Eventos
Únase a nosotros en FabCon Vegas
31 mar, 11 p.m. - 2 abr, 11 p.m.
El evento definitivo dirigido por la comunidad de Microsoft Fabric, Power BI, SQL e IA. Del 31 de marzo al 2 de abril de 2025.
Regístrese hoy mismoEste explorador ya no es compatible.
Actualice a Microsoft Edge para aprovechar las características, las actualizaciones de seguridad y el soporte técnico más recientes.
SE APLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. ¡Obtenga más información sobre cómo iniciar una nueva evaluación gratuita!
Integration Runtime (IR) es la infraestructura de proceso que usan las canalizaciones de Azure Data Factory y Azure Synapse para proporcionar las siguientes funcionalidades de integración de datos en distintos entornos de red:
En las canalizaciones de Data Factory y Synapse, una actividad define la acción que se realizará. Un servicio vinculado define un almacén de datos o un servicio de proceso de destino. Un entorno de ejecución de integración proporciona el puente entre las actividades y los servicios vinculados. El servicio vinculado o la actividad hace referencia a él y proporciona el entorno de proceso en el que la actividad se ejecuta directamente o se envía. De esta forma, la actividad se puede realizar en la región más cercana posible al almacén de datos de destino o al servicio de proceso para maximizar el rendimiento, a la vez que permite flexibilidad para cumplir los requisitos de seguridad y cumplimiento.
Los entornos de ejecución de integración se pueden crear en las interfaces de usuario de Azure Data Factory y Azure Synapse por medio del centro de administración directamente y de cualquier actividad, conjunto de datos o flujo de datos que haga referencia a ellos.
Data Factory ofrece tres tipos de entornos de ejecución de integración (IR) y debe elegir el que mejor se adapte a sus funcionalidades de integración de datos y a los requisitos del entorno de red. Los tres tipos de IR son:
Nota
Actualmente, las canalizaciones de Synapse solo admiten entornos de ejecución de integración de Azure o autohospedados.
En la tabla siguiente se describen las funcionalidades y la compatibilidad de red para cada uno de los tipos de instancias de Integration Runtime:
| Tipo de IR | Compatibilidad con redes públicas | Compatibilidad con Private Link |
|---|---|---|
| Azure | Data Flow Movimiento de datos Distribución de actividades |
Data Flow Movimiento de datos Distribución de actividades |
| Autohospedado | Movimiento de datos Distribución de actividades |
Movimiento de datos Distribución de actividades |
| SSIS de Azure | Ejecución de paquetes SSIS | Ejecución de paquetes SSIS |
Nota
Los controles de salida varían según el servicio para Azure IR. En Synapse, las áreas de trabajo tienen opciones para limitar el tráfico saliente de la red virtual administrada al usar Azure IR. En Data Factory, todos los puertos se abren para las comunicaciones salientes al usar Azure IR. Azure-SSIS IR se puede integrar con la red virtual para proporcionar controles de comunicaciones salientes.
Una instancia de Azure Integration Runtime puede:
Azure Integration Runtime admite la conexión con almacenes de datos y servicios de proceso con puntos de conexión de acceso público. Al habilitar Virtual Network administrado y Azure Integration Runtime se admite la conexión a almacenes de datos mediante el servicio de Private Link en el entorno de red privada. En Synapse, las áreas de trabajo tienen opciones para limitar el tráfico saliente de la red virtual administrada por IR. En Data Factory, se abren todos los puertos para las comunicaciones salientes. Azure-SSIS IR se puede integrar con la red virtual para proporcionar controles de comunicaciones salientes.
Integration Runtime de Azure proporciona un proceso completamente administrado y sin servidor en Azure. No tiene que preocuparse del aprovisionamiento de la infraestructura, la instalación de software, la aplicación de revisiones ni el escalado de la capacidad. Además, solo se paga por la duración de la utilización real.
Integration Runtime de Azure proporciona el proceso nativo para mover datos entre almacenes de datos en la nube de forma segura, confiable y con alto rendimiento. Puede establecer cuántas unidades de integración de datos se van a utilizar en la actividad de copia, y el tamaño de cálculo de Azure IR se escala verticalmente de forma elástica en consecuencia, sin necesidad de ajustar explícitamente el tamaño del entorno de ejecución de integración de Azure.
La distribución de actividades es una operación ligera para enrutar la actividad al servicio de proceso de destino, por lo que no hay necesidad de escalar verticalmente el tamaño de proceso para este escenario.
Para obtener información sobre cómo crear y configurar una instancia de Azure IR, consulte Cómo crear y configurar una instancia de Azure Integration Runtime.
Nota
El entorno de ejecución de integración de Azure tiene propiedades relacionadas con el entorno de ejecución de Data Flow, que define la infraestructura de proceso subyacente que se usaría para ejecutar los flujos de datos.
Una instancia de Integration Runtime autohospedado es capaz de:
Nota
Use el entorno de ejecución de integración autohospedado para admitir almacenes de datos que requieran que uno aporte su propio controlador, como SAP Hana, MySQL, etc. Para más información, consulte los almacenes de datos admitidos.
Nota
Java Runtime Environment (JRE) es una dependencia del entorno de ejecución de integración autohospedado. Asegúrese de que tiene JRE instalado en el mismo host.
Si quiere realizar la integración de datos de forma segura en un entorno de red privada que no tenga una línea de visión directa desde el entorno de nube pública, puede instalar un entorno de ejecución de integración autohospedado en el entorno local detrás de un firewall o dentro de una red privada virtual. El entorno de ejecución de integración autohospedado solo realiza conexiones salientes basadas en HTTP a Internet.
Instale un entorno de ejecución de integración autohospedado en una máquina local o en una máquina virtual dentro de una red privada. Actualmente, el entorno de ejecución de integración autohospedado solo se admite en sistemas operativos Windows.
Para una alta disponibilidad y escalabilidad, puede escalar horizontalmente IR autohospedado mediante la asociación de la instancia lógica con varias máquinas locales en modo activo-activo. Para más información, consulte el artículo sobre cómo crear y configurar un entorno de ejecución de integración autohospedado.
Para levantar y mover la carga de trabajo de SSIS existente, puede crear una instancia de Integration Runtime de SSIS de Azure para ejecutar paquetes SSIS de forma nativa.
Azure-SSIS IR se puede aprovisionar en una red pública o en una red privada. El acceso a datos locales se admite mediante la unión de Azure-SSIS IR a una red virtual que está conectada a la red local.
Azure-SSIS IR es un clúster totalmente administrado de máquinas virtuales de Azure dedicado a ejecutar los paquetes SSIS. Puede traer su propia instancia de Azure SQL Database o Instancia administrada de SQL para el catálogo de proyectos y paquetes de SSIS (SSISDB). Puede escalar verticalmente la eficacia de los procesos especificando el tamaño de nodo y escalar horizontalmente especificando el número de nodos del clúster. Para administrar el costo de ejecutar su instancia de Azure-SSIS Integration Runtime, deténgala e iníciela según sus requisitos.
Para más información, consulte Crear y configurar una instancia de Azure SSIS IR. Una vez creada, puede implementar y administrar los paquetes de SSIS existentes con poco o ningún cambio utilizando herramientas conocidas, como SQL Server Data Tools (SSDT) y SQL Server Management Studio (SSMS), de manera similar a usar SSIS de forma local.
Para más información sobre el entorno de ejecución de Azure SSIS, consulte los artículos siguientes:
Al crear una instancia de Data Factory o un área de trabajo de Synapse, debe especificar su ubicación. Los metadatos de la instancia se almacenan aquí y el desencadenador de la canalización se inicia desde aquí. Los metadatos solo se almacenan en la región elegida y no en otras regiones.
Mientras tanto, una canalización puede acceder a almacenes de datos y servicios de proceso de otras regiones de Azure para mover datos entre almacenes de datos o procesar datos mediante servicios de proceso. Este comportamiento se lleva a cabo a través de la instancia de Integration Runtime disponible globalmente para garantizar el cumplimiento de los datos, la eficacia y los menores costes de salida de la red.
La ubicación del entorno de ejecución de integración define la ubicación de su proceso de back-end y dónde se realizan el movimiento de datos, la distribución de actividades y la ejecución de los paquetes de SSIS. La ubicación de la instancia de Integration Runtime puede ser diferente de la ubicación de la factoría de datos a la que pertenece.
Puede establecer la región de ubicación de un entorno de ejecución de integración de Azure, en cuyo caso la ejecución o distribución de la actividad se realizará en la región seleccionada.
El valor predeterminado es resolver automáticamente Azure IR en la red pública. Con esta opción:
En el caso de la actividad de copia, se hace todo lo posible para detectar automáticamente la ubicación del almacén de datos receptor y, luego, se usa el entorno de ejecución de integración de la misma región, si está disponible, o, en caso contrario, de la más cercana de la misma ubicación geográfica. Si la región del almacén de datos receptor no se puede detectar, se usaría entonces el entorno de ejecución de integración de la región de la instancia.
Por ejemplo, se ha creado un área de trabajo de Data Factory o Synapse en la región Este de EE. UU.,
Sugerencia
Si tiene requisitos estrictos de cumplimiento de datos y necesita asegurarse de que los datos no salen de una determinada geografía, puede crear explícitamente una instancia de Azure IR en una región determinada y apuntar el servicio vinculado a esta instancia de IR mediante la propiedad ConnectVia. Por ejemplo, si quiere copiar datos de un blob del Sur de Reino Unido a un área de trabajo de Azure Synapse de esta misma región y quiere asegurarse de que los datos no salen del Reino Unido, cree una instancia de Azure IR en el Sur de Reino Unido y vincule ambos servicios vinculados a este entorno de ejecución de integración.
Para la ejecución de la actividad Lookup/GetMetadata/Delete (actividades de canalización), la distribución de actividades de transformación (actividades externas) y las operaciones de creación (conexión de prueba, lista de carpetas de exploración y lista de tablas, y datos de versión preliminar), se usa el entorno de ejecución de integración de la misma región que el área de trabajo de Data Factory o Synapse.
En el caso de Data Flow, se usa el entorno de ejecución de integración de la región del área de trabajo de Data Factory o de Synapse.
Sugerencia
Un procedimiento recomendado es asegurarse de que los flujos de datos se ejecuten en la misma región que los almacenes de datos correspondientes cuando sea posible. Para ello, puede usar la resolución automática de Azure IR (si la ubicación del almacén de datos es la misma que la ubicación del área de trabajo de Data Factory o Synapse) o mediante la creación de una instancia de Azure IR en la misma región que los almacenes de datos y, luego, la ejecución de los flujos de datos en ella.
Si habilita la red virtual administrada con resolución automática para Azure IR, se usa el entorno de ejecución de integración de la región de Data Factory o del área de trabajo de Synapse.
Puede supervisar qué ubicación de IR tiene efecto durante la ejecución de la actividad en la vista de supervisión de la actividad de canalización en Data Factory Studio o Synapse Studio, o en la carga de supervisión de actividad.
El IR autohospedado se registra lógicamente en el área de trabajo de Data Factory o de Synapse, y el usuario proporciona el proceso que se usa para admitir sus funcionalidades. Por lo tanto, no hay ninguna propiedad de ubicación explícita para la instancia de Integration Runtime autohospedado.
Cuando se utiliza para realizar el movimiento de datos, IR autohospedado extrae datos del origen y los escribe en el destino.
Nota
Los entornos de ejecución de integración de SSIS de Azure no se admiten actualmente en las canalizaciones de Synapse.
Al seleccionar la ubicación adecuada para Integration Runtime de SSIS de Azure, es esencial lograr un alto rendimiento en los flujos de trabajo de extracción, transformación y carga (ETL).
En el diagrama siguiente se muestra la configuración de ubicación de Data Factory y sus entornos de ejecución de integración:
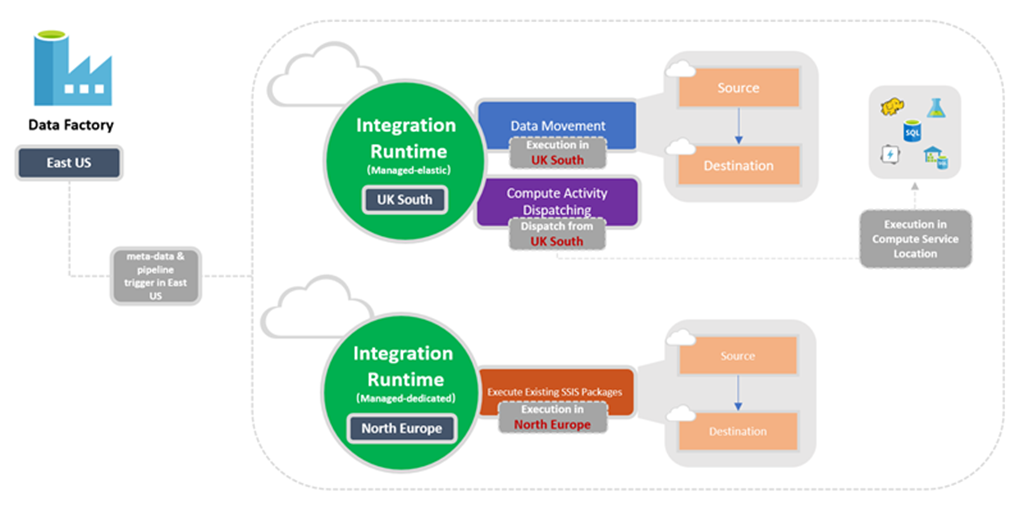
Si una actividad se asocia a más de un tipo de entorno de ejecución de integración, se resolverá en uno de ellos. El entorno de ejecución de integración autohospedado tiene prioridad sobre el entorno de ejecución de integración de Azure en las instancias de Azure Data Factory o del área de trabajo de Synapse que usan una red virtual administrada. Y este último tiene prioridad sobre el entorno de ejecución de integración global de Azure.
Por ejemplo, se usa una actividad de copia para copiar datos del origen al receptor. El entorno de ejecución de integración global de Azure está asociado al servicio vinculado en el caso del origen, y un entorno de ejecución de integración de Azure en una red virtual administrada de Azure Data Factory se asocia con el servicio vinculado para el receptor. El resultado es que los servicios vinculados de origen y receptor usan Azure Integration Runtime en la red virtual administrada por Azure Data Factory. Pero si un entorno de ejecución de integración autohospedado asocia el servicio vinculado para el origen, tanto el servicio vinculado de origen como el servicio vinculado receptor usan el entorno de ejecución de integración autohospedado.
La actividad de copia requiere servicios vinculados de origen y receptor para definir la dirección del flujo de datos. Se utiliza la lógica siguiente para determinar qué instancia de Integration Runtime se utiliza para realizar la copia:
La actividad Lookup y GetMetadata se ejecuta en el entorno de ejecución de integración asociado al servicio vinculado de almacén de datos.
Cada actividad de transformación externa que usa un motor de proceso externo tiene un servicio vinculado de proceso de destino, que señala a un entorno de ejecución de integración. Esta instancia de IR determina la ubicación desde la que se envía esa actividad de transformación externa codificada a mano.
Las actividades de Data Flow se ejecutan en su entorno de ejecución de integración de Azure asociado. El proceso de Spark utilizado por los flujos de datos viene determinado por las propiedades del flujo de datos en Azure IR y el servicio los administra por completo.
Los entornos de ejecución de integración no cambian a menudo y son similares en todas las fases de CI/CD. En Data Factory es necesario tener el mismo nombre y tipo de entorno de ejecución de integración en todas las fases de CI/CD. Si quiere compartir entornos de ejecución de integración en todas las fases, considere la posibilidad de usar una factoría dedicada solo para contener los entornos de ejecución de integración compartidos. A continuación, puede usar esta fábrica compartida en todos los entornos como un tipo de entorno de ejecución de integración vinculado.
Vea los artículos siguientes:
Eventos
Únase a nosotros en FabCon Vegas
31 mar, 11 p.m. - 2 abr, 11 p.m.
El evento definitivo dirigido por la comunidad de Microsoft Fabric, Power BI, SQL e IA. Del 31 de marzo al 2 de abril de 2025.
Regístrese hoy mismo