Inicio rápido: Creación de una factoría de datos y una canalización con SDK de .NET
SE APLICA A: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga información sobre cómo iniciar una nueva evaluación gratuita.
En este inicio rápido se describe cómo usar SDK de .NET para crear una instancia de Azure Data Factory. La canalización que ha creado en esta factoría de datos copia los datos de una carpeta a otra en Azure Blob Storage. Para ver un tutorial acerca de cómo transformar datos mediante Azure Data Factory, consulte Tutorial: Transformación de datos con Spark.
Nota
En este artículo no se ofrece una introducción detallada al servicio Data Factory. Para ver una introducción al servicio Azure Data Factory, consulte Introducción al servicio Azure Data Factory.
Requisitos previos
Suscripción de Azure
Si no tiene una suscripción a Azure, cree una cuenta gratuita antes de empezar.
Roles de Azure
Para crear instancias de Data Factory, la cuenta de usuario que use para iniciar sesión en Azure debe ser un miembro de los roles colaborador o propietario, o de administrador de la suscripción de Azure. Para ver los permisos que tiene en la suscripción, vaya a Azure Portal, seleccione su nombre de usuario en la esquina superior derecha, seleccione el icono " ... " para ver más opciones y, después, seleccione Mis permisos. Si tiene acceso a varias suscripciones, elija la correspondiente.
Para crear y administrar recursos secundarios para Data Factory incluidos los conjuntos de datos, servicios vinculados, canalizaciones, desencadenadores y entornos de ejecución de integración, se aplican los siguientes requisitos:
- Para crear y administrar recursos secundarios en Azure Portal, debe pertenecer al rol Colaborador de Data Factory en el nivel de grupo de recursos u otro nivel superior.
- Para crear y administrar recursos secundarios con Powershell o el SDK, el rol de Colaborador en el nivel de recurso u otro nivel superior es suficiente.
Para obtener instrucciones de ejemplo sobre cómo agregar un usuario a un rol, consulte el artículo sobre la adición de roles.
Para más información, consulte los siguientes artículos:
Cuenta de Azure Storage
En esta guía de inicio rápido, use una cuenta de Azure Storage (en concreto Blob Storage) de uso general como almacén de datos de origen y destino. Si no dispone de una cuenta de Azure Storage de uso general, consulte el artículo Creación de una cuenta de almacenamiento, donde se indica cómo crearla.
Obtención del nombre de la cuenta de almacenamiento
En este inicio rápido, necesita el nombre de su cuenta de Azure Storage. El siguiente procedimiento especifica los pasos necesarios para obtener el nombre de una cuenta de almacenamiento:
- En un explorador web, vaya a Azure Portal e inicie sesión con su nombre de usuario y contraseña de Azure.
- En el menú de Azure Portal, seleccione Todos los servicios y, a continuación, seleccione Almacenamiento>Cuentas de almacenamiento. También puede buscar y seleccionar cuentas de almacenamiento desde cualquier página.
- En la página Cuentas de Storage, filtre por su cuenta de almacenamiento (si fuera necesario) y, después, seleccione su cuenta de Storage.
También puede buscar y seleccionar cuentas de almacenamiento desde cualquier página.
Creación de un contenedor de blobs
En esta sección se crea un contenedor de blobs denominado adftutorial en la instancia de Azure Blob Storage.
En la página de la cuenta de almacenamiento, seleccione Información general>Contenedores.
En la barra de herramientas de la página <Nombre de cuenta> - Contenedores, seleccione Contenedor.
En el cuadro de diálogo Nuevo contenedor, escriba adftutorial para el nombre y seleccione Aceptar. La página <Nombre de cuenta> - Contenedores se actualiza para incluir adftutorial en la lista de contenedores.
Agregar una carpeta de entrada y un archivo para el contenedor de blobs
En esta sección, creará una carpeta denominada entrada en el contenedor que creó y cargará un archivo de ejemplo en dicha carpeta. Antes de empezar, abra un editor de texto, como el Bloc de notas, y cree un archivo denominado emp.txt con el siguiente contenido:
John, Doe
Jane, Doe
Guarde el archivo en la carpeta C:\ADFv2QuickStartPSH. (Si la carpeta no existe, créela). A continuación, vuelva a Azure Portal y siga estos pasos:
En la página <Nombre de cuenta> - Contenedores, en el punto donde se quedó, seleccione adftutorial en la lista actualizada de contenedores.
- Si ha cerrado la ventana o ha pasado a otra página; inicie sesión de nuevo en Azure Portal.
- En el menú de Azure Portal, seleccione Todos los servicios y, a continuación, seleccione Almacenamiento>Cuentas de almacenamiento. También puede buscar y seleccionar cuentas de almacenamiento desde cualquier página.
- Seleccione la cuenta de almacenamiento y, después, seleccione Contenedores>adftutorial.
En la barra de herramientas de la página del contenedor adftutorial, seleccione Cargar.
En la página Cargar blob, seleccione Archivos y, a continuación, busque y seleccione el archivo emp.txt.
Expanda el título Avanzado. La página aparece ahora como a continuación:
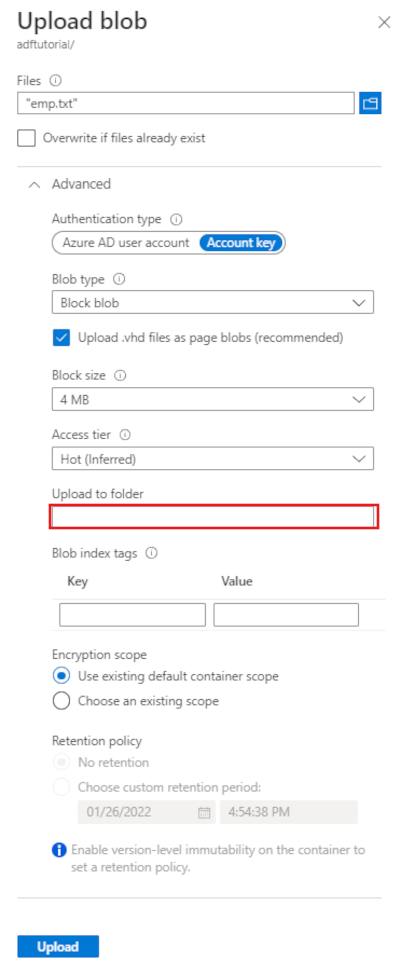
En el cuadro Cargar en carpeta, escriba input.
Seleccione el botón Cargar. Debería ver el archivo emp.txt y el estado de la carga en la lista.
Seleccione el icono Cerrar (X) para cerrar la página Cargar blob.
Mantenga abierta la página del contenedor adftutorial. Úsela para comprobar la salida al final de esta guía de inicio rápido.
Visual Studio
En el tutorial de este artículo se usa Visual Studio 2019. Los procedimientos para Visual Studio 2013, 2015 o 2017 son ligeramente diferentes.
Creación de aplicaciones en Microsoft Entra ID
En las secciones de Procedimiento: uso del portal para crear una aplicación de Azure AD y una entidad de servicio con acceso a los recursos, siga las instrucciones para realizar las siguientes tareas:
- En Crear una aplicación de Microsoft Entra, cree una aplicación que represente la aplicación .NET que va a crear en este tutorial. Para la dirección URL de inicio de sesión, puede proporcionar una dirección URL ficticia, tal como se muestra en el artículo (
https://contoso.org/exampleapp). - En Obtener valores para iniciar sesión, obtenga el identificador de aplicación y el identificador de inquilino y tome nota de estos valores que se usa más adelante en este tutorial.
- En Certificados y secretos, obtenga la clave de autenticación y tome nota de este valor que se usa más adelante en este tutorial.
- En Asignar la aplicación a un rol, asigne la aplicación al rol Colaborador en el nivel de suscripción para que la aplicación pueda crear factorías de datos en la suscripción.
Creación de un proyecto de Visual Studio
A continuación, cree una aplicación de consola .NET de C# en Visual Studio:
- Inicie Visual Studio.
- En la ventana Inicio, seleccione Crear un nuevo proyecto>Aplicación de consola (.NET Framework) . Se requiere .NET versión 4.5.2 o posterior.
- En Nombre del proyecto, escriba ADFv2QuickStart.
- Seleccione Crear para crear el proyecto.
Instalación de paquetes NuGet
Seleccione Herramientas>Administrador de paquetes NuGet>Consola del Administrador de paquetes.
En el panel Consola del Administrador de paquetes, ejecute los comandos siguientes para instalar los paquetes. Para más información, consulte el paquete NuGet Azure.ResourceManager.DataFactory.
Install-Package Azure.ResourceManager.DataFactory -IncludePrerelease Install-Package Azure.Identity
Crear una factoría de datos
Abra Program.cs e incluya las siguientes instrucciones para agregar referencias a espacios de nombres.
using Azure; using Azure.Core; using Azure.Core.Expressions.DataFactory; using Azure.Identity; using Azure.ResourceManager; using Azure.ResourceManager.DataFactory; using Azure.ResourceManager.DataFactory.Models; using Azure.ResourceManager.Resources; using System; using System.Collections.Generic;Agregue el siguiente código al método main que define las variables. Reemplace los marcadores de posición por sus propios valores. Para una lista de las regiones de Azure en las que Data Factory está disponible actualmente, seleccione las regiones que le interesen en la página siguiente y expanda Análisis para poder encontrar Data Factory: Productos disponibles por región. Los almacenes de datos (Azure Storage, Azure SQL Database, etc.) y los procesos (HDInsight, etc.) que usa la factoría de datos pueden encontrarse en otras regiones.
// Set variables string tenantID = "<your tenant ID>"; string applicationId = "<your application ID>"; string authenticationKey = "<your authentication key for the application>"; string subscriptionId = "<your subscription ID where the data factory resides>"; string resourceGroup = "<your resource group where the data factory resides>"; string region = "<the location of your resource group>"; string dataFactoryName = "<specify the name of data factory to create. It must be globally unique.>"; string storageAccountName = "<your storage account name to copy data>"; string storageKey = "<your storage account key>"; // specify the container and input folder from which all files // need to be copied to the output folder. string inputBlobContainer = "<blob container to copy data from, e.g. containername>"; string inputBlobPath = "<path to existing blob(s) to copy data from, e.g. inputdir/file>"; //specify the contains and output folder where the files are copied string outputBlobContainer = "<blob container to copy data from, e.g. containername>"; string outputBlobPath = "<the blob path to copy data to, e.g. outputdir/file>"; // name of the Azure Storage linked service, blob dataset, and the pipeline string storageLinkedServiceName = "AzureStorageLinkedService"; string blobDatasetName = "BlobDataset"; string pipelineName = "Adfv2QuickStartPipeline";Agregue el código siguiente al método main que crea una factoría de datos.
ArmClient armClient = new ArmClient( new ClientSecretCredential(tenantID, applicationId, authenticationKey, new TokenCredentialOptions { AuthorityHost = AzureAuthorityHosts.AzurePublicCloud }), subscriptionId, new ArmClientOptions { Environment = ArmEnvironment.AzurePublicCloud } ); ResourceIdentifier resourceIdentifier = SubscriptionResource.CreateResourceIdentifier(subscriptionId); SubscriptionResource subscriptionResource = armClient.GetSubscriptionResource(resourceIdentifier); Console.WriteLine("Get an existing resource group " + resourceGroupName + "..."); var resourceGroupOperation = subscriptionResource.GetResourceGroups().Get(resourceGroupName); ResourceGroupResource resourceGroupResource = resourceGroupOperation.Value; Console.WriteLine("Create a data factory " + dataFactoryName + "..."); DataFactoryData dataFactoryData = new DataFactoryData(AzureLocation.EastUS2); var dataFactoryOperation = resourceGroupResource.GetDataFactories().CreateOrUpdate(WaitUntil.Completed, dataFactoryName, dataFactoryData); Console.WriteLine(dataFactoryOperation.WaitForCompletionResponse().Content); // Get the data factory resource DataFactoryResource dataFactoryResource = dataFactoryOperation.Value;
Creación de un servicio vinculado
Agregue el código siguiente al método main que crea un servicio vinculado de Azure Storage.
Los servicios vinculados se crean en una factoría de datos para vincular los almacenes de datos y los servicios de proceso con la factoría de datos. En este inicio rápido, solo debe crear un servicio vinculado de Azure Storage para el origen de copia y el almacén de destino. En el ejemplo, se llama "AzureStorageLinkedService".
// Create an Azure Storage linked service
Console.WriteLine("Create a linked service " + storageLinkedServiceName + "...");
AzureBlobStorageLinkedService azureBlobStorage = new AzureBlobStorageLinkedService()
{
ConnectionString = azureBlobStorageConnectionString
};
DataFactoryLinkedServiceData linkedServiceData = new DataFactoryLinkedServiceData(azureBlobStorage);
var linkedServiceOperation = dataFactoryResource.GetDataFactoryLinkedServices().CreateOrUpdate(WaitUntil.Completed, storageLinkedServiceName, linkedServiceData);
Console.WriteLine(linkedServiceOperation.WaitForCompletionResponse().Content);
Crear un conjunto de datos
Agregue el código siguiente al método Main que crea un conjunto de datos de texto delimitado.
Se define un conjunto de datos que representa los datos que se copian de un origen a un receptor. En este ejemplo, este conjunto de datos de texto delimitado hace referencia al servicio vinculado de Azure Storage que creó en el paso anterior. El conjunto de datos toma dos parámetros cuyo valor se establece en una actividad que consume el conjunto de datos. Los parámetros se usan para construir el "contenedor" y el valor de "folderPath" que apunta a donde residen o se almacenan los datos.
// Create an Azure Blob dataset
DataFactoryLinkedServiceReference linkedServiceReference = new DataFactoryLinkedServiceReference(DataFactoryLinkedServiceReferenceType.LinkedServiceReference, storageLinkedServiceName);
DelimitedTextDataset delimitedTextDataset = new DelimitedTextDataset(linkedServiceReference)
{
DataLocation = new AzureBlobStorageLocation
{
Container = DataFactoryElement<string>.FromExpression("@dataset().container"),
FileName = DataFactoryElement<string>.FromExpression("@dataset().path")
},
Parameters =
{
new KeyValuePair<string, EntityParameterSpecification>("container",new EntityParameterSpecification(EntityParameterType.String)),
new KeyValuePair<string, EntityParameterSpecification>("path",new EntityParameterSpecification(EntityParameterType.String))
},
FirstRowAsHeader = false,
QuoteChar = "\"",
EscapeChar = "\\",
ColumnDelimiter = ","
};
DataFactoryDatasetData datasetData = new DataFactoryDatasetData(delimitedTextDataset);
var datasetOperation = dataFactoryResource.GetDataFactoryDatasets().CreateOrUpdate(WaitUntil.Completed, blobDatasetName, datasetData);
Console.WriteLine(datasetOperation.WaitForCompletionResponse().Content);
Crear una canalización
Agregue el código siguiente al método main que crea una canalización con una actividad de copia.
En este ejemplo, esta canalización contiene una actividad y toma cuatro parámetros: el contenedor de blobs y la ruta de acceso de entrada, y el contenedor de blobs y la ruta de acceso de salida. Los valores para estos parámetros se establecen cuando se desencadena/ejecuta la canalización. La actividad de copia hace referencia al mismo conjunto de datos de blob creado en el paso anterior como entrada y salida. Cuando el conjunto de datos se usa como conjunto de datos de entrada, se especifican el contenedor y la ruta de acceso de entrada. Además, cuando el conjunto de datos se usa como conjunto de datos de salida, se especifican el contenedor y la ruta de acceso de salida.
// Create a pipeline with a copy activity
Console.WriteLine("Creating pipeline " + pipelineName + "...");
DataFactoryPipelineData pipelineData = new DataFactoryPipelineData()
{
Parameters =
{
new KeyValuePair<string, EntityParameterSpecification>("inputContainer",new EntityParameterSpecification(EntityParameterType.String)),
new KeyValuePair<string, EntityParameterSpecification>("inputPath",new EntityParameterSpecification(EntityParameterType.String)),
new KeyValuePair<string, EntityParameterSpecification>("outputContainer",new EntityParameterSpecification(EntityParameterType.String)),
new KeyValuePair<string, EntityParameterSpecification>("outputPath",new EntityParameterSpecification(EntityParameterType.String))
},
Activities =
{
new CopyActivity("CopyFromBlobToBlob",new DataFactoryBlobSource(),new DataFactoryBlobSink())
{
Inputs =
{
new DatasetReference(DatasetReferenceType.DatasetReference,blobDatasetName)
{
Parameters =
{
new KeyValuePair<string, BinaryData>("container", BinaryData.FromString("\"@pipeline().parameters.inputContainer\"")),
new KeyValuePair<string, BinaryData>("path", BinaryData.FromString("\"@pipeline().parameters.inputPath\""))
}
}
},
Outputs =
{
new DatasetReference(DatasetReferenceType.DatasetReference,blobDatasetName)
{
Parameters =
{
new KeyValuePair<string, BinaryData>("container", BinaryData.FromString("\"@pipeline().parameters.outputContainer\"")),
new KeyValuePair<string, BinaryData>("path", BinaryData.FromString("\"@pipeline().parameters.outputPath\""))
}
}
}
}
}
};
var pipelineOperation = dataFactoryResource.GetDataFactoryPipelines().CreateOrUpdate(WaitUntil.Completed, pipelineName, pipelineData);
Console.WriteLine(pipelineOperation.WaitForCompletionResponse().Content);
Creación de una ejecución de canalización
Agregue el código siguiente al método Main que desencadena una ejecución de canalización.
Este código también establece los valores de los parámetros inputContainer, inputPath, outputContainer y outputPath especificados en la canalización con los valores reales de las rutas de acceso de blob de origen y destino.
// Create a pipeline run
Console.WriteLine("Creating pipeline run...");
Dictionary<string, BinaryData> parameters = new Dictionary<string, BinaryData>()
{
{ "inputContainer",BinaryData.FromObjectAsJson(inputBlobContainer) },
{ "inputPath",BinaryData.FromObjectAsJson(inputBlobPath) },
{ "outputContainer",BinaryData.FromObjectAsJson(outputBlobContainer) },
{ "outputPath",BinaryData.FromObjectAsJson(outputBlobPath) }
};
var pipelineResource = dataFactoryResource.GetDataFactoryPipeline(pipelineName);
var runResponse = pipelineResource.Value.CreateRun(parameters);
Console.WriteLine("Pipeline run ID: " + runResponse.Value.RunId);
Supervisar una ejecución de canalización
Agregue el código siguiente al método Main para comprobar continuamente el estado hasta que termine de copiar los datos.
// Monitor the pipeline run Console.WriteLine("Checking pipeline run status..."); DataFactoryPipelineRunInfo pipelineRun; while (true) { pipelineRun = dataFactoryResource.GetPipelineRun(runResponse.Value.RunId.ToString()); Console.WriteLine("Status: " + pipelineRun.Status); if (pipelineRun.Status == "InProgress" || pipelineRun.Status == "Queued") System.Threading.Thread.Sleep(15000); else break; }Agregue el código siguiente al método Main que recupera detalles de la ejecución de actividad de copia, como el tamaño de los datos que se leen o escriben.
// Check the copy activity run details Console.WriteLine("Checking copy activity run details..."); var queryResponse = dataFactoryResource.GetActivityRun(pipelineRun.RunId.ToString(), new RunFilterContent(DateTime.UtcNow.AddMinutes(-10), DateTime.UtcNow.AddMinutes(10))); var enumerator = queryResponse.GetEnumerator(); enumerator.MoveNext(); if (pipelineRun.Status == "Succeeded") Console.WriteLine(enumerator.Current.Output); else Console.WriteLine(enumerator.Current.Error); Console.WriteLine("\nPress any key to exit..."); Console.ReadKey();
Ejecución del código
Compile e inicie la aplicación y, a continuación, compruebe la ejecución de la canalización.
La consola imprime el progreso de la creación de la factoría de datos, el servicio vinculado, los conjuntos de datos, la canalización y la ejecución de canalización. A continuación, comprueba el estado de la ejecución de canalización. Espere hasta que vea los detalles de ejecución de actividad de copia con el tamaño de los datos leídos o escritos. Luego, use herramientas como el Explorador de Azure Storage para comprobar que los blobs se copian a "outputBlobPath" desde "inputBlobPath", como especificó en las variables.
Salida de ejemplo
Create a data factory quickstart-adf...
{
"name": "quickstart-adf",
"type": "Microsoft.DataFactory/factories",
"properties": {
"provisioningState": "Succeeded",
"version": "2018-06-01"
},
"location": "eastus2"
}
Create a linked service AzureBlobStorage...
{
"name": "AzureBlobStorage",
"type": "Microsoft.DataFactory/factories/linkedservices",
"properties": {
"type": "AzureBlobStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<storageAccountName>;",
"encryptedCredential": "<encryptedCredential>"
}
}
}
Creating dataset BlobDelimitedDataset...
{
"name": "BlobDelimitedDataset",
"type": "Microsoft.DataFactory/factories/datasets",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"type": "LinkedServiceReference",
"referenceName": "AzureBlobStorage"
},
"parameters": {
"container": {
"type": "String"
},
"path": {
"type": "String"
}
},
"typeProperties": {
"location": {
"container": {
"type": "Expression",
"value": "@dataset().container"
},
"type": "AzureBlobStorageLocation",
"fileName": {
"type": "Expression",
"value": "@dataset().path"
}
},
"columnDelimiter": ",",
"quoteChar": "\"",
"escapeChar": "\\",
"firstRowAsHeader": false
}
}
}
Creating pipeline Adfv2QuickStartPipeline...
{
"properties": {
"activities": [
{
"inputs": [
{
"type": "DatasetReference",
"referenceName": "BlobDelimitedDataset",
"parameters": {
"container": "@pipeline().parameters.inputContainer",
"path": "@pipeline().parameters.inputPath"
}
}
],
"outputs": [
{
"type": "DatasetReference",
"referenceName": "BlobDelimitedDataset",
"parameters": {
"container": "@pipeline().parameters.outputContainer",
"path": "@pipeline().parameters.outputPath"
}
}
],
"name": "CopyFromBlobToBlob",
"type": "Copy",
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "BlobSink"
}
}
}
],
"parameters": {
"inputContainer": {
"type": "String"
},
"inputPath": {
"type": "String"
},
"outputContainer": {
"type": "String"
},
"outputPath": {
"type": "String"
}
}
}
}
Creating pipeline run...
Pipeline run ID: 3aa26ffc-5bee-4db9-8bac-ccbc2d7b51c1
Checking pipeline run status...
Status: InProgress
Status: Succeeded
Checking copy activity run details...
{
"dataRead": 1048,
"dataWritten": 1048,
"filesRead": 1,
"filesWritten": 1,
"sourcePeakConnections": 1,
"sinkPeakConnections": 1,
"copyDuration": 8,
"throughput": 1.048,
"errors": [],
"effectiveIntegrationRuntime": "AutoResolveIntegrationRuntime (East US 2)",
"usedDataIntegrationUnits": 4,
"billingReference": {
"activityType": "DataMovement",
"billableDuration": [
{
"meterType": "AzureIR",
"duration": 0.06666666666666667,
"unit": "DIUHours"
}
],
"totalBillableDuration": [
{
"meterType": "AzureIR",
"duration": 0.06666666666666667,
"unit": "DIUHours"
}
]
},
"usedParallelCopies": 1,
"executionDetails": [
{
"source": {
"type": "AzureBlobStorage"
},
"sink": {
"type": "AzureBlobStorage"
},
"status": "Succeeded",
"start": "2023-12-15T10:25:33.9991558Z",
"duration": 8,
"usedDataIntegrationUnits": 4,
"usedParallelCopies": 1,
"profile": {
"queue": {
"status": "Completed",
"duration": 5
},
"transfer": {
"status": "Completed",
"duration": 1,
"details": {
"listingSource": {
"type": "AzureBlobStorage",
"workingDuration": 0
},
"readingFromSource": {
"type": "AzureBlobStorage",
"workingDuration": 0
},
"writingToSink": {
"type": "AzureBlobStorage",
"workingDuration": 0
}
}
}
},
"detailedDurations": {
"queuingDuration": 5,
"transferDuration": 1
}
}
],
"dataConsistencyVerification": {
"VerificationResult": "NotVerified"
}
}
Press any key to exit...
Comprobación del resultado
La canalización crea automáticamente la carpeta de salida en el contenedor de blobs adftutorial. A continuación, copia el archivo emp.txt de la carpeta de entrada a la carpeta de salida.
- En Azure Portal, en la página del contenedor adftutorial que detuvo en la sección anterior Agregar una carpeta de entrada y un archivo para el contenedor de blobs, seleccione Actualizar para ver la carpeta de salida.
- En la lista de carpetas, haga clic en output.
- Confirme que emp.txt se ha copiado en la carpeta de salida.
Limpieza de recursos
Para eliminar la factoría de datos mediante programación, agregue las líneas de código siguientes al programa:
Console.WriteLine("Deleting the data factory");
dataFactoryResource.Delete(WaitUntil.Completed);
Pasos siguientes
La canalización de este ejemplo copia los datos de una ubicación a otra en una instancia de Azure Blob Storage. Consulte los tutoriales para obtener información acerca del uso de Data Factory en otros escenarios.