Redes sociales y Azure Cosmos DB
SE APLICA A: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Cassandra
Cassandra ![]() Gremlin
Gremlin ![]() Table
Table
Vivir en una sociedad enormemente interconectada significa que, en algún momento de la vida, uno formará parte de una red social. Las redes sociales se usan para mantenerse en contacto con amigos, compañeros de trabajo y familiares y, a veces, para compartir intereses comunes con otras personas.
Como ingeniero o desarrollador, puede que se haya preguntado cómo es que estas redes almacenan e interconectan sus datos. O bien es posible que incluso le hayan encargado crear o diseñar una nueva red social para un segmento de mercado específico. Es ahí cuando surge la pregunta importante: ¿Cómo se almacenan todos estos datos?
Suponga que quiere crear una red social nueva en la que los usuarios puedan publicar artículos y materiales como imágenes, vídeos o incluso música. En esta red social, los usuarios podrán comentar y valorar las publicaciones con fines de clasificación. Además, en la página de aterrizaje del sitio web, los usuarios verán e interactuarán con una fuente de publicaciones. Este método no parece complejo en un principio, pero por motivos de simplicidad, nos detendremos allí. (Puede profundizar en las fuentes de usuario personalizadas que son afectadas por las relaciones, pero eso va más allá del objetivo de este artículo).
Entonces, ¿cómo y dónde almacena estos datos?
Debe tener experiencia en bases de datos SQL o al menos tener nociones de modelado de datos relacional. Puede empezar a dibujar algo como lo siguiente:
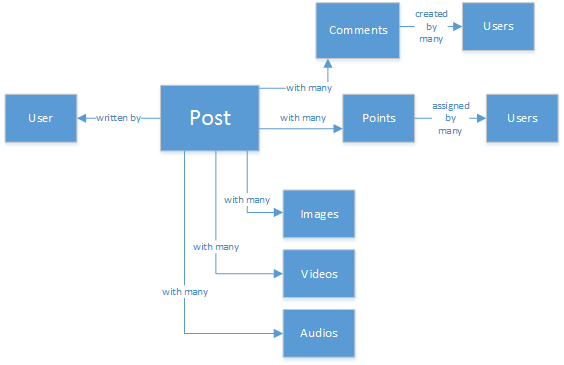
Sin embargo, a pesar de ser una estructura de datos perfectamente normalizada, no se escala.
No me malinterprete, he trabajado con bases de datos SQL toda mi vida. Son muy importantes, pero al igual que todos los patrones, prácticas y plataformas de software, no son perfectas para todos los escenarios.
¿Por qué SQL no es la mejor opción en este escenario? Echemos un vistazo a la estructura de una sola publicación. Si quisiéramos esa publicación en un sitio web o una aplicación, tendríamos que realizar una consulta WITH... mediante la combinación de ocho tablas(!) para mostrar una sola publicación. Ahora, cree una secuencia de entradas que se cargue dinámicamente y aparezcan en la pantalla.
Podría usar una instancia de SQL enorme con capacidad suficiente para resolver miles de consultas con muchas combinaciones para servir el contenido. Pero, ¿por qué habría de hacerlo cuando existe una solución más sencilla?
La vía NoSQL
En este artículo, se le guiará por el proceso de modelar los datos de su plataforma social con la base de datos de NoSQL de Azure, Azure Cosmos DB, de forma rentable. También, se le indicará cómo usar otras características de Azure Cosmos DB, como la API para Gremlin. Con un enfoque NoSQL, almacenamiento de datos en formato JSON y la aplicación de desnormalización, la publicación, que antes era complicada, ahora puede transformarse en un único documento:
{
"id":"ew12-res2-234e-544f",
"title":"post title",
"date":"2016-01-01",
"body":"this is an awesome post stored on NoSQL",
"createdBy":User,
"images":["https://myfirstimage.png","https://mysecondimage.png"],
"videos":[
{"url":"https://myfirstvideo.mp4", "title":"The first video"},
{"url":"https://mysecondvideo.mp4", "title":"The second video"}
],
"audios":[
{"url":"https://myfirstaudio.mp3", "title":"The first audio"},
{"url":"https://mysecondaudio.mp3", "title":"The second audio"}
]
}
Además, puede obtenerse con una sola consulta y sin combinaciones. Esta consulta es mucho más sencilla, directa, económica y requiere menos recursos para conseguir un mejor resultado.
Azure Cosmos DB se asegura de que todas las propiedades se indexen con su indexación automática. Además, puede personalizar la indexación automática. El enfoque sin esquema nos permite almacenar documentos con estructuras dinámicas y diferentes. ¿Tal vez mañana quiera que las publicaciones tengan una lista de categorías o hashtags asociados a ellas? Azure Cosmos DB gestionará los documentos nuevos con los atributos agregados sin requerir esfuerzo adicional de nuestra parte.
Los comentarios en una publicación pueden tratarse del mismo modo que otras publicaciones con una propiedad primaria. (Esta práctica simplifica la asignación de objetos).
{
"id":"1234-asd3-54ts-199a",
"title":"Awesome post!",
"date":"2016-01-02",
"createdBy":User2,
"parent":"ew12-res2-234e-544f"
}
{
"id":"asd2-fee4-23gc-jh67",
"title":"Ditto!",
"date":"2016-01-03",
"createdBy":User3,
"parent":"ew12-res2-234e-544f"
}
Por otro lado, todas las interacciones sociales pueden almacenarse en un objeto independiente como contadores:
{
"id":"dfe3-thf5-232s-dse4",
"post":"ew12-res2-234e-544f",
"comments":2,
"likes":10,
"points":200
}
Para la creación de fuentes solo es necesario crear documentos que puedan contener una lista de identificadores de publicación con un orden de importancia determinado:
[
{"relevance":9, "post":"ew12-res2-234e-544f"},
{"relevance":8, "post":"fer7-mnb6-fgh9-2344"},
{"relevance":7, "post":"w34r-qeg6-ref6-8565"}
]
Podría tener una secuencia "más recientes" con publicaciones ordenadas por fecha de creación. O bien podría tener una secuencia "más populares" con las publicaciones que han recibido más "me gusta" en las últimas 24 horas. Incluso podría implementar una secuencia personalizada para cada usuario según alguna lógica, como los seguidores e intereses. Aún así, sería una lista de publicaciones. Sin importar cómo cree estas listas, el rendimiento de lectura no se ve afectado. Una vez que adquiere una de estas listas, emite una consulta única a Azure Cosmos DB con la palabra clave IN para obtener páginas de publicaciones cada vez.
Los flujos de fuente se pueden generar mediante procesos en segundo plano de Azure App Services: Trabajos web. Una vez que se crea una publicación, el procesamiento en segundo plano puede activarse mediante el uso de Azure StorageQueues y Webjobs desencadenados mediante el SDK Azure Webjobs, implementando la propagación de publicaciones dentro de los flujos en función de nuestra lógica personalizada.
La puntuación y los "me gusta" de una publicación se pueden procesar de manera aplazada usando esta misma técnica para crear un entorno coherente.
Con los seguidores es más complicado. Azure Cosmos DB tiene un límite de tamaño para los documentos, por lo que la lectura o escritura de documentos de gran tamaño puede afectar a la escalabilidad de la aplicación. Por esta razón, debería plantearse almacenar los seguidores como un documento con esta estructura:
{
"id":"234d-sd23-rrf2-552d",
"followersOf": "dse4-qwe2-ert4-aad2",
"followers":[
"ewr5-232d-tyrg-iuo2",
"qejh-2345-sdf1-ytg5",
//...
"uie0-4tyg-3456-rwjh"
]
}
Esta estructura podría funcionar con un usuario con unos miles de seguidores. Sin embargo, si se trata de una persona famosa, este enfoque produciría un tamaño de documento grande y terminaría superándose el límite de tamaño de documentos.
Para solucionar este problema, podemos adoptar un enfoque mixto. Como parte del documento Estadísticas de usuario, se puede almacenar el número de seguidores:
{
"id":"234d-sd23-rrf2-552d",
"user": "dse4-qwe2-ert4-aad2",
"followers":55230,
"totalPosts":452,
"totalPoints":11342
}
Y puede almacenar el gráfico real de los seguidores con la API para Gremlin de Azure Cosmos DB, para crear vértices para cada usuario y bordes que mantienen relaciones del tipo "A sigue a B". Con la API para Gremlin, puede obtener los seguidores de un determinado usuario y crear consultas más complejas para sugerir personas en común. Si se agregan al gráfico las categorías de contenido que gustan o encantan a los individuos, podemos comenzar a componer escenarios que incluyen detección inteligente de contenido, sugerencias de contenido que gustan a las personas a las que seguimos o encontrar personas con quienes puede que se tenga mucho en común.
El documento de Estadísticas de usuario se sigue pudiendo usar para crear tarjetas en la interfaz de usuario o vistas previas rápidas de los perfiles.
El modelo "escalera" y la duplicación de datos
Como habrá observado en el documento JSON que hace referencia a una publicación, hay muchas coincidencias de un usuario. Y, como ya habrá imaginado, estos duplicados significan que la información que describe a un usuario, dada esta desnormalización, puede existir en más de un lugar.
Para permitir consultas más rápidas, se incurre en la duplicación de datos. El problema con este efecto secundario es que si, por alguna acción, cambian los datos de un usuario, habrá que buscar todas las actividades que ha hecho y actualizarlas. Lo cierto es que no parece muy práctico.
Se va a resolver mediante la identificación de los atributos clave de un usuario que se muestran en la aplicación para cada actividad. Si en nuestra aplicación se muestra una publicación tan solo con el nombre y la imagen del creador, ¿por qué almacenar todos los datos del usuario en el atributo "createdBy"? Si en cada comentario solo se muestra la imagen del usuario, no es necesario el resto de su información. Y aquí es donde entra en juego lo que yo llamo el modelo "escalera".
Tomemos como ejemplo información de usuario:
{
"id":"dse4-qwe2-ert4-aad2",
"name":"John",
"surname":"Doe",
"address":"742 Evergreen Terrace",
"birthday":"1983-05-07",
"email":"john@doe.com",
"twitterHandle":"\@john",
"username":"johndoe",
"password":"some_encrypted_phrase",
"totalPoints":100,
"totalPosts":24
}
Al examinar esta información, podemos detectar rápidamente cuál es información importante y cuál no, creando así una "escalera":

El paso más pequeño se denomina UserChunk: es el fragmento mínimo de información que identifica a un usuario y se usa para la duplicación de datos. Al reducir el tamaño de los datos duplicados a tan solo la información que "se muestra", se reduce también la posibilidad de actualizaciones masivas.
El paso intermedio se denomina usuario. Son todos los datos que se usarán en la mayoría de las consultas dependientes del rendimiento en Azure Cosmos DB: los datos a los que más accede y los más críticos. Incluye la información representada por un UserChunk.
El mayor es el usuario extendido. Incluye la información crítica del usuario y otros datos que no es necesario leer rápidamente ni tienen un posible uso, como el proceso de inicio de sesión. Estos datos pueden almacenarse fuera de Azure Cosmos DB, en Azure SQL Database o en tablas de Azure Storage.
¿Por qué se habría de dividir el usuario e incluso almacenar esta información en diferentes lugares? Porque desde el punto de vista del rendimiento, cuanto mayores sean los documentos, más costosas serán las consultas. Mantenga los documentos pequeños con la información necesaria para realizar todas las consultas dependientes del rendimiento de la red social. Almacene el resto de la información adicional para escenarios probables (como modificaciones del perfil completo, inicios de sesión y minería de datos) para los análisis de uso y las iniciativas de macrodatos. Realmente no importa si la recopilación de datos para minería de datos es más lenta, ya que se ejecuta en Azure SQL Database. Lo importante es que sus usuarios tengan una experiencia ligera y rápida. La apariencia de un usuario almacenado en Azure Cosmos DB sería similar al código siguiente:
{
"id":"dse4-qwe2-ert4-aad2",
"name":"John",
"surname":"Doe",
"username":"johndoe"
"email":"john@doe.com",
"twitterHandle":"\@john"
}
Asimismo, una solicitud Post tendría el aspecto siguiente:
{
"id":"1234-asd3-54ts-199a",
"title":"Awesome post!",
"date":"2016-01-02",
"createdBy":{
"id":"dse4-qwe2-ert4-aad2",
"username":"johndoe"
}
}
Cuando se produce una edición que afecta a un atributo de fragmento, puede encontrar fácilmente a los documentos afectados. Use consultas que apunten a los atributos indizados, como SELECT * FROM posts p WHERE p.createdBy.id == "edited_user_id" y, a continuación, actualice los fragmentos.
El cuadro de búsqueda
Los usuarios generarán, con suerte, gran cantidad de contenido. Debe proporcionar la capacidad de buscar y encontrar contenido que podría no estar directamente en los flujos de contenido de los usuarios, quizás porque no siguen a los creadores o quizás porque están buscando una publicación antigua de hace seis meses.
Gracias al empleo de Azure Cosmos DB, se puede implementar fácilmente un motor de búsqueda con Azure AI Search en un par de minutos y sin escribir una sola línea de código aparte del proceso de búsqueda y la interfaz de usuario.
¿Por qué es tan fácil este proceso?
Azure AI Search implementa lo que llaman "indexadores"; es decir, procesos en segundo plano que se enlazan en los repositorios de datos y automáticamente agregan, actualizan o quitan objetos en los índices. Son compatibles con indexadores de Azure SQL Database, indexadores de Blobs de Azure y, afortunadamente, indexadores de Cosmos DB. La transición de la información de Azure Cosmos DB a Azure AI Search es sencilla. Ambas tecnologías almacenan información en formato JSON, por lo que basta con crear el índice y asignar los atributos de los documentos que quiere indizar. ¡Ya está! Según el tamaño de los datos, todo el contenido estará disponible para realizar búsquedas en cuestión de minutos con la ayuda de la mejor solución de búsquedas como servicio en la infraestructura en la nube.
Para obtener más información sobre Azure AI Search, puede consultar la guía Hitchhiker’s Guide to Search(Guía de búsqueda de Hitchhiker).
La información subyacente
Después de almacenar todo este contenido que crece cada día más, es posible que se pregunte lo siguiente: ¿Qué puedo hacer con todo este flujo de información de mis usuarios?
La respuesta es sencilla: póngalo a trabajar y aprenda de él.
Pero, ¿qué se puede aprender? Por ejemplo, análisis de sentimiento, recomendaciones de contenido según las preferencias de un usuario o, incluso, un moderador automatizado que se asegura de que el contenido que publique nuestra red social sea adecuado para todos los públicos.
Ahora que ya está interesado, probablemente pensará que necesita un doctorado en ciencias matemáticas para extraer estos patrones y la información de los archivos y las bases de datos, pero no es así.
Azure Machine Learning es un servicio en la nube totalmente administrado que permite crear flujos de trabajo mediante algoritmos en una sencilla interfaz de arrastrar y colocar, programar sus propios algoritmos en R o usar algunas de las API integradas y listas para usar, como Text Analytics, Content Moderator o Recommendations.
Para posibilitar cualquiera de estos escenarios de Machine Learning, puede usar Azure Data Lake para ingerir la información de distintas fuentes. También puede usar U-SQL para procesar la información y generar una salida que Azure Machine Learning pueda procesar.
Otra opción disponible es usar los servicios de Azure AI para analizar el contenido de los usuarios; no solo se puede comprender mejor (mediante el análisis de lo que escriben con la API Text Analytics), sino que también se puede detectar contenido no deseado o contenido para adultos y actuar en consecuencia con la API Computer Vision. Los servicios de Azure AI incluyen una gran cantidad de soluciones listas para usar que no requieren ningún conocimiento de Machine Learning para usarlas.
Una experiencia social a escala mundial
Hay un último, pero no por ello menos importante, artículo que abordaremos: la escalabilidad. Al diseñar una arquitectura, cada componente debe escalarse por sí mismo. En algún momento tendrá que procesar más datos o querrá ampliar su cobertura geográfica. Afortunadamente, llevar a cabo ambas tareas es una experiencia inmediata con Azure Cosmos DB.
Azure Cosmos DB admite particiones dinámicas de fábrica. Automáticamente crea particiones basadas en una clave de partición específica, que se define como atributo en sus documentos. Debe definir la clave de partición correcta durante el tiempo de diseño. Para más información, consulte Creación de particiones en Azure Cosmos DB.
Para obtener una experiencia social, debe alinear la estrategia de creación de particiones con el modo de consulta y escritura. (Por ejemplo, es conveniente tener lecturas en la misma partición, así como evitar las "zonas activas" al propagar los procesos de escritura en varias particiones). Algunas opciones son: las particiones basadas en una clave temporal (día/mes/semana), por categoría de contenido, por región geográfica o por usuario. Todo depende de cómo va a consultar los datos y cómo va a mostrarlos en la experiencia social.
Azure Cosmos DB ejecutará las consultas (incluidas las agregaciones) en todas las particiones de forma transparente, por lo que no necesita agregar ninguna lógica a medida que crecen los datos.
Con el tiempo, el tráfico crecerá y su consumo de recursos (que se mide en RU o unidades de solicitud) aumentará. Leerá y escribirá con más frecuencia a medida que crece su base de usuarios. La base de usuarios comenzará a crear y a leer más contenido. Por lo que la capacidad de escalar el rendimiento es fundamental. Es fácil aumentar las RU. Se puede hacer con algunos clics en Azure Portal o a través de la emisión de comandos mediante la API.
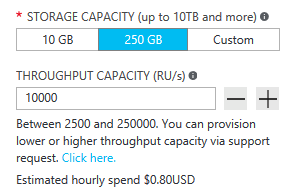
¿Qué ocurre si las cosas siguen mejorando? Supongamos que los usuarios de otro continente, país o región descubren su plataforma y empiecen a usarla. ¡Qué fantástica sorpresa!
Pero espere un momento. Pronto se dará cuenta de que su experiencia con la plataforma no es óptima. Están tan lejos de su región operativa que la latencia es enorme. Obviamente, no quiere que abandonen su red social. ¡Si tan solo hubiese una forma sencilla de extender su alcance global! Y la hay.
Azure Cosmos DB le permite replicar los datos global y transparentemente con un par de clics y seleccionar de forma automática entre las regiones disponibles del código de cliente. Este proceso también significa que tiene varias regiones de conmutación por error.
Cuando replica globalmente los datos, debe asegurarse de que los clientes puedan aprovecharlos. Si usa un front-end web o tiene acceso a las API desde clientes para dispositivos móviles, puede implementar Azure Traffic Manager y clonar la instancia de Azure App Service en todas las regiones deseadas mediante una configuración de rendimiento para admitir la cobertura global extendida. Cuando los clientes tienen acceso al front-end o a las API, se enrutan a la instancia de App Service más cercana que, a su vez, se conecta a la réplica local de Azure Cosmos DB.
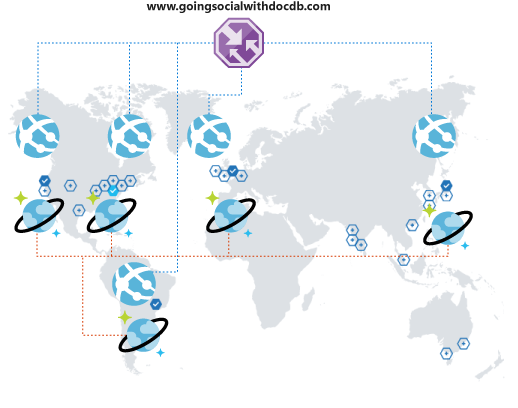
Conclusión
En este artículo se arroja luz sobre las alternativas para crear redes sociales completas en Azure con servicios de bajo costo. Se ofrecen resultados al fomentar el uso de una solución de almacenamiento y distribución de datos de varias capas denominada "escalera".
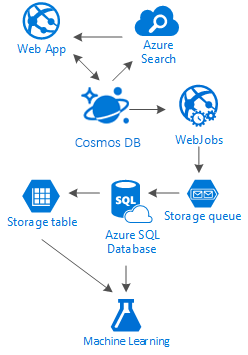
La verdad es que no hay ninguna solución mágica para este tipo de escenarios. Es la sinergia creada mediante la combinación de excelentes servicios lo que nos permite crear grandes experiencias: la velocidad y la libertad de Azure Cosmos DB para proporcionar una gran aplicación social; la inteligencia de una solución de búsqueda de primera clase como Azure AI Search; la flexibilidad de Azure App Services para hospedar aplicaciones independientes del lenguaje y eficaces procesos en segundo plano; los ampliables Azure Storage y Azure SQL Database para guardar cantidades ingentes de datos; y la potencia analítica de Azure Machine Learning para crear conocimiento e inteligencia que proporcionen información a nuestros procesos y nos ayuden a suministrar el contenido correcto a los usuarios adecuados.
Pasos siguientes
Para más información sobre los casos de uso de Azure Cosmos DB, consulte Casos de uso comunes de Azure Cosmos DB.