Orquestación de trabajos de Azure Databricks con Apache Airflow
En este artículo se describe la compatibilidad de Apache Airflow para orquestar canalizaciones de datos con Azure Databricks, tiene instrucciones para instalar y configurar Airflow localmente y proporciona un ejemplo de implementación y ejecución de un flujo de trabajo de Azure Databricks con Airflow.
El desarrollo y la implementación de una canalización de procesamiento de datos a menudo requiere la administración de dependencias complejas entre tareas. Por ejemplo, una canalización podría leer datos de un origen, limpiar los datos, transformar los datos limpios y escribir los datos transformados en un destino. También necesita compatibilidad con las pruebas, la programación y la solución de errores al poner en marcha una canalización.
Los sistemas de flujo de trabajo abordan estos desafíos al permitirle definir dependencias entre tareas, programar la ejecución de las canalizaciones y supervisar los flujos de trabajo. Apache Airflow es una solución de código abierto para administrar y programar canalizaciones de datos. Airflow representa las canalizaciones de datos como gráficos acíclicos dirigidos (DAG) de operaciones. El flujo de trabajo se define en un archivo de Python y Airflow administra la programación y la ejecución. La conexión de Azure Databricks y Airflow le permite aprovechar el motor de Spark optimizado que ofrece Azure Databricks con las características de programación de Airflow.
- La integración entre Airflow y Azure Databricks requiere la versión 2.5.0 y posteriores de Airflow. Los ejemplos de este artículo se prueban con la versión 2.6.1 de Airflow.
- Airflow requiere Python 3.8, 3.9, 3.10 o 3.11. Los ejemplos de este artículo se prueban con Python 3.8.
- Las instrucciones de este artículo para instalar y ejecutar Airflow requieren pipenv para crear un entorno virtual de Python.
Un DAG de Airflow se compone de tareas, donde cada tarea ejecuta un operador de Airflow. Los operadores de Airflow que admiten la integración con Databricks se implementan en el proveedor de Databricks.
El proveedor de Databricks incluye operadores para ejecutar varias tareas en un área de trabajo de Azure Databricks, incluida la importación de datos en una tabla, la ejecución de consultas SQL y el trabajo con carpetas de Databricks.
El proveedor de Databricks implementa dos operadores para desencadenar trabajos:
- DatabricksRunNowOperator requiere un trabajo de Azure Databricks existente y usa la solicitud de API POST /api/2.1/jobs/run-now para desencadenar una ejecución. Databricks recomienda usar
DatabricksRunNowOperatorporque reduce la duplicación de definiciones de trabajos y las ejecuciones de trabajos desencadenadas con este operador pueden encontrarse en la interfaz de usuario de trabajos. - DatabricksSubmitRunOperator no requiere que exista un trabajo en Azure Databricks y usa la solicitud de API POST /api/2.1/jobs/runs/submit para enviar la especificación de trabajo y desencadenar una ejecución.
Para crear un nuevo trabajo de Azure Databricks o restablecer un trabajo existente, el proveedor de Databricks implementa DatabricksCreateJobsOperator. DatabricksCreateJobsOperator usa las solicitudes de API POST /api/2.1/jobs/create y POST /api/2.1/jobs/reset. Puede usar DatabricksCreateJobsOperator con DatabricksRunNowOperator para crear y ejecutar un trabajo.
Nota
El uso de los operadores de Databricks para desencadenar un trabajo requiere proporcionar credenciales en la configuración de conexión de Databricks. Consulte Creación de un token de acceso personal de Azure Databricks para Airflow.
El operador Airflow de Databricks escribe la dirección URL de la página de ejecución del trabajo en los registros de Airflow cada polling_period_seconds (el valor predeterminado es 30 segundos). Para más información, consulte la página del paquete apache-airflow-providers-databricks en el sitio web de Airflow.
Para instalar Airflow y el proveedor de Databricks localmente para pruebas y desarrollo, siga estos pasos. Para ver otras opciones de instalación de Airflow, incluida la creación de una instalación de producción, consulte instalación en la documentación de Airflow.
Abra un terminal y ejecute los comandos siguientes:
mkdir airflow
cd airflow
pipenv --python 3.8
pipenv shell
export AIRFLOW_HOME=$(pwd)
pipenv install apache-airflow
pipenv install apache-airflow-providers-databricks
mkdir dags
airflow db init
airflow users create --username admin --firstname <firstname> --lastname <lastname> --role Admin --email <email>
Reemplace <firstname>, <lastname> y <email> por su nombre de usuario y correo electrónico. Se le pedirá que escriba una contraseña para el usuario administrador. Asegúrese de guardar esta contraseña porque es necesaria para iniciar sesión en la interfaz de usuario de Airflow.
Este script realiza los pasos siguientes:
- Crea un directorio denominado
airflowy cambia a ese directorio. - Usa
pipenvpara crear y generar un entorno virtual de Python. Databricks recomienda usar un entorno virtual de Python para aislar las versiones de paquetes y las dependencias de código en ese entorno. Este aislamiento ayuda a reducir las discrepancias inesperadas en las versiones de los paquetes y las colisiones en las dependencias de código. - Inicializa una variable de entorno llamada
AIRFLOW_HOMEestablecida en la ruta de acceso del directorioairflow. - Instala Airflow y los paquetes del proveedor de Airflow Databricks.
- Crea un directorio
airflow/dags. Airflow usa el directoriodagspara almacenar definiciones de DAG. - Inicializa una base de datos SQLite que Airflow usa para realizar un seguimiento de los metadatos. En una implementación de Airflow de producción, configuraría Airflow con una base de datos estándar. La base de datos SQLite y la configuración predeterminada de la implementación de Airflow se inicializan en el directorio
airflow. - Crea un usuario administrador para Airflow.
Sugerencia
Para confirmar la instalación del proveedor de Databricks, ejecute el siguiente comando en el directorio de instalación de Airflow:
airflow providers list
El servidor web de Airflow es necesario para ver la interfaz de usuario de Airflow. Para iniciar el servidor web, abra un terminal en el directorio de instalación de Airflow y ejecute los siguientes comandos:
Nota
Si el servidor web de Airflow no se inicia debido a un conflicto de puertos, puede cambiar el puerto predeterminado en la configuración de Airflow.
pipenv shell
export AIRFLOW_HOME=$(pwd)
airflow webserver
El programador es el componente de Airflow que programa los DAG. Para iniciar el programador, abra un nuevo terminal en el directorio de instalación de Airflow y ejecute los siguientes comandos:
pipenv shell
export AIRFLOW_HOME=$(pwd)
airflow scheduler
Para comprobar la instalación de Airflow, puede ejecutar uno de los DAG de ejemplo incluidos con Airflow:
- En una ventana del explorador, abra
http://localhost:8080/home. Inicie sesión en la interfaz de usuario de Airflow con el nombre de usuario y la contraseña que creó al instalar Airflow. Aparece la página DAG de Airflow. - Haga clic en el botón de conmutación Pause/Unpause DAG (Pausar/Dejar de pausar DAG) para dejar de pausar uno de los DAG de ejemplo, por ejemplo,
example_python_operator. - Para desencadenar el DAG de ejemplo, haga clic en el botón Desencadenar DAG.
- Haga clic en el nombre del DAG para ver los detalles, como el estado de ejecución.
Airflow se conecta a Databricks mediante un token de acceso personal (PAT) de Azure Databricks. Para crear un PAT, siga los pasos descritos en Tokens de acceso personal de Azure Databricks para los usuarios del área de trabajo.
Nota
Como procedimiento recomendado de seguridad, cuando se autentique con herramientas, sistemas, scripts y aplicaciones automatizados, Databricks recomienda usar los tokens de acceso personal pertenecientes a las entidades de servicio en lugar de a los usuarios del área de trabajo. Para crear tókenes para entidades de servicio, consulte Administración de tokens de acceso para una entidad de servicio.
También puede autenticarse en Azure Databricks mediante un token de Microsoft Entra ID. Consulte Conexión de Databricks en la documentación de Airflow.
La instalación de Airflow contiene una conexión predeterminada para Azure Databricks. Para actualizar la conexión para conectarse al área de trabajo mediante el token de acceso personal que creó anteriormente:
- En una ventana del explorador, abra
http://localhost:8080/connection/list/. Si se le pide que inicie sesión, escriba el nombre de usuario y la contraseña del administrador. - En Conn ID (Id. de conexión), busque databricks_default y haga clic en el botón Edit record (Editar registro).
- Reemplace el valor del campo Host por el nombre de la instancia del área de trabajo de la implementación de Azure Databricks, por ejemplo,
https://adb-123456789.cloud.databricks.com. - En el campo Contraseña, escriba el token de acceso personal de Azure Databricks.
- Haga clic en Save(Guardar).
Si usa un token de Microsoft Entra ID, consulte Conexión de Databricks en la documentación de Airflow para obtener información sobre cómo configurar la autenticación.
En el ejemplo siguiente se muestra cómo crear una implementación sencilla de Airflow que se ejecuta en la máquina local y que implementa un DAG de ejemplo para desencadenar ejecuciones en Azure Databricks. En este ejemplo, hará lo siguiente:
- Crear un cuaderno y agregar código para imprimir una felicitación en función de un parámetro configurado.
- Crear un trabajo de Azure Databricks con una sola tarea que ejecute el cuaderno.
- Configurar una conexión de Airflow al área de trabajo de Azure Databricks.
- Crear un DAG de Airflow para desencadenar el trabajo del cuaderno. El DAG se define en un script de Python mediante
DatabricksRunNowOperator. - Usar la interfaz de usuario de Airflow para desencadenar el DAG y ver el estado de ejecución.
En este ejemplo se usa un cuaderno que contiene dos celdas:
- La primera contiene un widget de texto de utilidades de Databricks que define una variable llamada
greetingestablecida en el valor predeterminadoworld. - La segunda imprime el valor de la variable
greetingprecedida porhello.
Para crear el cuaderno:
Vaya al área de trabajo de Azure Databricks, haga clic en
 Nuevo en la barra lateral y seleccione Notebook.
Nuevo en la barra lateral y seleccione Notebook.Asigne un nombre al cuaderno, como Hello Airflow, y asegúrese de que el lenguaje predeterminado está establecido en Python.
Copie el código de Python siguiente y péguelo en la primera celda del cuaderno.
dbutils.widgets.text("greeting", "world", "Greeting") greeting = dbutils.widgets.get("greeting")Agregue una nueva celda debajo de la primera y copie y pegue el siguiente código de Python en la nueva celda:
print("hello {}".format(greeting))
Haga clic en
 Flujos de trabajo en la barra lateral.
Flujos de trabajo en la barra lateral.Haga clic en el
 .
.Aparece la pestaña Tareas con el cuadro de diálogo Crear tarea.
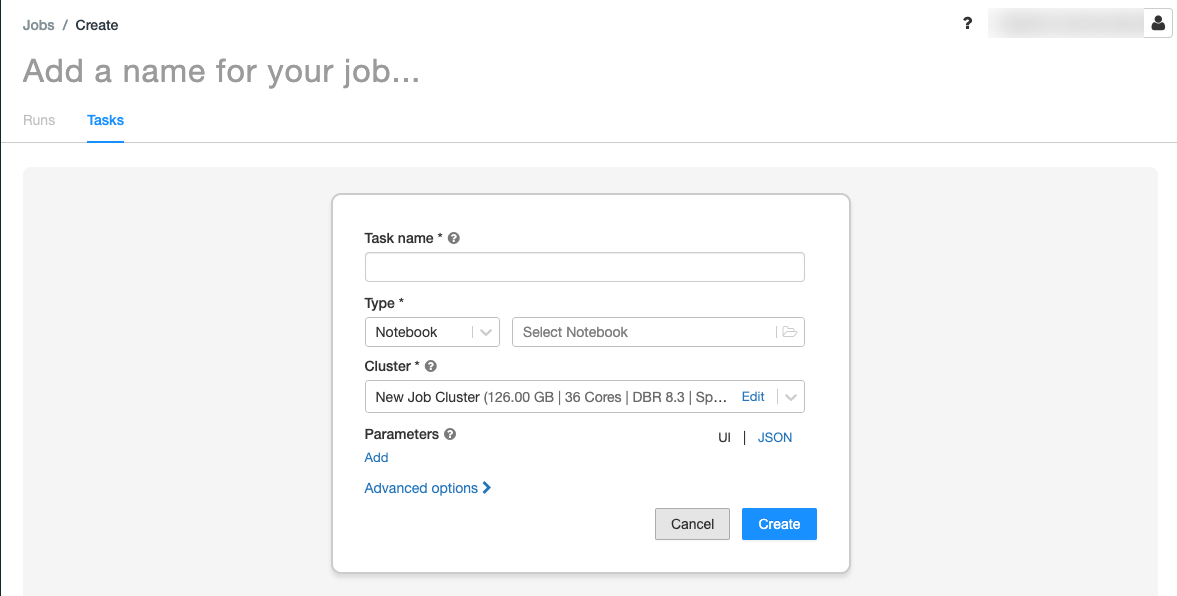
Reemplace Add a name for your job… (Agregar un nombre para el trabajo…) por el nombre del trabajo.
En el campo Task name (Nombre de tarea), escriba un nombre para la tarea, por ejemplo, greeting-task.
En el menú desplegable Tipo, seleccione Notebook.
En el menú desplegable Origen, seleccione Área de trabajo.
Haga clic en el cuadro de texto Ruta de acceso y use el explorador de archivos para buscar el cuaderno que creó, haga clic en el nombre del cuaderno y haga clic en Confirmar.
Haga clic en Add (Agregar) en Parameters (Parámetros). En el campo Key (Clave), escriba
greeting. En el campo Value (Valor), escribaAirflow user.Haga clic en Create task (Crear tarea).
En el panel Detalles del trabajo, copie el valor del Id. de trabajo. Este valor es necesario para desencadenar el trabajo desde Airflow.
Para probar el nuevo trabajo en la interfaz de usuario de trabajos de Azure Databricks, haga clic en  en la esquina superior derecha. Cuando se complete la ejecución, puede comprobar la salida viendo los detalles de la ejecución del trabajo.
en la esquina superior derecha. Cuando se complete la ejecución, puede comprobar la salida viendo los detalles de la ejecución del trabajo.
Defina un DAG de Airflow en un archivo de Python. Para crear un DAG para desencadenar el trabajo de cuaderno de ejemplo:
En un editor de texto o IDE, cree un nuevo archivo llamado
databricks_dag.pycon el siguiente contenido:from airflow import DAG from airflow.providers.databricks.operators.databricks import DatabricksRunNowOperator from airflow.utils.dates import days_ago default_args = { 'owner': 'airflow' } with DAG('databricks_dag', start_date = days_ago(2), schedule_interval = None, default_args = default_args ) as dag: opr_run_now = DatabricksRunNowOperator( task_id = 'run_now', databricks_conn_id = 'databricks_default', job_id = JOB_ID )Reemplace
JOB_IDpor el valor del identificador de trabajo guardado anteriormente.Guarde el archivo en el directorio
airflow/dags. Airflow lee e instala automáticamente los archivos DAG almacenados enairflow/dags/.
Para desencadenar y comprobar el DAG en la interfaz de usuario de Airflow:
- En una ventana del explorador, abra
http://localhost:8080/home. Aparece la pantalla DAGs (DAG) de Airflow. - Busque
databricks_dagy haga clic en Pause/Unpause DAG (Pausar/Dejar de pausar DAG) para dejar de pausar el DAG. - Para desencadenar el DAG, haga clic en el botón Desencadenar DAG.
- Haga clic en una ejecución en la columna Runs (Ejecuciones) para ver el estado y los detalles de la ejecución.