Procedimientos recomendados para escalar el rendimiento aprovisionado (RU/s)
SE APLICA A: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Cassandra
Cassandra ![]() Gremlin
Gremlin ![]() Table
Table
En este artículo se describen los procedimientos recomendados y las estrategias para escalar el rendimiento (RU/s) de la base de datos o el contenedor (colección, tabla o grafo). Los conceptos se aplican cuando aumenta las RU/s manuales aprovisionadas o las RU/s máximas de escalado automático de cualquier recurso para cualquiera de las API de azure Cosmos DB.
Prerrequisitos
- Si es la primera vez que hace una partición y escalado en Azure Cosmos DB, recomendamos que lea primero el artículo Creación de particiones y escalado horizontal en Azure Cosmos DB.
- Si planea escalar las RU/s debido a 429 excepciones, revise las instrucciones que encontrará en Diagnóstico y solución de problemas de las excepciones de tasa de solicitudes demasiado grande (429) en Azure Cosmos DB. Antes de aumentar las RU/s, identifique la causa principal del problema y confirme si el aumento de las RU/s es la solución adecuada.
Información general sobre el escalado de las RU/s
Cuando envía una solicitud para aumentar las RU/s de la base de datos o contenedor, en función de las RU/s solicitadas y del diseño de la partición física actual, la operación de escalado vertical se completará de forma instantánea o asincrónica (normalmente de 4 a 6 horas).
- Escalado vertical instantáneo
- Cuando las RU/s solicitadas pueden ser compatibles con el diseño de partición física actual, Azure Cosmos DB no necesita dividir ni agregar nuevas particiones.
- Como resultado, la operación se completa inmediatamente y las RU/s están disponibles para su uso.
- Escalado vertical asincrónico
- Cuando las RU/s solicitadas son superiores a lo que puede ser compatible con el diseño de partición física, Azure Cosmos DB dividirá las particiones físicas existentes. Esto sucede hasta que el recurso tiene el número mínimo de particiones necesarias para admitir las RU/s solicitadas.
- Como resultado, la operación puede tardar algún tiempo en completarse, normalmente de 4 a 6 horas. Cada partición física puede admitir un máximo de 10 000 RU/s (se aplica a todas las API) de rendimiento y 50 GB de almacenamiento (se aplica a todas las API, excepto Cassandra, que tiene 30 GB de almacenamiento).
Nota:
Si realiza una operación de conmutación por error de región manual o agrega o quita una nueva región mientras hay una operación asincrónica de escalado vertical en curso, la operación de escalado vertical del rendimiento se pausará. Se reanudará automáticamente cuando se complete la operación de conmutación por error o de agregar o quitar región.
- Escalado vertical instantáneo
- Para realizar la operación de reducción vertical, Azure Cosmos DB no necesita dividir ni agregar nuevas particiones.
- Como resultado, la operación se completa inmediatamente y las RU están disponibles para su uso.
- El resultado clave de esta operación es que se reducirán las RU por partición física.
Escalado vertical de las RU/s sin cambiar el diseño de la partición
Paso 1: Buscar el número actual de particiones físicas.
Vaya a Información>Rendimiento>Normalized RU Consumption (%) By PartitionKeyRangeID [Consumo de RU normalizado (%) por PartitionKeyRangeID]. Cuente el número distinto de PartitionKeyRangeIds.
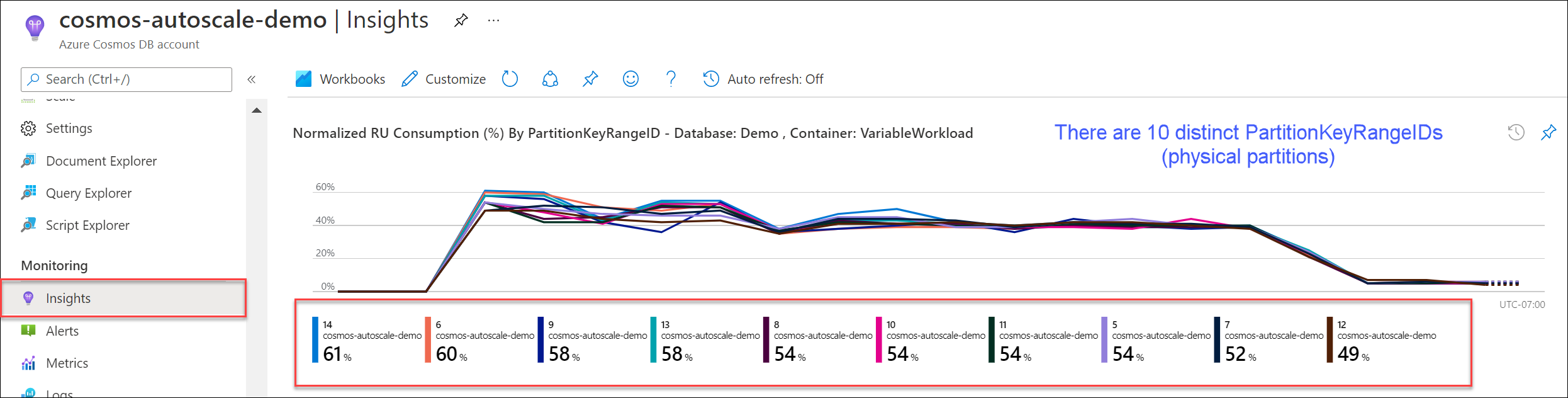
Nota:
El gráfico solo mostrará un máximo de 50 PartitionKeyRangeIds. Si el recurso tiene más de 50, puede usar la API de REST de Azure Cosmos DB para contar el número total de particiones.
Cada PartitionKeyRangeId se asigna a una partición física y se asigna para contener datos para un intervalo de valores hash posibles.
Azure Cosmos DB distribuye los datos entre particiones lógicas y físicas en función de la clave de partición para habilitar el escalado horizontal. A medida que se escriben los datos, Azure Cosmos DB usa el hash del valor de la clave de partición para determinar en qué partición lógica y física se encuentran los datos.
Paso 2: Calcular el rendimiento máximo predeterminado
Las mayor cantidad de RU/s a la que se puede escalar sin provocar que Azure Cosmos DB divida las particiones es igual a Current number of physical partitions * 10,000 RU/s. Puede obtener este valor del proveedor de recursos de Azure Cosmos DB. Realice una solicitud GET en los objetos de configuración de rendimiento base de datos o contenedor y recupere la propiedad instantMaximumThroughput. Este valor también está disponible en la página Escala y configuración, de la base de datos o el contenedor en el portal.
Ejemplo
Supongamos que tenemos un contenedor existente con cinco particiones físicas y 30 000 RU/s de rendimiento aprovisionado manual. Podemos aumentar las RU/s a 5 * 10 000 RU/s = 50 000 RU/s al instante. Del mismo modo, si hubo un contenedor con una escalabilidad automática máxima de las RU/s de 30 000 RU/s (escala entre 3000 y 30 000 RU/s), podríamos aumentar el número máximo de RU/s a 50 000 RU/s al instante (escala entre 5000 y 50 000 RU/s).
Sugerencia
Si va a escalar verticalmente las RU/s para responder a excepciones de tasa de solicitud demasiado grandes (429 s), se recomienda aumentar primero las RU/s hasta las más altas soportadas por su diseño de partición física actual y evaluar si las nuevas RU/s son suficientes antes de seguir aumentando.
Cómo garantizar la distribución uniforme de datos durante el escalado asincrónico
Información previa
Al aumentar las RU/s más allá del número actual de particiones físicas * 10 000 RU/s, Azure Cosmos DB divide las particiones existentes hasta que el nuevo número de particiones es igual a ROUNDUP(requested RU/s / 10,000 RU/s). Durante una división, las particiones primarias se dividen en dos particiones secundarias.
Por ejemplo, supongamos que tenemos un contenedor con tres particiones físicas y 30 000 RU/s de rendimiento aprovisionado manual. Si aumentamos el rendimiento a 45 000 RU/s, Azure Cosmos DB dividirá dos de las particiones físicas existentes para que, en total, haya ROUNDUP(45,000 RU/s / 10,000 RU/s) = 5 particiones físicas.
Nota:
Las aplicaciones siempre pueden ingerir o consultar datos durante una división. El servicio y los SDK de cliente de Azure Cosmos DB controlan automáticamente este escenario y garantizan que las solicitudes se enrutan a la partición física correcta, por lo que no se requiere ninguna acción adicional del usuario.
Si tiene una carga de trabajo que está distribuida de forma muy uniforme con respecto al almacenamiento y al volumen de solicitudes (normalmente se realiza mediante la creación de particiones con campos de cardinalidad alta como /id), se recomienda, al escalar verticalmente, establecer RU/s de forma que todas las particiones se dividan uniformemente.
Para ver por qué, veamos un ejemplo en el que tenemos un contenedor existente con 2 particiones físicas, 20 000 RU/s y 80 GB de datos.
Gracias a la elección de una buena clave de partición con una cardinalidad alta, los datos se distribuyen más o menos uniformemente en ambas particiones físicas. A cada partición física se le asigna aproximadamente el 50 % del espacio de claves, que se define como el intervalo total de valores hash posibles.
Además, Azure Cosmos DB distribuye las RU/s uniformemente entre todas las particiones físicas. Como resultado, cada partición física tiene 10 000 RU/s y el 50 % (40 GB) de los datos totales. En el diagrama siguiente se muestra nuestro estado actual.

Ahora, supongamos que queremos aumentar nuestras RU/s de 20 000 RU/s a 30 000 RU/s.
Si simplemente aumentamos las RU/s a 30 000 RU/s, solo se dividirá una de las particiones. Después de la división, tendremos:
- Una partición que contiene el 50 % de los datos (esta partición no se ha dividido)
- Dos particiones que contienen el 25 % de los datos cada una (son las particiones secundarias resultantes del elemento primario que se dividió)
Dado que Azure Cosmos DB distribuye RU/s uniformemente entre todas las particiones físicas, cada partición física seguirá teniendo 10 000 RU/s. Sin embargo, ahora tenemos un sesgo en el almacenamiento y la distribución de solicitudes.
En el diagrama siguiente, vemos que las Particiones 3 y 4 (las particiones secundarias de la Partición 2) tienen cada una 10 000 RU/s para atender solicitudes de 20 GB de datos, mientras que la Partición 1 tiene 10 000 RU/s para atender solicitudes para el doble de datos (40 GB).

Para mantener una distribución de almacenamiento uniforme, primero podemos escalar verticalmente nuestras RU/s para garantizar que cada partición se divida. A continuación, podemos reducir las RU/s al estado deseado.
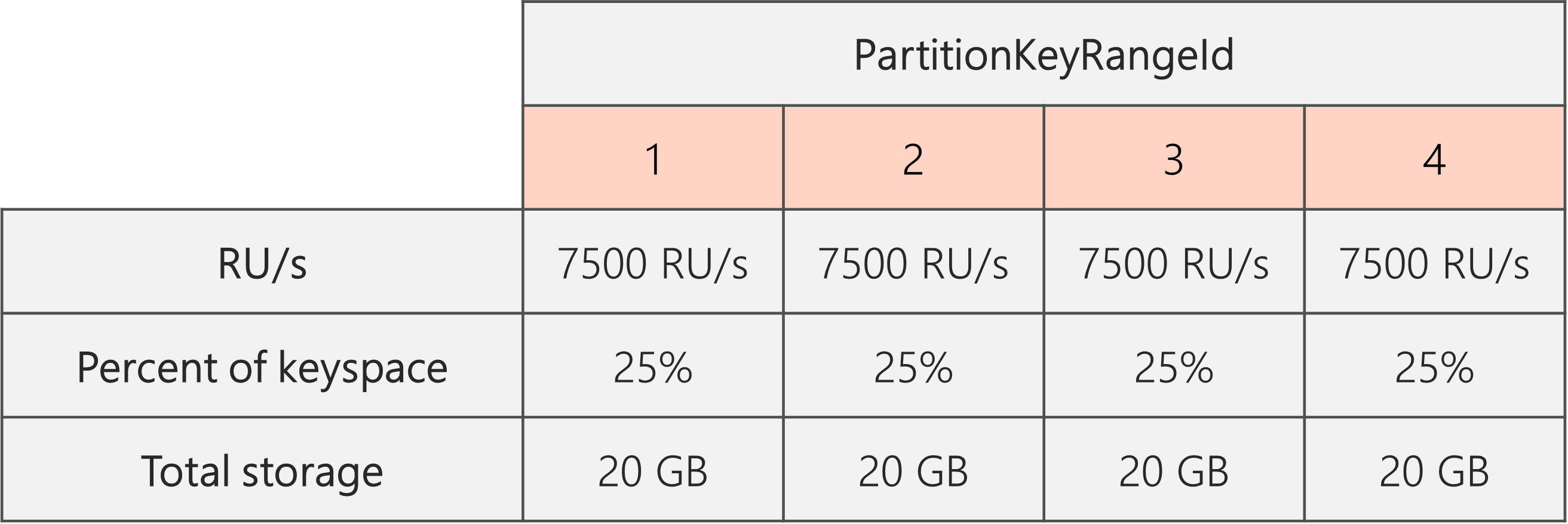
Por lo tanto, si empezamos con dos particiones físicas, para garantizar que las particiones sean iguales después de la división, es necesario establecer las RU/s de modo que terminemos con cuatro particiones físicas. Para ello, primero estableceremos las RU/s = 4 * 10 000 RU/s por partición = 40 000 RU/s. Después, una vez completada la división, podemos reducir nuestras RU/s a 30 000 RU/s.
Como resultado, vemos en el diagrama siguiente que cada partición física obtiene 30 000 RU/s/4 = 7500 RU/s para atender solicitudes de 20 GB de datos. En general, se mantiene el almacenamiento uniforme y la distribución de solicitudes entre particiones.
Fórmula general
Paso 1: Aumentar las RU/s para garantizar que todas las particiones se dividen uniformemente
En general, si tiene un número inicial de particiones físicas Py desea establecer una RU/s deseadaS:
Aumente la RU/s hasta 10,000 * P * (2 ^ (ROUNDUP(LOG_2 (S/(10,000 * P)))). De este modo se obtiene el valor de RU/s más cercano al deseado que garantizará que todas las particiones se dividan uniformemente.
Nota:
El aumento de las RU/s de una base de datos o contenedor puede afectar a las RU/s mínimas a las que se puede bajar en el futuro. Normalmente, las RU/s mínimas son iguales a MAX(400 RU/s, almacenamiento actual en GB * 1 RU/s, RU/s más altas aprovisionadas/ 100). Por ejemplo, si las RU/s más altas a las que ha escalado son de 100 000 RU/s, las RU/s más bajas que puede establecer en el futuro son 1000 RU/s. Obtenga más información sobre las RU/s mínimas.
Paso 2: Reducir las RU/s a las RU/s deseadas
Por ejemplo, supongamos que tenemos cinco particiones físicas y 50 000 RU/s y queremos escalar a 150 000 RU/s. Primero deberíamos establecer: 10,000 * 5 * (2 ^ (ROUND(LOG_2(150,000/(10,000 * 5)))) = 200 000 RU/s y después reducir a 150 000 RU/s.
Cuando escalamos verticalmente hasta 200 000 RU/s, las RU/s manuales más bajas que podemos establecer en el futuro son 2000 RU/s. El valor más bajo de RU/s máximas de escalabilidad automática que se puede establecer es de 20 000 RU/s (escala entre 2000 y 20 000 RU/s). Dado que nuestras RU/s de destino son 150 000 RU/s, no nos afectan las RU/s mínimas.
Optimización de RU/s para la ingesta de datos de gran tamaño
Cuando se planea migrar o ingerir una gran cantidad de datos en Azure Cosmos DB, se recomienda establecer las RU/s del contenedor de forma que Azure Cosmos DB aprovisione previamente las particiones físicas necesarias para almacenar la cantidad total de datos que se planea ingerir por adelantado. De lo contrario, durante la ingesta, Azure Cosmos DB puede tener que dividir particiones, lo que agrega más tiempo a la ingesta de datos.
Podemos aprovechar el hecho de que, durante la creación del contenedor, Azure Cosmos DB usa la fórmula heurística de iniciar RU/s para calcular el número de particiones físicas con las que empezar.
Paso 1: Revisar la elección de la clave de partición
Siga los procedimientos recomendados para elegir una clave de partición para asegurarse de que tendrá una distribución uniforme del volumen de solicitudes y del almacenamiento después de la migración.
Paso 2: Calcular el número de particiones físicas que necesitará
Number of physical partitions = Total data size in GB / Target data per physical partition in GB
Cada partición física puede contener un máximo de 50 GB de almacenamiento (30 GB para la API de Cassandra). El valor que debe elegir para el Target data per physical partition in GB depende de lo llenas que quiera que estén las particiones físicas y de cuánto espera que crezca el almacenamiento después de la migración.
Por ejemplo, si prevé que el almacenamiento seguirá creciendo, puede optar por establecer el valor en 30 GB. Suponiendo que haya elegido una buena clave de partición que distribuya uniformemente el almacenamiento, cada partición estará llena aproximadamente en un 60 % (30 GB de 50 GB). A medida que se escriben los datos futuros, se pueden almacenar en el conjunto existente de particiones físicas, sin necesidad de que el servicio agregue inmediatamente más particiones físicas.
Por el contrario, si cree que el almacenamiento no crecerá significativamente después de la migración, puede optar por establecer un valor más alto, por ejemplo, 45 GB. Esto significa que cada partición estará llena aproximadamente en un 90 % (45 GB de 50 GB). Esto minimiza el número de particiones físicas entre las que se reparten los datos, lo que significa que cada partición física puede obtener una fracción mayor del total de RU/s aprovisionadas.
Paso 3: Calcular el número de RU/s con las que empezar para todas las particiones
Starting RU/s for all partitions = Number of physical partitions * Initial throughput per physical partition.
Comencemos con un ejemplo con un número arbitrario de RU/s de destino por partición física.
Initial throughput per physical partition= 10 000 RU/s por partición física al usar bases de datos de escalado automático o rendimiento compartidoInitial throughput per physical partition= 6000 RU/s por partición física al usar el rendimiento manual
Ejemplo
Supongamos que tenemos 1 TB (1000 GB) de datos que tenemos previsto ingerir y queremos usar el rendimiento manual. Cada partición física de Azure Cosmos DB tiene una capacidad de 50 GB. Supongamos que nuestro objetivo es empaquetar las particiones para que se llenen al 80 % (40 GB), lo que nos deja espacio para el crecimiento futuro.
Esto significa que para 1 TB de datos se necesitarán 1000 GB/40 GB = 25 particiones físicas. Para asegurarse de que vamos a obtener 25 particiones físicas, si se usa el rendimiento manual, primero se aprovisionan 25 * 6000 RU/s = 150 000 RU/s. Después de crear el contenedor, para ayudar a que la ingesta sea más rápida, aumentamos las RU/s a 250 000 RU/s antes de que comience la ingesta (se produce al instante porque ya tenemos 25 particiones físicas). Esto permite que cada partición obtenga un máximo de 10 000 RU/s.
Si se usa el rendimiento de escalado automático o una base de datos de rendimiento compartido, para obtener 25 particiones físicas, primero se aprovisionan 25 * 10 000 RU/s = 250 000 RU/s. Dado que ya estamos en las RU/s más altas que se pueden admitir con 25 particiones físicas, no aumentaríamos aún más las RU/s aprovisionadas antes de la ingesta.
En teoría, con 250 000 RU/s y 1 TB de datos, si se supone que se requieren documentos de 1 kb y 10 RU para escritura, la ingesta puede completarse teóricamente en: 1000 GB * (1 000 000 kb/1 GB) * (1 documento/1 kb) * (10 RU/documento) * (1 s/250 000 RU) * (1 hora/3600 segundos) = 11,1 horas.
Este cálculo es una estimación suponiendo que el cliente que realiza la ingesta puede saturar completamente el rendimiento y distribuir las escrituras entre todas las particiones físicas. Como procedimiento recomendado, se recomienda "seleccionar aleatoriamente" los datos del lado del cliente. Esto garantiza que cada segundo, el cliente escribe en muchas particiones lógicas distintas (y, por tanto, físicas).
Una vez que haya terminado la migración, podemos reducir las RU/s o habilitar el escalado automático según sea necesario.
Pasos siguientes
- Supervisión del consumo normalizado de RU/s de la base de datos o el contenedor.
- Diagnóstico y solución de problemas de las excepciones de tasa de solicitud demasiado grande (429).
- Activación de la escalabilidad automática en una base de datos o un contenedor.