Copia incremental de nuevos archivos por el nombre de archivo con particiones de tiempo mediante la herramienta Copiar datos
SE APLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga información sobre cómo iniciar una nueva evaluación gratuita.
En este tutorial, usará Azure Portal para crear una factoría de datos. Luego, use la herramienta Copiar datos para crear una canalización que copie incrementalmente los archivos nuevos por el nombre de archivo con particiones de tiempo de una instancia de Azure Blob Storage a otra.
Nota
Si no está familiarizado con Azure Data Factory, consulte Introducción a Azure Data Factory.
En este tutorial, realizará los siguientes pasos:
- Creación de una factoría de datos.
- Uso de la herramienta Copy Data para crear una canalización.
- Supervisión de las ejecuciones de canalización y actividad.
Requisitos previos
- Suscripción de Azure: Si no tiene una suscripción a Azure, cree una cuenta gratuita antes de empezar.
- Cuenta de almacenamiento de Azure: use Blob Storage como almacén de datos de origen y receptor. Si no dispone de una cuenta de almacenamiento de Azure, consulte las instrucciones de Creación de una cuenta de almacenamiento.
Crear dos contenedores en Azure Blob Storage
Haga lo siguiente para preparar su instancia de Blob Storage para el tutorial.
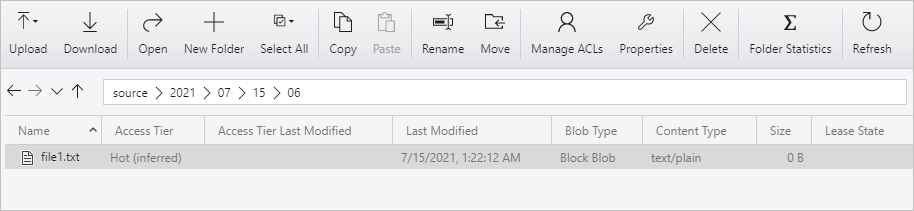
Cree un contenedor denominado source. Cree una ruta de acceso de carpeta, como 2021/07/15/06, en el contenedor. Cree un archivo de texto vacío y asígnele el nombre file1.txt. Cargue el archivo file1.txt en la ruta de acceso de carpeta source/2021/07/15/06 en su cuenta de almacenamiento. Puede usar varias herramientas para realizar estas tareas, como el Explorador de Azure Storage.
Nota
Ajuste el nombre de carpeta con la hora UTC correspondiente. Por ejemplo, si la hora UTC actual es 6:10 a. m. del 15 de julio de 2021, puede crear la ruta de acceso de carpeta como source/2021/07/15/06/ por la regla de source/{año}/{mes}/{día}/{hora}/ .
Cree un contenedor denominado destination. Puede usar varias herramientas para realizar estas tareas, como el Explorador de Azure Storage.
Crear una factoría de datos
En el menú de la izquierda, seleccione Crear un recurso>Integración>Data Factory:
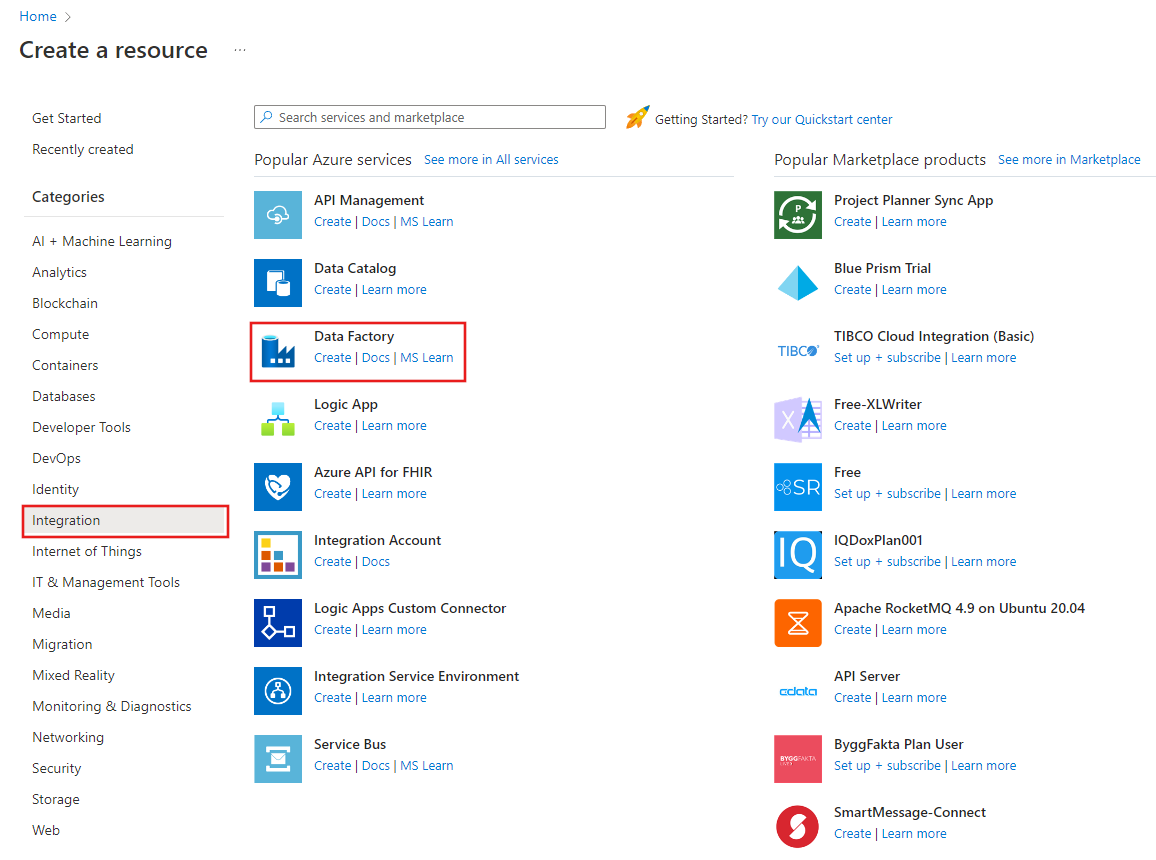
En la página Nueva factoría de datos, en Nombre, escriba ADFTutorialDataFactory.
El nombre de la factoría de datos debe ser globalmente único. Puede aparecer el siguiente mensaje de error:
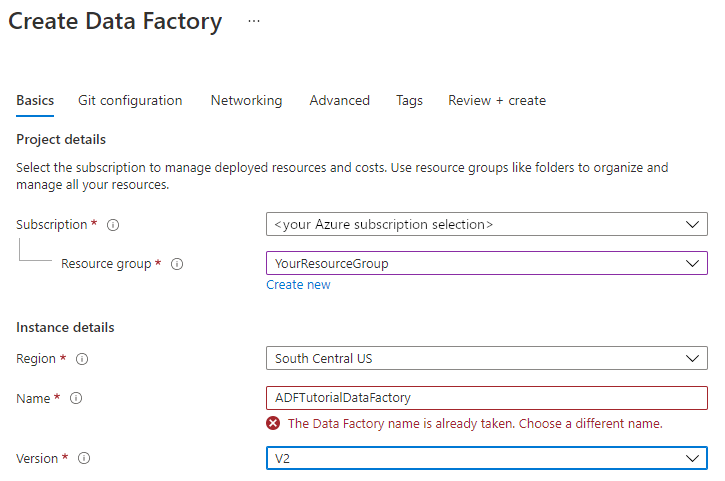
Si recibe un mensaje de error sobre el valor de nombre, escriba un nombre diferente para la factoría de datos. Por ejemplo, utilice suNombreADFTutorialDataFactory. Para conocer las reglas de nomenclatura de los artefactos de Data Factory, consulte Data Factory: reglas de nomenclatura.
Seleccione la suscripción de Azure en la que quiere crear la nueva factoría de datos.
Para Grupo de recursos, realice uno de los siguientes pasos:
a. Seleccione en primer lugar Usar existentey después un grupo de recursos de la lista desplegable.
b. Seleccione Crear nuevoy escriba el nombre de un grupo de recursos.
Para más información sobre los grupos de recursos, consulte Uso de grupos de recursos para administrar los recursos de Azure.
En Versión, seleccione V2 como versión.
En Ubicación, seleccione la ubicación de la factoría de datos. Solo las ubicaciones admitidas se muestran en la lista desplegable. Los almacenes de datos (por ejemplo, Azure Storage y SQL Database) y los procesos (por ejemplo, Azure HDInsight) que usa la factoría de datos pueden estar en otras ubicaciones o regiones.
Seleccione Crear.
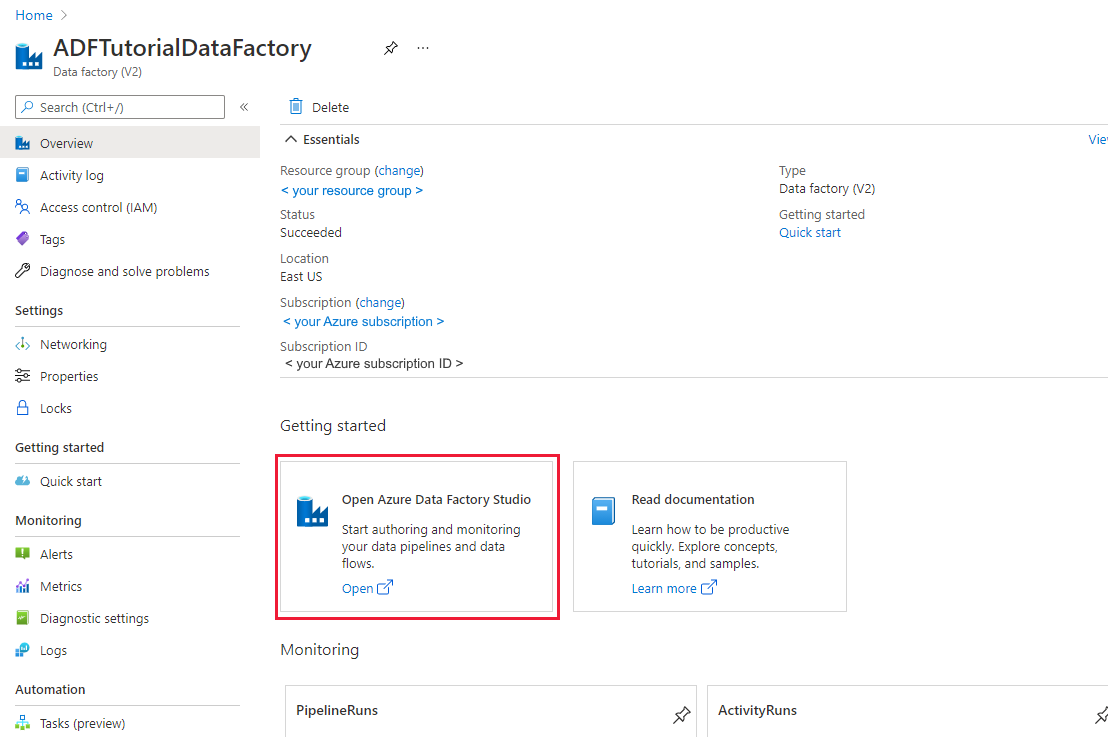
Una vez finalizada la creación, se muestra la página principal de Data Factory.
Para iniciar la aplicación de interfaz de usuario (IU) de Azure Data Factory en una pestaña independiente del explorador, seleccione Abrir en el icono Abrir Azure Data Factory Studio.
Uso de la herramienta Copy Data para crear una canalización
En la página principal de Azure Data Factory, seleccione el título Ingerir para iniciar la herramienta Copiar datos.
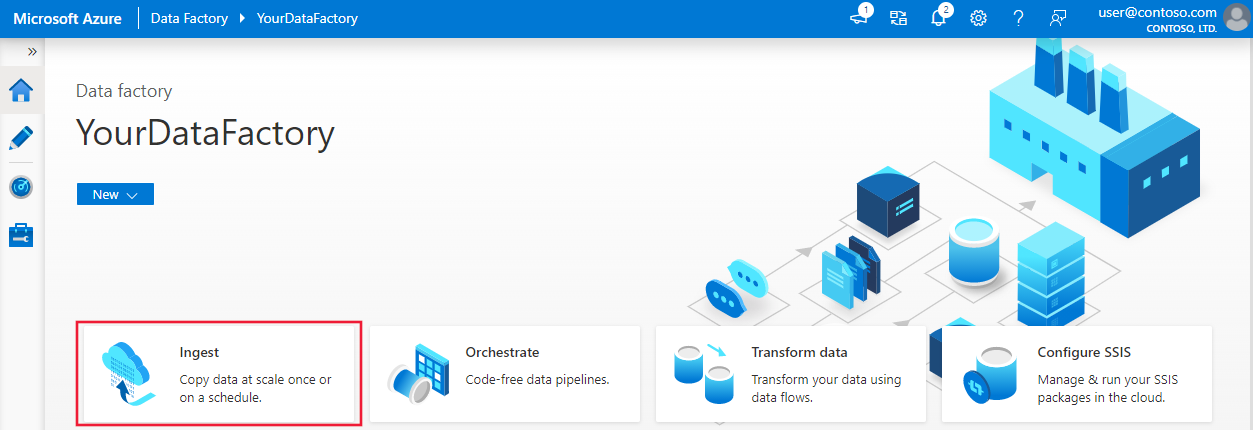
En la página Propiedades, realice los pasos siguientes:
En Tipo de tarea, elija Built-in copy task (Tarea de copia integrada).
En Task cadence or task schedule (Cadencia de tareas o programación de tareas), seleccione Ventana de saltos de tamaño constante.
En Periodicidad, establezca 1 hora.
Seleccione Next (Siguiente).
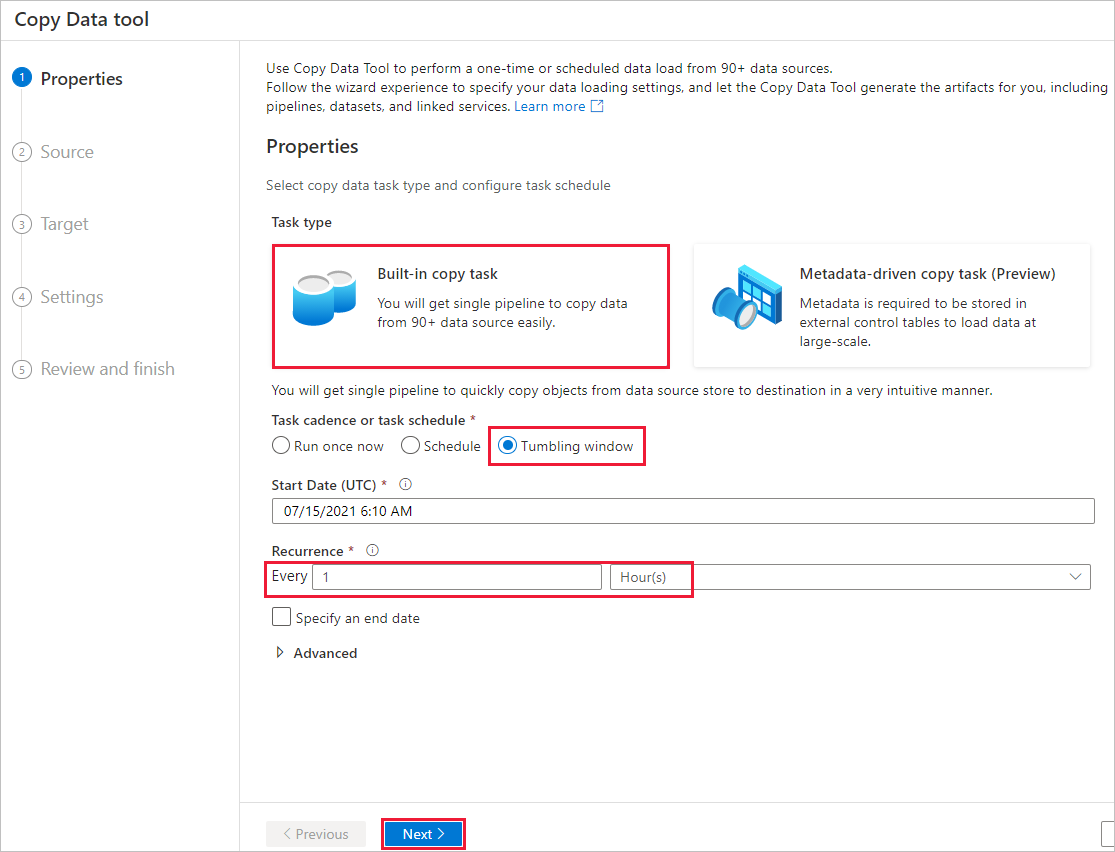
En la página Almacén de datos de origen, realice los pasos siguientes:
a. Seleccione + Nueva conexión para agregar una conexión.
b. Seleccione Azure Blob Storage en la galería y, a continuación, seleccione Continue (Continuar).
c. En la página Nueva conexión (Azure Blob Storage) , escriba un nombre para la conexión. Seleccione la suscripción a Azure y, a continuación, su cuenta de almacenamiento de la lista Nombre de la cuenta de almacenamiento. Pruebe la conexión y, después, seleccione Create (Crear).
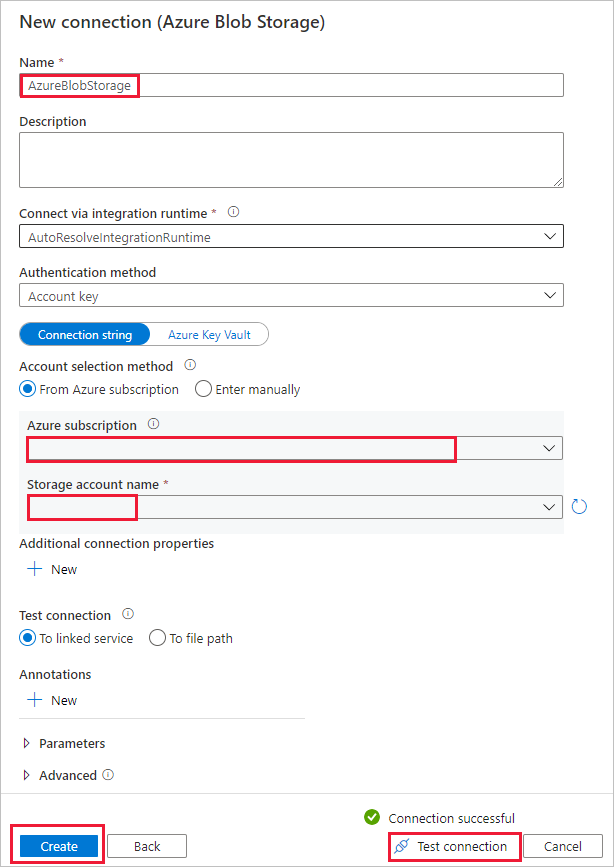
d. En la página Almacén de datos de origen, seleccione la conexión recién creada en la sección Conexión.
e. En la sección Archivo o carpeta, busque y seleccione el contenedor source y, luego, seleccione Aceptar.
f. En File loading behavior (Comportamiento de carga de archivos), seleccione Incremental load: time-partitioned folder/file names (Carga Incremental: nombres de archivo/carpeta con particiones de tiempo).
g. Escriba la ruta de acceso de carpeta dinámica como source/{año}/{mes}/{día}/{hora}/ y cambie el formato según se muestra en la captura de pantalla siguiente.
h. Seleccione Binary copy (Copia binaria) y seleccione Next (Siguiente).
En la página Almacén de datos de destino, realice los pasos siguientes:
Seleccione el elemento AzureBlobStorage, que es la misma cuenta de almacenamiento que el almacén de origen de datos.
Busque y seleccione la carpeta destination y, después, seleccione Aceptar.
Escriba la ruta de acceso de carpeta dinámica como destination/{año}/{mes}/{día}/{hora}/ y cambie el formato según se muestra en la captura de pantalla siguiente.
Seleccione Siguiente.
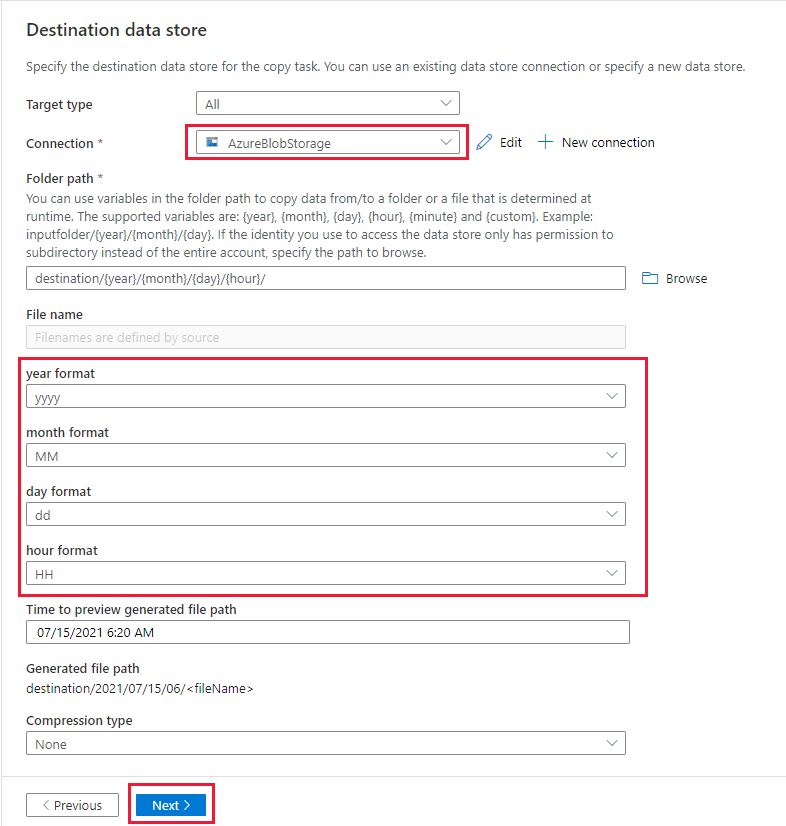
En la página Configuración, en Nombre de tarea, escriba DeltaCopyFromBlobPipeline y, a continuación, seleccione Siguiente. La interfaz de usuario de Data Factory crea una canalización con el nombre de la tarea especificado.
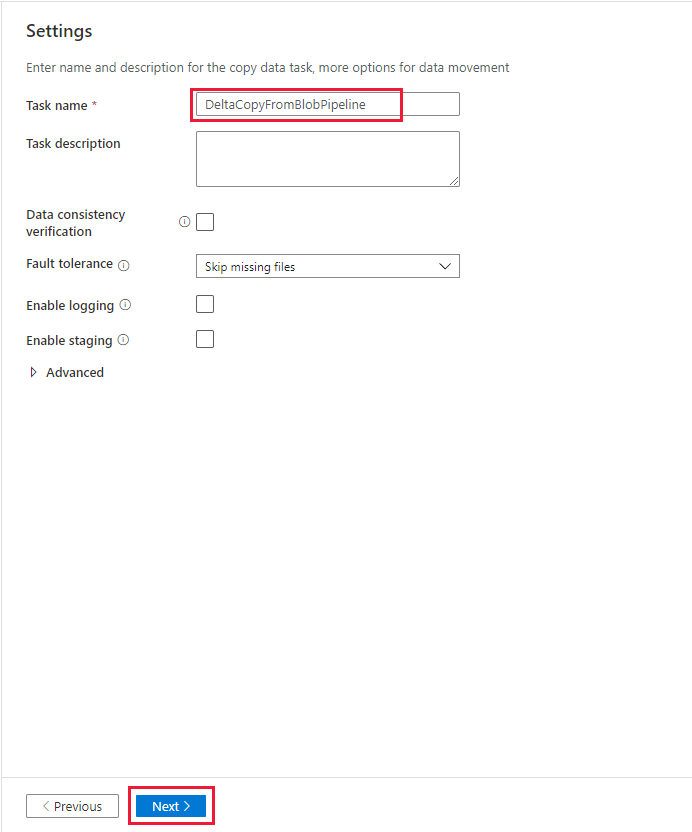
En la página Summary (Resumen), revise la configuración y seleccione Next (Siguiente).
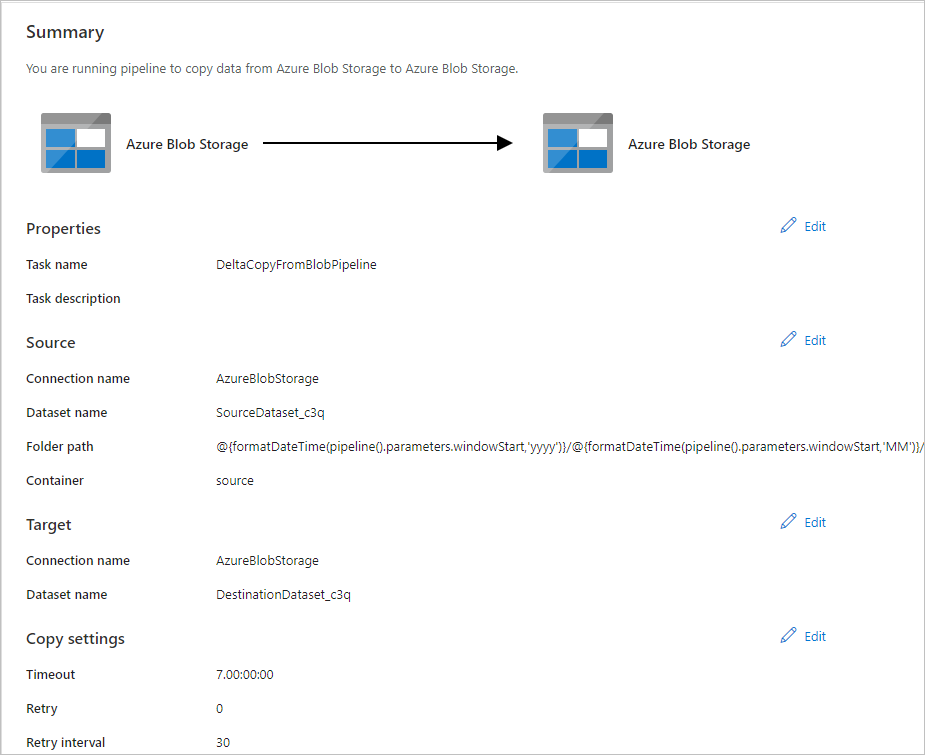
En la página Implementación, seleccione Monitor para supervisar la canalización (tarea).
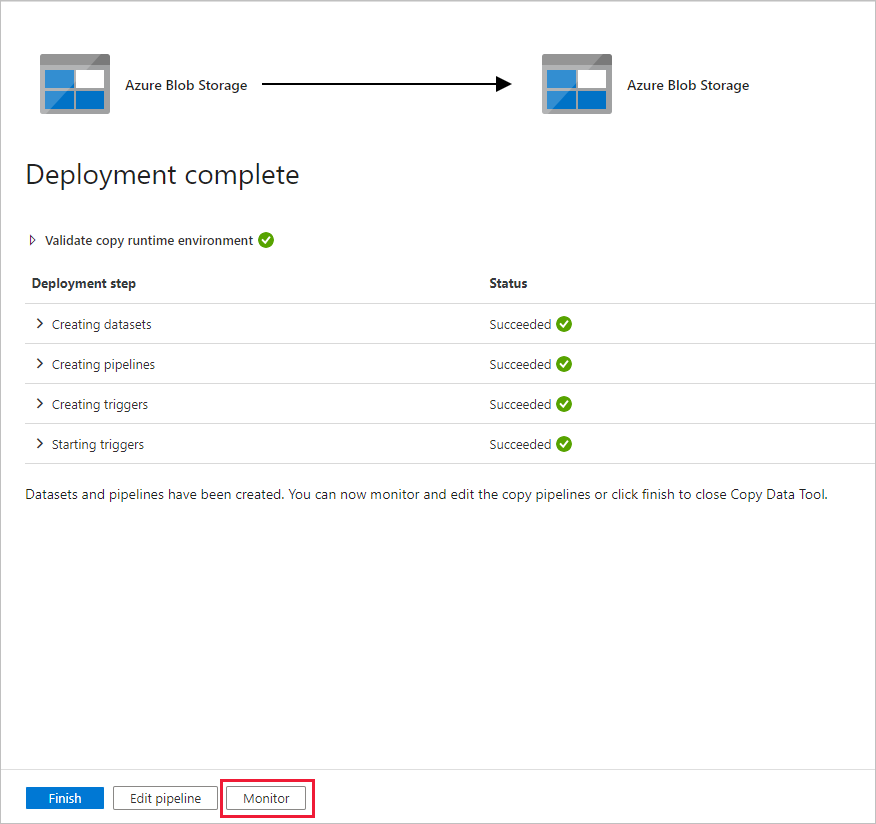
Observe que la pestaña Monitor (Supervisión) de la izquierda se selecciona automáticamente. Debe esperar a que la canalización se ejecute cuando se desencadene automáticamente (después de una hora aproximadamente). Cuando se ejecute, seleccione el vínculo del nombre de canalización DeltaCopyFromBlobPipeline para ver los detalles de la ejecución de la actividad o vuelva a ejecutar la canalización. Seleccione Refresh (Actualizar) para actualizar la lista.
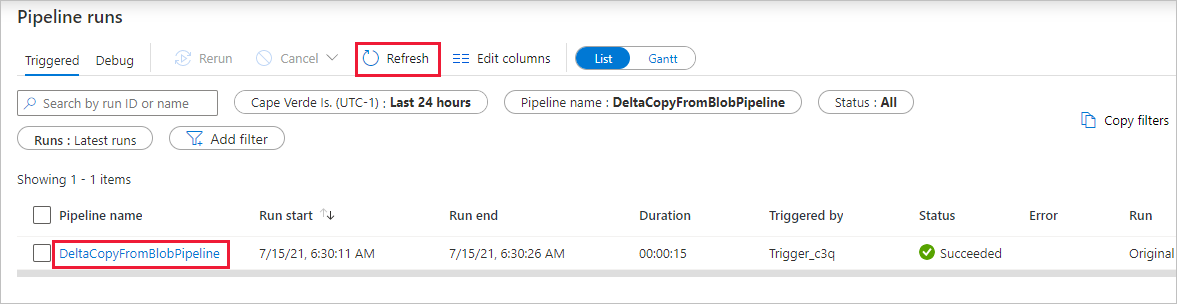
Como solo hay una actividad (actividad de copia) en la canalización, solo verá una entrada. Ajuste el ancho de columna de la columnas de origen y destino (si es necesario) para mostrar más detalles. Puede ver que el archivo de origen (file1.txt) se ha copiado de source/2021/07/15/06/ a destination/2021/07/15/06/ con el mismo nombre de archivo.
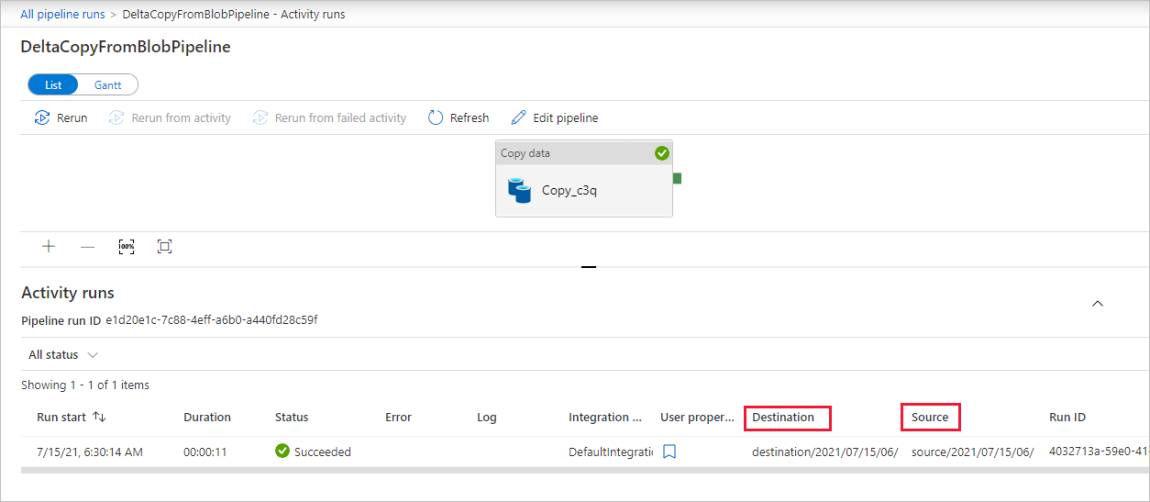
Esto también se puede confirmar con el Explorador de Azure Storage (https://storageexplorer.com/) para examinar los archivos.
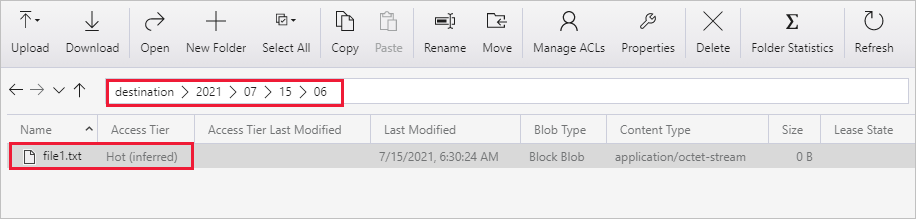
Cree otro archivo de texto vacío con el nuevo nombre file2.txt. Cargue el archivo file2.txt en la ruta de acceso de carpeta source/2021/07/15/07 de su cuenta de almacenamiento. Puede usar varias herramientas para realizar estas tareas, como el Explorador de Azure Storage.
Nota
Es posible que ya sepa que debe crear una nueva ruta de acceso de carpeta. Ajuste el nombre de carpeta con la hora UTC correspondiente. Por ejemplo, si la hora UTC actual es las 7:30 a. m. del 15 de julio de 2021, puede crear la ruta de acceso de carpeta como source/2021/07/15/07/ por la regla de {año}/{mes}/{día}/{hora}/ .
Para volver a la vista Ejecuciones de canalización, seleccione Todas las ejecuciones de la canalización, y espere a que la misma canalización se desencadene de nuevo automáticamente al cabo de una hora.
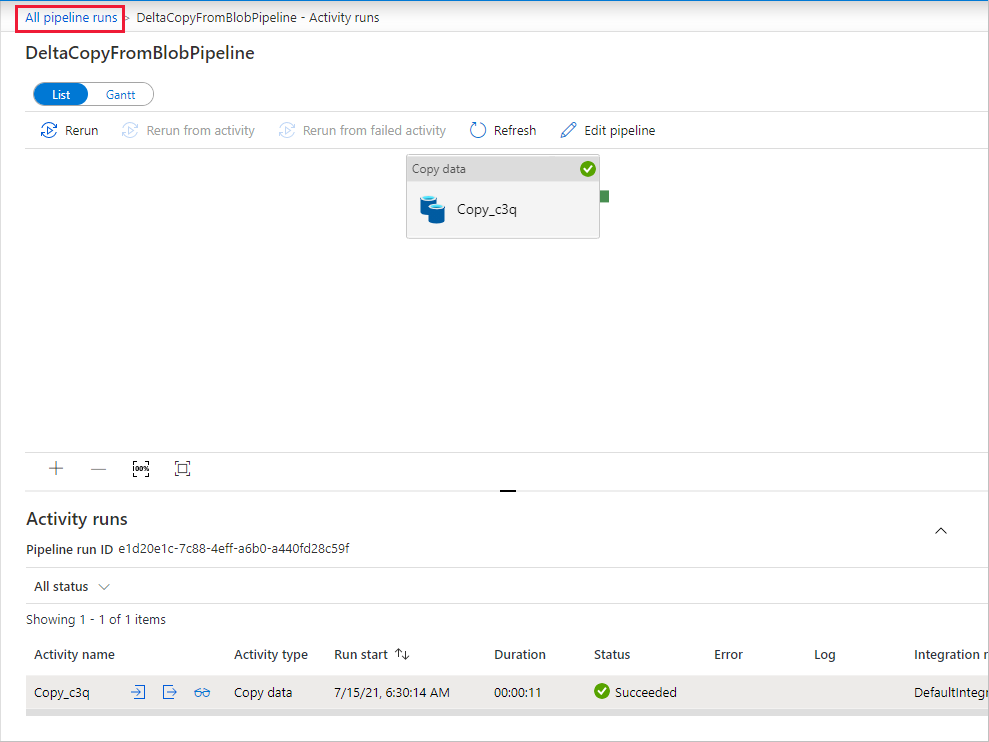
Seleccione el nuevo vínculo DeltaCopyFromBlobPipeline para la segunda ejecución de canalización cuando se realice y repita el proceso para revisar los detalles. Puede ver que el archivo de origen (file2.txt) se ha copiado de source/2021/07/15/07/ a destination/2021/07/15/07/ con el mismo nombre de archivo. Esto también se puede confirmar con el Explorador de Azure Storage (https://storageexplorer.com/) para examinar los archivos en el contenedor destination.
Contenido relacionado
Pase al tutorial siguiente para obtener información acerca de la transformación de datos mediante el uso de un clúster de Spark en Azure: