Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
SE APLICA A: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga información sobre cómo iniciar una nueva evaluación gratuita.
En este tutorial, usará Azure Portal para crear una canalización de Azure Data Factory. Esta canalización permite transformar datos mediante una actividad de Spark y un servicio vinculado de Azure HDInsight a petición.
En este tutorial, realizará los siguientes pasos:
- Creación de una factoría de datos.
- Creación de una canalización que use una actividad de Spark.
- Desencadenamiento de una ejecución de la canalización
- Supervisión de la ejecución de la canalización
Si no tiene una suscripción a Azure, cree una cuenta gratuita antes de empezar.
Requisitos previos
Nota:
Se recomienda usar el módulo Azure Az de PowerShell para interactuar con Azure. Para comenzar, consulte Instalación de Azure PowerShell. Para más información sobre cómo migrar al módulo Az de PowerShell, consulte Migración de Azure PowerShell de AzureRM a Az.
- Cuenta de Azure Storage. Debe crear un script de Python y un archivo de entrada y cargarlos en Azure Storage. La salida del programa Spark se almacena en esta cuenta de almacenamiento. El clúster de Spark a petición usa la misma cuenta de almacenamiento que el almacenamiento principal.
Nota:
HdInsight admite solo cuentas de almacenamiento de uso general con nivel estándar. Asegúrese de que la cuenta no sea una cuenta de almacenamiento solo Premium o de blobs.
- Azure PowerShell. Siga las instrucciones de Instalación y configuración de Azure PowerShell.
Carga del script de Python en la cuenta de Blob Storage
Cree un archivo de Python denominado WordCount_Spark.py con el siguiente contenido:
import sys from operator import add from pyspark.sql import SparkSession def main(): spark = SparkSession\ .builder\ .appName("PythonWordCount")\ .getOrCreate() lines = spark.read.text("wasbs://adftutorial@<storageaccountname>.blob.core.windows.net/spark/inputfiles/minecraftstory.txt").rdd.map(lambda r: r[0]) counts = lines.flatMap(lambda x: x.split(' ')) \ .map(lambda x: (x, 1)) \ .reduceByKey(add) counts.saveAsTextFile("wasbs://adftutorial@<storageaccountname>.blob.core.windows.net/spark/outputfiles/wordcount") spark.stop() if __name__ == "__main__": main()Reemplace <storageAccountName> por el nombre de la cuenta de Azure Storage. A continuación, guarde el archivo.
En Azure Blob Storage, cree un contenedor denominado adftutorial si no existe.
Cree una carpeta llamada spark.
Cree una subcarpeta denominada script en la carpeta spark.
Cargue el archivo WordCount_Spark.py a la subcarpeta script.
Carga del archivo de entrada
- Cree un archivo denominado minecraftstory.txt con algo de texto. El programa Spark contará el número de palabras de este texto.
- Cree una subcarpeta denominada inputfiles en la carpeta spark.
- Cargue el archivo minecraftstory.txt en la subcarpeta inputfiles.
Crear una factoría de datos
Siga los pasos del artículo Inicio rápido: Creación de una factoría de datos mediante Azure Portal para crear una factoría de datos si aún no tiene una con la que trabajar.
Crear servicios vinculados
En esta sección, deberá crear dos servicios vinculados:
- Un servicio vinculado a Azure Storage que vincule una cuenta de Azure Storage con la factoría de datos. Este almacenamiento lo usa el clúster HDInsight a petición. También contiene el script de Spark que se ejecutará.
- Un servicio vinculado de HDInsight a petición. Azure Data Factory permite crear automáticamente un clúster de HDInsight y ejecutar el programa de Spark. A continuación, elimina el clúster de HDInsight si el clúster está inactivo durante un tiempo configurado previamente.
Creación de un servicio vinculado de Azure Storage
En la página principal, cambie a la pestaña Administrar del panel de la izquierda.
Seleccione Connections (Conexiones) en la parte inferior de la ventana y seleccione + New (+ Nuevo).
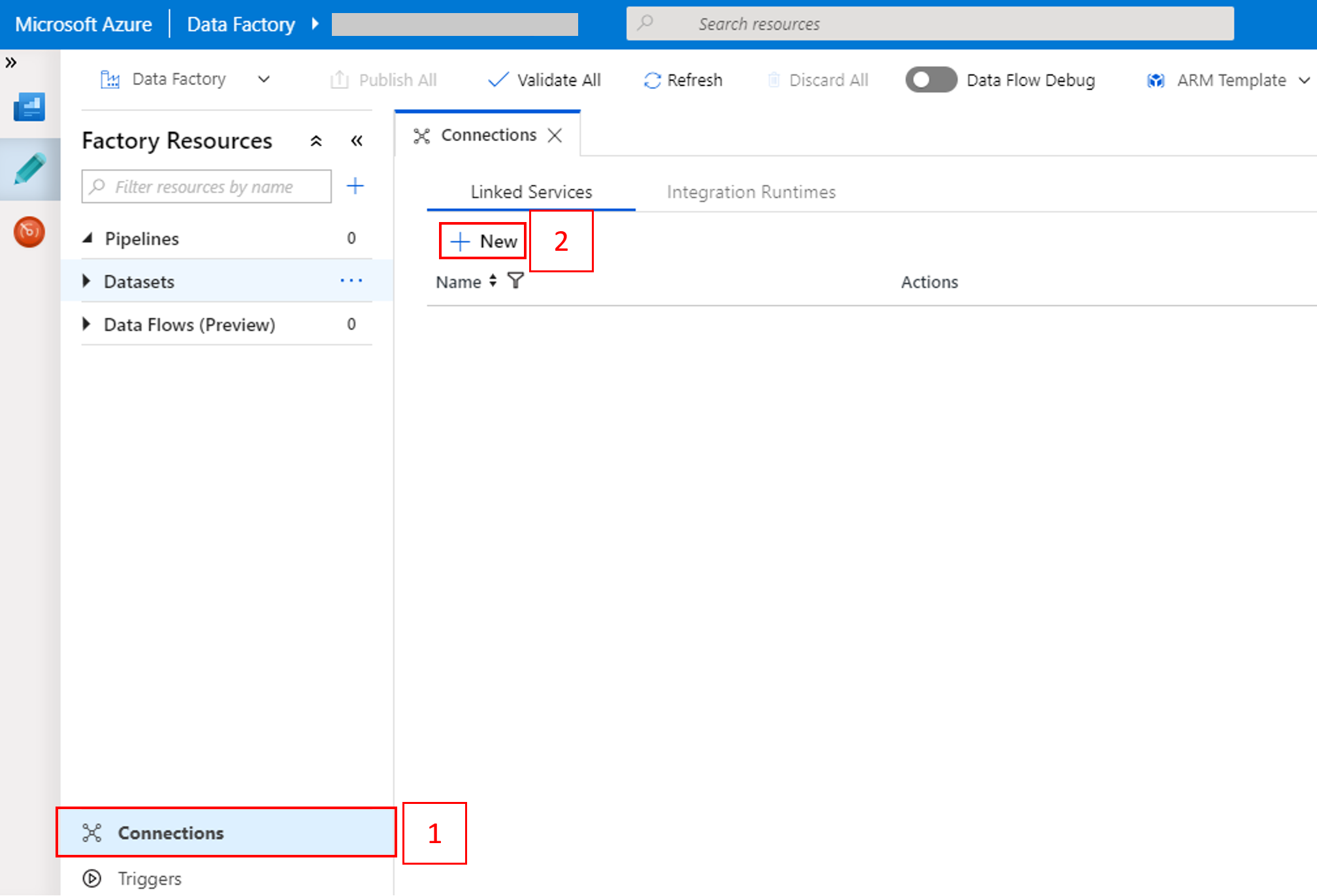
En la ventana New Linked Service (Nuevo servicio vinculado), seleccione Data Store>Azure Blob Storage y después Continue (Continuar).

En Storage account name (Nombre de la cuenta de almacenamiento), seleccione el nombre de la lista y, a continuación, seleccione Save (Guardar).
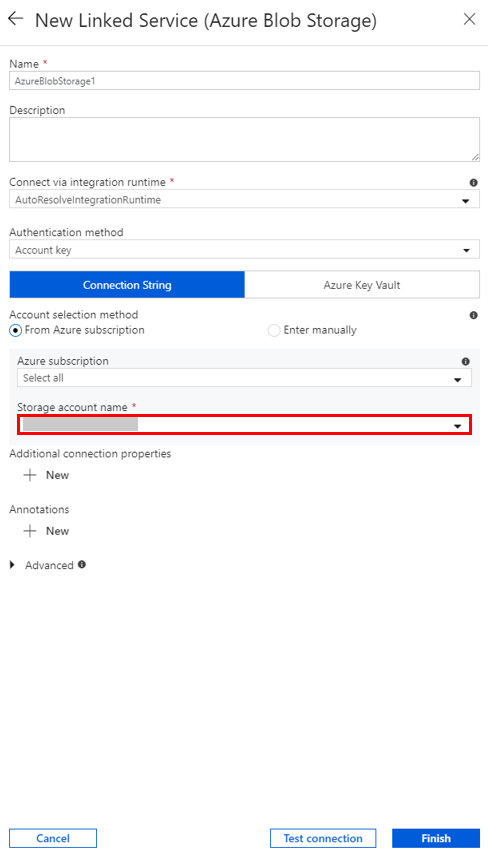
Creación de un servicio vinculado de HDInsight a petición
Seleccione el botón + New (+ Nuevo) una vez más para crear otro servicio vinculado.
En la ventana New Linked Service (Nuevo servicio vinculado), seleccione Compute>Azure HDInsight y seleccione Continue (Continuar).

En la ventana New Linked Service (Nuevo servicio vinculado), realice los pasos siguientes:
a. Escriba AzureHDInsightLinkedService como nombre.
b. Confirme que On-demand HDInsight (HDInsight a petición) está seleccionado en tipo.
c. Seleccione AzureBlobStorage1 como Servicio vinculado de Azure Storage. Este servicio vinculado lo creó anteriormente. Si usó un nombre diferente, especifique el nombre correcto aquí.
d. Seleccione spark como tipo de clúster.
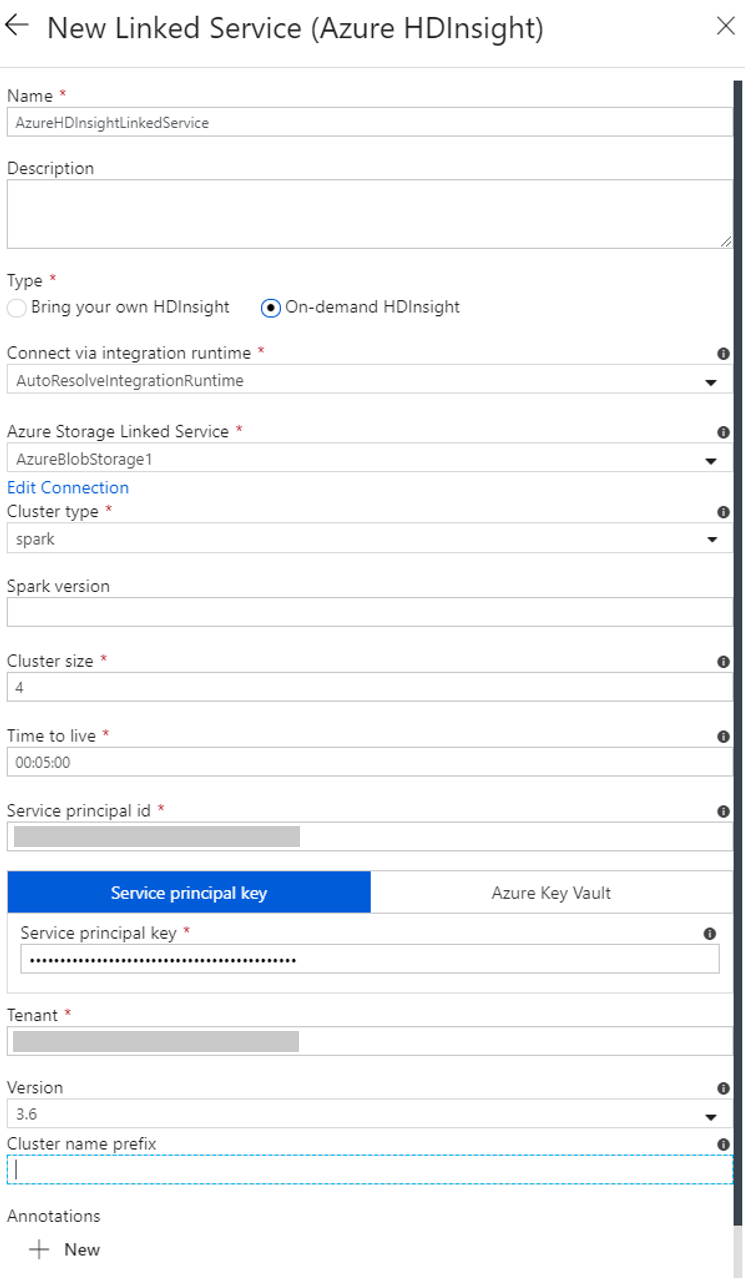
e. Escriba el identificador de la entidad de servicio que tenga permiso para crear un clúster de HDInsight.
Esta entidad de servicio debe ser miembro del rol de colaborador de la suscripción o del grupo de recursos en el que se crea el clúster. Para más información, consulte Creación de una aplicación de Microsoft Entra y una entidad de servicio con acceso a los recursos. El Id. de entidad de servicio es equivalente al Id. de aplicación y una Clave de entidad de servicio es equivalente al valor de un Secreto de cliente.
f. Escriba la clave de la entidad de servicio.
g. Seleccione el mismo grupo de recursos que utilizó al crear la factoría de datos en Grupo de recursos. El clúster de Spark se crea en este grupo de recursos.
h. Expanda OS type (Tipo de SO).
i. Escriba un nombre para Cluster user name (Nombre de usuario del clúster).
j. Escriba el valor de Cluster password (Contraseña del clúster) para el usuario.
k. Seleccione Finalizar.
Nota:
Azure HDInsight limita el número total de núcleos que se pueden utilizar en cada región de Azure que admite. Para el servicio vinculado de HDInsight a petición, el clúster de HDInsight se creará en la misma ubicación de Azure Storage que se usó como almacenamiento principal. Asegúrese de que dispone de suficientes cuotas de núcleo para que el clúster se cree correctamente. Para obtener más información, consulte Configuración de clústeres en HDInsight con Hadoop, Spark, Kafka, etc.
Crear una canalización
Seleccione el botón + (Más) y, después, seleccione Canalización en el menú.
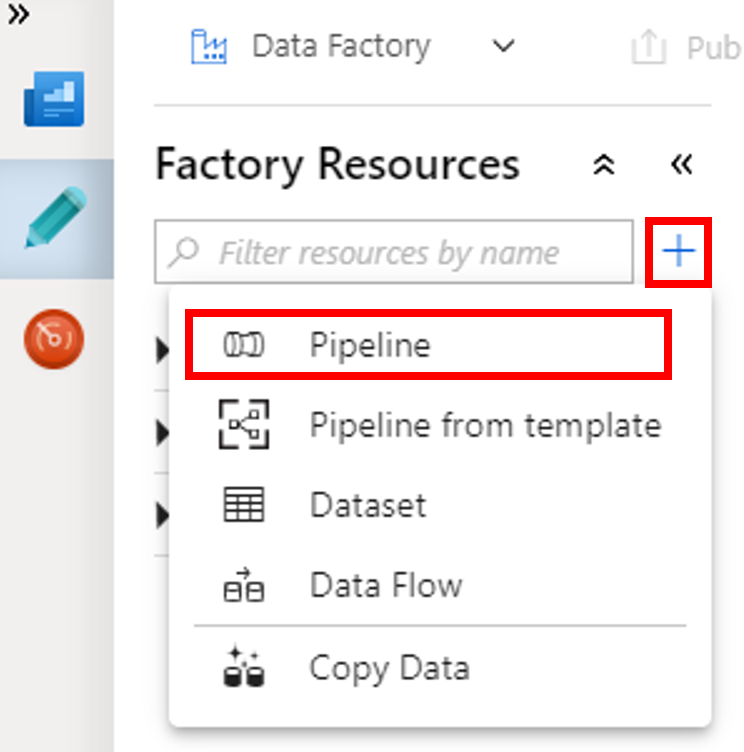
En el cuadro de herramientas Activities (Actividades), expanda HDInsight. Arrastre la actividad de Spark del cuadro de herramientas Activities (Actividades) a la superficie del diseñador de canalizaciones.
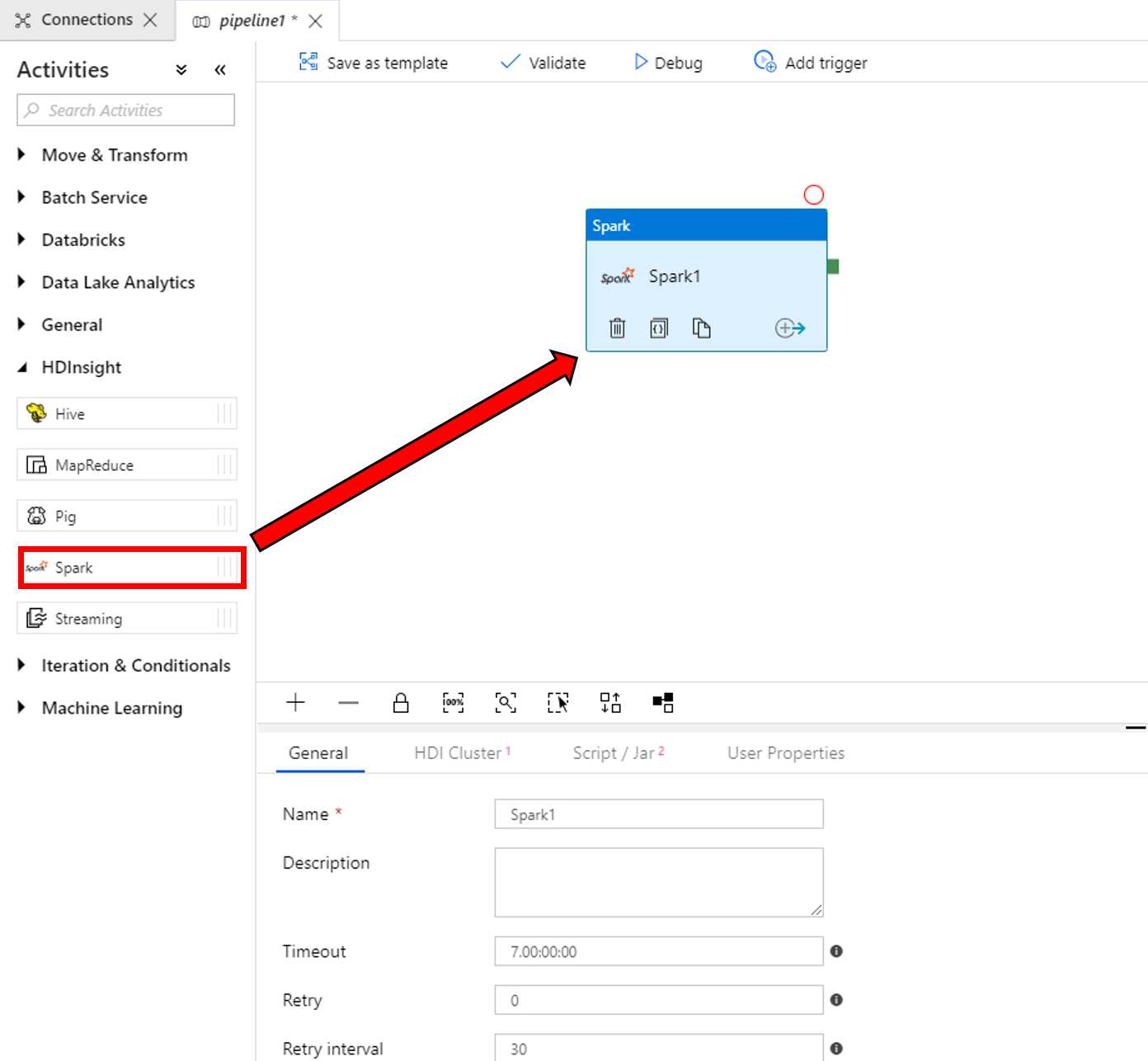
En las propiedades de la ventana de la actividad de Spark de la parte inferior, realice los pasos siguientes:
a. Vaya a la pestaña HDI Cluster (Clúster de HDI).
b. Seleccione el servicio AzureHDInsightLinkedService que creó en el procedimiento anterior.
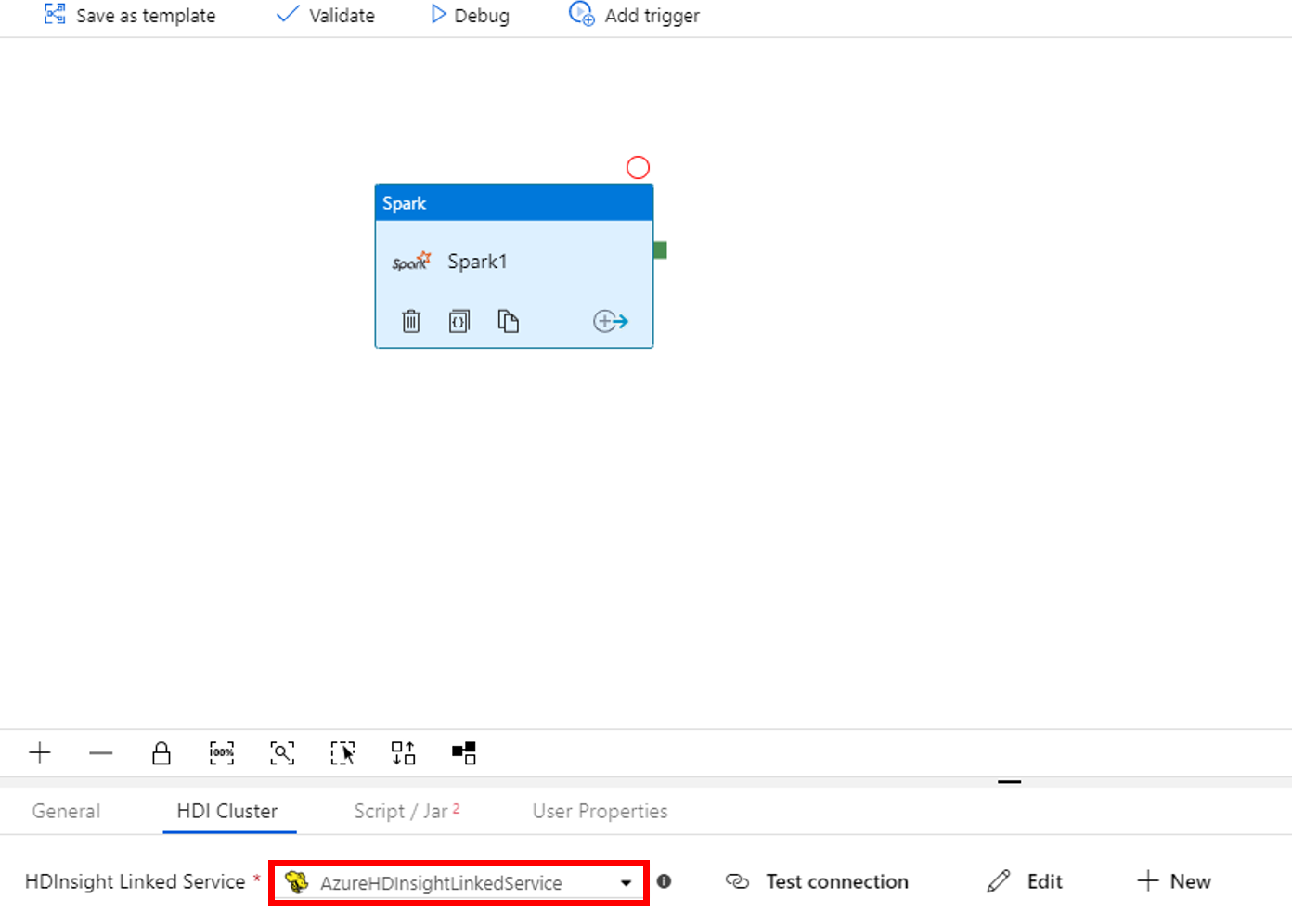
Cambie a la pestaña Script/Jar y complete los pasos siguientes:
a. Seleccione AzureBlobStorage1 como servicio vinculado de trabajo.
b. Seleccione Browse Storage (Examinar almacenamiento).

c. Vaya a la carpeta adftutorial/spark/script , seleccione WordCount_Spark.py y seleccione Finalizar.
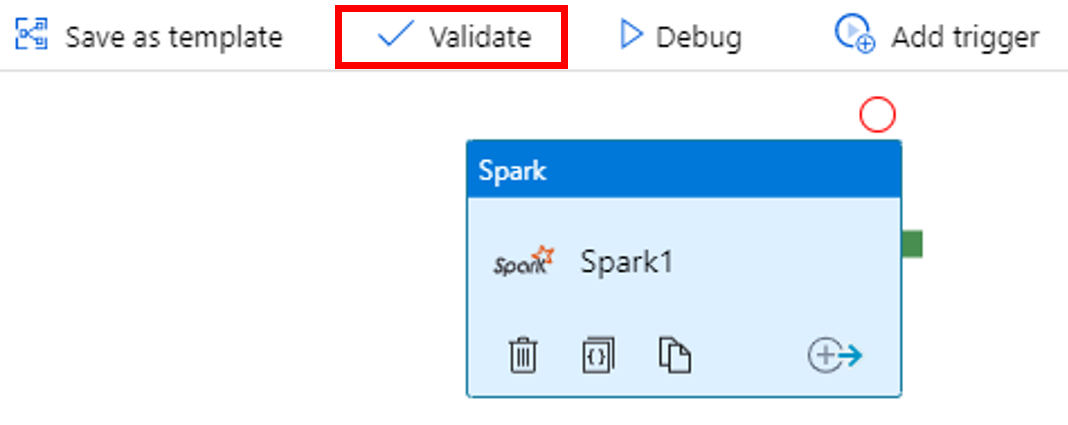
Para comprobar la canalización, seleccione el botón Validate (Comprobar) en la barra de herramientas. Seleccione el botón >> (flecha derecha) para cerrar la ventana de comprobación.
Seleccione Publish All (Publicar todo). La interfaz de usuario de Data Factory permite publicar entidades (servicios vinculados y canalizaciones) en el servicio Azure Data Factory.
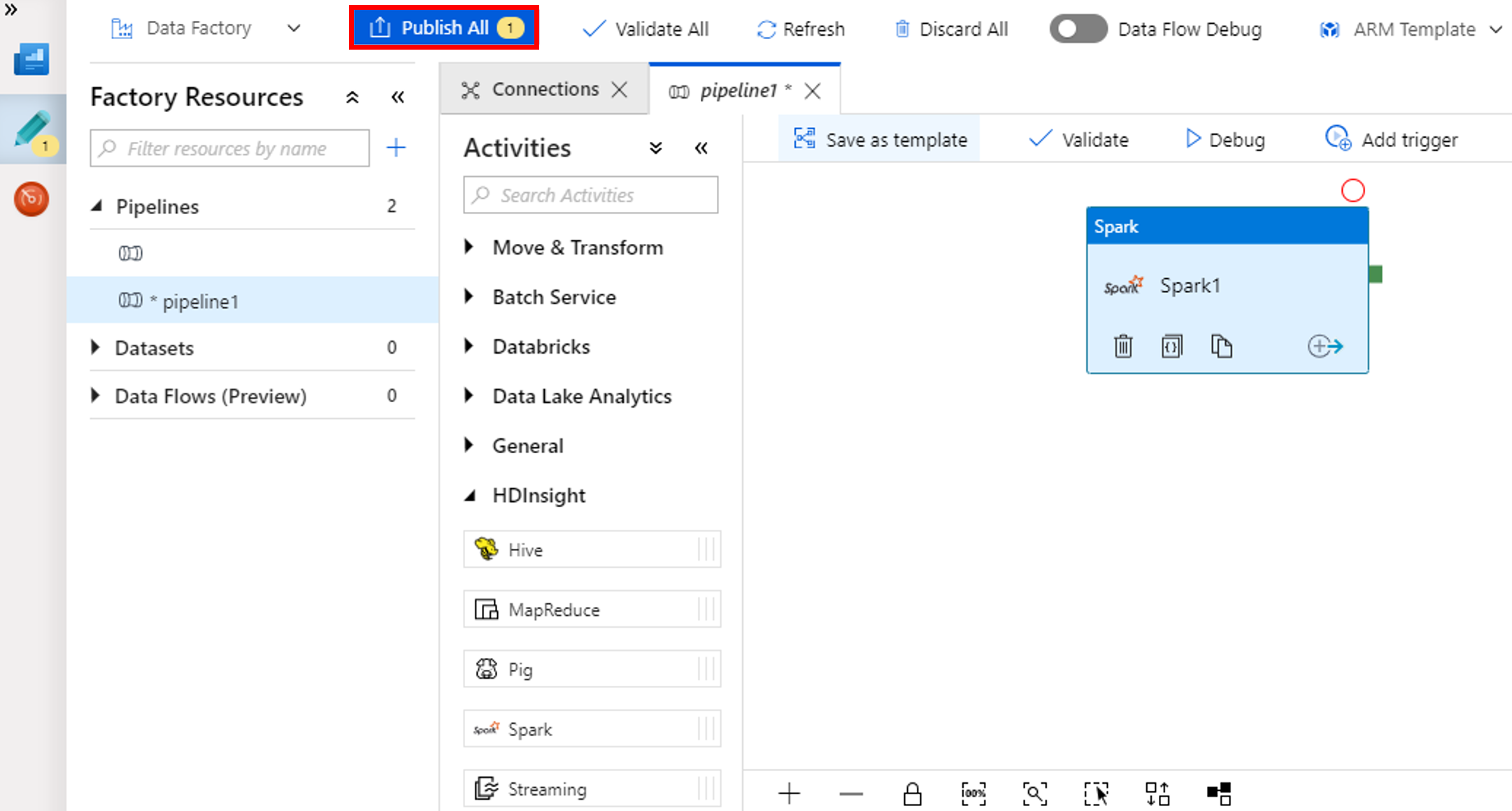
Desencadenamiento de una ejecución de la canalización
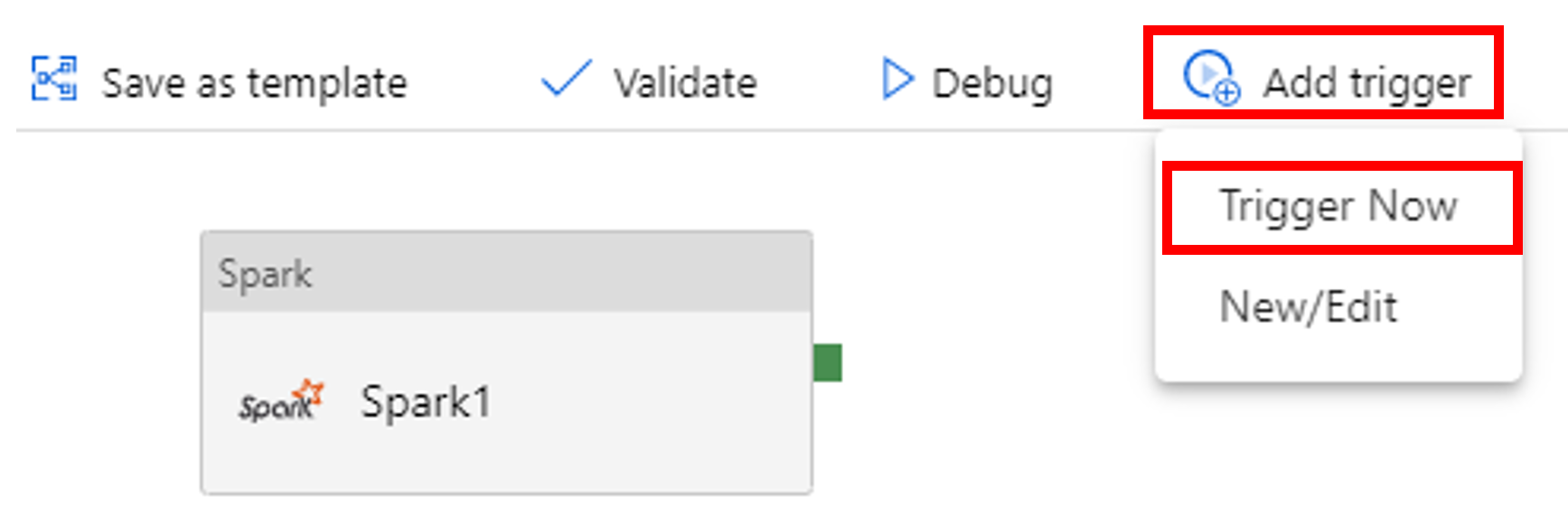
Seleccione Add Trigger (Agregar desencadenador) en la barra de herramientas y, después, seleccione Trigger Now (Desencadenar ahora).
Supervisión de la ejecución de la canalización
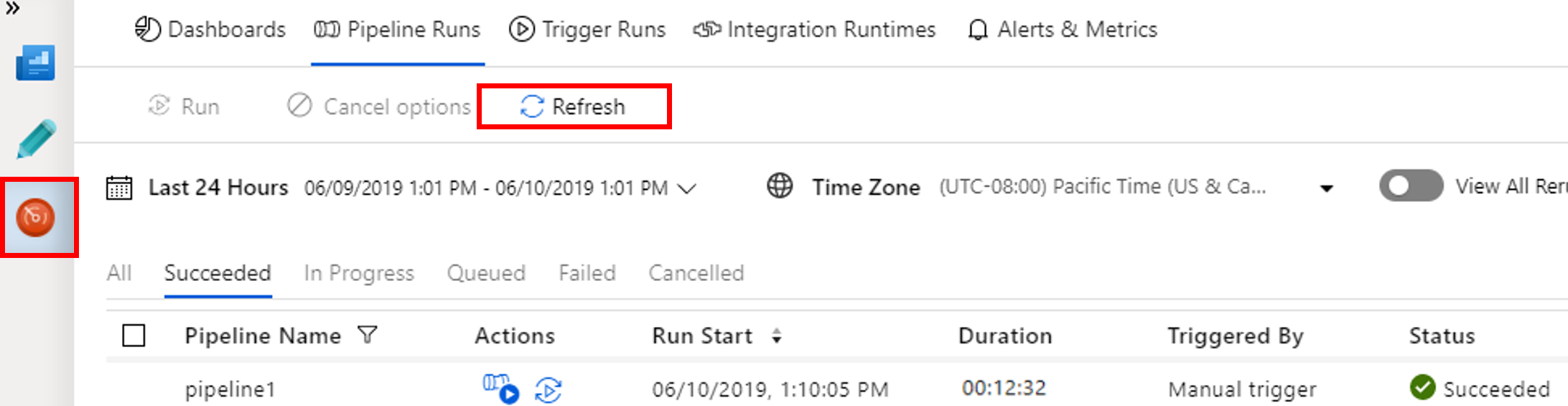
Vaya a la pestaña Monitor (Supervisar). Confirme que ve una ejecución de canalización. Se tardan veinte minutos aproximadamente en crear un clúster de Spark.
Seleccione Actualizar periódicamente para comprobar el estado de la ejecución de canalización.
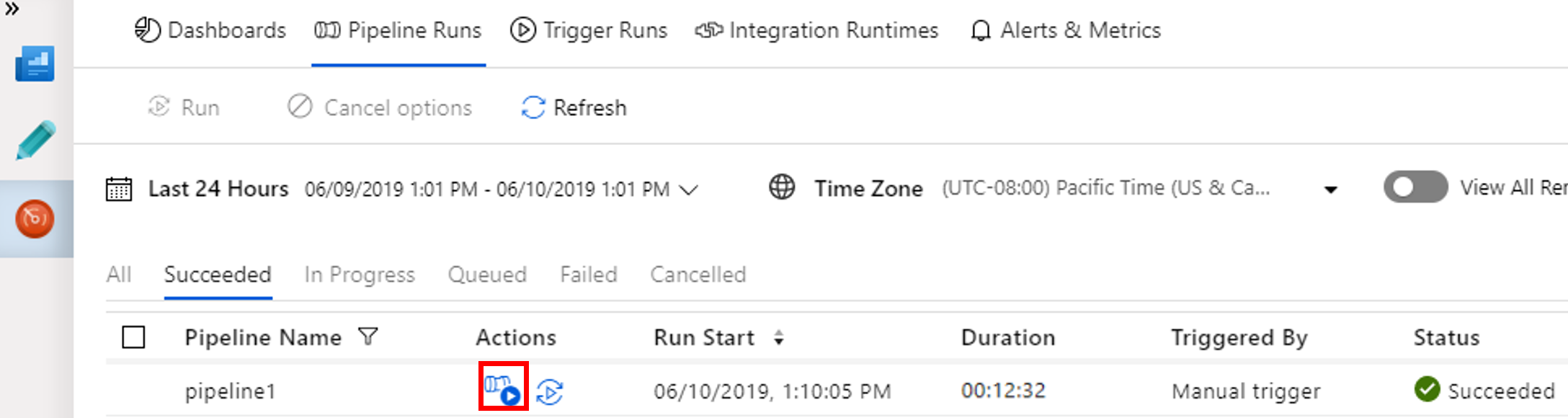
Para ver las ejecuciones de actividad asociadas con la ejecución de esta canalización, seleccione View Activity Runs (Ver ejecuciones de actividad) de la columna Actions (Acciones).
Puede volver a la vista de ejecuciones de canalización. Para ello seleccione el vínculo All Pipeline Runs (Todas las ejecuciones de canalizaciones) en la parte superior.
Comprobación del resultado
Compruebe que se crea el archivo de salida en la carpeta spark/otuputfiles/wordcount del contenedor adftutorial.
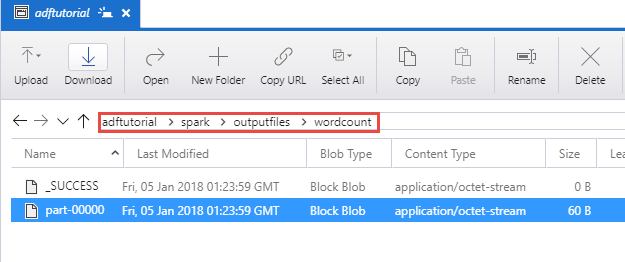
El archivo debe incluir todas las palabras del archivo de texto de entrada y el número de veces que cada palabra aparecía en el archivo. Por ejemplo:
(u'This', 1)
(u'a', 1)
(u'is', 1)
(u'test', 1)
(u'file', 1)
Contenido relacionado
La canalización de este ejemplo permite transformar datos mediante una actividad de Spark y un servicio vinculado de HDInsight a petición. Ha aprendido a:
- Creación de una factoría de datos.
- Creación de una canalización que use una actividad de Spark.
- Desencadenamiento de una ejecución de la canalización
- Supervisión de la ejecución de la canalización
Pase al siguiente tutorial para obtener información sobre cómo puede transformar datos mediante la ejecución del script de Hive en un clúster de Azure HDInsight que se encuentra en una red virtual: