Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
SE APLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis integral para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y la creación de informes. Obtenga información sobre cómo iniciar una nueva evaluación gratuita.
En este artículo se explica el uso de la actividad de copia de canalizaciones de Azure Data Factory o Azure Synapse para copiar datos con Azure SQL Database como origen y destino, y el uso de Data Flow para transformarlos en Azure SQL Database. Para obtener más información, lea el artículo de introducción para Azure Data Factory o Azure Synapse Analytics.
Funcionalidades admitidas
Este conector de Azure SQL Database es compatible con las funcionalidades siguientes:
| Funcionalidades admitidas | IR | Punto de conexión privado administrado |
|---|---|---|
| Actividad de copia (origen/receptor) | 1 2 | ✓ |
| Flujo de datos de asignación (origen/receptor) | ① | ✓ |
| Actividad de búsqueda | 1 2 | ✓ |
| Actividad GetMetadata | 1 2 | ✓ |
| Actividad de script | 1 2 | ✓ |
| Actividad de procedimiento almacenado | 1 2 | ✓ |
① Azure Integration Runtime ② Entorno de ejecución de integración autohospedado
Para la actividad de copia, este conector de Azure SQL Database admite estas funciones:
- Copia de datos mediante la autenticación con SQL y la autenticación de tokens de aplicaciones de Microsoft Entra con una entidad de servicio o identidades administradas para recursos de Azure.
- Como origen, la recuperación de datos mediante una consulta SQL o un procedimiento almacenado. También puede optar por la copia en paralelo desde un origen de Azure SQL Database; vea la sección Copia en paralelo desde una base de datos SQL para obtener detalles.
- Como receptor, la creación automática de la tabla de destino si no existe en función del esquema de origen; la anexión de datos a una tabla o la invocación de un procedimiento almacenado con lógica personalizada durante la copia.
Si usa el nivel sin servidor de Azure SQL Database, tenga en cuenta que cuando se pausa el servidor, se produce un error en la ejecución de la actividad en lugar de esperar a que esté lista la reanudación automática. Puede agregar reintentos de actividad o encadenar actividades adicionales para asegurarse de que el servidor está activo en la ejecución real.
Importante
Si copia los datos mediante el entorno de ejecución de integración de Azure, configure una regla de firewall de nivel de servidor para que los servicios de Azure puedan acceder al servidor. Si copia los datos mediante un entorno de ejecución de integración autohospedado, configure el firewall para permitir el intervalo IP apropiado. Dicho intervalo incluye la dirección IP de la máquina que se utiliza para conectarse a Azure SQL Database.
Primeros pasos
Para realizar la actividad de copia con una canalización, puede usar una de las siguientes herramientas o SDK:
- Herramienta Copiar datos
- Azure Portal
- SDK de .NET
- SDK de Python
- Azure PowerShell
- REST API
- Plantilla de Azure Resource Manager
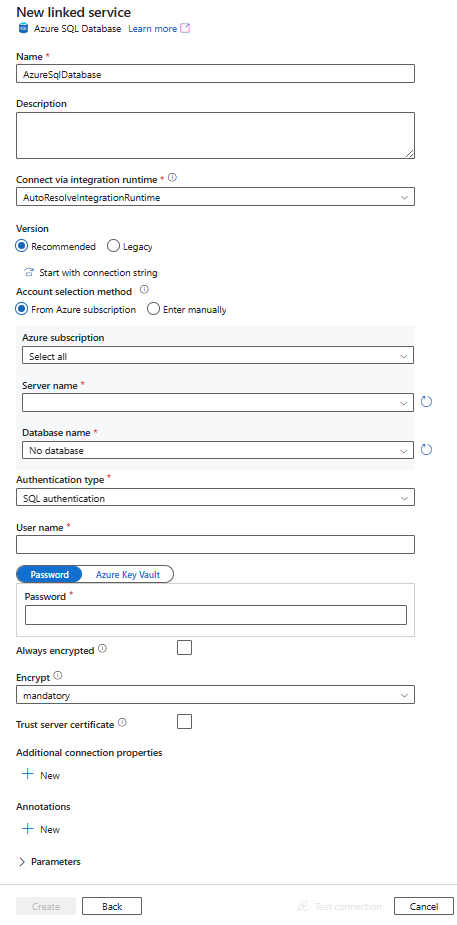
Creación de un servicio vinculado de Azure SQL Database mediante la interfaz de usuario
Siga estos pasos para crear un servicio vinculado de Azure SQL Database en la interfaz de usuario de Azure Portal.
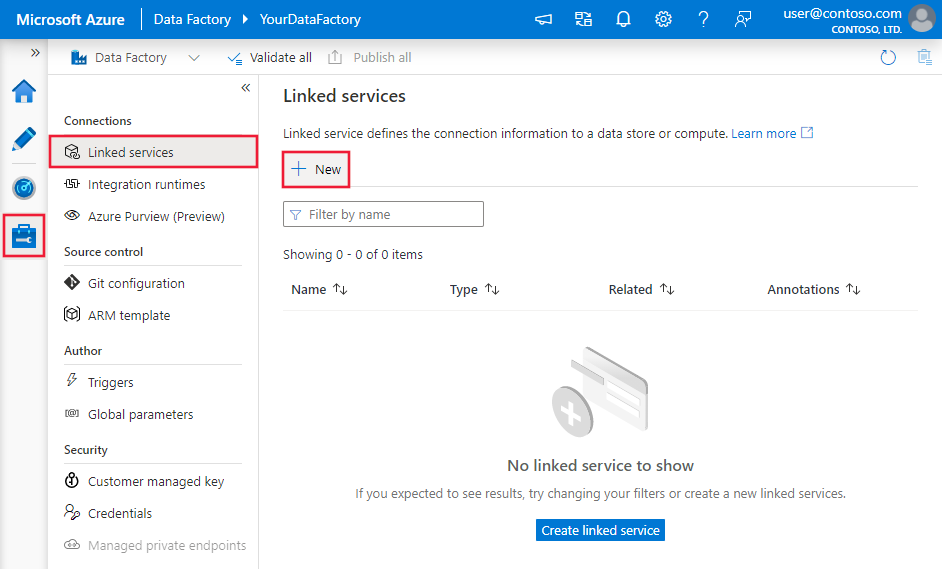
Vaya a la pestaña "Administrar" de su área de trabajo de Azure Data Factory o Synapse y seleccione "Servicios vinculados"; a continuación, haga clic en "Nuevo":
Busque SQL y seleccione el conector de Azure SQL Database.

Configure los detalles del servicio, pruebe la conexión y cree el servicio vinculado.
Detalles de configuración del conector
En las secciones siguientes se proporciona información acerca de las propiedades que se usan para definir las entidades de canalizaciones de Data Factory o Synapse específicas de un conector de Azure SQL Database.
Propiedades del servicio vinculado
La versión Recomendada conector de Azure SQL Database admite TLS 1.3. Consulte esta sección para actualizar la versión del conector de Azure SQL Database desde Heredado. Para obtener los detalles de la propiedad, consulte las secciones correspondientes.
Sugerencia
Si recibió un error con el código de error "UserErrorFailedToConnectToSqlServer" y un mensaje parecido a "The session limit for the database is XXX and has been reached" (El límite de sesión de la base de datos es XXX y ya se ha alcanzado), agregue Pooling=false a la cadena de conexión e inténtelo de nuevo.
Pooling=false también se recomienda para la configuración de servicios vinculados de tipo SHIR (entorno de ejecución de integración autohospedado). Es posible agregar una agrupación y otros parámetros de conexión como nuevos nombres y valores de parámetro en la sección Propiedades de conexión adicionales del formulario de creación de servicios vinculados.
Versión recomendada
Estas propiedades genéricas son compatibles con un servicio vinculado de Azure SQL Database al aplicar la versión Recomendada :
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type debe establecerse en AzureSqlDatabase. | Sí |
| server | Nombre o dirección de red de la instancia de SQL Server a la que desea conectarse. | Sí |
| database | El nombre de la base de datos. | Sí |
| authenticationType | Tipo usado para la autenticación. Los valores permitidos son SQL (valor predeterminado), ServicePrincipal, SystemAssignedManagedIdentity, UserAssignedManagedIdentity. Ve a la sección de autenticación pertinente sobre propiedades y requisitos previos específicos. | Sí |
| alwaysEncryptedSettings | Especifique la información alwaysencryptedsettings necesaria para permitir que Always Encrypted proteja los datos confidenciales almacenados en un servidor SQL mediante una identidad administrada o una entidad de servicio. Para obtener más información, vea el ejemplo de JSON debajo de la tabla y consulte la sección Uso de Always Encrypted. Si no se especifica, la configuración predeterminada Always Encrypted está deshabilitada. | No |
| encrypt | Indica si se requiere cifrado TLS para todos los datos enviados entre el cliente y el servidor. Opciones: obligatorio (para true, valor predeterminado)/opcional (para falso)/restringido. | No |
| trustServerCertificate | Indique si el canal se cifrará al pasar la cadena de certificados para validar la confianza. | No |
| hostNameInCertificate | Nombre de host que se va a usar al validar el certificado de servidor para la conexión. Cuando no se especifica, el nombre del servidor se usa para la validación de certificados. | No |
| connectVia | Este entorno de ejecución de integración se usa para conectarse al almacén de datos. Se puede usar Azure Integration Runtime o un entorno de ejecución de integración autohospedado, si el almacén de datos se encuentra en una red privada. Si no se especifica, se usa el valor predeterminado de Azure Integration Runtime. | No |
Para obtener más propiedades de conexión, consulte la tabla siguiente:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| applicationIntent | Tipo de carga de trabajo de aplicación al conectarse a un servidor. Los valores permitidos son ReadOnly y ReadWrite. |
No |
| connectTimeout | El período de tiempo (en segundos) que se espera a una conexión al servidor antes de finalizar el intento y generar un error. | No |
| connectRetryCount | Número de reconexión intentadas después de identificar un error de conexión inactiva. El valor debe ser un número entero entre 0 y 255. | No |
| connectRetryInterval | Cantidad de tiempo (en segundos) entre cada intento de reconexión después de identificar un error de conexión inactiva. El valor debe ser un entero entre 1 y 60. | No |
| loadBalanceTimeout | Tiempo mínimo (en segundos) para que la conexión resida en el grupo de conexiones antes de que se destruya la conexión. | No |
| commandTimeout | Tiempo de espera predeterminado (en segundos) antes de terminar el intento de ejecutar un comando y generar un error. | No |
| integratedSecurity | Los valores permitidos son true o false. Al especificar false, indique si userName y contraseña se especifican en la conexión. Al especificar true, indica si las credenciales actuales de la cuenta de Windows se usan para la autenticación. |
No |
| failoverPartner | Nombre o dirección del servidor asociado al que se va a conectar si el servidor principal está inactivo. | No |
| maxPoolSize | Número máximo de conexiones permitidas en el grupo de conexiones para la conexión específica. | No |
| minPoolSize | Número mínimo de conexiones permitidas en el grupo de conexiones para la conexión específica. | No |
| multipleActiveResultSets | Los valores permitidos son true o false. Al especificar true, una aplicación puede mantener conjunto de resultados activo múltiple (MARS). Al especificar false, una aplicación debe procesar o cancelar todos los conjuntos de resultados de un lote para poder ejecutar cualquier otro lote en esa conexión. |
No |
| multiSubnetFailover | Los valores permitidos son true o false. Si la aplicación se conecta a un grupo de disponibilidad AlwaysOn (AG) en subredes diferentes, establecer esta propiedad en true proporciona una detección y conexión más rápidas con el servidor activo actualmente. |
No |
| packetSize | Tamaño en bytes de los paquetes de red usados para comunicarse con una instancia de servidor. | No |
| pooling | Los valores permitidos son true o false. Al especificar true, la conexión se agrupará. Al especificar false, la conexión se abrirá explícitamente cada vez que se solicite la conexión. |
No |
Autenticación SQL
Para usar la autenticación de SQL, además de las propiedades genéricas que se describen en la sección anterior, especifique las siguientes propiedades:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| userName | Nombre de usuario usado para conectarse al servidor. | Sí |
| password | Contraseña del nombre de usuario. Marque este campo como SecureString para almacenarlo de forma segura. O bien puede hacer referencia a un secreto almacenado en Azure Key Vault. | Sí |
Ejemplo: uso de la autenticación de SQL
{
"name": "AzureSqlDbLinkedService",
"properties": {
"type": "AzureSqlDatabase",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Ejemplo: contraseña de Azure Key Vault
{
"name": "AzureSqlDbLinkedService",
"properties": {
"type": "AzureSqlDatabase",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Ejemplo: Use Always Encrypted
{
"name": "AzureSqlDbLinkedService",
"properties": {
"type": "AzureSqlDatabase",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
},
"alwaysEncryptedSettings": {
"alwaysEncryptedAkvAuthType": "ServicePrincipal",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"type": "SecureString",
"value": "<service principal key>"
}
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Autenticación de entidad de servicio
Para usar la autenticación de la entidad de servicio, además de las propiedades genéricas descritas en las secciones anteriores, especifique las siguientes:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| servicePrincipalId | Especifique el id. de cliente de la aplicación. | Sí |
| servicePrincipalCredential | Credencial de entidad de servicio. Especifique la clave de la aplicación. Marque este campo como SecureString para almacenarlo de forma segura, o bien haga referencia a un secreto almacenado en Azure Key Vault. | Sí |
| tenant | Especifique la información del inquilino, como el nombre de dominio o identificador de inquilino, en el que reside la aplicación. Para recuperarlo, mantenga el puntero del mouse en la esquina superior derecha de Azure Portal. | Sí |
| azureCloudType | Para la autenticación de la entidad de servicio, especifique el tipo de entorno de nube de Azure en el que está registrada la aplicación de Microsoft Entra. Los valores permitidos son AzurePublic, AzureChina, AzureUsGovernment y AzureGermany. De forma predeterminada, se usa el entorno en la nube de la canalización de Data Factory o Synapse. |
No |
También debe seguir los pasos siguientes:
Crear una aplicación de Microsoft Entra desde Azure Portal. Anote el nombre de la aplicación y los siguientes valores, que definen el servicio vinculado:
- Identificador de aplicación
- Clave de la aplicación
- Id. de inquilino
Aprovisione un administrador de Microsoft Entra para el servidor en Azure Portal, si aún no lo ha hecho. El administrador de Microsoft Entra debe ser un usuario de Microsoft Entra o un grupo de Microsoft Entra, pero no puede ser un servicio principal. Este paso se realiza con el fin de que, en el siguiente paso, pueda usar una identidad de Microsoft Entra para crear un usuario de base de datos independiente para la entidad de servicio.
Cree usuarios de bases de datos independientes para la entidad de servicio. Conéctese a la base de datos de la que desea copiar datos (o a la que desea copiarlos) mediante alguna herramienta como SQL Server Management Studio, con una identidad de Microsoft Entra que tenga al menos permiso para MODIFICAR CUALQUIER USUARIO. Ejecute el T-SQL siguiente:
CREATE USER [your application name] FROM EXTERNAL PROVIDER;Conceda a la entidad de servicio los permisos necesarios, tal como lo haría normalmente para los usuarios de SQL, u otros usuarios. Ejecute el código siguiente: Para más opciones, consulte este documento.
ALTER ROLE [role name] ADD MEMBER [your application name];Configure un servicio vinculado a Azure SQL Database en un área de trabajo de Azure Data Factory o Synapse.
Ejemplo de servicio vinculado que usa la autenticación de entidad de servicio
{
"name": "AzureSqlDbLinkedService",
"properties": {
"type": "AzureSqlDatabase",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"hostNameInCertificate": "<host name>",
"authenticationType": "ServicePrincipal",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredential": {
"type": "SecureString",
"value": "<application key>"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Autenticación de identidad administrada asignada por el sistema
Un área de trabajo de Data Factory o de Synapse se puede asociar con una identidad administrada asignada por el sistema para recursos de Azure que represente el servicio cuando se autentica en otros recursos de Azure. Esta identidad administrada se puede usar para la autenticación de Azure SQL Database. Puede acceder a la factoría designada o al área de trabajo de Synapse y copiar datos desde la base de datos o en la base de datos usando esta identidad.
Para usar la autenticación de identidad administrada asignada por el sistema, especifique las propiedades genéricas que se describen en la sección anterior y siga estos pasos.
Aprovisione un administrador de Microsoft Entra para el servidor en Azure Portal, si aún no lo ha hecho. El administrador de Microsoft Entra puede ser un usuario de Microsoft Entra o un grupo de Microsoft Entra. Si concede al grupo con identidad administrada un rol de administrador, omita los pasos 3 y 4. El administrador tiene acceso total a la base de datos.
Cree usuarios de bases de datos independientes para la identidad administrada. Conéctese a la base de datos de la que desea copiar datos (o a la que desea copiarlos) mediante alguna herramienta como SQL Server Management Studio, con una identidad de Microsoft Entra que tenga al menos permiso para MODIFICAR CUALQUIER USUARIO. Ejecute el T-SQL siguiente:
CREATE USER [your_resource_name] FROM EXTERNAL PROVIDER;Conceda a la identidad administrada los permisos necesarios, tal como lo haría normalmente para los usuarios de SQL y otros usuarios. Ejecute el código siguiente: Para más opciones, consulte este documento.
ALTER ROLE [role name] ADD MEMBER [your_resource_name];Configure un servicio vinculado de Azure SQL Database.
Ejemplo
{
"name": "AzureSqlDbLinkedService",
"properties": {
"type": "AzureSqlDatabase",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SystemAssignedManagedIdentity"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Autenticación de identidad administrada asignada por el usuario
Un área de trabajo de Data Factory o de Synapse se puede asociar con una identidad administrada asignada por el usuario que represente el servicio cuando se autentica en otros recursos de Azure. Esta identidad administrada se puede usar para la autenticación de Azure SQL Database. Puede acceder a la factoría designada o al área de trabajo de Synapse y copiar datos desde la base de datos o en la base de datos usando esta identidad.
Para usar la autenticación de identidad administrada asignada por el usuario, además de las propiedades genéricas descritas en la sección anterior, especifique las siguientes:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| credentials | Especifique la identidad administrada asignada por el usuario como objeto de credencial. | Sí |
También debe seguir los pasos siguientes:
Aprovisione un administrador de Microsoft Entra para el servidor en Azure Portal, si aún no lo ha hecho. El administrador de Microsoft Entra puede ser un usuario de Microsoft Entra o un grupo de Microsoft Entra. Si concede al grupo con identidad administrada asignada por el usuario un rol de administrador, omita el paso 3. El administrador tiene acceso total a la base de datos.
Cree usuarios de bases de datos independientes para la identidad administrada asignada por el usuario. Conéctese a la base de datos de la que desea copiar datos (o a la que desea copiarlos) mediante alguna herramienta como SQL Server Management Studio, con una identidad de Microsoft Entra que tenga al menos permiso para MODIFICAR CUALQUIER USUARIO. Ejecute el T-SQL siguiente:
CREATE USER [your_resource_name] FROM EXTERNAL PROVIDER;Cree una o varias identidades administradas asignadas por el usuario y conceda a la identidad administrada asignada por el usuario los permisos necesarios como haría normalmente para usuarios SQL y otros. Ejecute el código siguiente: Para más opciones, consulte este documento.
ALTER ROLE [role name] ADD MEMBER [your_resource_name];Asigne una o varias identidades administradas asignadas por el usuario a la factoría de datos y cree credenciales para cada identidad.
Configure un servicio vinculado de Azure SQL Database.
Ejemplo
{
"name": "AzureSqlDbLinkedService",
"properties": {
"type": "AzureSqlDatabase",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "UserAssignedManagedIdentity",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Versión heredada
Estas propiedades genéricas se admiten para un servicio vinculado de Azure SQL Database al aplicar la versión Heredada:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type debe establecerse en AzureSqlDatabase. | Sí |
| connectionString | Especifique la información necesaria para conectarse a la base de datos de Azure SQL para la propiedad connectionString. También puede poner una contraseña o una clave de entidad de servicio Azure Key Vault. Si se trata de la autenticación de SQL, extraiga la configuración password de la cadena de conexión. Para obtener más información, consulte Almacenamiento de credenciales en Azure Key Vault. |
Sí |
| alwaysEncryptedSettings | Especifique la información alwaysencryptedsettings necesaria para permitir que Always Encrypted proteja los datos confidenciales almacenados en un servidor SQL mediante una identidad administrada o una entidad de servicio. Para más información, consulte la sección Uso de Always Encrypted. Si no se especifica, la configuración predeterminada Always Encrypted está deshabilitada. | No |
| connectVia | Este entorno de ejecución de integración se usa para conectarse al almacén de datos. Se puede usar Azure Integration Runtime o un entorno de ejecución de integración autohospedado, si el almacén de datos se encuentra en una red privada. Si no se especifica, se usa el valor predeterminado de Azure Integration Runtime. | No |
Para los distintos tipos de autenticación, consulte las secciones siguientes sobre propiedades y requisitos previos específicos, respectivamente:
- Autenticación de SQL para la versión heredada
- Autenticación de entidad de servicio para la versión heredada
- Autenticación de identidad administrada asignada por el sistema para la versión heredada
- Autenticación de identidad administrada asignada por el usuario para la versión heredada
Autenticación de SQL para la versión heredada
Para usar la autenticación de SQL, especifique las propiedades genéricas que se describen en la sección anterior.
Autenticación de entidad de servicio para la versión heredada
Para usar la autenticación de la entidad de servicio, además de las propiedades genéricas descritas en las secciones anteriores, especifique las siguientes:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| servicePrincipalId | Especifique el id. de cliente de la aplicación. | Sí |
| servicePrincipalKey | Especifique la clave de la aplicación. Marque este campo como SecureString para almacenarlo de forma segura, o bien haga referencia a un secreto almacenado en Azure Key Vault. | Sí |
| tenant | Especifique la información del inquilino, como el nombre de dominio o identificador de inquilino, en el que reside la aplicación. Para recuperarlo, mantenga el puntero del mouse en la esquina superior derecha de Azure Portal. | Sí |
| azureCloudType | Para la autenticación de la entidad de servicio, especifique el tipo de entorno de nube de Azure en el que está registrada la aplicación de Microsoft Entra. Los valores permitidos son AzurePublic, AzureChina, AzureUsGovernment y AzureGermany. De forma predeterminada, se usa el entorno en la nube de la canalización de Data Factory o Synapse. |
No |
También debe seguir los pasos descritos en Autenticación de la entidad de servicio para conceder el permiso correspondiente.
Autenticación de identidad administrada asignada por el sistema para la versión heredada
Para usar la autenticación de identidad administrada asignada por el sistema, siga el mismo paso para la versión recomendada en Autenticación de identidad administrada asignada por el sistema.
Autenticación de identidad administrada asignada por el usuario para la versión heredada
Para usar la autenticación de identidad administrada asignada por el usuario, siga el mismo paso para la versión recomendada en Autenticación de identidad administrada asignada por el usuario.
Propiedades del conjunto de datos
Si desea obtener una lista completa de secciones y propiedades disponibles para definir los conjuntos de datos, consulte Conjuntos de datos.
Las siguientes propiedades se admiten con el conjunto de datos de Azure SQL Database:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type del conjunto de datos debe establecerse en AzureSqlTable. | Sí |
| esquema | Nombre del esquema. | No para el origen, sí para el receptor |
| table | Nombre de la tabla o vista. | No para el origen, sí para el receptor |
| tableName | Nombre de la tabla o vista con el esquema. Esta propiedad permite la compatibilidad con versiones anteriores. Para la nueva carga de trabajo use schema y table. |
No para el origen, sí para el receptor |
Ejemplo de propiedades de un conjunto de datos
{
"name": "AzureSQLDbDataset",
"properties":
{
"type": "AzureSqlTable",
"linkedServiceName": {
"referenceName": "<Azure SQL Database linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
}
}
}
Propiedades de la actividad de copia
Para ver una lista completa de las secciones y propiedades disponibles para definir actividades, consulte Canalizaciones. En esta sección se proporciona una lista de las propiedades que el origen y el receptor de Azure SQL Database admiten.
Azure SQL Database como origen
Sugerencia
Para cargar datos desde Azure SQL Database de manera eficaz mediante la creación de particiones de datos, vea Copia en paralelo desde una base de datos SQL.
Para copiar datos desde Azure SQL Database, se admiten las siguientes propiedades en la sección de origen de la actividad de copia:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type del origen de la actividad de copia debe establecerse en AzureSqlSource. Todavía se admite el tipo "SqlSource" para la compatibilidad con versiones anteriores. | Sí |
| sqlReaderQuery | Esta propiedad usa la consulta SQL personalizada para leer los datos. Un ejemplo es select * from MyTable. |
No |
| sqlReaderStoredProcedureName | Nombre del procedimiento almacenado que lee datos de la tabla de origen. La última instrucción SQL debe ser una instrucción SELECT del procedimiento almacenado. | No |
| storedProcedureParameters | Parámetros del procedimiento almacenado. Los valores permitidos son pares de nombre o valor. Los nombres y las mayúsculas y minúsculas de los parámetros tienen que coincidir con las mismas características de los parámetros de procedimiento almacenado. |
No |
| isolationLevel | Especifica el comportamiento de bloqueo de transacción para el origen de SQL. Los valores permitidos son: ReadCommitted, ReadUncommitted, RepeatableRead, Serializable y Snapshot. Si no se especifica, se usa el nivel de aislamiento predeterminado de la base de datos. Vea este documento para obtener más detalles. | No |
| partitionOptions | Especifica las opciones de creación de particiones de datos que se usan para cargar datos desde Azure SQL Database. Los valores permitidos son: Ninguno (por defecto), PhysicalPartitionsOfTable, y DynamicRange. Cuando una opción de partición está habilitada (es decir, no None), el grado de paralelismo para cargar datos de forma concurrente desde una base de datos Azure SQL Database está controlado por la configuración parallelCopiesen la actividad de copia. |
No |
| partitionSettings | Especifique el grupo de configuración para la creación de particiones de datos. Se aplica si la opción de partición no es None. |
No |
En partitionSettings: |
||
| partitionColumnName | Especifique el nombre de la columna de origen de tipo entero o date/datetime (int, smallint, bigint, date, smalldatetime, datetime, datetime2 o datetimeoffset) que se va a usar en la creación de particiones por rangos para la copia en paralelo. Si no se especifica, el índice o la clave primaria de la tabla se detectan automáticamente y se usan como columna de partición.Se aplica si la opción de partición es DynamicRange. Si usa una consulta para recuperar datos de origen, enlace ?DfDynamicRangePartitionCondition en la cláusula WHERE. Para ver un ejemplo, consulte la sección Copia en paralelo desde una base de datos SQL. |
No |
| partitionUpperBound | Valor máximo de la columna de partición para la división del rango de partición. Este valor se usa para decidir el intervalo de particiones, no para filtrar las filas de la tabla. Se crean particiones de todas las filas de la tabla o el resultado de la consulta y se copian. Si no se especifica, la actividad de copia detecta automáticamente el valor. Se aplica si la opción de partición es DynamicRange. Para ver un ejemplo, consulte la sección Copia en paralelo desde una base de datos SQL. |
No |
| partitionLowerBound | Valor mínimo de la columna de partición para la división del rango de partición. Este valor se usa para decidir el intervalo de particiones, no para filtrar las filas de la tabla. Se crean particiones de todas las filas de la tabla o el resultado de la consulta y se copian. Si no se especifica, la actividad de copia detecta automáticamente el valor. Se aplica si la opción de partición es DynamicRange. Para ver un ejemplo, consulte la sección Copia en paralelo desde una base de datos SQL. |
No |
Tenga en cuenta los siguientes puntos:
- Si se especifica sqlReaderQuery para AzureSqlSource, la actividad de copia ejecuta la consulta en el origen de Azure SQL Database para obtener los datos. También puede indicar un procedimiento almacenado mediante la definición de sqlReaderStoredProcedureName y storedProcedureParameters si el procedimiento almacenado adopta parámetros.
- Al usar el procedimiento almacenado del origen para recuperar datos, tenga en cuenta que si está diseñado para devolver otro esquema cuando se pasa un valor de parámetro diferente, es posible que encuentre un error o vea un resultado inesperado al importar el esquema desde la interfaz de usuario, o bien al copiar datos en la base de datos SQL con la creación automática de tablas.
Ejemplo de consulta SQL
"activities":[
{
"name": "CopyFromAzureSQLDatabase",
"type": "Copy",
"inputs": [
{
"referenceName": "<Azure SQL Database input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureSqlSource",
"sqlReaderQuery": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Ejemplo de procedimiento almacenado
"activities":[
{
"name": "CopyFromAzureSQLDatabase",
"type": "Copy",
"inputs": [
{
"referenceName": "<Azure SQL Database input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureSqlSource",
"sqlReaderStoredProcedureName": "CopyTestSrcStoredProcedureWithParameters",
"storedProcedureParameters": {
"stringData": { "value": "str3" },
"identifier": { "value": "$$Text.Format('{0:yyyy}', <datetime parameter>)", "type": "Int"}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Definición del procedimiento almacenado
CREATE PROCEDURE CopyTestSrcStoredProcedureWithParameters
(
@stringData varchar(20),
@identifier int
)
AS
SET NOCOUNT ON;
BEGIN
select *
from dbo.UnitTestSrcTable
where dbo.UnitTestSrcTable.stringData != stringData
and dbo.UnitTestSrcTable.identifier != identifier
END
GO
Azure SQL Database como receptor
Sugerencia
Más información sobre los comportamientos de escritura, las configuraciones y los procedimientos recomendados que se admiten en Procedimiento recomendado para cargar datos en Azure SQL Database.
Para copiar datos en Azure SQL Database, se admiten las siguientes propiedades en la sección de receptor de la actividad de copia:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type del receptor de la actividad de copia debe establecerse en AzureSqlSink. Todavía se admite el tipo "SqlSink" para la compatibilidad con versiones anteriores. | Sí |
| preCopyScript | Especifique una consulta SQL para que la actividad de copia se ejecute antes de escribir datos en Azure SQL Database. Solo se invoca una vez por cada copia que se ejecuta. Esta propiedad se usa para limpiar los datos cargados previamente. | No |
| tableOption | Especifica si se crea automáticamente la tabla de receptores según el esquema de origen, si no existe. No se admite la creación automática de tablas cuando el receptor especifica un procedimiento almacenado. Los valores permitidos son: none (valor predeterminado), autoCreate. |
No |
| sqlWriterStoredProcedureName | El nombre del procedimiento almacenado que define cómo se aplican los datos de origen en una tabla de destino. Este procedimiento almacenado se invoca por lote. Para las operaciones que solo se ejecuta una vez y que no tiene nada que ver con los datos de origen, como por ejemplo, eliminar o truncar, use la propiedad preCopyScript.Vea el ejemplo de Invocación del procedimiento almacenado desde el receptor de SQL. |
No |
| storedProcedureTableTypeParameterName | Nombre del parámetro del tipo de tabla especificado en el procedimiento almacenado. | No |
| sqlWriterTableType | Nombre del tipo de tabla que se usará en el procedimiento almacenado. La actividad de copia dispone que los datos que se mueven estén disponibles en una tabla temporal con este tipo de tabla. El código de procedimiento almacenado puede combinar los datos copiados con datos existentes. | No |
| storedProcedureParameters | Parámetros del procedimiento almacenado. Los valores permitidos son pares de nombre y valor. Los nombres y las mayúsculas y minúsculas de los parámetros deben coincidir con las mismas características de los parámetros de procedimiento almacenado. |
No |
| writeBatchSize | Número de filas que se va a insertar en la tabla SQL por lote. El valor que se permite es un entero (número de filas). De manera predeterminada, el servicio determina dinámicamente el tamaño adecuado del lote en función del tamaño de fila. |
No |
| writeBatchTimeout | El tiempo de espera para que se complete la operación de inserción, upsert y el procedimiento almacenado antes de que se agote el tiempo de espera. Los valores permitidos son para el intervalo de tiempo. Un ejemplo es "00:30:00" para 30 minutos. Si no se especifica ningún valor, el valor predeterminado es "00:30:00". |
No |
| disableMetricsCollection | El servicio recopila métricas, como las DTU de Azure SQL Database, para la optimización del rendimiento de copia y la obtención de recomendaciones, lo que proporciona acceso adicional a la base de datos maestra. Si le preocupa este comportamiento, especifique true para desactivarlo. |
No (el valor predeterminado es false) |
| maxConcurrentConnections | Número máximo de conexiones simultáneas establecidas en el almacén de datos durante la ejecución de la actividad. Especifique un valor solo cuando quiera limitar las conexiones simultáneas. | No |
| WriteBehavior | Especifique el comportamiento de escritura de la actividad de copia para cargar datos en Azure SQL Database. El valor permitido es Inserty Upsert. De forma predeterminada, el servicio usa Insert para cargar los datos. |
No |
| Configuración de "Upsert" (actualizar/insertar) | Especifique el grupo de la configuración para el comportamiento de escritura. Se aplica cuando la opción WriteBehavior es Upsert. |
No |
En upsertSettings: |
||
| useTempDB | Especifica si se va a usar la tabla temporal global o la tabla física como tabla provisional para upsert. De forma predeterminada, el servicio usa la tabla temporal global como tabla provisional. El valor es true. |
No |
| interimSchemaName | Especifique el esquema provisional para crear una tabla provisional si se usa la tabla física. Nota: el usuario debe tener el permiso para crear y eliminar la tabla. De forma predeterminada, la tabla provisional compartirá el mismo esquema que la tabla receptora. Se aplica cuando la opción useTempDB es False. |
No |
| claves | Especifique los nombres de columna para la identificación de fila única. Se puede usar una sola clave o una serie de claves. Si no se especifica, se usa la clave principal. | No |
Ejemplo 1: Anexión de datos
"activities":[
{
"name": "CopyToAzureSQLDatabase",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure SQL Database output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureSqlSink",
"tableOption": "autoCreate",
"writeBatchSize": 100000
}
}
}
]
Ejemplo 2: Invocación de un procedimiento almacenado durante la copia
Para más información, vea Invocación del procedimiento almacenado desde el receptor de SQL .
"activities":[
{
"name": "CopyToAzureSQLDatabase",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure SQL Database output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureSqlSink",
"sqlWriterStoredProcedureName": "CopyTestStoredProcedureWithParameters",
"storedProcedureTableTypeParameterName": "MyTable",
"sqlWriterTableType": "MyTableType",
"storedProcedureParameters": {
"identifier": { "value": "1", "type": "Int" },
"stringData": { "value": "str1" }
}
}
}
}
]
Ejemplo 3: datos de actualizar/insertar (upsert)
"activities":[
{
"name": "CopyToAzureSQLDatabase",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure SQL Database output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureSqlSink",
"tableOption": "autoCreate",
"writeBehavior": "upsert",
"upsertSettings": {
"useTempDB": true,
"keys": [
"<column name>"
]
},
}
}
}
]
Copia en paralelo desde una base de datos SQL
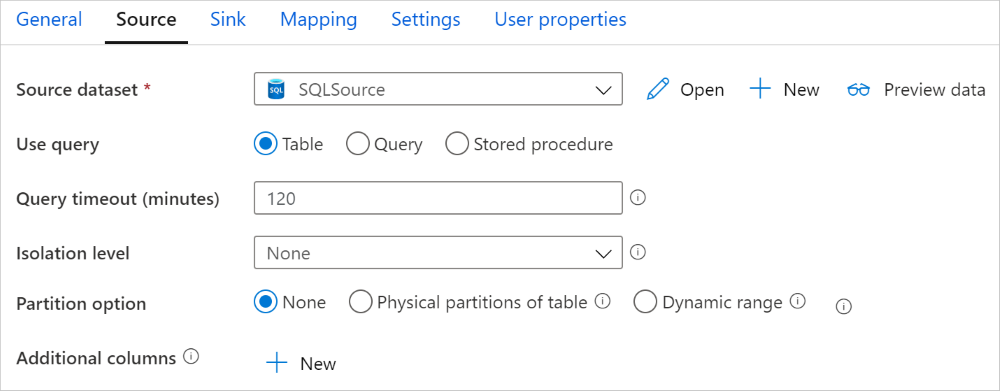
En la actividad de copia, el conector de Azure SQL Database proporciona creación de particiones de datos integrada para copiar los datos en paralelo. Puede encontrar las opciones de creación de particiones de datos en la pestaña Origen de la actividad de copia.
Al habilitar la copia con particiones, la actividad de copia ejecuta consultas en paralelo en el origen de Azure SQL Database para cargar los datos por particiones. El grado en paralelo se controla mediante el valor parallelCopies de la actividad de copia. Por ejemplo, si establece parallelCopies en cuatro, el servicio genera y ejecuta al mismo tiempo cuatro consultas de acuerdo con la configuración y la opción de partición que ha especificado, y cada consulta recupera una porción de la instancia de Azure SQL Database.
Se sugiere habilitar la copia en paralelo con la creación de particiones de datos, especialmente si se cargan grandes cantidades de datos de Azure SQL Database. Estas son algunas configuraciones sugeridas para diferentes escenarios. Cuando se copian datos en un almacén de datos basado en archivos, se recomienda escribirlos en una carpeta como varios archivos (solo especifique el nombre de la carpeta), en cuyo caso el rendimiento es mejor que escribirlos en un único archivo.
| Escenario | Configuración sugerida |
|---|---|
| Carga completa de una tabla grande con particiones físicas. |
Opción de partición: Particiones físicas de la tabla. Durante la ejecución, el servicio detecta automáticamente las particiones físicas y copia los datos por particiones. Para comprobar si la tabla tiene una partición física o no, puede hacer referencia a esta consulta. |
| Carga completa de una tabla grande, sin particiones físicas, aunque con una columna de tipo entero o datetime para la creación de particiones de datos. |
Opciones de partición: partición de intervalo dinámico. Columna de partición (opcional): especifique la columna usada para crear la partición de datos. Si no se especifica, se usa la columna de índice o clave principal. Partición de límite superior y partición de límite inferior (opcional): especifique si desea determinar el intervalo de partición. No es para filtrar las filas de la tabla, se crean particiones de todas las filas de la tabla y se copian. Si no se especifica, la actividad de copia detecta automáticamente los valores. Por ejemplo, si la columna de partición "ID" tiene valores que van de 1 a 100 y establece el límite inferior en 20 y el superior en 80, con la copia en paralelo establecida en 4, el servicio recupera los datos en 4 particiones: identificadores del rango <=20, del rango [21, 50], del rango [51, 80] y del rango >=81, respectivamente. |
| Carga de grandes cantidades de datos mediante una consulta personalizada, sin particiones físicas, aunque con una columna de tipo entero o date/datetime para la creación de particiones de datos. |
Opciones de partición: partición de intervalo dinámico. Consulta: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>.Columna de partición: especifique la columna usada para crear la partición de datos. Partición de límite superior y partición de límite inferior (opcional): especifique si desea determinar el intervalo de partición. No es para filtrar las filas de la tabla, se crean particiones de todas las filas del resultado de la consulta y se copian. Si no se especifica, la actividad de copia detecta automáticamente el valor. Por ejemplo, si la columna de partición "ID" tiene valores que van de 1 a 100 y establece el límite inferior en 20 y el superior en 80, con la copia en paralelo establecida en 4, el servicio recupera los datos en 4 particiones: identificadores del rango <=20, del rango [21, 50], del rango [51, 80] y del rango >=81, respectivamente. A continuación se muestran más consultas de ejemplo para distintos escenarios: 1. Consulta de la tabla completa: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition2. Consulta de una tabla con selección de columnas y filtros adicionales de la cláusula where: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>3. Consulta con subconsultas: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>4. Consulta con partición en subconsulta: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
Procedimientos recomendados para cargar datos con la opción de partición:
- Seleccione una columna distintiva como columna de partición (como clave principal o clave única) para evitar la asimetría de datos.
- Si la tabla tiene una partición integrada, use la opción de partición "Particiones físicas de tabla" para obtener un mejor rendimiento.
- Si usa Azure Integration Runtime para copiar datos, puede establecer "unidades de integración de datos (DIU)" mayores (>4) para usar más recursos de cálculo. Compruebe los escenarios aplicables allí.
- "Grado de paralelismo de copia" controla los números de partición. Si se establece en un número demasiado grande, puede resentirse el rendimiento, así que se recomienda establecerlo como (DIU o número de nodos de IR autohospedados) * (2 a 4).
Ejemplo: carga completa de una tabla grande con particiones físicas
"source": {
"type": "AzureSqlSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
Ejemplo: consulta con partición por rangos dinámica
"source": {
"type": "AzureSqlSource",
"query": "SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
Consulta de ejemplo para comprobar la partición física
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, pf.name AS PartitionFunctionName, c.name AS ColumnName, iif(pf.name is null, 'no', 'yes') AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON pf.function_id = ps.function_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
Si la tabla tiene una partición física, verá "HasPartition" como "yes" como en el caso siguiente.

Procedimiento recomendado para cargar datos en Azure SQL Database
Al copiar datos en Azure SQL Database, puede requerir un comportamiento de escritura diferente:
- Anexión: mis datos de origen solo tienen registros nuevos.
- Actualización e inserción: mis datos de origen tienen inserciones y actualizaciones.
- Sobrescritura: quiero recargar una tabla de dimensiones completa cada vez.
- Escritura con lógica personalizada: necesito un procesamiento adicional antes de la inserción final en la tabla de destino.
Consulte las secciones correspondientes sobre cómo configurar en el servicio y los procedimientos recomendados.
Anexión de datos
La anexión de datos es el comportamiento predeterminado de este conector de receptor de Azure SQL Database. El servicio realiza una inserción masiva para escribir en la tabla de forma eficaz. Puede configurar el origen y el receptor según corresponda en la actividad de copia.
Actualización e inserción de datos
La actividad de copia ahora admite la carga nativa de datos en una tabla temporal de base de datos y, a continuación, actualizar los datos en la tabla receptora si existe la clave y, de lo contrario, insertar nuevos datos. Para obtener más información sobre la configuración de upsert en las actividades de copia, consulte la sección Azure SQL Database como receptor.
Sobrescritura de toda la tabla
Puede configurar la propiedad preCopyScript en un receptor de la actividad de copia. En este caso, para cada actividad de copia que se ejecuta, el servicio ejecuta primero el script. Después, ejecuta la copia para insertar los datos. Por ejemplo, para sobrescribir toda la tabla con los datos más recientes, especifique un script para eliminar primero todos los registros antes de realizar la carga masiva de los nuevos datos desde el origen.
Escritura de datos con lógica personalizada
Los pasos necesarios para escribir datos con lógica personalizada son similares a los que se describen en la sección Actualización e inserción de datos. Si necesita aplicar procesamiento adicional antes de la inserción final de los datos de origen en la tabla de destino, puede cargarlos en una tabla de almacenamiento provisional y luego invocar una actividad de procedimiento almacenado, o invocar un procedimiento almacenado en un receptor de actividad de copia para aplicar datos, o usar un flujo de datos de asignación.
Invocación del procedimiento almacenado desde el receptor de SQL
Al copiar datos en Azure SQL Database, también se puede configurar e invocar un procedimiento almacenado especificado por el usuario con parámetros adicionales en cada lote de la tabla de origen. La característica de procedimiento almacenado aprovecha los parámetros con valores de tabla.
Cuando los mecanismos de copia integrados no prestan el servicio, se puede usar un procedimiento almacenado. Por ejemplo, si quiere aplicar un procesamiento adicional antes de la inserción final de los datos de origen en la tabla de destino. Otros ejemplos de procesamiento adicional son cuando quiere combinar columnas, buscar valores adicionales e insertar datos en más de una tabla.
En el ejemplo siguiente se muestra cómo usar un procedimiento almacenado para realizar una operación upsert en una tabla de Azure SQL Database. Supongamos que los datos de entrada y la tabla Marketing del receptor tienen tres columnas: ProfileID, State y Category. Realice una operación UPSERT en función de la columna ProfileID y aplíquela solo a una categoría específica llamada "ProductA".
En la base de datos, defina el tipo de tabla con el mismo nombre que sqlWriterTableType. El esquema del tipo de tabla es el mismo que el que devuelven los datos de entrada.
CREATE TYPE [dbo].[MarketingType] AS TABLE( [ProfileID] [varchar](256) NOT NULL, [State] [varchar](256) NOT NULL, [Category] [varchar](256) NOT NULL )En la base de datos, defina el procedimiento almacenado con el mismo nombre que sqlWriterStoredProcedureName. Dicho procedimiento administra los datos de entrada del origen especificado y los combina en la tabla de salida. El nombre del parámetro del tipo de tabla del procedimiento almacenado es el mismo que el de tableName que se ha definido en el conjunto de datos.
CREATE PROCEDURE spOverwriteMarketing @Marketing [dbo].[MarketingType] READONLY, @category varchar(256) AS BEGIN MERGE [dbo].[Marketing] AS target USING @Marketing AS source ON (target.ProfileID = source.ProfileID and target.Category = @category) WHEN MATCHED THEN UPDATE SET State = source.State WHEN NOT MATCHED THEN INSERT (ProfileID, State, Category) VALUES (source.ProfileID, source.State, source.Category); ENDEn la canalización de Azure Data Factory o Synapse, defina la sección del receptor SQL en la actividad de copia como se indica a continuación:
"sink": { "type": "AzureSqlSink", "sqlWriterStoredProcedureName": "spOverwriteMarketing", "storedProcedureTableTypeParameterName": "Marketing", "sqlWriterTableType": "MarketingType", "storedProcedureParameters": { "category": { "value": "ProductA" } } }
Al escribir datos en Azure SQL Database mediante el procedimiento almacenado, el receptor divide los datos de origen en mini lotes y, a continuación, realiza la inserción, por lo que la consulta adicional en el procedimiento almacenado se puede ejecutar varias veces. Si tienes la consulta para que se ejecute la actividad de copia antes de escribir datos en Azure SQL Database, no se recomienda agregarla al procedimiento almacenado, agrégala en el cuadro Precopiar script.
Propiedades de Asignación de instancias de Data Flow
Al transformar datos en el flujo de datos de asignación, puede leer y escribir en las tablas de Azure SQL Database. Para más información, vea la transformación de origen y la transformación de receptor en los flujos de datos de asignación.
Transformación de origen
La configuración específica de Azure SQL Database está disponible en la pestaña Source Options (Opciones de origen) de la transformación de origen.
Entrada: seleccione si desea señalar el origen en una tabla (equivale a Select * from <table-name>) o escribir una consulta SQL personalizada.
Consulta: Si selecciona Consulta en el campo de entrada, escriba una consulta SQL para el origen. Esta configuración invalidará cualquier tabla que haya elegido en el conjunto de datos. Las cláusulas Ordenar por no se admiten aquí, pero puede establecer una instrucción SELECT FROM completa. También puede usar las funciones de tabla definidas por el usuario. select * from udfGetData() es un UDF in SQL que devuelve una tabla. Esta consulta genera una tabla de origen que puede usar en el flujo de datos. El uso de consultas también es una excelente manera de reducir las filas para pruebas o búsquedas.
Sugerencia
La expresión de tabla común (CTE) de SQL no se admite en el modo de consulta del flujo de datos de asignación, ya que el requisito previo para usar este modo es que las consultas se pueden usar en la cláusula FROM de la consulta SQL, pero las CTE no pueden hacerlo. Para usar expresiones de tabla común, debe crear un procedimiento almacenado mediante la consulta siguiente:
CREATE PROC CTESP @query nvarchar(max)
AS
BEGIN
EXECUTE sp_executesql @query;
END
Luego, use el modo de procedimiento almacenado en la transformación de origen del flujo de datos de asignación y establezca @query como el ejemplo de with CTE as (select 'test' as a) select * from CTE. A continuación, puede usar las CTE según lo previsto.
Procedimiento almacenado: elija esta opción si desea generar una proyección y datos de origen a partir de un procedimiento almacenado que se ejecuta desde la base de datos de origen. Puede escribir el esquema, el nombre del procedimiento y los parámetros, o bien hacer clic en Actualizar para pedir al servicio que detecte los esquemas y los nombres de los procedimientos. Después, puede hacer clic en Importar para importar todos los parámetros de procedimiento mediante el formulario @paraName.
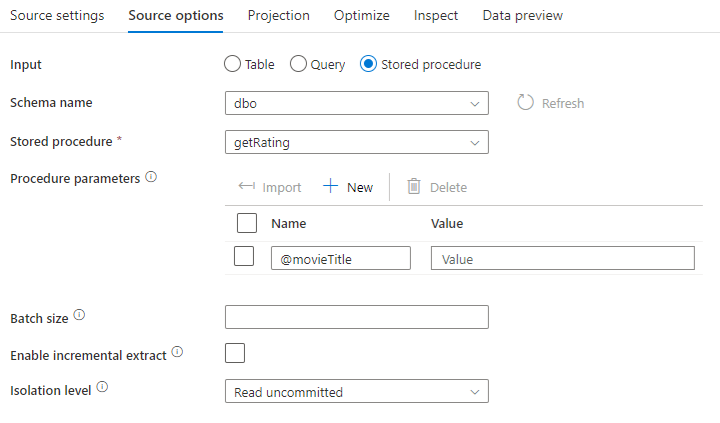
- Ejemplo de SQL:
Select * from MyTable where customerId > 1000 and customerId < 2000 - Ejemplo de SQL con parámetros:
"select * from {$tablename} where orderyear > {$year}"
Tamaño del lote: escriba un tamaño de lote para fragmentar datos grandes en lecturas.
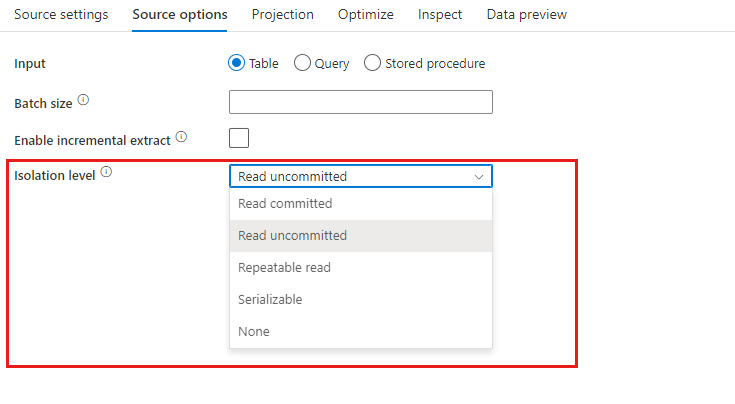
Nivel de aislamiento: El valor predeterminado de los orígenes de SQL en el flujo de datos de asignación es de lectura no confirmada. Puede cambiar el nivel de aislamiento aquí a uno de estos valores:
- Lectura confirmada
- Lectura no confirmada
- Lectura repetible
- Serializable
- Ninguno (ignorar el nivel de aislamiento)
Habilitar extracción incremental: use esta opción para indicar a ADF que procese solo las filas que hayan cambiado desde la última vez que se ejecutó la canalización. Para habilitar la extracción incremental con desfase de esquema, elija tablas basadas en columnas incrementales o de referencia en lugar de tablas habilitadas para la captura de datos modificados nativa.
Columna incremental: si se usa la característica de extracción incremental, es preciso elegir la columna numérica o de fecha y hora que desea se usar como marca de agua en la tabla de origen.
Habilitar captura de datos modificados nativos (versión preliminar): use esta opción para indicar a ADF que solo procese los datos delta capturados por la tecnología de captura de datos modificados de SQL desde la última vez que se ejecutó la canalización. Con esta opción, los datos delta, incluida la inserción de filas, su actualización y su eliminación, se cargarán automáticamente sin necesidad de ninguna columna incremental. Debe habilitar la captura de datos modificados en Azure SQL DB antes de usar esta opción en ADF. Para obtener más información sobre esta opción en ADF, consulte captura nativa de datos modificados.
Empezar a leer desde el principio: si se establece esta opción con extracción incremental, se indicará a ADF que lea todas las filas en la primera ejecución de una canalización con la extracción incremental activada.
Transformación de receptor
La configuración específica de Azure SQL Database está disponible en la pestaña Configuración de la transformación de receptor.
Método de actualización: determina qué operaciones se permiten en el destino de la base de datos. El valor predeterminado es permitir solamente las inserciones. Para realizar las operaciones update, upsert o delete rows, se requiere una transformación de alteración de filas para etiquetar esas acciones. En el caso de las actualizaciones, upserts y eliminaciones, se debe establecer una o varias columnas de clave para determinar la fila que se va a modificar.
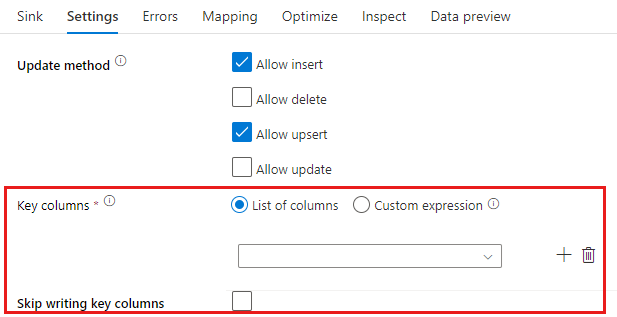
El nombre de columna que elija aquí como clave se usará en el servicio como parte de las operaciones posteriores de actualización, upsert y eliminación. Por lo tanto, debe seleccionar una columna que exista en la asignación del receptor. Si no quiere escribir el valor en esta columna de clave, haga clic en "Skip writing key columns" (Omitir escritura de columnas de clave).
Puede parametrizar la columna de clave que se usa aquí para actualizar la tabla de Azure SQL Database de destino. Si tiene varias columnas para una clave compuesta, haga clic en "Expresión personalizada" y podrá agregar contenido dinámico mediante el lenguaje de expresiones de flujo de datos del servicio, que puede incluir una matriz de cadenas con nombres de columna para una clave compuesta.
Acción de tabla: determina si se deben volver a crear o quitar todas las filas de la tabla de destino antes de escribir.
- None (Ninguna): no se realizará ninguna acción en la tabla.
- Recreate (Volver a crear): se quitará la tabla y se volverá a crear. Obligatorio si se crea una nueva tabla dinámicamente.
- Truncate (Truncar): se quitarán todas las filas de la tabla de destino.
Tamaño del lote: controla el número de filas que se escriben en cada cubo. Los tamaños de lote más grandes mejoran la compresión y la optimización de memoria, pero se arriesgan a obtener excepciones de memoria al almacenar datos en caché.
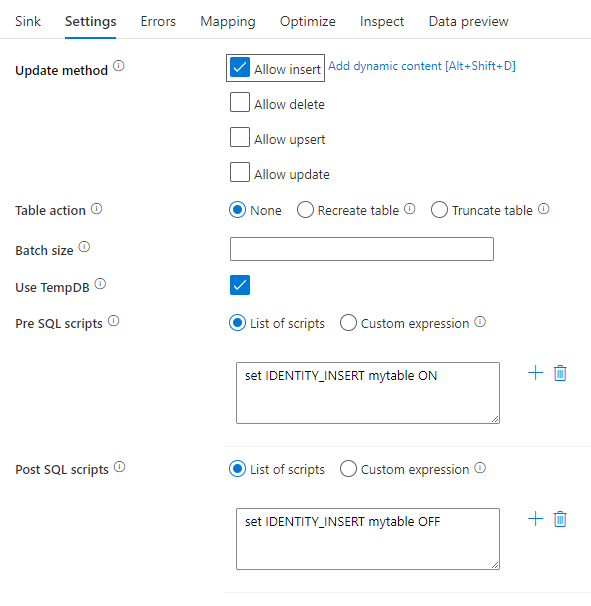
Usar TempDB: de manera predeterminada, Data Factory utilizará una tabla temporal global para almacenar los datos como parte del proceso de carga. También puede desactivar la opción "Usar TempDB" y, en su lugar, pedir al servicio que almacene la tabla de almacenamiento temporal en una base de datos de usuario que se encuentra en la base de datos que se utiliza para este receptor.

Scripts SQL anteriores y posteriores: escriba scripts de SQL de varias líneas que se ejecutarán antes (preprocesamiento) y después (procesamiento posterior) de que los datos se escriban en la base de datos del receptor
Sugerencia
- Se recomienda dividir los scripts por lotes únicos con varios comandos en varios lotes.
- Tan solo las instrucciones de lenguaje de definición de datos (DDL) y lenguaje de manipulación de datos (DML) que devuelven un recuento de actualizaciones sencillo se pueden ejecutar como parte de un lote. Obtenga más información en Realización de operaciones por lotes
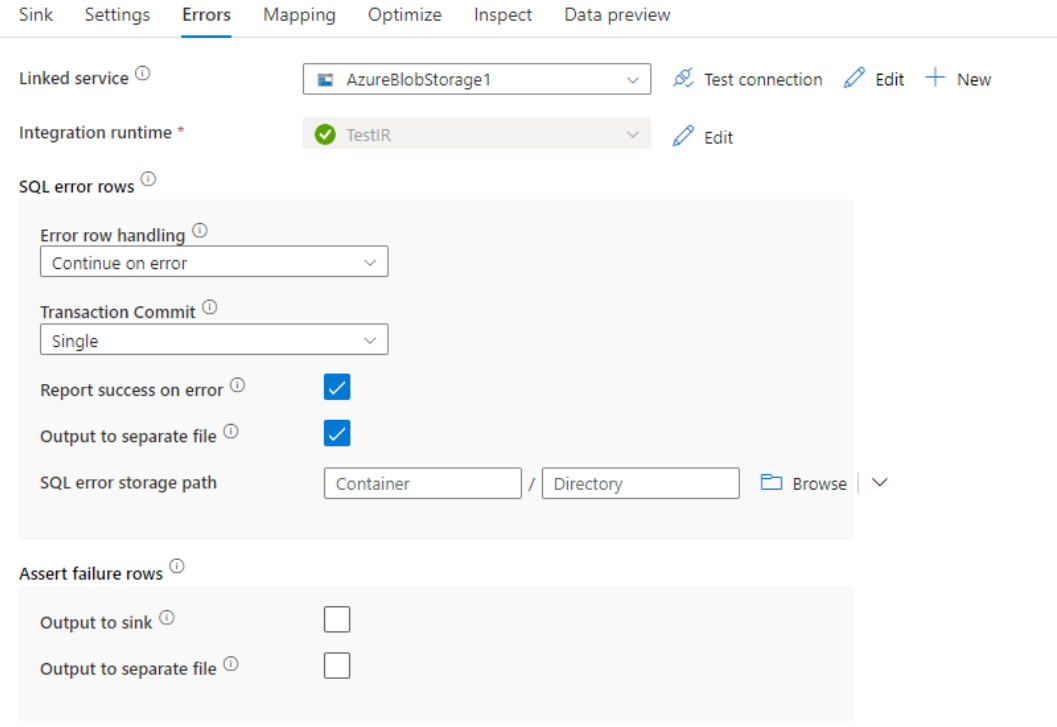
Control de filas de errores
Al escribir en la base de datos de Azure SQL, es posible que se produzcan errores en determinadas filas de datos debido a las restricciones establecidas por el destino. Estos son algunos de los errores comunes:
- Los datos binarios o de tipo cadena se truncarían en una tabla.
- No se puede insertar el valor NULL en la columna.
- La instrucción INSERT entra en conflicto con la restricción CHECK.
De forma predeterminada, la ejecución de un flujo de datos no funcionará al recibir el primer error. Puede optar por Continuar en caso de error, que permite que el flujo de datos se complete, aunque haya filas individuales con errores. El servicio proporciona diferentes opciones para controlar estas filas de error.
Confirmación de transacción: elija si los datos se escriben en una única transacción o en lotes. Una sola transacción proporcionará peor rendimiento, pero ningún dato escrito será visible para otros usuarios hasta que finalice la transacción.
Datos rechazados de salida: si está habilitado, puede generar las filas de error en un archivo CSV en Azure Blob Storage o en una cuenta de Azure Data Lake Storage Gen2 de su elección. Las filas de error se escribirán con tres columnas adicionales: la operación SQL, como INSERT o UPDATE, el código de error de flujo de datos y el mensaje de error de la fila.
Notificar éxito cuando hay error: si está habilitada, el flujo de datos se marcará como correcto, aunque se encuentren filas de error.
Asignación de tipos de Azure SQL Database
Al copiar datos desde o a Azure SQL Database, se utilizan las siguientes asignaciones de tipos de datos de Azure SQL Database en los tipos de datos provisionales de Azure Data Factory. La característica de canalización de Synapse usa las mismas asignaciones, que Azure Data Factory implementa directamente. Consulte el artículo sobre asignaciones de tipos de datos y esquema para más información sobre cómo la actividad de copia asigna el tipo de datos y el esquema de origen al receptor.
| Tipo de datos de Azure SQL Database | Tipo de datos provisionales de Data Factory |
|---|---|
| bigint | Int64 |
| binary | Byte[] |
| bit | Boolean |
| char | String, Char[] |
| date | DateTime |
| Datetime | DateTime |
| datetime2 | DateTime |
| Datetimeoffset | DateTimeOffset |
| Decimal | Decimal |
| Atributo FILESTREAM (varbinary(max)) | Byte[] |
| Float | Double |
| imagen | Byte[] |
| int | Int32 |
| money | Decimal |
| NCHAR | String, Char[] |
| ntext | String, Char[] |
| NUMERIC | Decimal |
| NVARCHAR | String, Char[] |
| real | Single |
| rowversion | Byte[] |
| smalldatetime | DateTime |
| SMALLINT | Int16 |
| SMALLMONEY | Decimal |
| sql_variant | Object |
| text | String, Char[] |
| time | TimeSpan |
| timestamp | Byte[] |
| TINYINT | Byte |
| UNIQUEIDENTIFIER | Guid |
| varbinary | Byte[] |
| varchar | String, Char[] |
| Xml | String |
Nota:
En el caso de los tipos de datos que se asignan al tipo decimal provisional, la actividad de copia actualmente admite una precisión de hasta 28. Si tiene datos con una precisión mayor de 28, considere la posibilidad de convertirlos en una cadena de consulta SQL.
Propiedades de la actividad de búsqueda
Para obtener información detallada sobre las propiedades, consulte Actividad de búsqueda.
Propiedades de la actividad GetMetadata
Para información detallada sobre las propiedades, consulte Actividad de obtención de metadatos.
Uso de Always Encrypted
Al copiar datos desde o en Azure SQL Database con Always Encrypted, siga estos pasos:
Almacene la clave maestra de columna (CMK) en una instancia de Azure Key Vault. Obtenga más información acerca de la configuración de Always Encrypted con Azure Key Vault
Asegúrese de obtener acceso al almacén de claves donde se almacena la clave maestra de columna (CMK). Consulte este artículo para obtener información acerca de los permisos necesarios.
Cree un servicio vinculado para conectarse a la base de datos SQL y habilitar la función "Always Encrypted" mediante una identidad administrada o una entidad de servicio.
Nota:
Always Encrypted de Azure SQL Database admite los siguientes escenarios:
- Los almacenes de datos de origen o receptores usan la identidad administrada o la entidad de servicio como tipo de autenticación del proveedor de claves.
- Los almacenes de datos de origen y receptores usan la identidad administrada como tipo de autenticación del proveedor de claves.
- Los almacenes de datos de origen y receptores usan la misma entidad de servicio como tipo de autenticación del proveedor de claves.
Nota:
Actualmente, Always Encrypted de Azure SQL Database no se admite para la transformación del receptor en flujos de datos de asignación.
Captura nativa de datos modificados
Azure Data Factory puede admitir capacidades de captura nativa de datos modificados para SQL Server, Azure SQL DB y Azure SQL MI. Los datos modificados, incluida la inserción, actualización y eliminación de filas en almacenes SQL, se pueden detectar y extraer automáticamente mediante el flujo de datos de asignación de ADF. Con la experiencia sin código en el flujo de datos de asignación, los usuarios pueden alcanzar fácilmente el escenario de replicación de datos desde almacenes SQL, anexando una base de datos como almacén de destino. Es más, los usuarios también pueden componer cualquier lógica de transformación de datos entre medias para lograr un escenario de ETL incremental desde almacenes SQL.
No debe cambiar el nombre de la canalización ni de la actividad para que ADF pueda registrar el punto de control y usted pueda obtener automáticamente los datos modificados desde la última ejecución. Si cambia el nombre de la canalización o de la actividad, el punto de control se restablecerá, por lo que tendría que empezar desde el principio u obtener los cambios que se realicen a partir de ese momento en la siguiente ejecución. Si desea cambiar el nombre de la canalización o el nombre de la actividad, pero mantener el punto de control para obtener automáticamente los datos modificados de la última ejecución, use su propia clave de punto de control en la actividad del flujo de datos.
Cuando se depura la canalización, esta característica funciona igual. Tenga en cuenta que el punto de control se restablecerá cuando se actualice el explorador durante la ejecución de depuración. Cuando esté conforme con el resultado de la canalización obtenida a partir de la ejecución de depuración, podrá publicar y desencadenar la canalización. En el momento en que desencadene por primera vez la canalización publicada, la canalización se reiniciará automáticamente desde el principio o se obtendrán los cambios a partir de ese momento.
Siempre puede volver a ejecutar la canalización en la sección de supervisión. Si lo hace, siempre se capturarán los datos modificados a partir del punto de control anterior de la ejecución de la canalización seleccionada.
Ejemplo 1:
Cuando encadene directamente una transformación de origen referenciada al conjunto de datos habilitado para CDC de SQL con una transformación de receptor referenciada a una base de datos en un flujo de datos de asignación, los cambios que se producen en el origen de SQL se aplicarán automáticamente a la base de datos de destino, de modo que obtendrá fácilmente el escenario de replicación de datos entre bases de datos. Puede usar el método de actualización en la transformación del receptor para seleccionar si desea permitir la inserción, la actualización o la eliminación en la base de datos de destino. El script de ejemplo en el flujo de datos de asignación es el siguiente.
source(output(
id as integer,
name as string
),
allowSchemaDrift: true,
validateSchema: false,
enableNativeCdc: true,
netChanges: true,
skipInitialLoad: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source1
source1 sink(allowSchemaDrift: true,
validateSchema: false,
deletable:true,
insertable:true,
updateable:true,
upsertable:true,
keys:['id'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true,
errorHandlingOption: 'stopOnFirstError') ~> sink1
Ejemplo 2:
Si quiere habilitar el escenario ETL en vez de la replicación de datos entre la base de datos a través de CDC de SQL, puede usar expresiones en el flujo de datos de asignación, incluidas isInsert(1), isUpdate(1) y isDelete(1), para diferenciar las filas con distintos tipos de operación. A continuación se muestra uno de los scripts de ejemplo para asignar flujos de datos en la derivación de una columna con el valor: 1 para indicar filas insertadas, 2 para indicar filas actualizadas y 3 para indicar filas eliminadas en las transformaciones de bajada para procesar los datos delta.
source(output(
id as integer,
name as string
),
allowSchemaDrift: true,
validateSchema: false,
enableNativeCdc: true,
netChanges: true,
skipInitialLoad: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source1
source1 derive(operationType = iif(isInsert(1), 1, iif(isUpdate(1), 2, 3))) ~> derivedColumn1
derivedColumn1 sink(allowSchemaDrift: true,
validateSchema: false,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> sink1
Limitación conocida:
- ADF cargará solo los cambios netos de CDC de SQL a través de cdc.fn_cdc_get_net_changes_.
Actualización de la versión de Azure SQL Database
Para actualizar la versión de Azure SQL Database, en la página Editar servicio vinculado, seleccione Recomendado en Versión y configure el servicio vinculado haciendo referencia a Propiedades del servicio vinculado para la versión recomendada.
Diferencias entre la versión recomendada y la heredada
En la tabla siguiente se muestran las diferencias entre la base de datos de Azure SQL con la versión recomendada y heredada.
| Versión recomendada | Versión heredada |
|---|---|
Admite TLS 1.3 a través de encrypt como strict. |
No se admite TLS 1.3. |
Contenido relacionado
Consulte los formatos y almacenes de datos compatibles para ver una lista de los almacenes de datos que la actividad de copia admite como orígenes y receptores.