Configuración de clústeres en HDInsight con Apache Hadoop, Apache Spark, Apache Kafka, etc.
Aprenda a instalar y configurar Apache Hadoop, Apache Spark, Apache Kafka, Interactive Query o Apache HBase, o en HDInsight. Además, aprenda a personalizar clústeres y a aumentar la seguridad al asociarlos a un dominio.
Un clúster de Hadoop se compone de varias máquinas virtuales (nodos) que se usan para el procesamiento distribuido de tareas. Azure HDInsight se ocupa de los detalles de implementación de la instalación y configuración de los nodos individuales, por lo que solo tiene que proporcionar información de configuración general.
Importante
La facturación del clúster de HDInsight se inicia una vez creado el clúster y solo se detiene cuando se elimina. Se facturan por minuto realizando una prorrata, por lo que siempre debe eliminar aquellos que ya no se estén utilizando. Aprenda a eliminar un clúster.
Si usa varios clústeres juntos, querrá crear una red virtual y, si está usando un clúster de Spark, también querrá usar Hive Warehouse Connector. Para más información, consulte Planificación de una red virtual para Azure HDInsight e Integración de Apache Spark y Apache Hive con el conector de Hive Warehouse.
Métodos de configuración de clústeres
La tabla siguiente muestra los distintos métodos que se pueden usar para configurar un clúster de HDInsight.
| Clústeres creados con | Explorador web | Línea de comandos | API DE REST | SDK |
|---|---|---|---|---|
| Azure Portal | ✅ | |||
| Azure Data Factory | ✅ | ✅ | ✅ | ✅ |
| CLI de Azure | ✅ | |||
| Azure PowerShell | ✅ | |||
| cURL | ✅ | ✅ | ||
| Plantillas del Administrador de recursos de Azure | ✅ |
Este artículo le guía a lo largo del proceso de configuración en Azure Portal, donde puede crear un clúster de HDInsight.
Aspectos básicos
Detalles del proyecto
Azure Resource Manager lo ayuda a trabajar con los recursos de la aplicación como grupo, al que se conoce como grupo de recursos de Azure. Puede implementar, actualizar, supervisar o eliminar todos los recursos de la aplicación en una operación única y coordinada.
Detalles del clúster
Nombre del clúster
Los nombres de clúster de HDInsight tienen las siguientes restricciones:
- Caracteres permitidos: a-z, 0-9, A-Z
- Longitud máxima: 59
- Nombres reservados: aplicaciones
- El ámbito de nombres del clúster es común para todo Azure, para todas las suscripciones. Por lo tanto, el nombre del clúster debe ser único en todo el mundo.
- Los seis primeros caracteres deben ser únicos en una red virtual.
Region
No es preciso que especifique la ubicación del clúster explícitamente: El clúster se encuentra en la misma ubicación que el almacenamiento predeterminado. Si desea obtener una lista de las regiones admitidas, seleccione la lista desplegable Región en Precios de HDInsight.
Tipo de clúster
Actualmente, Azure HDInsight proporciona los siguientes tipos de clúster, cada uno de ellos con un conjunto de componentes que ofrecen determinadas funcionalidades.
Importante
Los clústeres de HDInsight están disponibles en distintos tipos, cada uno de ellos para una carga de trabajo o una tecnología única. No hay ningún método admitido para crear un solo clúster que combine varios tipos, como HBase en un clúster. Si la solución requiere tecnologías repartidas entre varios tipos de clústeres de HDInsight, una red virtual de Azure puede conectar los tipos de clústeres necesarios.
| Tipo de clúster | Funcionalidad |
|---|---|
| Hadoop | Consulta por lotes y análisis de datos almacenados |
| HBase | Procesamiento de grandes cantidades de datos no SQL sin esquema |
| Interactive Query | Almacenamiento en caché en memoria para realizar consultas de Hive interactivas y más rápidas |
| Kafka | Una plataforma de streaming distribuida que se puede utilizar para compilar aplicaciones y canalizaciones de datos de streaming en tiempo real. |
| Spark | Procesamiento en memoria, consultas interactivas, procesamiento de transmisión de microlotes |
Versión
Elija la versión de HDInsight para este clúster. Para más información, consulte Versiones compatibles de HDInsight.
Credenciales del clúster
Con los clústeres de HDInsight, puede configurar dos cuentas de usuario durante la creación del clúster:
- Nombre de usuario de inicio de sesión del clúster: El nombre de usuario predeterminado es admin. Emplea la configuración básica en el portal de Azure. A veces, se denomina "Usuario de clúster" o "usuario HTTP".
- Nombre de usuario de Secure Shell (SSH): se usa para conectarse al clúster mediante SSH. Para más información, consulte Uso SSH con HDInsight.
El nombre de usuario de HTTP tiene las siguientes restricciones:
- Caracteres especiales que se permiten:
_y@ - Caracteres no permitidos:
#;."',/:!*?$(){}[]<>|&---=+%~^space' - Longitud máxima: 20
El nombre de usuario de SSH tiene las siguientes restricciones:
- Caracteres especiales que se permiten:
_y@ - Caracteres no permitidos:
#;."',/:!*?$(){}[]<>|&---=+%~^space' - Longitud máxima: 64
- Nombres reservados: hadoop, users, oozie, hive, mapred, ambari-qa, zookeeper, tez, hdfs, sqoop, yarn, hcat, ams, hbase, administrator, admin, user, user1, test, user2, test1, user3, admin1, 1, 123, a, a,
actuser, adm, admin2, aspnet, backup, console, David, guest, John, owner, root, server, sql, support, support_388945a0, sys, test2, test3, user4, user5, spark
Storage

Aunque una instalación local de Hadoop usa el sistema de archivos distribuido de Hadoop (HDFS) para el almacenamiento en el clúster, en la nube se usan puntos de conexión de almacenamiento conectados al clúster. El empleo de almacenamiento en la nube significa que puede eliminar con seguridad los clústeres de HDInsight usados para el cálculo y, al mismo tiempo, conservar los datos.
Los clústeres de HDInsight pueden usar las siguientes opciones de almacenamiento:
- Azure Data Lake Storage Gen2
- Azure Storage de uso general v2
-
- Blob en bloques de Azure Storage (solo se admite como almacenamiento secundario)
Para más información sobre las opciones de almacenamiento con HDInsight, consulte Comparación de opciones de almacenamiento para usar con clústeres de Azure HDInsight.
Advertencia
No se admite el uso de una cuenta de almacenamiento adicional en una ubicación diferente a la del clúster de HDInsight.
Durante la configuración se especifica un contenedor de blobs de una cuenta de Azure Storage o de Data Lake Storage para el punto de conexión de almacenamiento predeterminado. El almacenamiento predeterminado contiene los registros del sistema y de la aplicación. De manera opcional, puede especificar más cuentas vinculadas de Azure Storage y cuentas de Data Lake Storage a las que el clúster pueda acceder. El clúster de HDInsight y las cuentas de almacenamiento dependientes deben estar en la misma ubicación de Azure.
Nota
La característica que requiere una transferencia segura aplica todas las solicitudes a su cuenta mediante una conexión segura. Esta característica solo es compatible con la versión de clúster de HDInsight 3.6 o posterior. Para más información, consulte Creación de un clúster de Apache Hadoop con cuentas de almacenamiento de transferencia segura en Azure HDInsight.
Importante
Habilitar la transferencia segura del almacenamiento después de crear un clúster puede producir errores al usar la cuenta de almacenamiento, por lo que no se recomienda. Es mejor crear un clúster mediante una cuenta de almacenamiento que ya tenga habilitada la transferencia segura.
Nota
Azure HDInsight no transfiere, mueve ni copia automáticamente los datos almacenados en Azure Storage de una región a otra.
Configuración de metastores
Puede crear tiendas de metadatos opcionales de Hive o Apache Oozie. Pero no todos los tipos de clúster admiten las tiendas de metadatos; además, Azure Synapse Analytics no es compatible con ellas.
Para más información, consulte Use external metadata stores in Azure HDInsight (Uso de almacenes externos de metadatos en Azure HDInsight).
Importante
Cuando cree una tienda de metadatos personalizada, no use guiones ni espacios en el nombre de la base de datos. Podría provocar que el proceso de creación del clúster diera error.
Base de datos SQL para Hive
Si quiere conservar las tablas de Hive después de eliminar un clúster de HDInsight, use una tienda de metadatos personalizada. Luego puede adjuntar la tienda de metadatos a otro clúster de HDInsight.
Un metastore de HDInsight creado para una versión del clúster de HDInsight no se puede compartir entre diferentes versiones del clúster de HDInsight. Para obtener una lista de versiones de HDInsight, consulte Versiones compatibles de HDInsight.
Importante
El metastore predeterminado proporciona una instancia de Azure SQL Database con un límite de 5 DTU de nivel básico (no actualizable) . Esto resulta adecuado para la realización de pruebas básicas. En el caso de las cargas de trabajo de producción o de gran volumen, se recomienda migrar a un metastore externo.
Base de datos SQL para Oozie
Para aumentar el rendimiento al usar Oozie, utilice un Metastore personalizado. Una tienda de metadatos también puede proporcionar acceso a datos de trabajo de Oozie después de eliminar el clúster.
Base de datos SQL para Ambari
Ambari se usa para supervisar clústeres de HDInsight, realizar cambios en la configuración y almacenar información de administración del clúster, así como el historial de trabajos. La característica de bases de datos personalizadas de Ambari permite implementar un nuevo clúster y configurar Ambari en una base de datos externa que usted administra. Para obtener más información, consulte Base de datos de Ambari personalizada.
Importante
No puede volver a usar un Oozie Metastore personalizado. Para usar un Oozie Metastore personalizado, debe proporcionar una base de datos de Azure SQL vacía al crear el clúster HDInsight.
Seguridad y redes

Paquete de seguridad de la empresa
Para los tipos de clúster de Hadoop, Spark, HBase, Kafka e Interactive Query, puede elegir la opción para habilitar Enterprise Security Package. Este paquete proporciona la opción de tener una configuración de clúster más segura mediante Apache Ranger e integrar con Microsoft Entra ID. Para más información, consulte el Introducción a la seguridad de la empresa en Azure HDInsight.
El paquete de seguridad de la empresa le permite integrar HDInsight con Active Directory y Apache Ranger. Se pueden crear varios usuarios con el paquete de seguridad de la empresa.
Para más información sobre la creación de un clúster de HDInsight unido a un dominio, consulte la creación de un entorno de espacio aislado de HDInsight unido a un dominio.
TLS
Para más información, consulte Seguridad de la capa de transporte.
Virtual network
Si la solución requiere tecnologías repartidas entre varios tipos de clústeres de HDInsight, una red virtual de Azure puede conectar los tipos de clústeres necesarios. Esta configuración permite que los clústeres, y cualquier otro código que se implemente en ellos, se comuniquen directamente entre sí.
Para más información acerca del uso de una red virtual de Azure con HDInsight, consulte Planeamiento de una red virtual para HDInsight.
Para ver un ejemplo de cómo usar dos tipos de clúster en una red virtual de Azure, consulte Uso del flujo estructurado de Apache Spark con Apache Kafka en HDInsight. Para más información acerca del uso de HDInsight con una red virtual, incluidos los requisitos de configuración específicos de la red virtual, consulte Planeamiento de una red virtual para HDInsight.
Configuración de cifrado de disco
Para obtener más información, consulte Cifrado de disco mediante claves administradas por el cliente.
Proxy de REST de Kafka
Esta opción solo está disponible para el tipo de clúster Kafka. Para más información, consulte Uso de un proxy de REST.
Identidad
Para obtener más información, consulte Identidades administradas en Azure HDInsight.
Configuración y precios

Mientras que exista el clúster, se le facturará por el uso de nodos. La facturación se inicia una vez creado el clúster y se detiene cuando se elimina el clúster. Los clústeres no se puede desasignar ni ponerse en espera.
Configuración del nodo
Cada tipo de clúster tiene su propio número de nodos, terminología para los nodos y tamaño de máquina virtual predeterminado. En la siguiente tabla, el número de nodos de cada tipo de nodo se muestra entre paréntesis.
| Tipo | Nodos | Diagrama |
|---|---|---|
| Hadoop | Nodo principal (2), nodo de trabajo (1+) | 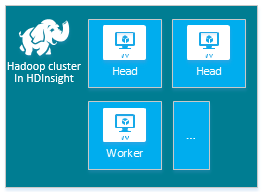
|
| HBase | Servidor principal (2), servidor de región (más de 1), nodo maestro/ZooKeeper (3) | 
|
| Spark | Nodo principal (2), nodo de trabajo (más de 1), nodo ZooKeeper (3) (gratis para el tamaño de máquina virtual ZooKeeper A1) | 
|
Para más información, vea Configuración de nodo predeterminada y tamaños de máquina virtual para clústeres en "¿Cuáles son los componentes y versiones de Hadoop disponibles con HDInsight?"
El costo de los clústeres de HDInsight viene determinado por el número de nodos y por los tamaños de las máquinas virtuales de los nodos.
Los distintos tipos de clúster tienen distintos tipos, número y tamaños de nodos:
- Tipo de clúster predeterminado de Hadoop:
Dos nodos principales
Cuatro nodos de trabajo
Si simplemente está probando HDInsight, se recomienda usar un nodo de trabajo. Para más información sobre los precios de HDInsight, vea HDInsight Precios.
Nota
El límite de tamaño del clúster varía entre las suscripciones a Azure. Póngase en contacto con el servicio de soporte técnico de facturación de Azure para aumentar el límite.
Al usar Azure Portal para configurar el clúster, el tamaño del nodo está disponible en la pestaña Configuración y precios. En el portal también puede ver el costo asociado a los diferentes tamaños de nodo.
Tamaños de máquina virtual
Al implementar clústeres, elija los recursos de proceso en función de la solución que tenga previsto implementar. Las máquinas virtuales siguientes se usan para clústeres de HDInsight:
- Máquinas virtuales de las series A y D1-4: Tamaños de máquinas virtuales Linux para uso general
- Máquinas virtuales de la serie D11-14: Tamaños de máquinas virtuales Linux optimizadas para memoria
Para averiguar el valor que debe usar para especificar un tamaño de máquina virtual durante la creación de un clúster mediante los distintos SDK o mientras usa Azure PowerShell, vea Tamaños de máquina virtual para clústeres de HDInsight. Use el valor de la columna Tamaño de las tablas de este artículo vinculado.
Importante
Si necesita más de 32 nodos de trabajo en un clúster, tiene que seleccionar un tamaño de nodo principal con al menos 8 núcleos y 14 GB de RAM.
Para más información, consulte Tamaños de las máquinas virtuales Linux en Azure. Para más información sobre los precios de los diferentes tamaños, consulte Precios de HDInsight.
Conexión de discos
Nota
Los discos agregados solo están configurados para los directorios locales del administrador de nodos y no para los directorios de nodos de datos
El clúster de HDInsight incluye espacio en disco predefinido basado en SKU. Si ejecuta algunas aplicaciones grandes, puede provocar un espacio en disco insuficiente, con un error completo en el disco: LinkId=221672#ERROR_NOT_ENOUGH_DISK_SPACE y errores de trabajos.
Se pueden agregar más discos al clúster con el nuevo directorio local de NodeManager de la característica. En el momento de la creación del clúster de Hive y Spark, se puede seleccionar y agregar el número de discos a los nodos de trabajo. El disco seleccionado, que tendrá un tamaño de 1 TB cada uno, formaría parte de los directorios locales de NodeManager.
- En la pestaña Configuración y precios
- Seleccione la opción Habilitar disco administrado.
- En Discos estándar, escriba el Número de discos.
- Elija el Nodo de trabajo.
Puede comprobar el número de discos en la pestaña Revisar y crear, en Configuración del clúster.
Agregar aplicación
Una aplicación de HDInsight es aquella que los usuarios pueden instalar en un clúster de HDInsight basado en Linux. Puede usar aplicaciones proporcionadas por Microsoft, de terceros o desarrolladas por usted. Para más información, consulte Instalación de aplicaciones de Apache Hadoop de terceros en Azure HDInsight.
La mayoría de las aplicaciones de HDInsight se instalan en un nodo perimetral vacío. Un nodo perimetral vacío es una máquina virtual Linux con las mismas herramientas cliente instaladas y configuradas que en el nodo principal. Se puede usar el nodo perimetral para acceder al clúster y para probar y hospedar las aplicaciones cliente. Para obtener más información, consulte Uso de nodos perimetrales vacíos en HDInsight.
Acciones de script
Puede instalar componentes adicionales o personalizar la configuración del clúster mediante el uso de scripts durante la creación. Tales scripts se invocan mediante la opción de Acción de script, una opción de configuración que se puede usar a partir de los cmdlets de Windows PowerShell de HDInsight, en el Portal de Azure o el SDK de .NET para HDInsight. Para obtener más información, consulte Personalización de un clúster de HDInsight mediante la acción de script.
Algunos componentes nativos de Java, como Apache Mahout y Cascading, se pueden ejecutar en el clúster como archivos Java Archive (JAR). Estos archivos JAR se pueden distribuir a Azure Storage y enviarse a clústeres de HDInsight con los mecanismos de envío de trabajos de Hadoop. Para más información, consulte Envío de trabajos de Apache Hadoop mediante programación.
Nota
Si tiene problemas con la implementación de archivos JAR en clústeres de HDInsight o con la llamada a archivos JAR en clústeres de HDInsight, póngase en contacto con el soporte técnico de Microsoft.
Cascading no se admite en HDInsight, y no puede optar a recibir soporte técnico de Microsoft. Para ver las listas de los componentes compatibles, consulte Novedades en las versiones de clústeres proporcionadas por HDInsight.
En ocasiones, querrá configurar los siguientes archivos de configuración durante el proceso de creación:
- clusterIdentity.xml
- core-site.xml
- gateway.xml
- hbase-env.xml
- hbase-site.xml
- hdfs-site.xml
- hive-env.xml
- hive-site.xml
- mapred-site
- oozie-site.xml
- oozie-env.xml
- tez-site.xml
- webhcat-site.xml
- yarn-site.xml
Para más información, consulte Personalización de los clústeres de HDInsight con Bootstrap.