Uso de Graph con particiones en Azure Cosmos DB
SE APLICA A: ![]() Gremlin
Gremlin
Una de las características clave de la API para Gremlin de Azure Cosmos DB es la posibilidad de tratar grafos a gran escala con escalado horizontal. Los contenedores pueden escalarse independientemente en términos de almacenamiento y rendimiento. Puede crear contenedores en Azure Cosmos DB que pueden escalarse automáticamente para almacenar los datos de un grafo. Los datos se equilibrarán automáticamente según la clave de partición especificada.
La creación de particiones se realiza internamente si se espera que el contenedor almacene más de 20 GB de tamaño o se quieren asignar más de 10 000 unidades de solicitud por segundo (RU). Las particiones de datos se crean automáticamente en función de la clave de partición que se especifica. La clave de partición es necesaria si se crean contenedores de gráficos desde Azure Portal o desde las versiones 3.x o posteriores de los controladores Gremlin. La clave de partición no es necesaria si usa las versiones 2.x o anteriores de los controladores de Gremlin.
Se aplican los mismos principios generales del mecanismo para crear particiones de Azure Cosmos DB con algunas optimizaciones específicas de Grafo que se describen a continuación.
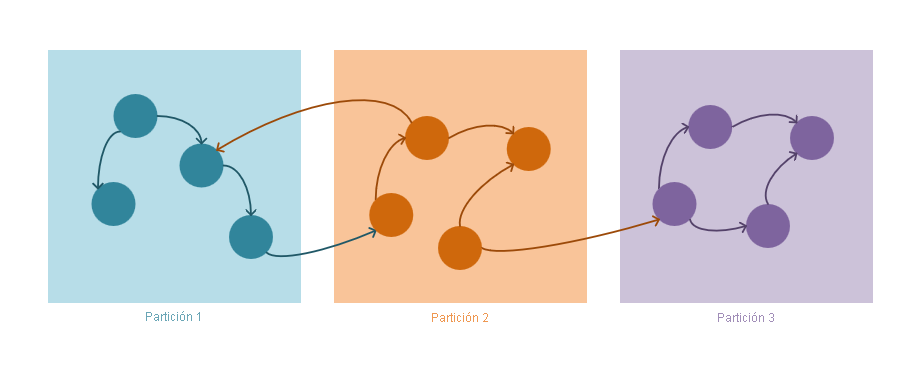
Mecanismo de creación de particiones de Graph
Las instrucciones siguientes describen cómo funciona la estrategia de creación de particiones de Azure Cosmos DB:
Los vértices y los bordes se almacenan como documentos JSON.
Los vértices requieren una clave de partición. Esta clave determinará en qué partición se almacenará el vértice a través de un algoritmo hash. El nombre de la propiedad de clave de partición se define al crear otro contenedor y tiene el siguiente formato:
/partitioning-key-name.Los bordes se almacenarán con sus vértices de origen. En otras palabras, para cada vértice, su clave de partición define dónde se almacena junto con sus bordes salientes. Esta optimización se hace para evitar consultas entre particiones cuando se usa la cardinalidad
out()en las consultas de grafo.Los bordes contienen referencias a los vértices a los que apuntan. Todos los bordes se almacenan con las claves de partición y los identificadores de los vértices a los que apuntan. Este cálculo hace que todas las consultas de dirección
out()sean siempre una consulta con particiones con ámbito y no una consulta ciega entre particiones.Las consultas de grafo tienen que especificar una clave de partición. Para aprovechar al máximo la partición horizontal en Azure Cosmos DB, la clave de partición debe especificarse al seleccionar un solo vértice, siempre que sea posible. Estas son las consultas para seleccionar uno o varios vértices en un grafo con particiones:
/idy/labelno se admiten como claves de partición para un contenedor en la API para Gremlin.Selección de un vértice por el identificador, use el paso
.has()para especificar la propiedad de clave de partición:g.V('vertex_id').has('partitionKey', 'partitionKey_value')Selección de un vértice, especifique una tupla con valor de clave de partición e identificador:
g.V(['partitionKey_value', 'vertex_id'])Selección de un conjunto de vértices con sus identificadores y especificación de una lista de valores de clave de partición:
g.V('vertex_id0', 'vertex_id1', 'vertex_id2', …).has('partitionKey', within('partitionKey_value0', 'partitionKey_value01', 'partitionKey_value02', …)Mediante la estrategia de partición al inicio de una consulta y la especificación de una partición para el ámbito del resto de la consulta de Gremlin:
g.withStrategies(PartitionStrategy.build().partitionKey('partitionKey').readPartitions('partitionKey_value').create()).V()
Procedimientos recomendados con un grafo con particiones
Para garantizar la escalabilidad y el rendimiento al usar grafos con particiones con contenedores ilimitados, siga estas directrices:
Especifique siempre el valor de la clave de partición al consultar un vértice. Obtener un vértice de una partición conocida es una forma de conseguir rendimiento. Todas las operaciones de adyacencia subsiguientes se limitarán siempre a una partición, porque los bordes contienen los identificadores de referencia y las claves de partición de sus vértices de destino.
Use la dirección saliente al consultar los bordes siempre que sea posible. Tal y como se mencionó anteriormente, los bordes se almacenan con sus vértices de origen en la dirección saliente. Por lo que se minimizan las posibilidades de recurrir a las consultas entre particiones cuando los datos y las consultas están diseñados con este patrón en mente. Por el contrario, la consulta
in()siempre será una consulta de distribución ramificada costosa.Elija una clave de partición que distribuya los datos uniformemente por las particiones. Esta decisión depende mucho el modelo de datos de la solución. Más información sobre la creación de una clave de partición apropiada en Partición y escalado en Azure Cosmos DB.
Optimice las consultas para obtener los datos dentro de los límites de una partición. Una estrategia de partición óptima se alinea con los patrones de consulta. Las consultas que obtienen datos de una sola partición proporcionan el mejor rendimiento.
Pasos siguientes
Ahora puede pasar a la lectura los artículos siguientes:
- Información acerca de la Partición y escalado en Azure Cosmos DB.
- Información acerca de la compatibilidad de Gremlin en la API para Gremlin.
- Información acerca de la introducción a la API para Gremlin.