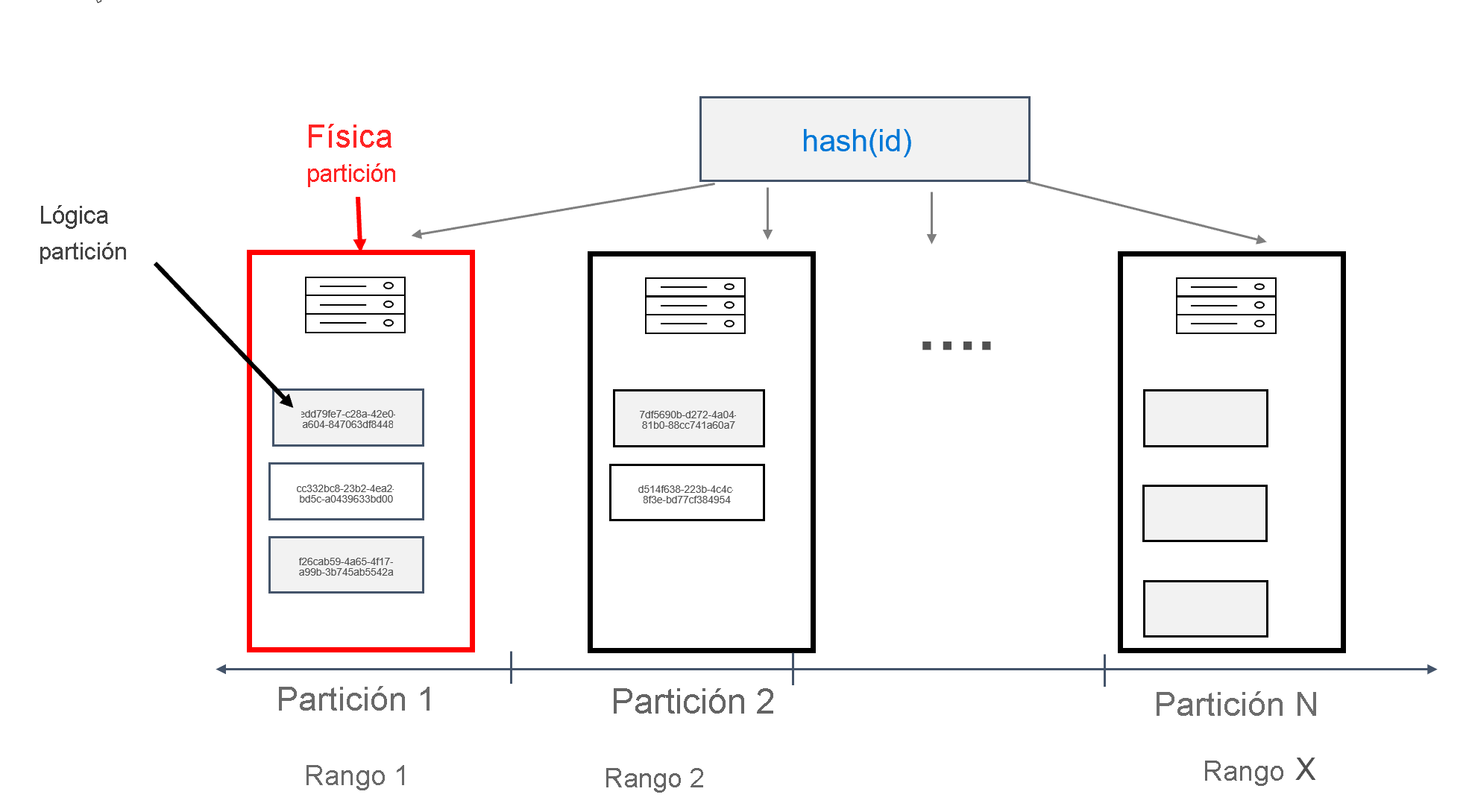
En Azure Cosmos DB, cada máquina en la que se almacenan las particiones se conoce como partición física. La partición física es similar a una máquina virtual, una unidad de proceso dedicada o un conjunto de recursos físicos. Cada partición almacenada en esta unidad de proceso se conoce como partición lógica en Azure Cosmos DB. Si ya está familiarizado con Apache Cassandra, puede considerar las particiones lógicas igual que las particiones normales de Cassandra.
Apache Cassandra recomienda un límite de 100 MB en el tamaño de los datos que se pueden almacenar en una partición. La API para Cassandra de Azure Cosmos DB permite hasta 20 GB por partición lógica y hasta 30 GB de datos por partición física. En Azure Cosmos DB, a diferencia de Apache Cassandra, la capacidad de proceso disponible en la partición física se expresa mediante una sola métrica denominada unidades de solicitud, lo que le permite considerar la carga de trabajo en términos de solicitudes (lecturas o escrituras) por segundo, en lugar de núcleos, memoria o número de IOPS. Como consecuencia, el planeamiento de la capacidad puede ser más sencillo, una vez que comprenda el costo de cada solicitud. Cada partición física puede tener hasta 10000 RU de proceso disponibles. Para más información sobre las opciones de escalabilidad, lea el artículo sobre escala elástica en API para Cassandra.
En Azure Cosmos DB, cada partición física se compone de un conjunto de réplicas, con al menos 4 réplicas por partición. No ocurre los mismo en Apache Cassandra, donde es posible establecer un factor de replicación de 1. Sin embargo, el resultado es una disponibilidad baja si el único nodo con datos deja de funcionar. En API para Cassandra siempre hay un factor de replicación de 4 (cuórum de 3). Azure Cosmos DB administra automáticamente los conjuntos de réplicas, mientras que en Apache Cassandra se deben mantener con varias herramientas.
Apache Cassandra tiene un concepto de tokens, que son valores hash de claves de partición. Los tokens se basan en un hash murmur3 de 64 bytes, con valores comprendidos entre--2^63 y -2^63 - 1. Este intervalo se conoce comúnmente como "Token Ring" en Apache Cassandra. Token Ring se distribuye en intervalos de tokens y estos intervalos se dividen entre los nodos presentes en un clúster de Apache Cassandra nativo. La creación de particiones para Azure Cosmos DB se implementa de forma similar, salvo que se usa un algoritmo hash diferente y tiene un Token Ring interno mayor. Sin embargo, externamente exponemos el mismo intervalo de token que Apache Cassandra, es decir -2^63 to -2^63 - 1.
Clave principal
Todas las tablas en API para Cassandra deben tener un elemento primary key definido. A continuación se muestra la sintaxis de una clave principal:
column_name cql_type_definition PRIMARY KEY
Supongamos que queremos crear una tabla de usuario, que almacena mensajes para diferentes usuarios:
CREATE TABLE uprofile.user (
id UUID PRIMARY KEY,
user text,
message text);
En este diseño, hemos definido el campo id como la clave principal. La clave principal funciona como el identificador del registro de la tabla y también se usa como clave de partición en Azure Cosmos DB. Si la clave principal se define en el modo descrito anteriormente, solo habrá un único registro en cada partición. El resultado será una distribución perfectamente horizontal y escalable al escribir datos en la base de datos, lo que es muy conveniente para los casos de uso de búsqueda de pares clave-valor. La aplicación debe proporcionar la clave principal cada vez que se lean datos de la tabla para maximizar el rendimiento de lectura.
Clave principal compuesta
Apache Cassandra también tiene un concepto de compound keys. Un elemento primary key compuesto consta de más de una columna; la primera columna es el elemento partition key y todas las columnas adicionales son los elementos clustering keys. La sintaxis de compound primary key se muestra a continuación:
PRIMARY KEY (partition_key_column_name, clustering_column_name [, ...])
Supongamos que queremos cambiar el diseño anterior y permitir la recuperación eficaz de mensajes para un usuario determinado:
CREATE TABLE uprofile.user (
user text,
id int,
message text,
PRIMARY KEY (user, id));
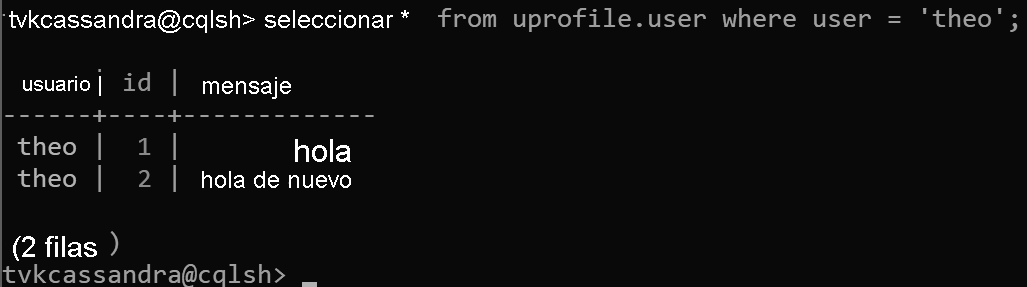
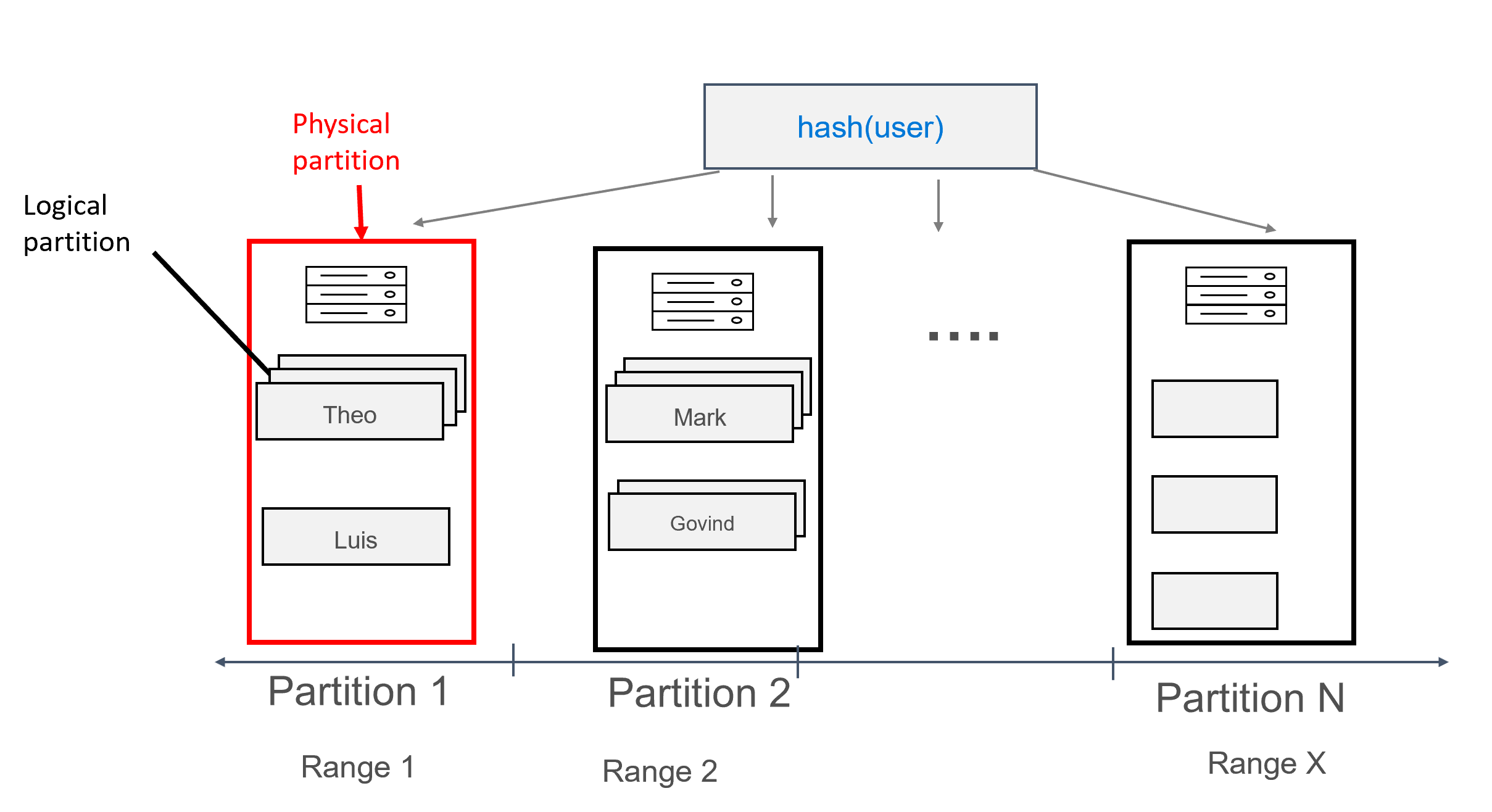
En este diseño, ahora vamos a definir user como clave de partición e id como clave de agrupación en clústeres. Puede definir tantas claves de agrupación en clústeres como desee, pero cada valor (o una combinación de valores) de esta clave debe ser único para que se agreguen varios registros a la misma partición, por ejemplo:
insert into uprofile.user (user, id, message) values ('theo', 1, 'hello');
insert into uprofile.user (user, id, message) values ('theo', 2, 'hello again');
Cuando se devuelven datos, se ordenan por la clave de agrupación en clústeres, tal y como se espera en Apache Cassandra:
Advertencia
Al consultar datos en una tabla con una clave principal compuesta, si desea filtrar por la clave de partición y cualquier otro campo no indexado aparte de la clave de agrupación en clústeres, asegúrese de agregar explícitamente un índice secundario en la clave de partición:
CREATE INDEX ON uprofile.user (user);
Azure Cosmos DB for Apache Cassandra no aplica índices a las claves de partición de forma predeterminada, y el índice de este escenario puede mejorar significativamente el rendimiento de las consultas. Revise nuestro artículo sobre indexación secundaria para obtener más información.
Con los datos modelados de esta manera, se pueden asignar varios registros a cada partición, agrupados por usuario. Por tanto, se puede emitir una consulta que se enrute de forma eficaz mediante el elemento partition key (en este caso, user) para obtener todos los mensajes de un usuario determinado.
Clave de partición compuesta
Las claves de partición compuestas funcionan esencialmente de la misma manera que las claves compuestas, salvo que se pueden especificar varias columnas como tales. A continuación se muestra la sintaxis de las claves de partición compuestas:
PRIMARY KEY (
(partition_key_column_name[, ...]),
clustering_column_name [, ...]);
Por ejemplo, puede tener lo siguiente, donde la combinación única de firstname y lastname formaría la clave de partición e id es la clave de agrupación en clústeres:
CREATE TABLE uprofile.user (
firstname text,
lastname text,
id int,
message text,
PRIMARY KEY ((firstname, lastname), id) );
Pasos siguientes
- Obtenga información sobre cómo crear particiones y escalado horizontal en Azure Cosmos DB.
- Información sobre el procesamiento aprovisionado en Azure Cosmos DB.
- Información sobre la distribución global en Azure Cosmos DB.