Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Para ayudarle a empezar a usar agrupaciones de automatización declarativa en el área de trabajo, este tutorial le guiará a través de la creación de un lote con un trabajo, su implementación y la ejecución del trabajo en el lote, todo desde el área de trabajo.
Para conocer los requisitos para usar agrupaciones en el área de trabajo, consulte Paquetes de automatización declarativos en los requisitos del área de trabajo.
Para obtener más información sobre las agrupaciones, consulte ¿Qué son los conjuntos de automatización declarativos?.
Crear un paquete
En primer lugar, crea un paquete en el área de trabajo de Databricks.
Diríjase a la carpeta git donde desea crear su paquete.
Sugerencia
Si has abierto previamente la carpeta Git en el editor del espacio de trabajo, puedes usar el menú contextual del navegador del espacio de trabajo para navegar rápidamente a la carpeta Git. Consulte Contextos de creación.
Haga clic en el botón Crear y, a continuación, haga clic en Agrupación. Como alternativa, haga clic con el botón derecho en la carpeta Git o en su kebab asociado en el árbol del área de trabajo y haga clic en Crear>Agrupación:
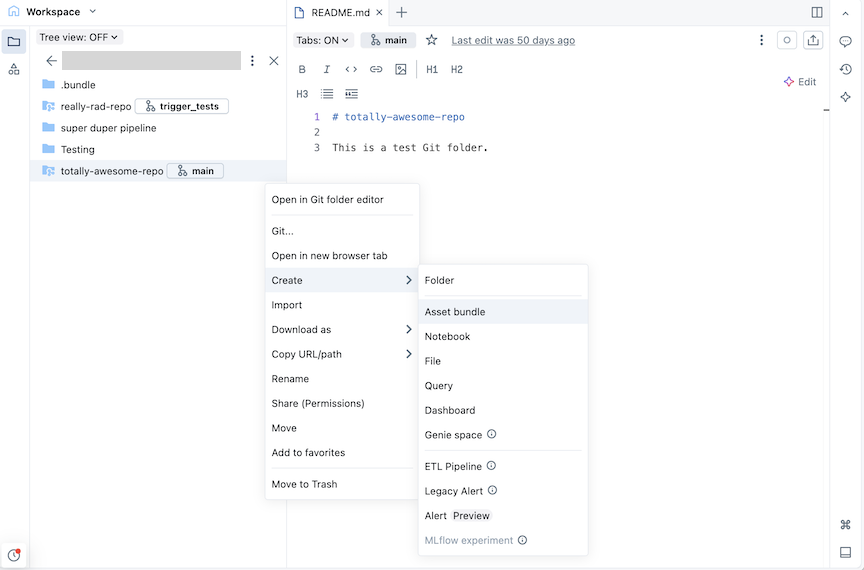
En el cuadro de diálogo Crear un lote , asigne un nombre al lote, como un paquete totalmente impresionante. El nombre del lote solo puede contener letras, números, guiones y caracteres de subrayado. Seleccione Proyecto vacío y haga clic en Siguiente .
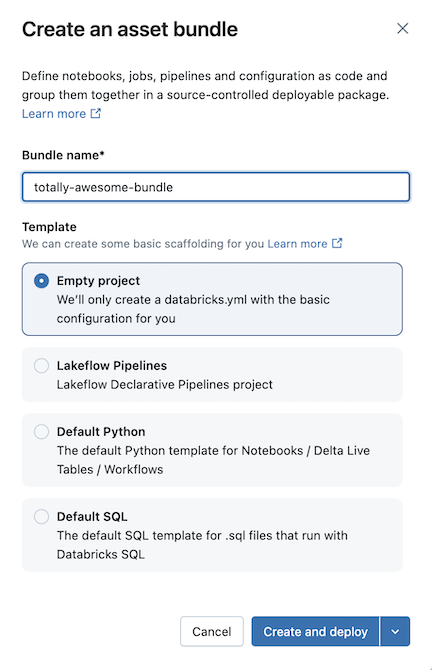
Esto crea una agrupación inicial en la carpeta Git, que incluye un .gitignore archivo de configuración de Git y el archivo de paquetes databricks.yml declarativos de Automatización necesarios. El databricks.yml archivo contiene la configuración principal de la agrupación. Para obtener más información, consulte Configuración de agrupaciones de automatización declarativa.
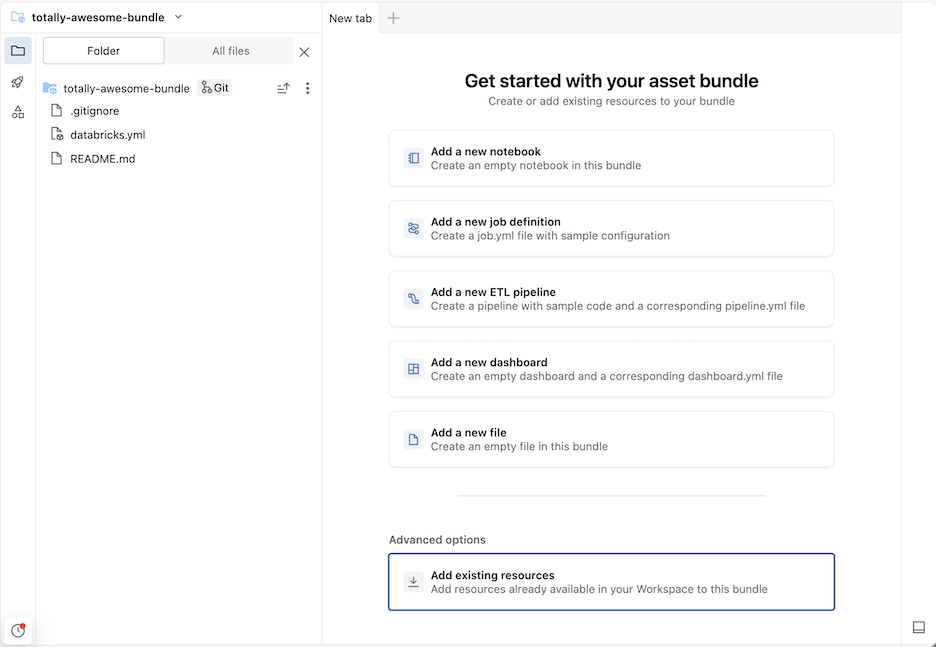
Agregar un cuaderno
A continuación, agregue un cuaderno al paquete. El cuaderno del ejemplo siguiente imprime "Hola mundo!".
Haga clic en el icono de agrupación de proyecto Agregar cuaderno. Como alternativa, haga clic en el kebab para la agrupación en la tabla de contenido y, a continuación, haga clic en Crear>cuaderno.
Cambie el nombre del bloc de notas a helloworld.
Establezca el lenguaje del cuaderno en Python y pegue lo siguiente en la celda del cuaderno:
print("Hello World!")
Definición de un trabajo
Ahora defina un trabajo que ejecute el cuaderno.
Haga clic en el icono de implementación del paquete para cambiar al panel Implementaciones .
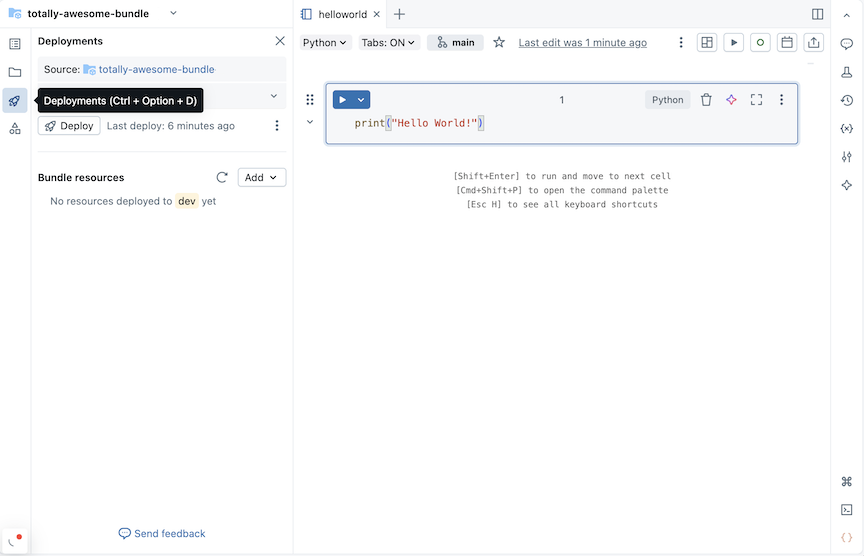
En la sección Agrupación de recursos , haga clic en Agregar y, a continuación, en Nueva definición de trabajo.
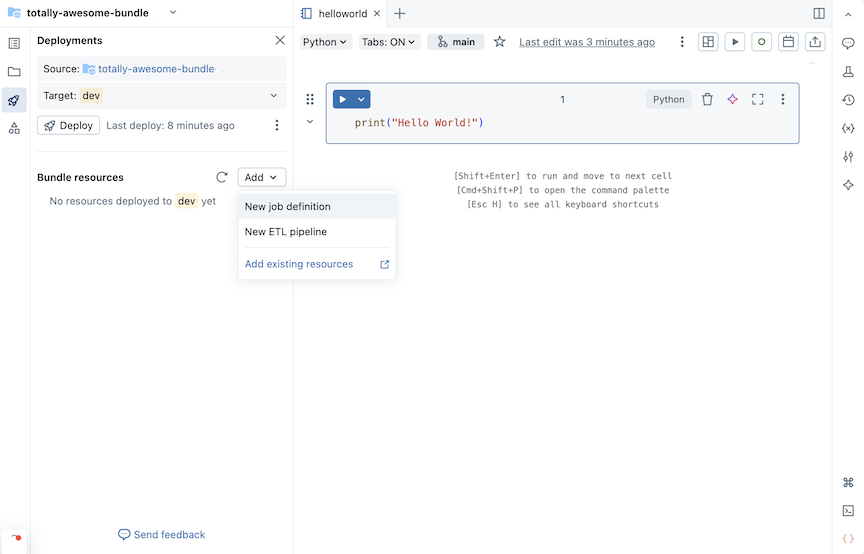
Escriba run-notebook en el campo Nombre del trabajo del cuadro de diálogo Agregar trabajo a la agrupación existente. Haga clic en Agregar e implementar.
Aparece un cuadro de diálogo de confirmación Implementar en desarrollo con información sobre el recurso de tarea que se creará en el espacio de trabajo de destino en desarrollo. Haga clic en Implementar.
Vuelva a los archivos de la agrupación haciendo clic en el icono de carpeta situado encima del icono de implementaciones. Se creó un recurso de trabajo
run-notebook.job.ymlcon YAML básico para el trabajo y un YAML de ejemplo de tarea de trabajo adicional comentado.Agregue una tarea de cuaderno a la definición del trabajo. Reemplace el código YAML de ejemplo en el
run-notebook.job.ymlarchivo por lo siguiente:resources: jobs: run_notebook: name: run-notebook queue: enabled: true tasks: - task_key: my-notebook-task notebook_task: notebook_path: ../helloworld.ipynb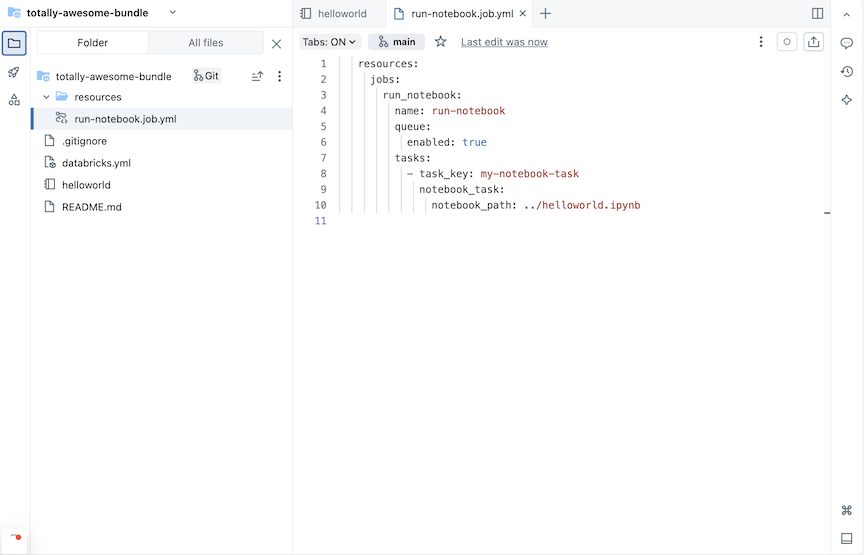
Para más información sobre cómo definir un trabajo en YAML, consulte trabajo. Para ver la sintaxis de YAML para otros tipos de tareas de trabajo compatibles, consulte Incorporación de tareas a trabajos en agrupaciones de automatización declarativa.
Desplegar el paquete
A continuación, despliegue el paquete y ejecute el trabajo que contiene la tarea del cuaderno helloworld.
En el panel de Implementaciones para el paquete, bajo Destinos, haga clic en la lista desplegable para seleccionar el área de trabajo de destino
devsi aún no está seleccionada. Los espacios de trabajo destinados se definen en latargetsasignación del conjuntodatabricks.yml. Consulte Modos de implementación de paquetes de automatización declarativos.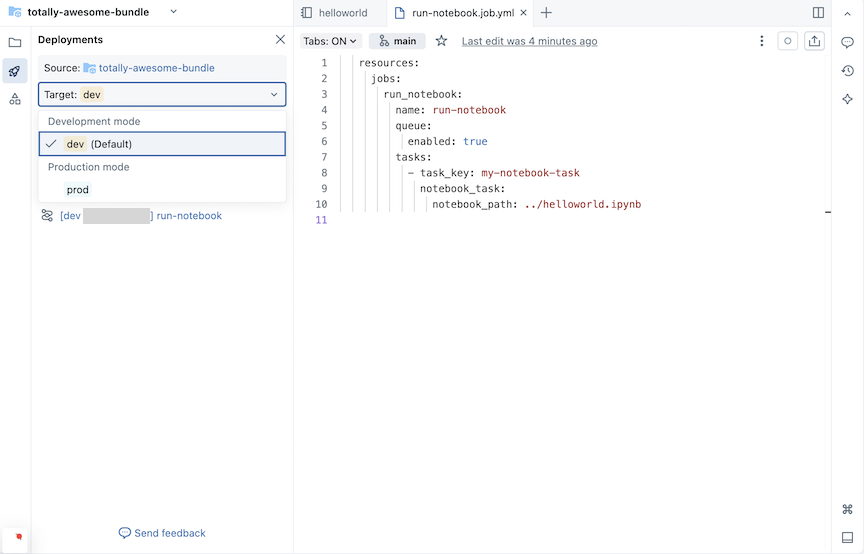
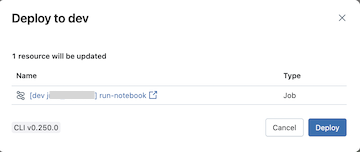
Haga clic en el botón Implementar . La agrupación se valida y los detalles de la validación aparecen en un cuadro de diálogo.
Revise los detalles de implementación en este cuadro de diálogo de confirmación Desplegar en desarrollo y, a continuación, haga clic en Desplegar.
Importante
La implementación de paquetes y la ejecución de recursos de paquetes ejecuta el código como el usuario actual. Asegúrese de confiar en el código de la agrupación, incluido YAML, que puede contener opciones de configuración que ejecutan comandos.
El estado de la implementación se genera en la ventana Salida del proyecto .
Ejecutar el trabajo
Los recursos de agrupación implementados aparecen en Recursos de agrupación. Haga clic en el icono de reproducción asociado al recurso de trabajo para ejecutarlo.
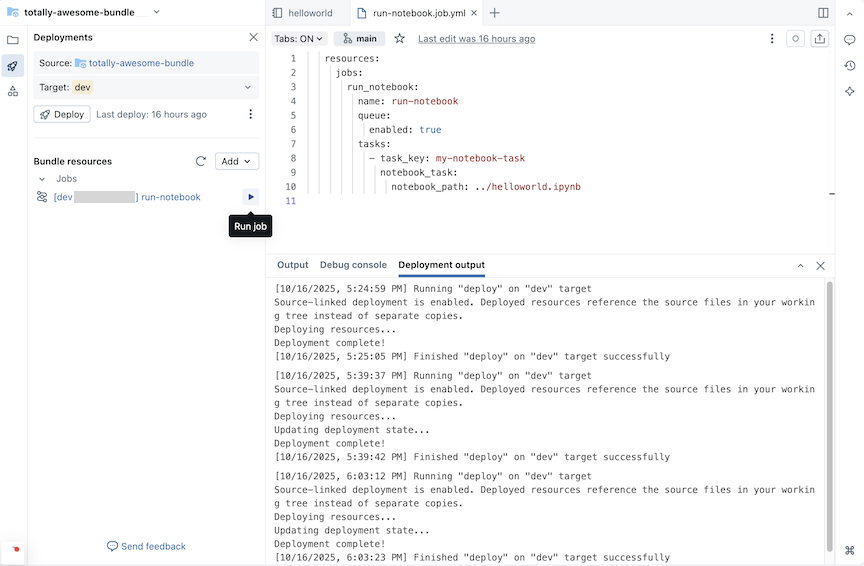
Vaya a Ejecuciones de trabajo desde la barra de navegación izquierda para ver la ejecución del lote. El nombre de la ejecución del trabajo agrupado tiene un prefijo, por ejemplo [dev someone] run-notebook.