Procedimientos para modelar y crear particiones de datos en Azure Cosmos DB mediante un ejemplo real
SE APLICA A: ![]() NoSQL
NoSQL
Este artículo se basa en varios conceptos de Azure Cosmos DB como el modelado de datos, la creación de particiones y rendimiento aprovisionado para demostrar cómo abordar un ejercicio de diseño de datos reales.
Si suele trabajar con bases de datos relacionales, es probable que haya desarrollado hábitos e intuiciones acerca de cómo diseñar un modelo de datos. Dadas no solo las restricciones específicas, sino también los puntos fuertes exclusivos de Azure Cosmos DB, la mayoría de estos procedimientos recomendados no se traduce bien y es posible que le lleve a soluciones que no llegan a ser óptimas. El objetivo de este artículo es guiarle por todo el proceso de modelado de un caso de uso real en Azure Cosmos DB, desde el modelado de elementos a la colocación de entidades y la creación de particiones en contenedores.
Descargue o vea un código fuente generado por la comunidad que ilustre los conceptos de este artículo.
Importante
Un colaborador de la comunidad ha contribuido a este ejemplo de código y el equipo de Azure Cosmos DB no admite su mantenimiento.
Escenario
Para este ejercicio, vamos a tener en cuenta el dominio de una plataforma de blogs en las que los usuarios pueden crear publicaciones. Los usuarios también pueden indicar que dichas publicaciones les gustan y agregarles comentarios.
Sugerencia
Hemos resaltado algunas palabras en cursiva; dichas palabras identifican el tipo de "cosas" que nuestro modelo va a tener que manipular.
Incorporación de más requisitos a la especificación:
- Una página frontal muestra una fuente de publicaciones recientemente creadas.
- Podemos capturar todas las publicaciones de un usuario, todos los comentarios de una publicación y todos los "Me gusta" de una publicación.
- Las publicaciones se devuelven con el nombre de usuario de sus autores y el número de comentarios y "Me gusta" que tienen.
- Los comentarios y "Me gusta" también se devuelven con el nombre de usuario de los usuarios que los han creado.
- Cuando se muestran en forma de listas, las publicaciones solo tienen que presentar un resumen truncado de su contenido.
Identificación de los patrones de acceso principales
Para empezar, proporcionamos cierta estructura a nuestra especificación inicial mediante la identificación de los patrones de acceso de nuestra solución. Al diseñar un modelo de datos para Azure Cosmos DB, es importante saber qué solicitudes tendrá que atender nuestro modelo para tener la certeza de que el modelo va a hacerlo de manera eficiente.
Para que el proceso general sea más fácil de seguir, categorizamos las diferentes solicitudes ya sea como comandos o consultas, y tomamos prestado parte del vocabulario de CQRS. En CQRS, los comandos son solicitudes de escritura (es decir, intenciones de actualizar el sistema) y las consultas son solicitudes de solo lectura.
Esta es la lista de solicitudes que expone nuestra plataforma:
- [C1] Crear o editar un usuario
- [Q1] Recuperar un usuario
- [C2] Crear o editar una publicación
- [Q2] Recuperar una publicación
- [Q3] Enumerar las publicaciones de un usuario en forma abreviada
- [C3] Crear un comentario
- [P4] Enumerar los comentarios de una publicación
- [C4] Gustar una publicación
- [Q5] Enumerar los "Me gusta" de una publicación
- [P6] Enumerar las x publicaciones más recientes creadas en formato abreviado (fuente)
En esta fase, aún no se ha pensado en los detalles de lo que va a contener cada entidad (usuario, publicación, etc.). Este paso suele estar entre los primeros en abordarse al diseñar en base a un almacén relacional. Comenzamos con este paso porque hay que averiguar cómo se van a traducir esas entidades en términos de tablas, columnas, claves externas, etc. Es una preocupación mucho menor con una base de datos de documentos que no aplica ningún esquema al escribir.
El motivo principal por el que es importante identificar los patrones de acceso desde el principio, es que esta lista de solicitudes va a ser nuestro conjunto de pruebas. Cada vez que iteramos el modelo de datos, pasamos por todas y cada una de las solicitudes y comprobamos su rendimiento y escalabilidad. Se calculan las unidades de solicitud consumidas en cada modelo y se optimizan. Todos estos modelos utilizan la directiva de indexación predeterminada, que se puede invalidar mediante la indexación de propiedades específicas. Esto puede mejorar aún más el consumo y la latencia de RU.
V1: una primera versión
Comenzamos con dos contenedores: users y posts.
Contenedor users
Este contenedor solo almacena elementos de usuario:
{
"id": "<user-id>",
"username": "<username>"
}
La partición de este contenedor la realizamos por id, lo que significa que cada partición lógica del contenedor solo contiene un elemento.
Contenedor posts
Este contenedor hospeda entidades como publicaciones, comentarios y "Me gusta":
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"title": "<post-title>",
"content": "<post-content>",
"creationDate": "<post-creation-date>"
}
{
"id": "<comment-id>",
"type": "comment",
"postId": "<post-id>",
"userId": "<comment-author-id>",
"content": "<comment-content>",
"creationDate": "<comment-creation-date>"
}
{
"id": "<like-id>",
"type": "like",
"postId": "<post-id>",
"userId": "<liker-id>",
"creationDate": "<like-creation-date>"
}
La partición de este contenedor la realizamos por postId, lo que significa que cada partición lógica de dicho contenedor contiene solo una publicación, junto con todos los comentarios y "Me gusta" de la misma.
Hemos introducido una propiedad type en los elementos almacenados en este contenedor para establecer una distinción entre los tres tipos de entidades que este contenedor hospeda.
Además, hemos elegido hacer referencia a los datos relacionados, en lugar de incrustarlo (consulte esta sección para más información acerca de estos conceptos) porque:
- no hay límite superior en el número de publicaciones que puede crear un usuario,
- las publicaciones pueden ser arbitrariamente largas,
- no límite superior con respecto al número de comentarios y "Me gusta" que puede tener una publicación
- queremos poder agregar un comentario o un "Me gusta" a una publicación sin tener que actualizar la propia publicación.
¿Hasta qué punto funciona bien nuestro modelo?
Ahora es el momento de evaluar el rendimiento y la escalabilidad de nuestra primera versión. En cada una de las solicitudes que ha identificado anteriormente, medimos su latencia y el número de unidades de solicitud que consume. Esta medida se realiza en un conjunto de datos ficticio que contiene 100 000 usuarios con entre 5 y 50 publicaciones por usuario y hasta 25 comentarios y 100 "Me gusta" por publicación.
[C1] Crear o editar un usuario
Esta solicitud es fácil de implementar, ya que acabamos de crear o actualizar un elemento en el contenedor users. Las solicitudes se esparcen entre todas las particiones gracias a la clave de partición id.
| Latency | Carga de unidad de solicitud | Rendimiento |
|---|---|---|
7 ms |
5.71 RU |
✅ |
[Q1] Recuperar un usuario
La recuperación de los usuarios se realiza mediante la lectura del elemento correspondiente del contenedor users.
| Latency | Carga de unidad de solicitud | Rendimiento |
|---|---|---|
2 ms |
1 RU |
✅ |
[C2] Crear o editar una publicación
Del mismo modo que [C1] , solo tenemos que escribir en el contenedor posts.
| Latency | Carga de unidad de solicitud | Rendimiento |
|---|---|---|
9 ms |
8.76 RU |
✅ |
[Q2] Recuperar una publicación
Empezaremos por recuperar el documento correspondiente del contenedor posts. Pero eso no es suficiente, ya que de acuerdo con nuestra especificación, también debemos agregar el nombre de usuario del creador de la publicación, el recuento de comentarios y el recuento de Me gusta de la publicación. Las agregaciones enumeradas requieren que se emitan 3 consultas SQL más.
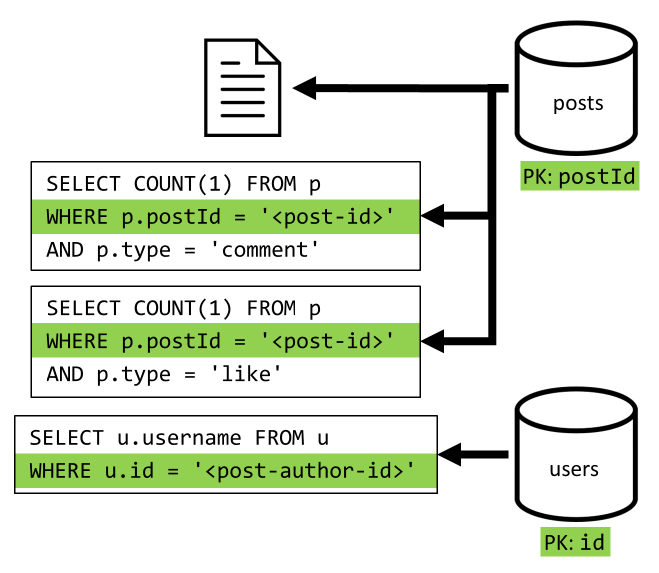
Cada uno de los filtros de consultas adicionales de la clave de partición de su respectivo contenedor, que es exactamente lo que deseamos para maximizar el rendimiento y la escalabilidad. Pero eventualmente tenemos que realizar cuatro operaciones para devolver una publicación individual, lo que mejoraremos en una iteración posterior.
| Latency | Carga de unidad de solicitud | Rendimiento |
|---|---|---|
9 ms |
19.54 RU |
⚠ |
[Q3] Enumerar las publicaciones de un usuario en forma abreviada
En primer lugar, tenemos que recuperar las publicaciones deseadas con una consulta SQL que captura las publicaciones correspondientes al usuario concreto. Pero también tenemos que emitir más consultas para agregar el nombre de usuario del creador y el número de comentarios y "Me gusta".
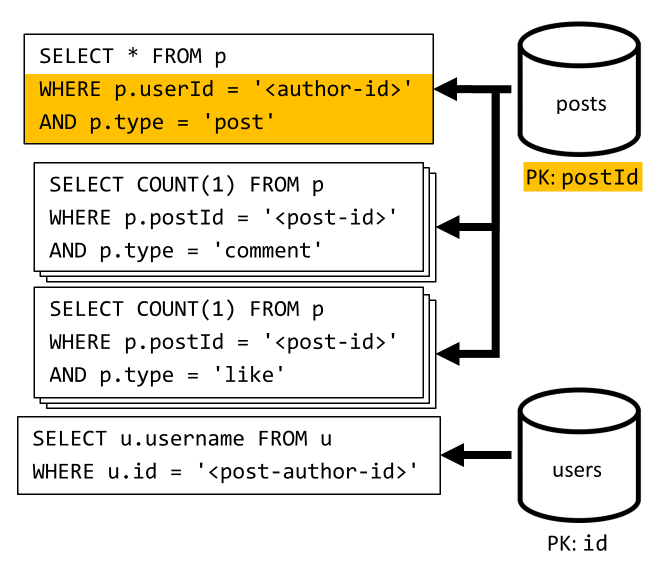
Esta implementación presenta muchas desventajas:
- las consultas que agregan el número de comentarios y "Me gusta" deben emitirse para cada publicación que devuelve la primera consulta,
- la consulta principal no se filtra en la clave de partición del contenedor
posts, lo que provoca una distribución ramificada y un examen de las particiones en el contenedor.
| Latency | Carga de unidad de solicitud | Rendimiento |
|---|---|---|
130 ms |
619.41 RU |
⚠ |
[C3] Crear un comentario
Los comentarios se crean mediante la escritura del elemento correspondiente en el contenedor posts.
| Latency | Carga de unidad de solicitud | Rendimiento |
|---|---|---|
7 ms |
8.57 RU |
✅ |
[Q4] Enumerar los comentarios de una publicación
Comenzamos con una consulta que captura todos los comentarios de la publicación y, una vez más, es preciso agregar los nombres de usuario agregados por separado para cada comentario.
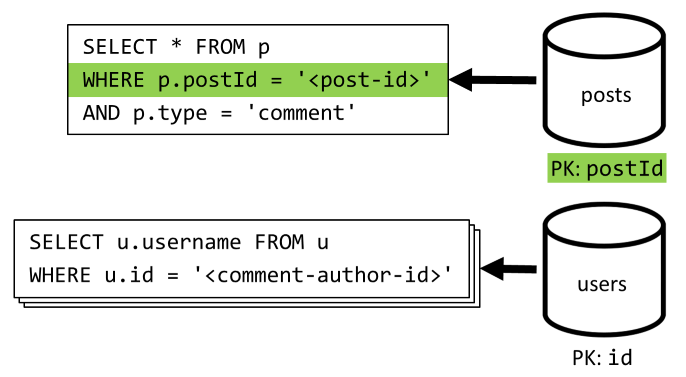
Aunque la consulta principal filtrar por la clave de partición del contenedor, agregar los nombres de usuario por separado penaliza el rendimiento general. Eso lo mejoraremos más adelante.
| Latency | Carga de unidad de solicitud | Rendimiento |
|---|---|---|
23 ms |
27.72 RU |
⚠ |
[C4] Gustar una publicación
Al igual que [C3] , creamos el elemento correspondiente en el contenedor posts.
| Latency | Carga de unidad de solicitud | Rendimiento |
|---|---|---|
6 ms |
7.05 RU |
✅ |
[Q5] Enumerar los "Me gusta" de una publicación
Al igual que [Q4] , se consulta los "Me gusta" para la publicación y, después, se agregan sus nombres de usuario.
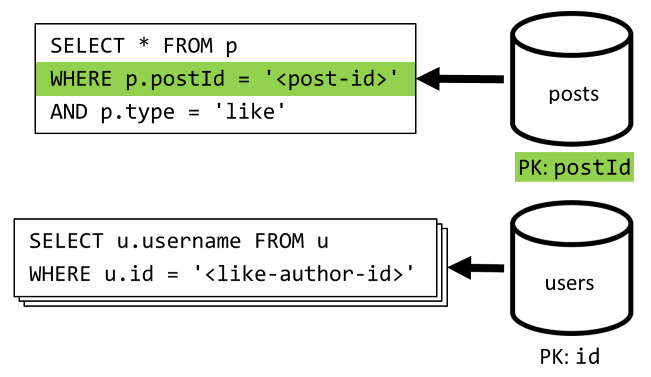
| Latency | Carga de unidad de solicitud | Rendimiento |
|---|---|---|
59 ms |
58.92 RU |
⚠ |
[Q6] Enumerar las x publicaciones más recientes creadas en formato abreviado (fuente)
Para capturar las publicaciones más recientes, consultamos el contenedor posts ordenado por fecha de creación orden, de forma descendente, y, después, los nombres de usuario agregados y el número de comentarios y "Me gusta" de cada una de las publicaciones.
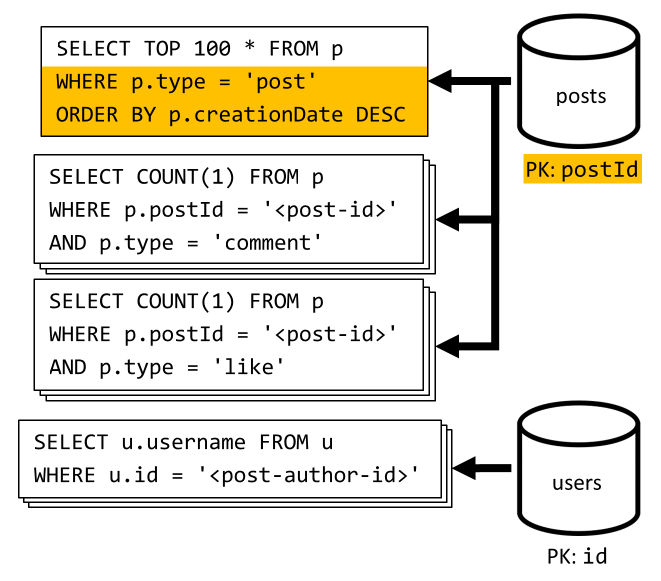
Una vez más, la consulta inicial no filtra por la clave de partición del contenedor posts, lo que desencadena una costosa distribución ramificada. Esta es incluso peor, ya que nos dirigimos a un conjunto de resultados más grande y ordenamos los resultados con una cláusula ORDER BY, lo que la hace más cara en términos de unidades de solicitud.
| Latency | Carga de unidad de solicitud | Rendimiento |
|---|---|---|
306 ms |
2063.54 RU |
⚠ |
Reflexión en el rendimiento de V1
Al examinar los problemas de rendimiento que nos encontramos en la sección anterior, podemos identificar dos clases principales:
- algunas solicitudes requieren que se emitan varias consultas para recopilar todos los datos que hay que devolver,
- algunas consultas no filtran por la clave de partición de los contenedores a los que van dirigidas, lo que da lugar a una distribución ramificada que impide la escalabilidad.
Vamos a resolver cada uno de estos problemas, empezando por el primero.
V2: presentación de la desnormalización para optimizar las consultas de lectura
El motivo por el que en algunos casos es preciso emitir más solicitudes es que los resultados de la solicitud inicial no contienen todos los datos que necesitamos devolver. La desnormalización de datos resuelve este tipo de problema en nuestro conjunto de datos al trabajar con un almacén de datos no relacional como Azure Cosmos DB.
En nuestro ejemplo, modificamos los elementos de la publicación para agregar el nombre de usuario del autor de la publicación y el número de comentarios y "Me gusta":
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"userUsername": "<post-author-username>",
"title": "<post-title>",
"content": "<post-content>",
"commentCount": <count-of-comments>,
"likeCount": <count-of-likes>,
"creationDate": "<post-creation-date>"
}
También modificamos los elementos de comentarios y, "Me gusta" para agregar el nombre de usuario del usuario que los ha creado:
{
"id": "<comment-id>",
"type": "comment",
"postId": "<post-id>",
"userId": "<comment-author-id>",
"userUsername": "<comment-author-username>",
"content": "<comment-content>",
"creationDate": "<comment-creation-date>"
}
{
"id": "<like-id>",
"type": "like",
"postId": "<post-id>",
"userId": "<liker-id>",
"userUsername": "<liker-username>",
"creationDate": "<like-creation-date>"
}
Desnormalización del número de comentarios y, "Me gusta"
Lo que queremos conseguir es que cada vez que agregamos un comentario o un "Me gusta", también aumentamos commentCount o likeCount en la publicación correspondiente. A medida que postId particiona nuestro contenedor posts, el nuevo elemento (comentario o "Me gusta") y su publicación correspondiente se colocan en la misma partición lógica. Como resultado, podemos usar un procedimiento almacenado para realizar dicha operación.
Cuando crea un comentario ([C3]), en lugar de simplemente agregar un nuevo elemento al contenedor posts llamamos al siguiente procedimiento almacenado de dicho contenedor:
function createComment(postId, comment) {
var collection = getContext().getCollection();
collection.readDocument(
`${collection.getAltLink()}/docs/${postId}`,
function (err, post) {
if (err) throw err;
post.commentCount++;
collection.replaceDocument(
post._self,
post,
function (err) {
if (err) throw err;
comment.postId = postId;
collection.createDocument(
collection.getSelfLink(),
comment
);
}
);
})
}
Este procedimiento almacenado toma el identificador de la publicación y el cuerpo del nuevo comentario como parámetros y luego:
- recupera la publicación
- incrementa el valor de
commentCount - reemplaza la publicación
- agrega el nuevo comentario
Dado que los procedimientos almacenados se ejecutan como transacciones atómicas, el valor de commentCount y el número real de comentarios siempre están sincronizados.
Obviamente llamamos a un procedimiento almacenado similar al agregar nuevos "Me gusta" para incrementar likeCount.
Desnormalización de nombres de usuario
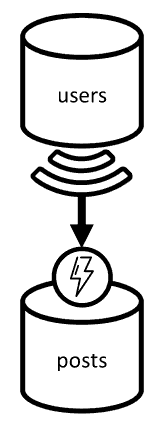
Los nombres de usuario requieren un enfoque diferente, ya que los usuarios no solo se encuentran en particiones distintas, sino también en un contenedor diferente. Cuando tenemos que desnormalizar los datos en las particiones y contenedores, podemos usar la fuente de cambios del contenedor de origen.
En nuestro ejemplo, usamos la fuente de cambios del contenedor users para reaccionar cuando los usuarios actualizan sus nombres de usuario. Cuando esto ocurre, propagamos el cambio llamando a otro procedimiento almacenado del contenedor posts:
function updateUsernames(userId, username) {
var collection = getContext().getCollection();
collection.queryDocuments(
collection.getSelfLink(),
`SELECT * FROM p WHERE p.userId = '${userId}'`,
function (err, results) {
if (err) throw err;
for (var i in results) {
var doc = results[i];
doc.userUsername = username;
collection.upsertDocument(
collection.getSelfLink(),
doc);
}
});
}
Este procedimiento almacenado toma el identificador del usuario y el nuevo nombre de usuario del usuario como parámetros y luego:
- recupera todos los elementos que coinciden con
userId(que puede ser publicaciones, comentarios, o "Me gusta") - en cada uno de los elementos
- reemplaza el valor de
userUsername - reemplaza el elemento
- reemplaza el valor de
Importante
Esta operación es costosa porque requiere que este procedimiento almacenado se ejecute en todas las particiones del contenedor posts. Suponemos que la mayoría de los usuarios eligen un nombre de usuario adecuado en el registro y que nunca lo cambiará, por lo que esta actualización se ejecutará con muy poca frecuencia.
¿Cuáles son las mejoras de rendimiento de V2?
Hablemos de algunas de las mejoras de rendimiento de V2.
[Q2] Recuperar una publicación
Ahora que la desnormalización está en vigor, solo tenemos que capturar un elemento para controlar la solicitud.
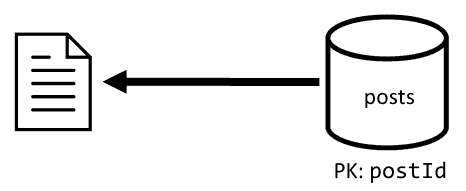
| Latency | Carga de unidad de solicitud | Rendimiento |
|---|---|---|
2 ms |
1 RU |
✅ |
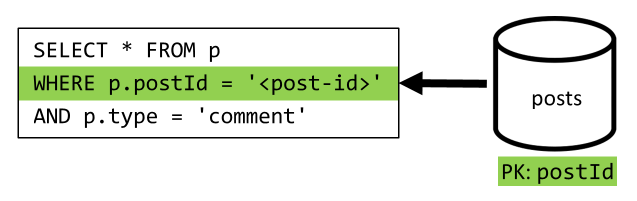
[Q4] Enumerar los comentarios de una publicación
Aquí podemos volver a compartir solicitudes adicionales que han capturado los el nombres de usuario y acabar con una sola consulta que filtra por la clave de partición.
| Latency | Carga de unidad de solicitud | Rendimiento |
|---|---|---|
4 ms |
7.72 RU |
✅ |
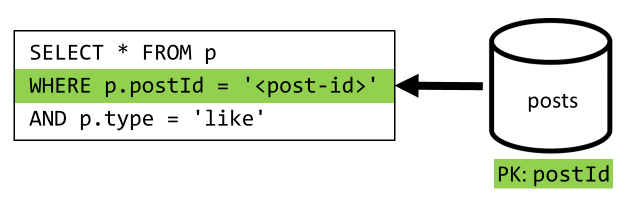
[Q5] Enumerar los "Me gusta" de una publicación
Exactamente la misma cuando se enumeran los "Me gusta".
| Latency | Carga de unidad de solicitud | Rendimiento |
|---|---|---|
4 ms |
8.92 RU |
✅ |
V3: asegurarse de que todas las solicitudes se pueden escalar
Todavía hay dos solicitudes que no hemos optimizado completamente al examinar nuestras mejoras generales de rendimiento. Estas solicitudes son [Q3] y [Q6]. Son las solicitudes que implican consultas que no filtran por la clave de partición de los contenedores a los que se dirige.
[Q3] Enumerar las publicaciones de un usuario en forma abreviada
Esta solicitud ya se beneficia de las mejoras introducidas en V2, que comparte más consultas.

Pero la consulta restante no se filtra por la clave de partición del contenedor posts.
La manera de pensar en esta situación es sencilla:
- Esta solicitud tiene que filtrar por
userId, ya que deseamos recuperar todas las publicaciones de un usuario en concreto. - No funciona bien porque se ejecuta en el contenedor
posts, que no se particiona medianteuserId. - Empezando por lo obvio, podríamos resolver nuestro problema de rendimiento mediante la ejecución de esta solicitud en un contenedor particionado con
userId. - Resulta que ya tenemos ese contenedor: el contenedor
users.
Por tanto, introducimos un segundo nivel de desnormalización mediante la duplicación de publicaciones completas en el contenedor users. Al hacerlo, obtenemos una copia de nuestras publicaciones, en las que solo se crean particiones en dimensiones diferentes, lo que hace que sea mucho más eficaz recuperarlas por userId.
El contenedor users ahora tiene dos tipos de elementos:
{
"id": "<user-id>",
"type": "user",
"userId": "<user-id>",
"username": "<username>"
}
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"userUsername": "<post-author-username>",
"title": "<post-title>",
"content": "<post-content>",
"commentCount": <count-of-comments>,
"likeCount": <count-of-likes>,
"creationDate": "<post-creation-date>"
}
En este ejemplo:
- Hemos introducido un campo
typeen el elemento de usuario para distinguir a los usuarios de las publicaciones, - También hemos agregado un campo
userIden el elemento de usuario, que es redundante con el campoid, pero es obligatorio, ya que el contenedorusersahora está particionado conuserId(noidcomo antes)
Para lograr dicha desnormalización, usamos una vez más la fuente de cambios. Esta vez reaccionamos ante la fuente de cambios del contenedor posts para enviar cualquier publicación nueva o actualizada al contenedor users. Y como la enumeración de publicaciones no requiere devolver todo su contenido, podemos truncarlas en el proceso.
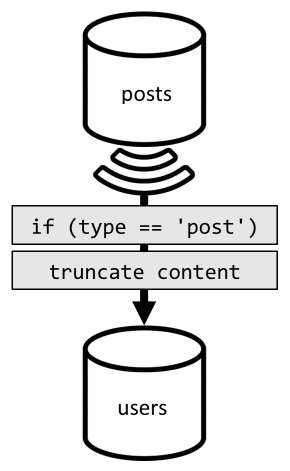
Ahora podemos enrutar nuestra consulta al contenedor users, filtrando por la clave de partición del contenedor.

| Latency | Carga de unidad de solicitud | Rendimiento |
|---|---|---|
4 ms |
6.46 RU |
✅ |
[Q6] Enumerar las x publicaciones más recientes creadas en formato abreviado (fuente)
Tenemos que tratar con una situación similar aquí: incluso después de compartir las consultas adicionales dejadas como innecesarias por la desnormalización introducida en V2, la consulta restante no se filtra por la clave de partición del contenedor:
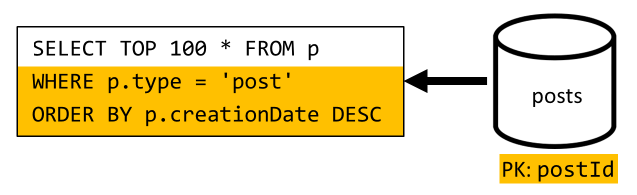
Siguiendo el mismo enfoque, la maximización del rendimiento y escalabilidad de esta solicitud requiere que solo acceda a una partición. Solo se puede alcanzar una sola partición porque solo tenemos que devolver un número limitado de elementos. Con el fin de rellenar la página principal de nuestra plataforma de blogs, solo debemos obtener las cien publicaciones más recientes, sin necesidad de paginar en todo el conjunto de datos.
Por lo que para optimizar esta última solicitud, se introduce un tercer contenedor en nuestro diseño, completamente dedicado a atender esta solicitud. Desnormalizamos nuestras publicaciones en ese nuevo contenedor feed:
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"userUsername": "<post-author-username>",
"title": "<post-title>",
"content": "<post-content>",
"commentCount": <count-of-comments>,
"likeCount": <count-of-likes>,
"creationDate": "<post-creation-date>"
}
El campo type particiona este contenedor, que siempre es post en nuestros elementos. Eso garantiza que todos los elementos de este contenedor se encontrarán en la misma partición.
Para lograr la desnormalización, solo tenemos que enlazar a la canalización de la fuente de cambios que hemos introducido anteriormente para enviar las publicaciones a ese nuevo contenedor. Hay algo importante que se debe tener en cuenta, que necesitamos asegurarnos de que solo almacenamos las 100 publicaciones más recientes; de lo contrario, el contenido del contenedor puede crecer más allá del tamaño máximo de una partición. Esta limitación se puede implementar llamando a un desencadenador posterior cada vez que se agrega un documento en el contenedor:
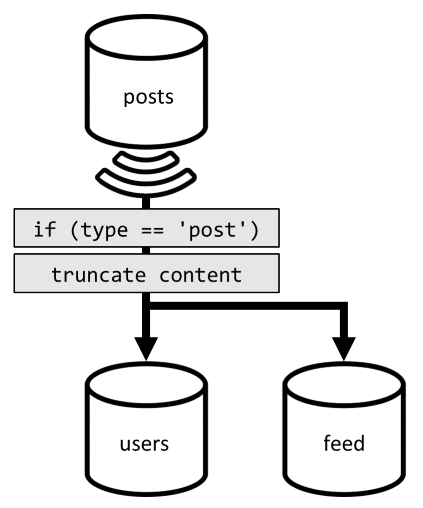
Este es el cuerpo del desencadenador posterior que trunca la colección:
function truncateFeed() {
const maxDocs = 100;
var context = getContext();
var collection = context.getCollection();
collection.queryDocuments(
collection.getSelfLink(),
"SELECT VALUE COUNT(1) FROM f",
function (err, results) {
if (err) throw err;
processCountResults(results);
});
function processCountResults(results) {
// + 1 because the query didn't count the newly inserted doc
if ((results[0] + 1) > maxDocs) {
var docsToRemove = results[0] + 1 - maxDocs;
collection.queryDocuments(
collection.getSelfLink(),
`SELECT TOP ${docsToRemove} * FROM f ORDER BY f.creationDate`,
function (err, results) {
if (err) throw err;
processDocsToRemove(results, 0);
});
}
}
function processDocsToRemove(results, index) {
var doc = results[index];
if (doc) {
collection.deleteDocument(
doc._self,
function (err) {
if (err) throw err;
processDocsToRemove(results, index + 1);
});
}
}
}
El último paso es para volver a enrutar nuestra consulta a nuestro nuevo contenedor feed:
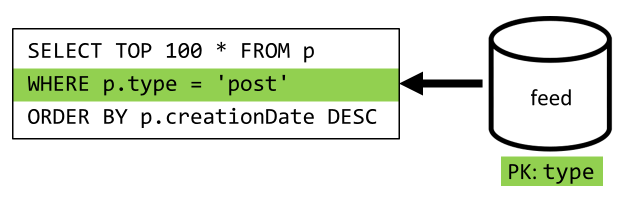
| Latency | Carga de unidad de solicitud | Rendimiento |
|---|---|---|
9 ms |
16.97 RU |
✅ |
Conclusión
Echemos un vistazo a las mejoras en el rendimiento y escalabilidad generales que hemos introducido en las distintas versiones de nuestro diseño.
| V1 | V2 | V3 | |
|---|---|---|---|
| [C1] | 7 ms / 5.71 RU |
7 ms / 5.71 RU |
7 ms / 5.71 RU |
| [Q1] | 2 ms / 1 RU |
2 ms / 1 RU |
2 ms / 1 RU |
| [C2] | 9 ms / 8.76 RU |
9 ms / 8.76 RU |
9 ms / 8.76 RU |
| [Q2] | 9 ms / 19.54 RU |
2 ms / 1 RU |
2 ms / 1 RU |
| [Q3] | 130 ms / 619.41 RU |
28 ms / 201.54 RU |
4 ms / 6.46 RU |
| [C3] | 7 ms / 8.57 RU |
7 ms / 15.27 RU |
7 ms / 15.27 RU |
| [Q4] | 23 ms / 27.72 RU |
4 ms / 7.72 RU |
4 ms / 7.72 RU |
| [C4] | 6 ms / 7.05 RU |
7 ms / 14.67 RU |
7 ms / 14.67 RU |
| [Q5] | 59 ms / 58.92 RU |
4 ms / 8.92 RU |
4 ms / 8.92 RU |
| [Q6] | 306 ms / 2063.54 RU |
83 ms / 532.33 RU |
9 ms / 16.97 RU |
Hemos optimizado un escenario en el que se realizan muchas lecturas
Es posible que haya observado que hemos concentrado nuestros esfuerzos en mejorar el rendimiento de las solicitudes de lectura (consultas) a costa de las solicitudes de escritura (comandos). En muchos casos, las operaciones de escritura desencadenan una desnormalización posteriores a través de fuentes de cambios, lo que hace que requieran más procesos computacionales y tarden más tiempo en materializarse.
Justificamos este enfoque en el rendimiento de lectura por el hecho de que una plataforma de blogs (como la mayoría de las aplicaciones sociales) es de lectura intensiva. Una carga de trabajo de lectura intensiva indica que la cantidad de solicitudes de lectura que tiene que servir suele ser órdenes de magnitudes más alta que la cantidad de solicitudes de escritura. Por consiguiente, tiene sentido realizar solicitudes de escritura cuya ejecución sea más costosas, con el fin de que las solicitudes de lectura sean mejores y más baratas.
Si examinamos la optimización más extrema que hemos realizado, [Q6] pasó de más de 2000 RU a solo 17 RU; esto lo hemos logrado mediante la desnormalización de publicaciones con un costo de aproximadamente 10 RU por elemento. Como se atenderían muchas más solicitudes de fuentes que de creación o actualizaciones de publicaciones, el costo de esta desnormalización es nimio, si se tiene en cuenta el ahorro general.
La desnormalización se puede aplicar de forma incremental
Las mejoras de escalabilidad que se han analizado en este implican la desnormalización y duplicación de datos en el conjunto de datos. Debe tenerse en cuenta que estas optimizaciones no necesariamente deben entrar en vigor el día 1. Las consultas que filtran por claves de partición funcionan mejor a gran escala, pero las consultas entre particiones pueden ser aceptables si se llama muy de vez en cuando o en un conjunto de datos limitado. Si solo está compilando un prototipo o iniciando un producto con una base de usuarios pequeña y controlada, probablemente pueda reservar esas mejoras para más adelante. Lo que es importante entonces es supervisar el rendimiento del modelo para poder decidir si es momento de implementarlas y cuándo implementarlas.
La fuente de cambios que usamos para distribuir las actualizaciones a otros contenedores almacena todas las actualizaciones sistemáticamente. Esta persistencia permite solicitar todas las actualizaciones desde la creación del contenedor y arrancar las vistas desnormalizadas como una operación de puesta al día que se realiza una sola vez, incluso si el sistema ya tiene muchos datos.
Pasos siguientes
Después de esta introducción práctica al modelado de datos y a la creación de particiones, es posible que desee consultar los artículos siguientes para revisar los conceptos que hemos tratado: