Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Importante
El escalado automático de Lakebase es la versión más reciente de Lakebase, con proceso de escalado automático, escalado a cero, bifurcación y restauración instantánea. Para ver las regiones admitidas, consulte Disponibilidad de regiones. Si es un usuario aprovisionado de Lakebase, consulte Aprovisionamiento de Lakebase.
Al final de esta guía, tendrá una base de datos de Postgres en ejecución con datos de ejemplo, conectados al catálogo de Unity, con datos que fluyen entre Lakebase y Databricks Lakehouse.
Pasos: (1) Crear un proyecto → (2) Conectar → (3) Crear una tabla → (4) Registrar en el catálogo de Unity → (5) Servir datos
Paso 1: Crear el primer proyecto
Abra la aplicación Lakebase desde el conmutador de aplicaciones.
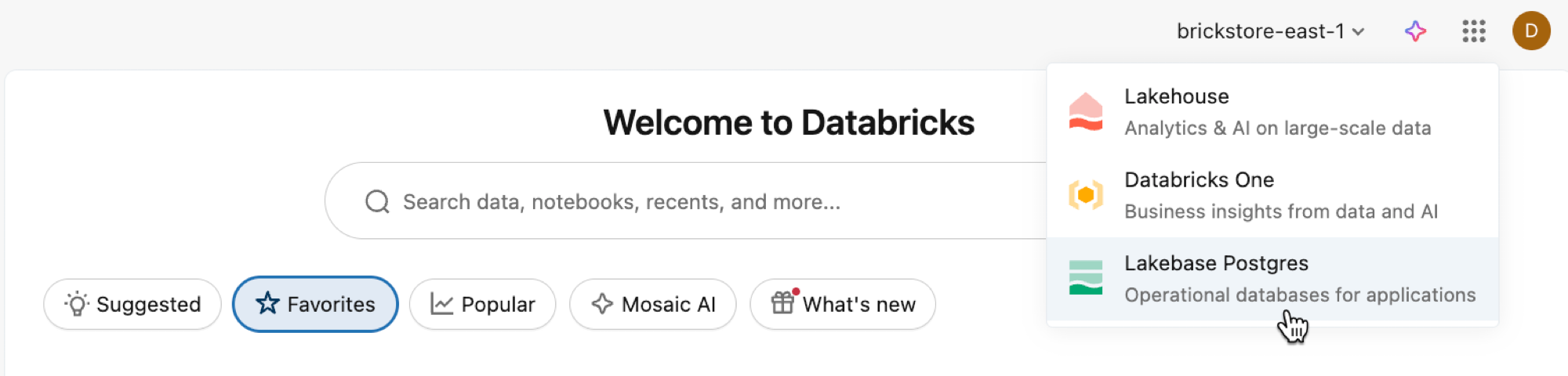
Seleccione Escalado automático para acceder a la interfaz de usuario de escalado automático de Lakebase.
Haz clic en Nuevo proyecto. Asigne un nombre al proyecto y seleccione la versión de Postgres. El proyecto se crea con una sola production rama, una base de datos predeterminada databricks_postgres y recursos de proceso configurados para la rama.
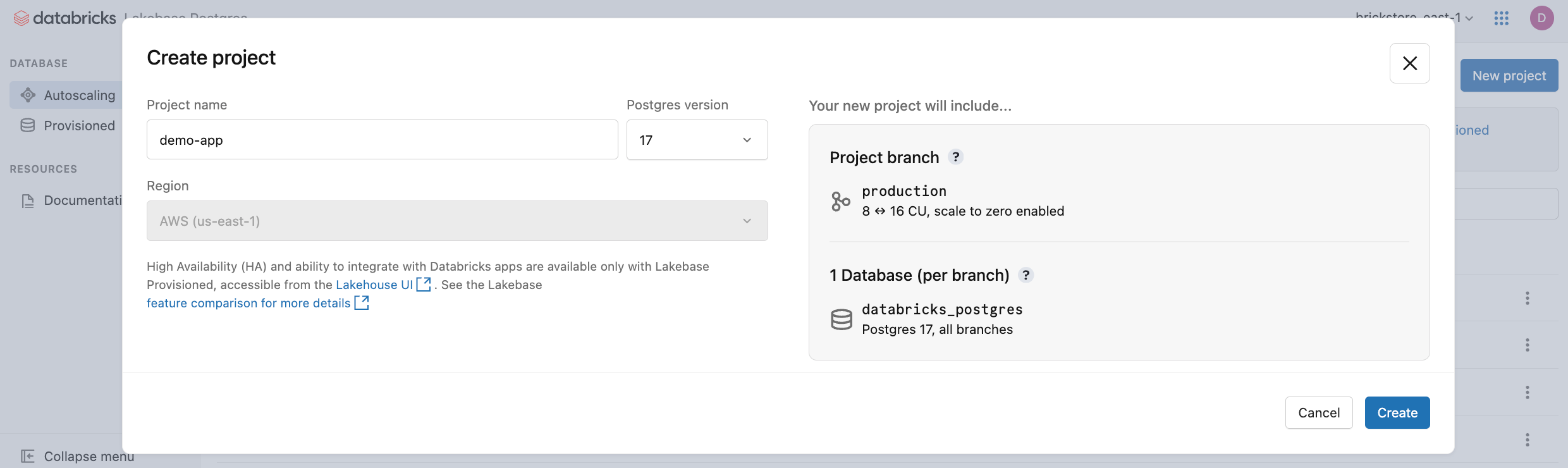
Puede tardar unos momentos en activarse tu computadora. El cómputo de la production rama está siempre activado por defecto (la escala a cero está deshabilitada), pero puede configurar esta opción si es necesario.
La región del proyecto se establece automáticamente en la región del área de trabajo.
Más información: Creación de un proyecto | Escalado automático | Escalado a cero
Paso 2: Conexión a la base de datos
En el proyecto, seleccione la rama de producción y haga clic en Conectar. Las cadenas de conexión funcionan con cualquier cliente de Postgres estándar (psql, pgAdmin, DBeaver o marcos de aplicación).
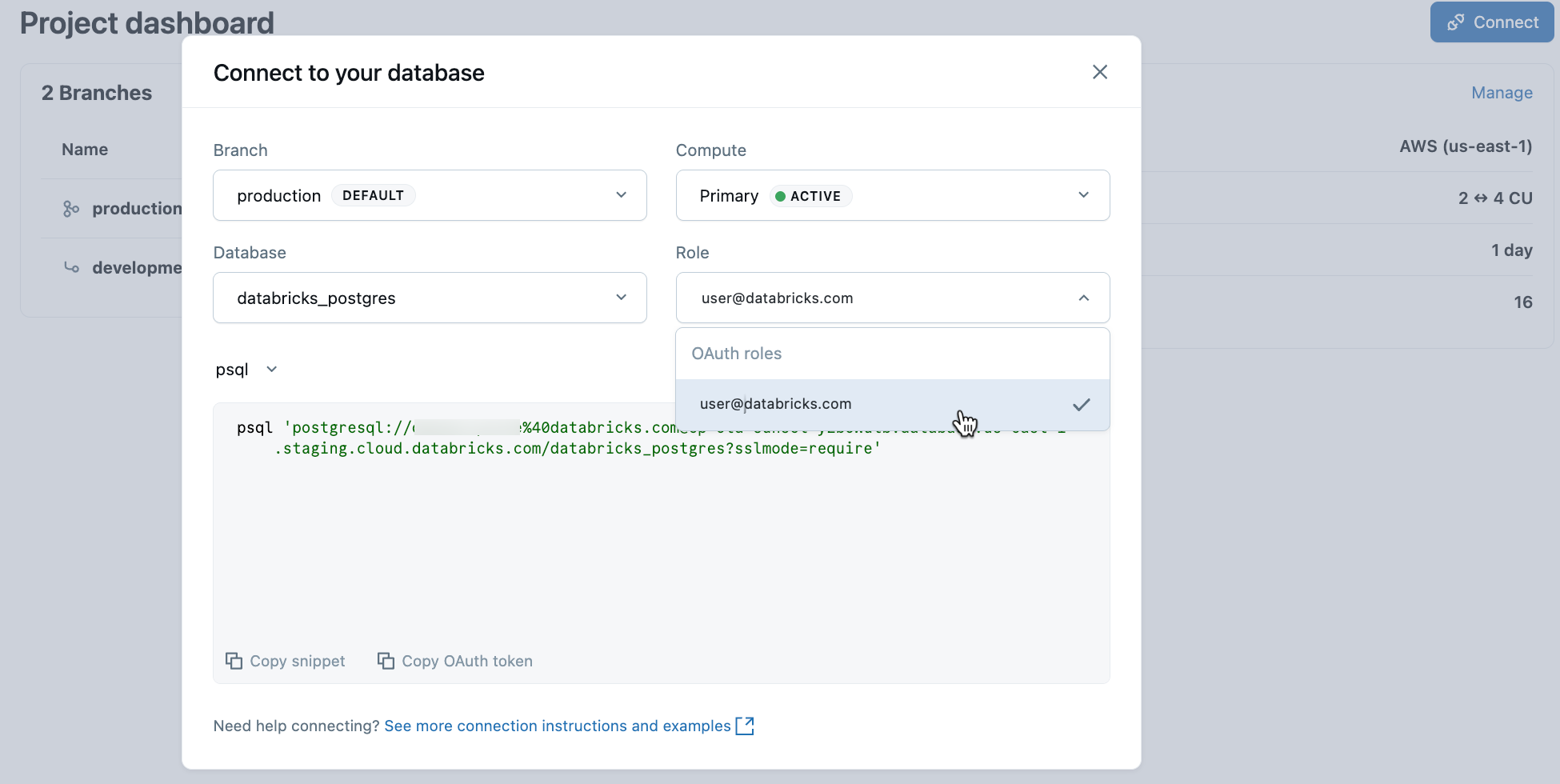
Para conectarse a la identidad de Databricks, copie el psql fragmento de código del cuadro de diálogo de conexión y pegue el token de OAuth cuando se le solicite:
psql 'postgresql://your-email@databricks.com@ep-abc-123.databricks.com/databricks_postgres?sslmode=require'
Más información: Guía rápida de conexión | psql | pgAdmin | Clientes de Postgres
Paso 3: Crear la primera tabla
El Editor sql de Lakebase viene precargado con SQL de ejemplo. En el proyecto, seleccione la rama de producción , abra el Editor de SQL y ejecute las instrucciones proporcionadas para crear una playing_with_lakebase tabla e insertar datos de ejemplo.
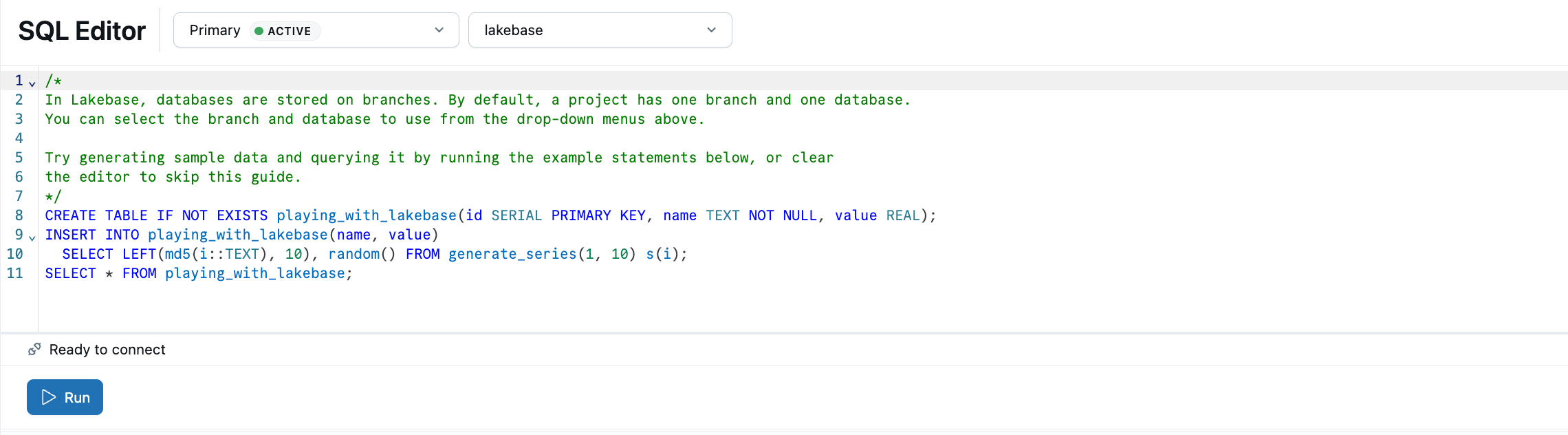
Más información: Editor de SQL | Editor de tablas | Clientes de Postgres
Paso 4: Registrarse en el catálogo de Unity
La base de datos de Lakebase se está ejecutando, pero es invisible para el resto de la plataforma de Databricks hasta que la registre en el catálogo de Unity. Una vez registrado, puede consultar tablas de Lakebase desde Databricks SQL, combinar datos operativos con análisis de lakehouse y aplicar una gobernanza unificada.
En el Explorador de catálogos, cree un nuevo catálogo con Lakebase Autoscaling como tipo, apuntando a la rama production y a la base de datos databricks_postgres de su proyecto.
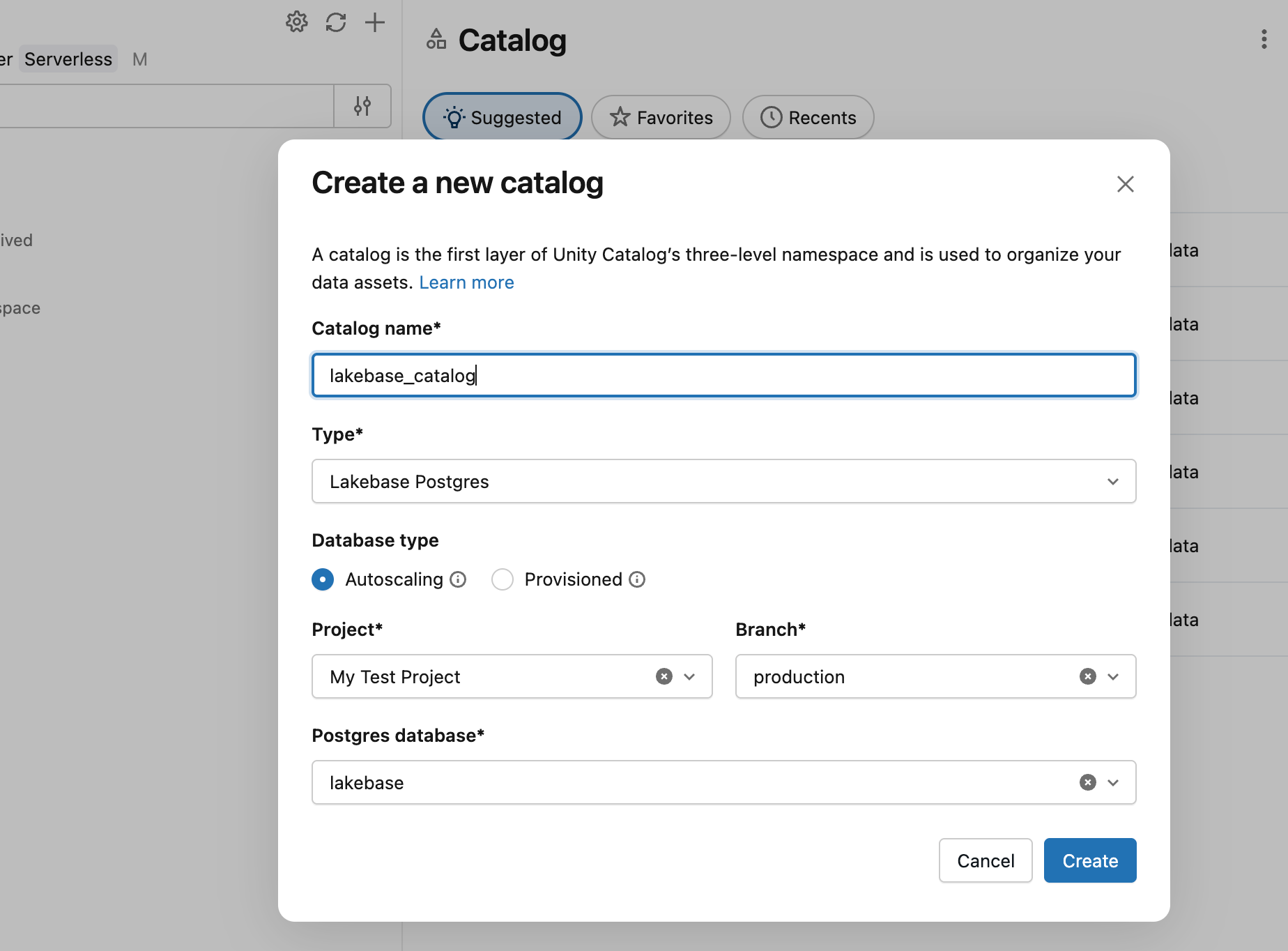
Ahora puede consultar desde una instancia de SQL Warehouse:
SELECT * FROM lakebase_catalog.public.playing_with_lakebase;
Más información: Registro en el catálogo de Unity
Paso 5: Servir datos de lakehouse en la aplicación
Las tablas sincronizadas llevan datos analíticos de Unity Catalog a la base de datos de Lakebase para que las aplicaciones puedan consultarlos con lecturas transaccionales de baja latencia. Cree una tabla de catálogo de Unity de ejemplo y, a continuación, sincroníela con Lakebase.
En un almacén o cuaderno de SQL, cree una tabla de origen:
CREATE TABLE main.default.user_segments AS
SELECT * FROM VALUES
(1001, 'premium', 2500.00, 'high'),
(1002, 'standard', 450.00, 'medium'),
(1003, 'premium', 3200.00, 'high'),
(1004, 'basic', 120.00, 'low')
AS segments(user_id, tier, lifetime_value, engagement);
Ahora sincronice esta tabla en Lakebase. En el Explorador de catálogos, cree una tabla sincronizada desde user_segments con el modo de instantánea , que tiene como destino la base de datos del databricks_postgres proyecto. El modo de instantánea copia los datos una vez. Para las actualizaciones continuas, use el modo desencadenado o continuo.
Una vez completada la sincronización, los datos están disponibles en Lakebase como default.user_segments_synced. Puede consultarlo en el Editor de SQL de Lakebase:
SELECT * FROM "default".user_segments_synced WHERE engagement = 'high';
Nota:
default debe citarse porque es una palabra clave reservada de PostgreSQL. El esquema de tabla sincronizada hereda el nombre del esquema del catálogo de Unity, por lo que si el esquema se denomina default, siempre debe citarlo en las consultas. Las comillas alrededor de otros identificadores son opcionales.
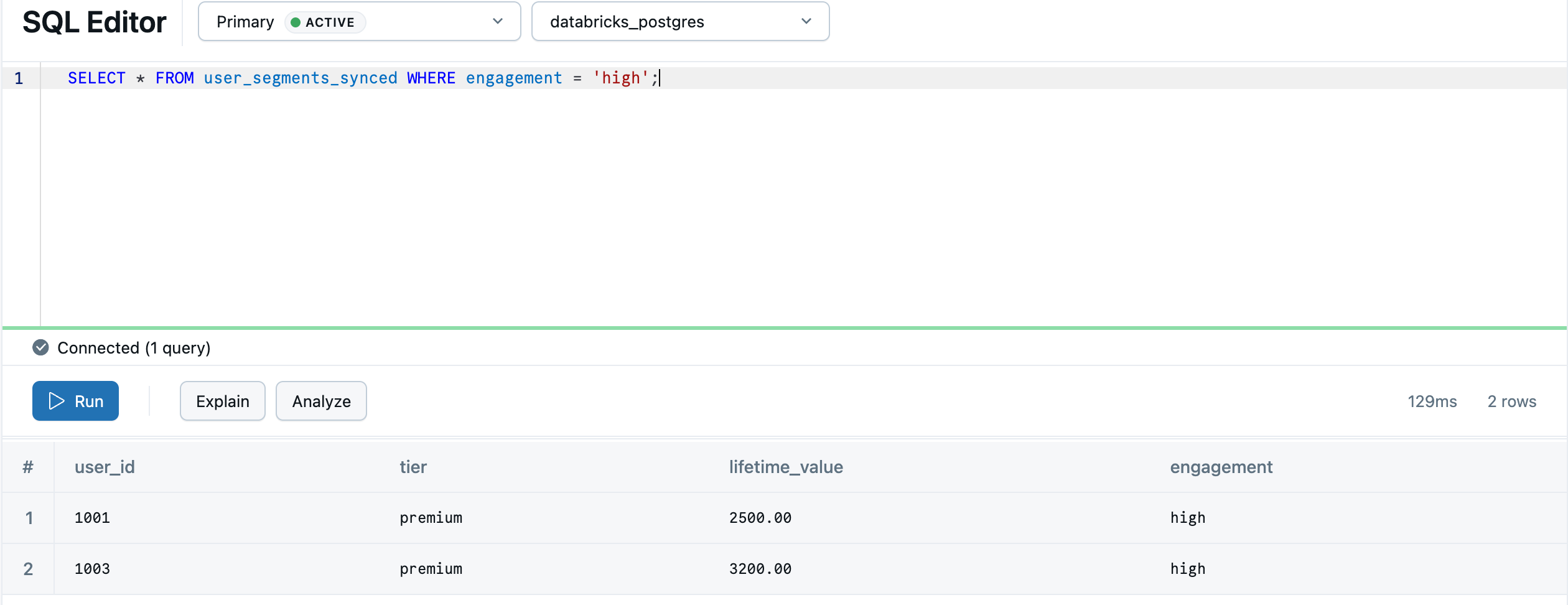
El análisis de lakehouse está listo para ser usado desde tu base de datos transaccional.
Más información: Tablas sincronizadas | Modos de sincronización | Asignación de tipos de datos
Pasos siguientes
- Creación de una aplicación:Tutorial de aplicaciones de Databricks | Aplicaciones externas
- Desarrollo con ramas:Tutorial de desarrollo basado en ramas
- Configurar el equipo:Conceder acceso a proyectos y bases de datos
- Explora la plataforma:Conceptos básicos | Introducción a los proyectos | Todos los tutoriales