Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
SE APLICA A: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Cassandra
Cassandra ![]() Gremlin
Gremlin ![]() Table
Table
Azure Cosmos DB usa la creación de particiones con el fin de escalar contenedores individuales en una base de datos para satisfacer las necesidades de rendimiento de la aplicación. Los elementos de un contenedor se dividen en distintos subconjuntos, que se llaman particiones lógicas. Las particiones lógicas se crean en función del valor de una clave de partición que está asociada con cada elemento de un contenedor. Todos los elementos de una partición lógica tienen el mismo valor de clave de partición.
Por ejemplo, un contenedor contiene elementos. Cada elemento tiene un valor único para la propiedad UserID. Si UserID actúa como la partición de clave para los elementos de un contenedor y hay 1000 valores UserID exclusivos, se crearán 1000 particiones lógicas del contenedor.
Además de una clave de partición que determina la partición lógica del elemento, cada elemento de un contenedor tiene también un id. de elemento (que es único dentro de una partición lógica). Al combinar la clave de partición y el id. del elemento se crea el índice del elemento, que los identifica de forma única. Elegir una clave de partición es una decisión importante que afecta al rendimiento de la aplicación.
En este artículo, se explica la relación entre las particiones lógicas y las físicas. También se describen los procedimientos recomendados para crear particiones y se proporciona una perspectiva detallada sobre el funcionamiento del escalado horizontal en Azure Cosmos DB. No es necesario comprender estos detalles internos para seleccionar la clave de partición, pero se tratan aquí para que sepa cómo funciona Azure Cosmos DB.
Particiones lógicas
Una partición lógica consta de un conjunto de elementos con la misma clave de partición. Por ejemplo, en un contenedor con datos sobre nutrición, todos los elementos contienen la propiedad foodGroup. Puede utilizar foodGroup como clave de partición del contenedor. Los grupos de elementos que tienen valores específicos para foodGroup, tales como Beef Products, Baked Products y Sausages and Luncheon Meats, forman distintas particiones lógicas.
Una partición lógica también define el ámbito de las transacciones de base de datos. Puede actualizar los elementos dentro de una partición lógica mediante el uso de una transacción con aislamiento de instantánea. Cuando se agregan nuevos elementos al contenedor, el sistema crea nuevas particiones lógicas de forma transparente. No tiene que preocuparse de quitar una partición lógica una vez eliminados los datos subyacentes.
No existen límites en el número de particiones lógicas que puede tener el contenedor. Cada partición lógica puede almacenar un máximo de 20 GB de datos. Las claves de partición correctas son aquellas que tienen una amplia gama de valores posibles. Por ejemplo, en un contenedor donde todos los elementos contienen una propiedad foodGroup, los datos de la partición lógica Beef Products podrían crecer hasta los 20 GB. Seleccionar una clave de partición con una amplia gama de valores posibles garantiza que el contenedor se puede escalar.
Puede usar alertas de Azure Monitor para supervisar si el tamaño de una partición lógica se aproxima a 20 GB.
Particiones físicas
Un contenedor se escala mediante la distribución de los datos y el rendimiento entre particiones físicas. De forma interna, a cada partición física se asignan una o varias particiones lógicas. Normalmente, los contenedores más pequeños tienen muchas particiones lógicas, pero solo necesitan una partición física. A diferencia de las particiones lógicas, las particiones físicas son una implementación interna del sistema y es Azure Cosmos DB quien se encarga en exclusiva de su administración.
El número de particiones físicas del contenedor depende de las siguientes características:
La cantidad de rendimiento aprovisionado (cada partición física individual puede proporcionar un rendimiento de hasta 10 000 unidades de solicitud por segundo). El límite de 10 000 RU/s para las particiones físicas implica que las particiones lógicas también tienen un límite de 10 000 RU/s, ya que cada partición lógica solo se asigna a una partición física.
El almacenamiento de datos total (cada partición física individual puede almacenar hasta 50 GB de datos).
Nota:
Las particiones físicas son una implementación interna del sistema y es Azure Cosmos DB quien se encarga en exclusiva de su administración. Al desarrollar las soluciones, no se centre en las particiones físicas porque no las puede controlar. En su lugar, céntrese en las claves de las particiones. Si elige una clave de partición que distribuya uniformemente el consumo del rendimiento por las particiones lógicas, tendrá la seguridad de que el consumo del rendimiento está equilibrado entre las particiones físicas.
No existen límites en el número de particiones físicas que puede tener el contenedor. A medida que aumente el tamaño de los datos o el rendimiento aprovisionado, Azure Cosmos DB creará nuevas particiones físicas automáticamente dividiendo las particiones existentes. Las divisiones de las particiones físicas no afectan a la disponibilidad de la aplicación. Cuando una partición física se divide, todos los datos que estén en una partición lógica específica se guardarán en la misma partición física. Las divisiones de las particiones físicas simplemente crean una nueva asignación entre las particiones lógicas y las particiones físicas.
El rendimiento aprovisionado para un contenedor se divide uniformemente entre las particiones físicas. Un diseño de clave de partición que no distribuye las solicitudes de forma uniforme puede dar como resultado demasiadas solicitudes dirigidas a un pequeño subconjunto de particiones que se usa con demasiada frecuencia. Las particiones activas provocan un uso ineficiente del rendimiento aprovisionado, lo que puede traducirse en una limitación de la frecuencia y en costes más altos.
Por ejemplo, imagine un contenedor con la ruta de acceso /foodGroup especificada como clave de partición. El contenedor podría tener cualquier número de particiones físicas, pero en este ejemplo se supone que tiene tres. Una sola partición física podría contener varias claves de partición. Por ejemplo, la partición física más grande podría contener las tres particiones lógicas de mayor tamaño: Beef Products, Vegetable and Vegetable Products y Soups, Sauces, and Gravies.
Si se aprovisiona un rendimiento de 18 000 unidades de solicitud por segundo (RU/s), cada una de las tres particiones físicas puede usar un tercio del rendimiento aprovisionado total. Dentro de la partición física seleccionada, las claves de partición lógicas Beef Products, Vegetable and Vegetable Products y Soups, Sauces, and Gravies podrán, en conjunto, utilizar 6 000 RU/s aprovisionadas de la partición física. Como el rendimiento aprovisionado se reparte uniformemente entre las particiones físicas del contenedor, es importante elegir una clave de partición que distribuya el consumo uniformemente. Para más información, consulte Elección de la clave de partición lógica adecuada.
Administración de particiones lógicas
Azure Cosmos DB administra de forma transparente y automática la ubicación de las particiones lógicas en particiones físicas para satisfacer de manera eficaz las necesidades de escalabilidad y rendimiento del contenedor. A medida que aumentan los requisitos de rendimiento y almacenamiento de la aplicación, Azure Cosmos DB mueve las particiones lógicas para distribuir automáticamente la carga entre un número más elevado de particiones físicas. Puede obtener más información sobre las particiones físicas.
Azure Cosmos DB usa la creación de particiones por hash para distribuir las particiones lógicas entre las particiones físicas. Azure Cosmos DB aplica un algoritmo hash al valor de clave de partición de un elemento. El resultado con hash determina la partición lógica. A continuación, Azure Cosmos DB asigna el espacio de claves de los hash de claves de partición uniformemente entre las particiones físicas.
Las transacciones (en procedimientos almacenados o desencadenadores) solo se permiten con elementos dentro de una única partición lógica.
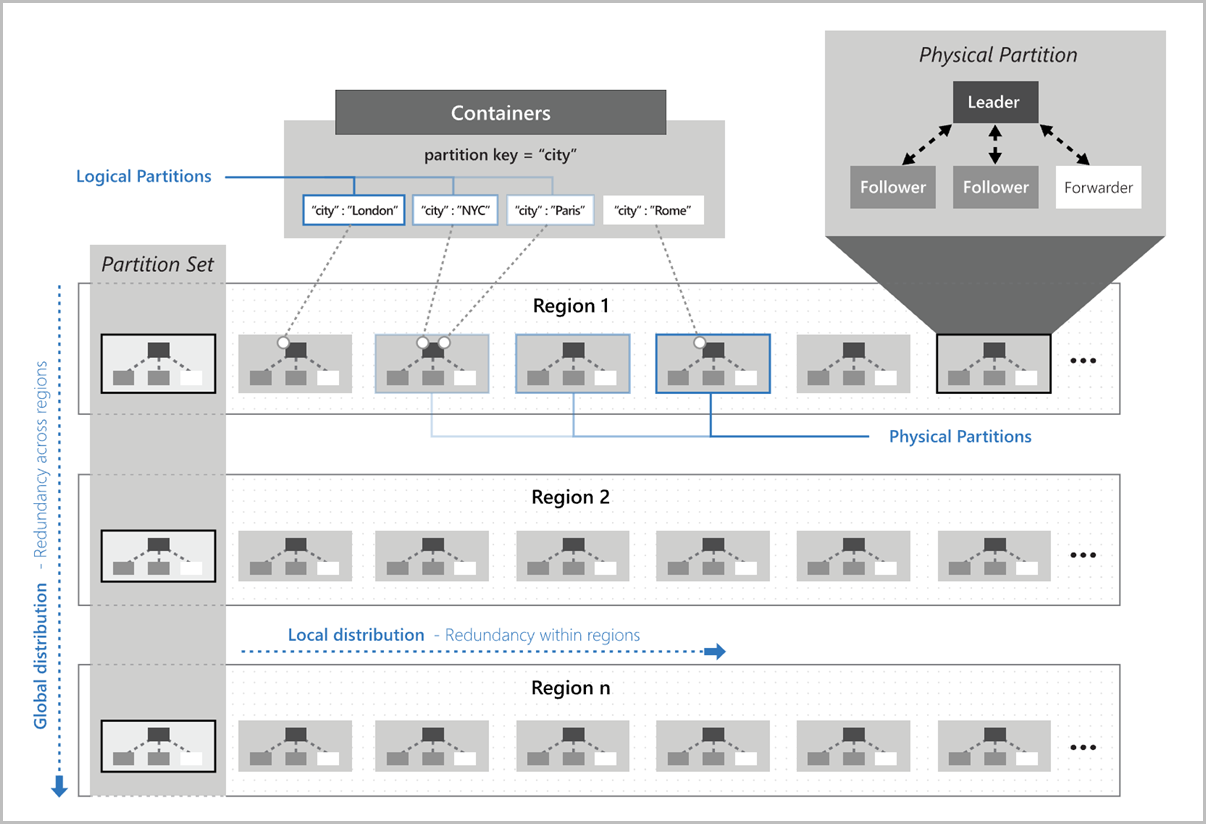
Conjuntos de réplicas
Cada partición física se compone de un conjunto de réplicas. Cada réplica hospeda una instancia del motor de base de datos. Los conjuntos de réplicas hacen que el almacén de datos de la partición física sea duraderos, coherente y tenga una alta disponibilidad. Cada réplica que compone la partición física hereda la cuota de almacenamiento. Y todas las réplicas de una partición física admiten colectivamente el rendimiento asignado a la partición física. Azure Cosmos DB administra automáticamente los conjuntos de réplicas.
Normalmente, los contenedores pequeños solo necesitan una partición física, pero siguen teniendo al menos cuatro réplicas.
La siguiente imagen muestra cómo se asignan particiones lógicas a particiones físicas distribuidas globalmente. El conjunto de particiones de la imagen hace referencia a un grupo de particiones físicas que administran las mismas claves de partición lógica en varias regiones:
Elegir una clave de partición
Una clave de partición tiene dos componentes: ruta de acceso de la clave de partición y valor de la clave de partición. Por ejemplo, considere un elemento { "userId" : "Andrew", "worksFor": "Microsoft" } si elige "userId" como la clave de partición. Estos son los dos componentes de la clave de partición:
La ruta de acceso de la clave de partición (por ejemplo: "/userId"). La ruta de acceso de la clave de partición acepta caracteres alfanuméricos y guiones bajos (_). También puede usar objetos anidados mediante la notación de ruta de acceso estándar (/).
El valor de la clave de partición (por ejemplo: "Andrew"). El valor de la clave de partición puede ser de tipo cadena o numérico.
Para obtener información sobre los límites de rendimiento, almacenamiento y longitud de la clave de partición, consulte el artículo Cuotas de servicio de Azure Cosmos DB.
La selección de la clave de partición es una decisión de diseño sencilla pero importante en Azure Cosmos DB. Una vez que haya seleccionado la clave de partición, no podrá cambiarla sin más. Si necesita cambiarla, debe trasladar los datos a un nuevo contenedor con la nueva clave de partición deseada. (los trabajos de copia de contenedor ayudan en este proceso).
Para todos los contenedores, la clave de partición debe:
Ser una propiedad con un valor invariable. Si una propiedad es la clave de partición, no se puede actualizar su valor.
Solo debe contener valores
String, o los números deben convertirse idealmente enString, si hay alguna posibilidad de que estén fuera de los límites de los números de doble precisión según IEEE 754 binary64. La especificación json señala las razones por las que utilizar números fuera de este límite en general es un procedimiento incorrecto debido a los probables problemas de interoperabilidad. Estos problemas son especialmente pertinentes para la columna de clave de partición, ya que es inmutable y requiere la migración de datos para cambiarla más adelante.Tener una cardinalidad alta. En otras palabras, la propiedad debe tener una amplia gama de valores posibles.
Distribuir el consumo de unidades de solicitud (RU) y el almacenamiento de datos uniformemente en todas las particiones lógicas. Esto garantiza una distribución uniforme del consumo de RU y el almacenamiento en las particiones físicas.
Tener valores que, por lo general, no superan los 2048 bytes (o 101 bytes si no están habilitadas las claves de partición grandes). Para más información, consulte Claves de partición de gran tamaño.
Si necesita transacciones ACID de varios elementos en Azure Cosmos DB, deberá usar procedimientos almacenados o desencadenadores. Todos los procedimientos almacenados y desencadenadores basados en JavaScript están limitados a una única partición lógica.
Nota:
Si solo tiene una partición física, es posible que el valor de la clave de partición no sea relevante, ya que todas las consultas tendrán como destino la misma partición física.
Tipos de claves de partición
| Estrategia de creación de particiones | Cuándo usar | Ventajas | Desventajas |
|---|---|---|---|
| Clave de partición normal (por ejemplo, CustomerId, OrderId) | - Se usa cuando la clave de partición tiene una cardinalidad alta y se alinea con los patrones de consulta (por ejemplo, el filtrado por CustomerId). - Adecuada para cargas de trabajo en las que las consultas tienen como destino principalmente los datos de un solo cliente (por ejemplo, la recuperación de todos los pedidos de un cliente). |
- Fácil de administrar. - Consultas eficaces cuando el patrón de acceso coincide con la clave de partición (por ejemplo, la consulta de todos los pedidos por CustomerId). - Impide consultas entre particiones si los patrones de acceso son coherentes. |
- Riesgo de particiones activas si algunos valores (por ejemplo, algunos clientes de tráfico elevado) generan mucho más datos que otros. - Puede alcanzar el límite de 20 GB por partición lógica si el volumen de datos de una clave específica crece rápidamente. |
| Clave de partición sintética (por ejemplo, CustomerId + OrderDate) | - Se usa cuando ningún campo tiene una cardinalidad alta y coincide con los patrones de consulta. - Adecuada para cargas de trabajo con muchas operaciones de escritura en las que los datos se deben distribuir de manera uniforme entre particiones físicas (por ejemplo, muchos pedidos realizados en la misma fecha). |
- Ayuda a distribuir los datos uniformemente entre las particiones, lo que reduce las particiones activas (por ejemplo, la distribución de pedidos por CustomerId y OrderDate). - Propaga las operaciones de escritura en varias particiones, lo que mejora el rendimiento. |
- Las consultas que solo filtran por un campo (por ejemplo, CustomerId solamente) pueden dar lugar a consultas entre particiones. - Las consultas entre particiones pueden provocar un mayor consumo de RU (cargo adicional de 2 a 3 RU/s por cada partición física que exista) y una latencia agregada. |
| Clave de partición jerárquica (HPK) (por ejemplo, CustomerId/OrderId, StoreId/ProductId) | - Se usa cuando es necesario crear particiones de varios niveles para admitir conjuntos de datos a gran escala. - Ideal cuando las consultas filtran por el primer y segundo nivel de la jerarquía. |
- Ayuda a evitar el límite de 20 GB mediante la creación de varios niveles de creación de particiones. - Consulta eficaz en ambos niveles jerárquicos (por ejemplo, filtrar primero por CustomerID y después por OrderID). - Minimiza las consultas entre particiones para las consultas destinadas al nivel superior (por ejemplo, la recuperación de todos los datos de un valor CustomerID específico). |
- Exige una planeación cuidadosa para asegurarse de que la clave de primer nivel tiene una cardinalidad alta y se incluye en la mayoría de las consultas. - Más compleja de administrar que una clave de partición normal. - Si las consultas no se alinean con la jerarquía (por ejemplo, solo se filtra por OrderID cuando CustomerID es el primer nivel), el rendimiento de las consultas podría verse afectado. |
Claves de partición para contenedores con lecturas frecuentes
En el caso de la mayoría de los contenedores, estos son todos los criterios que debe tener en cuenta a la hora de elegir una clave de partición. No obstante, en el caso de los contenedores con lecturas frecuentes, es posible que quiera elegir una clave de partición que aparece con frecuencia como filtro en las consultas. Las consultas se pueden enrutar de manera eficaz solo a las particiones físicas pertinentes si se incluye la clave de partición en el predicado de filtro.
Esta propiedad podría ser una buen clave de partición si la mayoría de las solicitudes de la carga de trabajo son consultas y la mayoría de las consultas tienen un filtro de igualdad en la misma propiedad. Por ejemplo, si ejecuta frecuentemente una consulta que filtra por UserID, al seleccionar UserID como clave de partición se reduciría el número de consultas entre particiones.
Sin embargo, si el contenedor es pequeño, probablemente no tenga suficientes particiones físicas como para preocuparse por el rendimiento de las consultas entre particiones. La mayoría de los contenedores pequeños en Azure Cosmos DB requieren solo una o dos particiones físicas.
Si el contenedor puede aumentar a unas cuantas particiones físicas, debe asegurarse de elegir una clave de partición que minimice las consultas entre particiones. Si se dan las siguientes condiciones, el contenedor tendrá suficiente con unas cuantas particiones físicas:
El contenedor tiene aprovisionadas más de 30 000 RU.
El contenedor almacena más de 100 GB de datos.
Uso del identificador de elemento como clave de partición
Nota:
Esta sección se aplica principalmente a la API para NoSQL. Otras API, como la API de Gremlin, no admiten el identificador único como clave de partición.
Si el contenedor tiene una propiedad con una amplia gama de posibles valores, probablemente sea una buena elección de clave de partición. Un posible ejemplo de una propiedad de este tipo, es el id. de elemento. En el caso de contenedores pequeños de lectura o escritura frecuente de cualquier tamaño, el id. de elemento (/id) es naturalmente una excelente opción de clave de partición.
La propiedad del sistema id. de elemento existe en todos los elementos del contenedor. Es posible que tenga otras propiedades que representen un identificador lógico para el elemento. En muchos casos, estos identificadores también son excelentes claves de partición por los mismos motivos que el identificador del elemento.
El id. de elemento es una excelente opción de clave de partición por los siguientes motivos:
- Hay una amplia gama de valores posibles (un id. de elemento único por elemento).
- Dado que cada elemento tiene un id. único, este id. de elemento realiza un trabajo excelente para equilibrar de manera uniforme el consumo de RU y el almacenamiento de datos.
- Puede realizar lecturas puntuales de forma eficiente, ya que siempre conocerá la clave de partición de un elemento si conoce su identificador.
Algunos aspectos que se deben tener en cuenta al seleccionar el id. de elemento como clave de partición son:
- Si el identificador del elemento es la clave de partición, se convertirá en un identificador único en todo el contenedor. No se pueden crear elementos con identificadores duplicados.
- Si tiene un contenedor con lecturas frecuentes que tiene muchas particiones físicas, las consultas serán más eficaces si disponen de un filtro de igualdad con el identificador del elemento.
- No se pueden ejecutar procedimientos almacenados ni desencadenadores que tengan como destino varias particiones lógicas.