Carga incremental de datos de Azure SQL Database a Azure Blob Storage mediante la información de control de cambios con PowerShell
SE APLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga información sobre cómo iniciar una nueva evaluación gratuita.
En este tutorial, creará una factoría de datos de Azure con una canalización que carga los datos diferenciales según la información de control de cambios de la base de datos de origen de Azure SQL Database a una instancia de Azure Blob Storage.
En este tutorial, realizará los siguientes pasos:
- Preparación del almacenamiento de datos de origen
- Creación de una factoría de datos.
- Cree servicios vinculados.
- Cree los conjuntos de datos de control de cambios, el origen y el receptor.
- Creación, ejecución y supervisión de la canalización de copia completa
- Adición o actualización de datos en la tabla de origen
- Creación, ejecución y supervisión de la canalización de copia incremental
Nota:
Se recomienda usar el módulo Azure Az de PowerShell para interactuar con Azure. Para comenzar, consulte Instalación de Azure PowerShell. Para más información sobre cómo migrar al módulo Az de PowerShell, consulte Migración de Azure PowerShell de AzureRM a Az.
Información general
En una solución de integración de datos, la carga incremental de los datos después de cargas completas iniciales es un método ampliamente usado. En algunos casos, los datos modificados en un período en el almacén de datos de origen pueden ser fácilmente segmentados (por ejemplo, LastModifyTime o CreationTime). En algunos casos, no hay ninguna manera explícita de identificar las diferencias de datos desde la última vez que se procesaron. Para identificar los datos diferenciales, puede usarse la tecnología de control de cambios, admitida por almacenes de datos como Azure SQL Database y SQL Server. Este tutorial describe cómo usar Azure Data Factory con la tecnología de control de cambios de SQL Server para cargar incrementalmente los datos diferenciales desde Azure SQL Database a Azure Blob Storage. Para obtener información más concreta sobre la tecnología de control de cambios de SQL, consulte Acerca del control de cambios (SQL Server).
Flujo de trabajo de un extremo a otro
Estos son los pasos del flujo de trabajo completo típico para cargar incrementalmente los datos mediante la tecnología de control de cambios.
Nota
Tanto Azure SQL Database como SQL Server admiten la tecnología de control de cambios. Este tutorial utiliza Azure SQL Database como almacén de datos de origen. También puede usar una instancia de SQL Server.
- Carga inicial de datos históricos (ejecutar una vez):
- Habilite la tecnología Change Tracking en la base de datos de origen de Azure SQL Database.
- Obtenga el valor inicial de SYS_CHANGE_VERSION en la base de datos como base de referencia para capturar los datos que han cambiado.
- Cargue todos los datos de la base de datos de origen en una instancia de Azure Blob Storage.
- Carga incremental de los datos diferenciales según una programación (ejecutar periódicamente después de la carga inicial de datos):
- Obtenga los valores SYS_CHANGE_VERSION antiguos y nuevos.
- Cargue los datos diferenciales combinando las claves principales de las filas modificadas (entre dos valores SYS_CHANGE_VERSION) desde sys.change_tracking_tables con los datos de la tabla de origen y, a continuación, muévalos al destino.
- Actualice el valor SYS_CHANGE_VERSION para la carga diferencial la próxima vez.
Solución de alto nivel
En este tutorial, creará dos canalizaciones que llevan a cabo las dos operaciones siguientes:
Carga inicial: creará una canalización con la actividad de copia que copia todos los datos desde el almacén de datos de origen (Azure SQL Database) al almacén de datos de destino (Azure Blob Storage).

Carga incremental: creará una canalización con las siguientes actividades y la ejecutará con regularidad.
- Cree dos actividades de búsqueda para obtener los valores SYS_CHANGE_VERSION antiguo y nuevo desde Azure SQL Database y pasarlos a la actividad de copia.
- Cree una actividad de copia para copiar los datos insertados, actualizados o eliminados entre los dos valores SYS_CHANGE_VERSION de Azure SQL Database a Azure Blob Storage.
- Cree una actividad de procedimiento almacenado para actualizar el valor SYS_CHANGE_VERSION para la ejecución de la siguiente canalización.

Si no tiene una suscripción a Azure, cree una cuenta gratuita antes de empezar.
Requisitos previos
- Azure PowerShell. Instale los módulos de Azure PowerShell siguiendo las instrucciones de Cómo instalar y configurar Azure PowerShell.
- Azure SQL Database. La base de datos se usa como almacén de datos de origen. Si no tiene ninguna base de datos en Azure SQL Database, consulte el artículo Creación de una base de datos en Azure SQL Database para ver los pasos y crear una.
- Cuenta de Azure Storage. Blob Storage se usa como almacén de datos receptor. Si no tiene una cuenta de almacenamiento de Azure, consulte el artículo Crear una cuenta de almacenamiento para ver los pasos para su creación. Cree un contenedor denominado adftutorial.
Creación de una tabla de origen de datos en la base de datos
Abra SQL Server Management Studio y conéctese a SQL Database.
En el Explorador de servidores, haga clic con el botón derecho en la base de datos y elija la Nueva consulta.
Ejecute el siguiente comando SQL en su base de datos para crear una tabla denominada
data_source_tablecomo almacén de origen de datos.create table data_source_table ( PersonID int NOT NULL, Name varchar(255), Age int PRIMARY KEY (PersonID) ); INSERT INTO data_source_table (PersonID, Name, Age) VALUES (1, 'aaaa', 21), (2, 'bbbb', 24), (3, 'cccc', 20), (4, 'dddd', 26), (5, 'eeee', 22);Habilite el mecanismo de control de cambios en la base de datos y la tabla de origen (data_source_table) ejecutando la siguiente consulta SQL:
Nota
- Reemplace <el nombre de la base de datos> por el nombre de la base de datos que tiene la tabla data_source_table.
- Los datos modificados se mantienen durante dos días en el ejemplo actual. Si carga los datos cambiados para cada tres días o más, no se incluyen algunos que han cambiado. Tiene que cambiar el valor de CHANGE_RETENTION por un número mayor. También puede asegurarse de que el período para cargar los datos cambiados es dentro de dos días. Para más información, vea Habilitar el control de cambios para una base de datos
ALTER DATABASE <your database name> SET CHANGE_TRACKING = ON (CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON) ALTER TABLE data_source_table ENABLE CHANGE_TRACKING WITH (TRACK_COLUMNS_UPDATED = ON)Cree una tabla y almacene el valor predeterminado ChangeTracking_version ejecutando la consulta siguiente:
create table table_store_ChangeTracking_version ( TableName varchar(255), SYS_CHANGE_VERSION BIGINT, ); DECLARE @ChangeTracking_version BIGINT SET @ChangeTracking_version = CHANGE_TRACKING_CURRENT_VERSION(); INSERT INTO table_store_ChangeTracking_version VALUES ('data_source_table', @ChangeTracking_version)Nota
Si los datos no cambian después de haber habilitado el control de cambios para SQL Database, el valor de la versión de control de cambios es 0.
Ejecute la siguiente consulta para crear un procedimiento almacenado en su base de datos. La canalización invoca este procedimiento almacenado para actualizar la versión de control de cambios en la tabla que creó en el paso anterior.
CREATE PROCEDURE Update_ChangeTracking_Version @CurrentTrackingVersion BIGINT, @TableName varchar(50) AS BEGIN UPDATE table_store_ChangeTracking_version SET [SYS_CHANGE_VERSION] = @CurrentTrackingVersion WHERE [TableName] = @TableName END
Azure PowerShell
Instale los módulos de Azure PowerShell siguiendo las instrucciones de Cómo instalar y configurar Azure PowerShell.
Crear una factoría de datos
Defina una variable para el nombre del grupo de recursos que usa en los comandos de PowerShell más adelante. Copie el texto del comando siguiente en PowerShell, especifique el nombre del grupo de recursos de Azure entre comillas dobles y ejecute el comando. Por ejemplo:
"adfrg".$resourceGroupName = "ADFTutorialResourceGroup";Si el grupo de recursos ya existe, puede que no desee sobrescribirlo. Asigne otro valor a la variable
$resourceGroupNamey vuelva a ejecutar el comandoDefina una variable para la ubicación de la factoría de datos:
$location = "East US"Para crear el grupo de recursos de Azure, ejecute el comando siguiente:
New-AzResourceGroup $resourceGroupName $locationSi el grupo de recursos ya existe, puede que no desee sobrescribirlo. Asigne otro valor a la variable
$resourceGroupNamey ejecute el comando de nuevo.Defina una variable para el nombre de la factoría de datos.
Importante
Actualice el nombre de la factoría de datos para que sea globalmente único.
$dataFactoryName = "IncCopyChgTrackingDF";Para crear la factoría de datos, ejecute el siguiente cmdlet, Set-AzDataFactoryV2:
Set-AzDataFactoryV2 -ResourceGroupName $resourceGroupName -Location $location -Name $dataFactoryName
Tenga en cuenta los siguientes puntos:
El nombre de la instancia de Azure Data Factory debe ser único de forma global. Si recibe el siguiente error, cambie el nombre y vuelva a intentarlo.
The specified Data Factory name 'ADFIncCopyChangeTrackingTestFactory' is already in use. Data Factory names must be globally unique.Para crear instancias de Data Factory, la cuenta de usuario que use para iniciar sesión en Azure debe ser un miembro de los roles colaborador o propietario, o de administrador de la suscripción de Azure.
Para una lista de las regiones de Azure en las que Data Factory está disponible actualmente, seleccione las regiones que le interesen en la página siguiente y expanda Análisis para poder encontrar Data Factory: Productos disponibles por región. Los almacenes de datos (Azure Storage, Azure SQL Database, etc.) y los procesos (HDInsight, etc.) que usa la factoría de datos pueden encontrarse en otras regiones.
Crear servicios vinculados
Los servicios vinculados se crean en una factoría de datos para vincular los almacenes de datos y los servicios de proceso con la factoría de datos. En esta sección, creará servicios vinculados en su cuenta de Azure Storage y en la base de datos de Azure SQL Database.
Creación de un servicio vinculado de Azure Storage
En este paso, vincula su cuenta de Azure Storage a la factoría de datos.
Cree un archivo JSON llamado AzureStorageLinkedService.json en la carpeta C:\ADFTutorials\IncCopyChangeTrackingTutorial con el siguiente contenido: (cree la carpeta si aún no existe). Reemplace
<accountName>,<accountKey>por el nombre y la clave de su cuenta de Azure Storage antes de guardar el archivo.{ "name": "AzureStorageLinkedService", "properties": { "type": "AzureStorage", "typeProperties": { "connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountName>;AccountKey=<accountKey>" } } }En Azure PowerShell, cambie a la carpeta C:\ADFTutorials\IncCopyChangeTrackingTutorial.
Ejecute el cmdlet Set-AzDataFactoryV2LinkedService para crear el servicio vinculado: AzureStorageLinkedService. En el ejemplo siguiente, debe pasar los valores de los parámetros ResourceGroupName y DataFactoryName.
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "AzureStorageLinkedService" -File ".\AzureStorageLinkedService.json"Este es la salida de ejemplo:
LinkedServiceName : AzureStorageLinkedService ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Properties : Microsoft.Azure.Management.DataFactory.Models.AzureStorageLinkedService
Creación de un servicio vinculado de Azure SQL Database
En este paso, vinculará la base de datos a la factoría de datos.
Cree un archivo JSON denominado AzureSQLDatabaseLinkedService.json en la carpeta C:\ADFTutorials\IncCopyChangeTrackingTutorial con el siguiente contenido: Reemplace <your-server-name> y <your-database-name> por el nombre del servidor y la base de datos antes de guardar el archivo. También debe configurar su servidor de Azure SQL Server para conceder acceso a la identidad administrada de su factoría de datos.
{ "name": "AzureSqlDatabaseLinkedService", "properties": { "type": "AzureSqlDatabase", "typeProperties": { "connectionString": "Server=tcp:<your-server-name>.database.windows.net,1433;Database=<your-database-name>;" }, "authenticationType": "ManagedIdentity", "annotations": [] } }En Azure PowerShell, ejecute el cmdlet Set-AzDataFactoryV2LinkedService para crear el servicio vinculado: AzureSQLDatabaseLinkedService.
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "AzureSQLDatabaseLinkedService" -File ".\AzureSQLDatabaseLinkedService.json"Este es la salida de ejemplo:
LinkedServiceName : AzureSQLDatabaseLinkedService ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlDatabaseLinkedService
Creación de conjuntos de datos
En este paso, creará conjuntos de datos para representar el origen de datos, el destino de datos. y el lugar donde almacenar el valor SYS_CHANGE_VERSION.
Creación de un conjunto de datos de origen
En este paso, creará conjuntos de datos para representar el origen de datos.
Cree un archivo JSON llamado SourceDataset.json en la misma carpeta con el siguiente contenido:
{ "name": "SourceDataset", "properties": { "type": "AzureSqlTable", "typeProperties": { "tableName": "data_source_table" }, "linkedServiceName": { "referenceName": "AzureSQLDatabaseLinkedService", "type": "LinkedServiceReference" } } }Ejecute el cmdlet Set-AzDataFactoryV2Dataset para crear el conjunto de datos: SourceDataset
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SourceDataset" -File ".\SourceDataset.json"Esta es la salida de ejemplo del cmdlet:
DatasetName : SourceDataset ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlTableDataset
Creación de un conjunto de datos receptor
En este paso, creará un conjunto de datos para representar los datos que se copian desde el almacén de datos de origen.
Cree un archivo JSON llamado SinkDataset.json en la misma carpeta con el siguiente contenido:
{ "name": "SinkDataset", "properties": { "type": "AzureBlob", "typeProperties": { "folderPath": "adftutorial/incchgtracking", "fileName": "@CONCAT('Incremental-', pipeline().RunId, '.txt')", "format": { "type": "TextFormat" } }, "linkedServiceName": { "referenceName": "AzureStorageLinkedService", "type": "LinkedServiceReference" } } }Creará el contenedor de adftutorial en Azure Blob Storage como parte de los requisitos previos. Cree el contenedor si no existe (o) asígnele el nombre de uno existente. En este tutorial, el nombre del archivo de salida se genera dinámicamente con la expresión:@CONCAT('Incremental-', pipeline().RunId, '.txt').
Ejecute el cmdlet Set-AzDataFactoryV2Dataset para crear el conjunto de datos: SinkDataset
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SinkDataset" -File ".\SinkDataset.json"Esta es la salida de ejemplo del cmdlet:
DatasetName : SinkDataset ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.AzureBlobDataset
Creación de un conjunto de datos de control de cambios
En este paso, creará un conjunto de datos para almacenar la versión de control de cambios.
Cree un archivo JSON llamado ChangeTrackingDataset.json en la misma carpeta con el siguiente contenido:
{ "name": " ChangeTrackingDataset", "properties": { "type": "AzureSqlTable", "typeProperties": { "tableName": "table_store_ChangeTracking_version" }, "linkedServiceName": { "referenceName": "AzureSQLDatabaseLinkedService", "type": "LinkedServiceReference" } } }Crea la tabla table_store_ChangeTracking_version como parte de los requisitos previos.
Ejecute el cmdlet Set-AzDataFactoryV2Dataset para crear el conjunto de datos: ChangeTrackingDataset
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "ChangeTrackingDataset" -File ".\ChangeTrackingDataset.json"Esta es la salida de ejemplo del cmdlet:
DatasetName : ChangeTrackingDataset ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlTableDataset
Creación de una canalización para la copia completa
En este paso, va a crear una canalización con la actividad de copia que copia todos los datos desde el almacén de datos de origen (Azure SQL Database) al almacén de datos de destino (Azure Blob Storage).
Cree un archivo JSON llamado FullCopyPipeline.json en la misma carpeta con el siguiente contenido:
{ "name": "FullCopyPipeline", "properties": { "activities": [{ "name": "FullCopyActivity", "type": "Copy", "typeProperties": { "source": { "type": "SqlSource" }, "sink": { "type": "BlobSink" } }, "inputs": [{ "referenceName": "SourceDataset", "type": "DatasetReference" }], "outputs": [{ "referenceName": "SinkDataset", "type": "DatasetReference" }] }] } }Ejecute el cmdlet Set-AzDataFactoryV2Pipeline para crear la canalización: FullCopyPipeline.
Set-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "FullCopyPipeline" -File ".\FullCopyPipeline.json"Este es la salida de ejemplo:
PipelineName : FullCopyPipeline ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Activities : {FullCopyActivity} Parameters :
Ejecución de la canalización de copia completa
Ejecución de la canalización FullCopyPipeline mediante el cmdlet Invoke-AzDataFactoryV2Pipeline.
Invoke-AzDataFactoryV2Pipeline -PipelineName "FullCopyPipeline" -ResourceGroup $resourceGroupName -dataFactoryName $dataFactoryName
Supervisión de la canalización de copia completa
Inicie sesión en Azure Portal.
Haga clic en Todos los servicios, busque con la palabra clave
data factoriesy seleccione Factorías de datos.
Busque su factoría de datos en la lista y selecciónela para iniciar la página Factoría de datos.

En la página Factoría de datos, haga clic en el icono Supervisión y administración.

La aplicación de integración de datos se inicia en otra pestaña. Puede ver todas las ejecuciones de canalización y sus estados. Tenga en cuenta que, en el ejemplo siguiente, el estado de ejecución de la canalización es Correcto. Puede comprobar los parámetros pasados a la canalización si hace clic en la columna Parámetros. Si se ha producido un error, verá un vínculo en la columna Error. Haga clic en el vínculo de la columna Acciones.
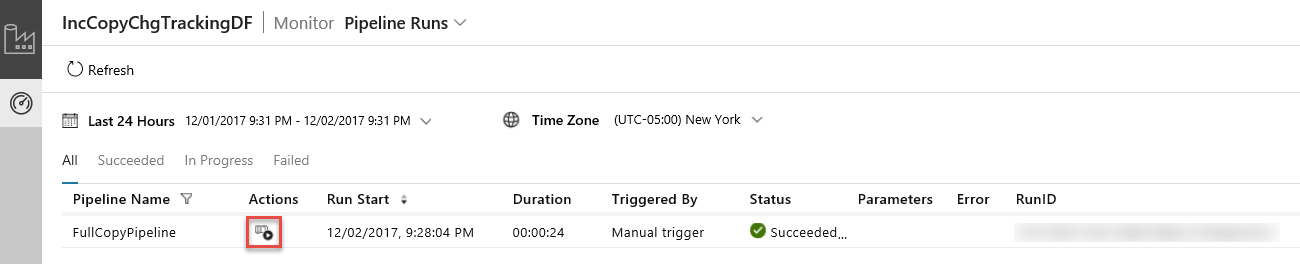
Al hacer clic en el vínculo de la columna Acciones, verá la página siguiente que muestra todas las ejecuciones de actividad de la canalización.

Para volver a la vista de ejecuciones de canalización, haga clic en Canalizaciones como se muestra en la imagen.
Revisión del resultado
Verá un archivo denominado incremental-<GUID>.txt en la carpeta incchgtracking del contenedor adftutorial.

El archivo debe tener los datos de la base de datos:
1,aaaa,21
2,bbbb,24
3,cccc,20
4,dddd,26
5,eeee,22
Adición de más datos a la tabla de origen
Ejecute la siguiente consulta en la base de datos para agregar una fila y actualizarla.
INSERT INTO data_source_table
(PersonID, Name, Age)
VALUES
(6, 'new','50');
UPDATE data_source_table
SET [Age] = '10', [name]='update' where [PersonID] = 1
Creación de una canalización para la copia diferencial
En este paso, creará una canalización con las siguientes actividades y la ejecutará con regularidad. Las actividades de búsqueda obtienen los valores SYS_CHANGE_VERSION antiguo y nuevo desde Azure SQL Database y los pasan a la actividad de copia. La actividad de copia copia los datos insertados, actualizados o eliminados entre los dos valores SYS_CHANGE_VERSION de Azure SQL Database a Azure Blob Storage. La actividad de procedimiento almacenado actualiza el valor SYS_CHANGE_VERSION para la ejecución de la siguiente canalización.
Cree un archivo JSON llamado IncrementalCopyPipeline.json en la misma carpeta con el siguiente contenido:
{ "name": "IncrementalCopyPipeline", "properties": { "activities": [ { "name": "LookupLastChangeTrackingVersionActivity", "type": "Lookup", "typeProperties": { "source": { "type": "SqlSource", "sqlReaderQuery": "select * from table_store_ChangeTracking_version" }, "dataset": { "referenceName": "ChangeTrackingDataset", "type": "DatasetReference" } } }, { "name": "LookupCurrentChangeTrackingVersionActivity", "type": "Lookup", "typeProperties": { "source": { "type": "SqlSource", "sqlReaderQuery": "SELECT CHANGE_TRACKING_CURRENT_VERSION() as CurrentChangeTrackingVersion" }, "dataset": { "referenceName": "SourceDataset", "type": "DatasetReference" } } }, { "name": "IncrementalCopyActivity", "type": "Copy", "typeProperties": { "source": { "type": "SqlSource", "sqlReaderQuery": "select data_source_table.PersonID,data_source_table.Name,data_source_table.Age, CT.SYS_CHANGE_VERSION, SYS_CHANGE_OPERATION from data_source_table RIGHT OUTER JOIN CHANGETABLE(CHANGES data_source_table, @{activity('LookupLastChangeTrackingVersionActivity').output.firstRow.SYS_CHANGE_VERSION}) as CT on data_source_table.PersonID = CT.PersonID where CT.SYS_CHANGE_VERSION <= @{activity('LookupCurrentChangeTrackingVersionActivity').output.firstRow.CurrentChangeTrackingVersion}" }, "sink": { "type": "BlobSink" } }, "dependsOn": [ { "activity": "LookupLastChangeTrackingVersionActivity", "dependencyConditions": [ "Succeeded" ] }, { "activity": "LookupCurrentChangeTrackingVersionActivity", "dependencyConditions": [ "Succeeded" ] } ], "inputs": [ { "referenceName": "SourceDataset", "type": "DatasetReference" } ], "outputs": [ { "referenceName": "SinkDataset", "type": "DatasetReference" } ] }, { "name": "StoredProceduretoUpdateChangeTrackingActivity", "type": "SqlServerStoredProcedure", "typeProperties": { "storedProcedureName": "Update_ChangeTracking_Version", "storedProcedureParameters": { "CurrentTrackingVersion": { "value": "@{activity('LookupCurrentChangeTrackingVersionActivity').output.firstRow.CurrentChangeTrackingVersion}", "type": "INT64" }, "TableName": { "value": "@{activity('LookupLastChangeTrackingVersionActivity').output.firstRow.TableName}", "type": "String" } } }, "linkedServiceName": { "referenceName": "AzureSQLDatabaseLinkedService", "type": "LinkedServiceReference" }, "dependsOn": [ { "activity": "IncrementalCopyActivity", "dependencyConditions": [ "Succeeded" ] } ] } ] } }Ejecute el cmdlet Set-AzDataFactoryV2Pipeline para crear la canalización: FullCopyPipeline.
Set-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "IncrementalCopyPipeline" -File ".\IncrementalCopyPipeline.json"Este es la salida de ejemplo:
PipelineName : IncrementalCopyPipeline ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Activities : {LookupLastChangeTrackingVersionActivity, LookupCurrentChangeTrackingVersionActivity, IncrementalCopyActivity, StoredProceduretoUpdateChangeTrackingActivity} Parameters :
Ejecución de la canalización de la copia incremental
Ejecución de la canalización IncrementalCopyPipeline mediante el cmdlet Invoke-AzDataFactoryV2Pipeline.
Invoke-AzDataFactoryV2Pipeline -PipelineName "IncrementalCopyPipeline" -ResourceGroup $resourceGroupName -dataFactoryName $dataFactoryName
Supervisión de la canalización de la copia incremental
En la aplicación de integración de datos, actualice la vista de ejecuciones de canalización. Confirme que ve IncrementalCopyPipeline en la lista. Haga clic en el vínculo de la columna Acciones.
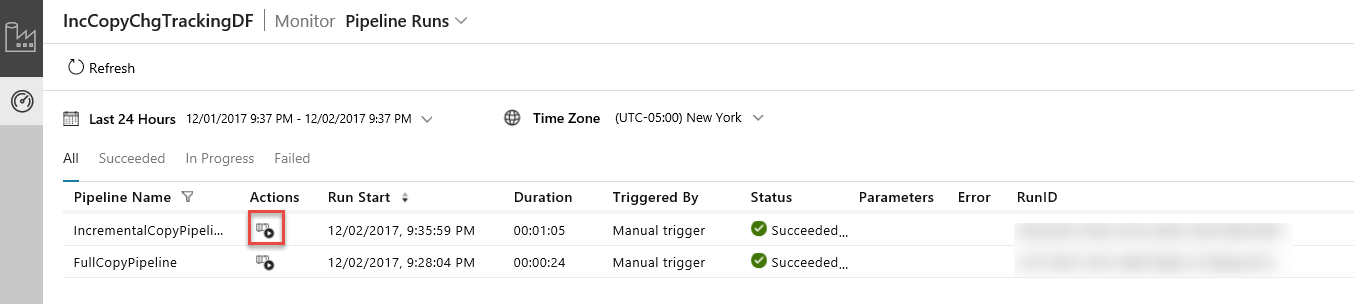
Al hacer clic en el vínculo de la columna Acciones, verá la página siguiente que muestra todas las ejecuciones de actividad de la canalización.

Para volver a la vista de ejecuciones de canalización, haga clic en Canalizaciones como se muestra en la imagen.
Revisión del resultado
Verá el segundo archivo incchgtracking en la carpeta adftutorial del contenedor.

El archivo debe tener solo los datos diferenciales de la base de datos. El registro con U es la fila actualizada en la base de datos y I es la fila que se agrega.
1,update,10,2,U
6,new,50,1,I
Las tres primeras columnas son datos que han cambiado de data_source_table. Las dos últimas columnas son los metadatos de la tabla del sistema de control de cambios. La cuarta columna es el valor SYS_CHANGE_VERSION de cada fila modificada. La quinta columna es la operación: U = actualización, I = inserción. Para obtener más información acerca de la información de control de cambios, consulte CHANGETABLE.
==================================================================
PersonID Name Age SYS_CHANGE_VERSION SYS_CHANGE_OPERATION
==================================================================
1 update 10 2 U
6 new 50 1 I
Contenido relacionado
Pase al tutorial siguiente para obtener información acerca de cómo copiar archivos nuevos y modificados solo según el valor de LastModifiedDate: