Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Puede usar un perfil de consulta para visualizar los detalles de la ejecución de una consulta. El perfil de consulta ayuda a solucionar los cuellos de botella de rendimiento durante la ejecución de la consulta. Por ejemplo:
- Puede visualizar cada operador de consulta y las métricas relacionadas, como el tiempo empleado, el número de filas procesadas, las filas procesadas y el consumo de memoria.
- Puede identificar la parte más lenta de la ejecución de una consulta de un vistazo y evaluar los impactos de las modificaciones en la consulta.
- Puede detectar y corregir errores comunes en instrucciones SQL, como la expansión de combinaciones o recorridos de tabla completos.
Requisitos
Para ver el perfil de una consulta, debe ser el propietario de la consulta o debe tener al menos el permiso CAN MONITOR en el almacén de SQL que ejecutó la consulta.
Visualización de un perfil de consulta
Puede ver el perfil de consulta desde el historial de consultas mediante los pasos siguientes:
Haga clic en
 Historial de consultas en la barra lateral.
Historial de consultas en la barra lateral.Haga clic en el nombre de una consulta. Aparece un panel de detalles de consulta en el lado derecho de la pantalla.
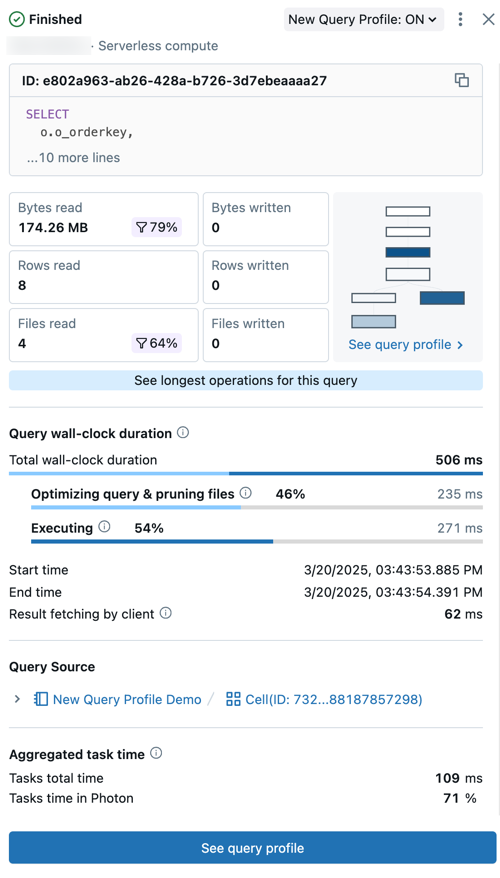
El resumen de la consulta incluye:
- Estado de la consulta: la consulta se etiqueta con su estado actual: En cola, En ejecución, Finalizado, Fallido o Cancelado.
- Detalles de usuario y proceso: consulte el nombre de usuario, el tipo de proceso y los detalles del tiempo de ejecución de esta consulta.
- Id.: es el identificador único universal (UUID) asociado a la ejecución de la consulta dada.
- Instrucción de consulta: esta sección incluye la instrucción de la consulta completa. Si la consulta es demasiado larga para mostrarse en la vista previa, haga clic en ... más líneas para ver el texto completo.
- Métricas de consulta: las métricas populares para el análisis de consultas se muestran bajo el texto de la consulta. Los iconos de filtro que aparecen con algunas métricas indican el porcentaje de datos depurados durante el examen.
- Ver perfil de consulta: en este resumen se muestra una versión preliminar del grafo acíclico dirigido (DAG) del perfil de consulta. Esto puede ser útil para estimar rápidamente la complejidad de la consulta y el flujo de ejecución. Haga clic en Ver perfil de consulta para abrir el DAG detallado.
- Ver operadores más largos para esta consulta: haga clic en este botón para abrir el panel Operadores principales. En este panel se muestran los operadores de ejecución más largos de la consulta.
- Duración del reloj de consulta: el tiempo total transcurrido entre el inicio de la planificación y el final de la ejecución de la consulta se proporciona como un resumen. Debajo del resumen aparece un desglose detallado de la programación, la optimización de las consultas y la depuración de archivos, así como del tiempo de ejecución.
- Origen de la consulta: haga clic en el nombre del objeto que aparece para ir al origen de la consulta.
- Tiempo de tarea agregado: vea el tiempo combinado que se tardó en ejecutar la consulta en todos los núcleos de todos los nodos. Puede ser significativamente mayor que la duración del reloj si se ejecutan varias tareas en paralelo. Puede ser menor que la duración del reloj si las tareas esperan por los nodos disponibles.
- Entrada/salida (E/S): vea los detalles sobre los datos leídos y escritos durante la ejecución de la consulta.
Haga clic en Ver perfil de consulta. Se abre un panel de Detalles en la parte derecha de la pantalla.
Nota
Si se muestra el perfil de consulta no disponible, no hay ningún perfil disponible para esta consulta. No hay perfil de consulta disponible para las consultas que se ejecutan desde la caché de consulta. Para evitar la caché de consulta, realice un cambio trivial en la consulta, como cambiar o quitar
LIMIT.
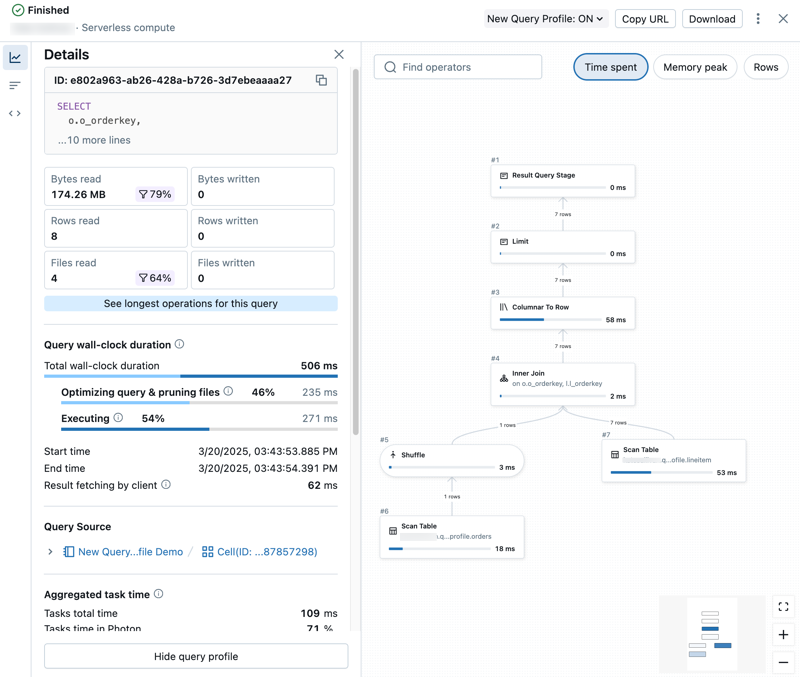
Ver los detalles del perfil de consulta
El perfil detallado de la consulta incluye métricas de resumen en la parte izquierda del panel y una vista gráfica de los operadores en la derecha.
Explorar las métricas de consulta
La parte izquierda del perfil de consulta tiene las siguientes pestañas:
 Detalles: abre el panel de Detalles que muestra las métricas de resumen de la consulta.
Detalles: abre el panel de Detalles que muestra las métricas de resumen de la consulta. Operadores principales: abre el panel Operadores principales que muestra los operadores más caros utilizados en su consulta. Esto puede ser útil para identificar oportunidades de optimización.
Operadores principales: abre el panel Operadores principales que muestra los operadores más caros utilizados en su consulta. Esto puede ser útil para identificar oportunidades de optimización. Texto de la consulta: abre el panel Texto de la consulta que muestra el texto completo de la consulta.
Texto de la consulta: abre el panel Texto de la consulta que muestra el texto completo de la consulta.
Nota
Algunas operaciones que no son de Photon se ejecutan como un grupo y comparten métricas comunes. En este caso, todas las operaciones tienen el mismo valor que el operador primario para una métrica determinada.
Exploración del DAG
La mitad derecha del perfil de la consulta muestra el grafo acíclico dirigido (DAG) de la consulta. La vista de grafo muestra métricas como Tiempo empleado, Pico de memoria y Filas. Haga clic en cada métrica para cambiar la métrica de informes que se muestra.
Puede interactuar con el DAG de las maneras siguientes:
- Use la barra de búsqueda para resaltar diferentes operadores o columnas.
- Acerque o aleje el zoom para centrarse en diferentes partes del DAG.
- Haga clic en operadores para mostrar descripciones y métricas detalladas. Un panel en el lado derecho del grafo muestra los detalles de la operación.
En el caso de las consultas SQL de Databricks, también puede ver el perfil de consulta en la interfaz de usuario de Spark. Haga clic en el ![]() situado cerca de la parte superior de la página y, a continuación, haga clic en Abrir en la interfaz de usuario de Spark.
situado cerca de la parte superior de la página y, a continuación, haga clic en Abrir en la interfaz de usuario de Spark.
De manera predeterminada, las tareas y las métricas de algunas operaciones están ocultas. Es poco probable que estas operaciones sean la causa de cuellos de botella de rendimiento. Para ver información de todas las operaciones y para ver métricas adicionales, haga clic en ![]() en la parte superior de la página y, a continuación, en Habilitar modo detallado.
en la parte superior de la página y, a continuación, en Habilitar modo detallado.
Operaciones comunes
Las operaciones más habituales son las siguientes:
- Examen: los datos se leyeron de un origen de datos y se generaron como filas.
- Combinación: las filas de varias relaciones se combinaron (intercaladas) en un único conjunto de filas.
- Unión: las filas de varias relaciones que usan el mismo esquema se concatenaron en un único conjunto de filas.
- Orden aleatorio: los datos se redistribuyeron o se repartieron. Las operaciones de orden aleatorio suponen un coste de recursos, ya que mueven datos entre ejecutores del clúster.
-
Hash/Ordenación: las filas se agruparon por una clave y se evaluaron mediante una función de agregado como
SUM,COUNToMAXdentro de cada grupo. -
Filtro: la entrada se filtra según un criterio, como una cláusula
WHERE, y se devuelve un subconjunto de filas.
Información sobre el rendimiento
Importante
Esta característica se encuentra en su versión beta. Los administradores del área de trabajo pueden controlar el acceso a esta característica desde la página Vistas previas . Consulte Administrar versiones preliminares de Azure Databricks.
Cuando se ejecutan consultas, Azure Databricks podrían devolver información de rendimiento que identifique oportunidades para mejorar el rendimiento de las consultas. El perfil de consulta muestra información en dos lugares:
- El panel de detalles de la consulta muestra un resumen de la información más impactante, clasificada por su efecto proyectado en la duración total de la tarea.
- En la pestaña Información de rendimiento del perfil de consulta detallado se muestran los detalles completos de cada información.
Para consultar la lista de indicadores compatibles y su significado, consulte Indicadores de rendimiento de consultas.
Optimización con Genie Code
Cuando una consulta tenga información sobre la que puede actuar, seleccione Optimizar para abrir Genie Code. Para obtener una información que requiera un cambio de consulta, Genie Code vuelve a escribir la consulta y presenta los cambios para su aprobación. Para una información que implique cambios en tablas o en el procesamiento, Genie Code resume las acciones recomendadas en lenguaje claro.
Para obtener más información sobre cómo trabajar con Genie Code, consulte Genie Code.
Uso compartido de un perfil de consulta
Para compartir un perfil de consulta con otro usuario:
- Visualice el historial de consultas.
- Haga clic en el nombre de la consulta.
- Para compartir la consulta, tiene dos opciones:
- Si el otro usuario tiene el permiso CAN MANAGE en la consulta, puede compartir la dirección URL del perfil de consulta con este usuario. Haga clic en Compartir. La dirección URL se copia en el Portapapeles.
- Si el otro usuario no tiene el permiso CAN MANAGE o no es miembro del área de trabajo, usted puede descargar el perfil de consulta como un objeto JSON. Descarga. El archivo JSON se descarga en el sistema local.
Importación de un perfil de consulta
Para importar el archivo JSON para un perfil de consulta:
Visualice el historial de consultas.
Haga clic en el menú de kebab
 en la esquina superior derecha y seleccione Importar perfil de consulta (JSON).
en la esquina superior derecha y seleccione Importar perfil de consulta (JSON).En el explorador de archivos, seleccione el archivo JSON que se ha compartido con usted y haga clic en Abrir. El archivo JSON se carga y se muestra el perfil de consulta.
Al importar un perfil de consulta, se carga dinámicamente en la sesión del explorador y no se conserva en el área de trabajo. Debe volver a importarlo cada vez que quiera verlo.
Para cerrar el perfil de consulta importado, haga clic en X en la parte superior de la página.
Acceso al perfil de consulta
También puede acceder al perfil de consulta en las siguientes partes de la interfaz de usuario:
Desde el editor de SQL: durante y después de la ejecución de la consulta, un vínculo situado cerca de la parte inferior de la página muestra el tiempo transcurrido y el número de filas devueltas. Haga clic en ese vínculo para abrir el panel detalles de la consulta. Haga clic en Ver perfil de consulta.

Nota
Si tiene habilitado el nuevo editor de SQL (versión preliminar pública), su vínculo aparecerá como en un cuaderno.
Desde un cuaderno: si su cuaderno está conectado a un almacén SQL o a un proceso sin servidor, puede acceder al perfil de consulta utilizando el vínculo situado bajo la celda que contiene la consulta. Haga clic en Ver rendimiento para abrir el historial de ejecuciones. Haga clic en una instrucción para abrir el panel de detalles de la consulta.

Desde la interfaz de usuario de canalizaciones de Lakeflow: puede acceder al historial de consultas y al perfil desde la pestaña Historial de consultas de la interfaz de usuario de la canalización. Consulte Historial de consultas de Access para canalizaciones.
Desde la interfaz de usuario de trabajos: puede acceder a los perfiles de consulta de los trabajos ejecutados en almacenes SQL y en el proceso sin servidor. Para los trabajos ejecutados en un proceso sin servidor, consulte Visualización de los detalles de la consulta para ejecuciones de trabajos para saber cómo ver los detalles de consulta en la interfaz de usuario de los trabajos.
Pasos siguientes
- Obtenga información sobre cómo acceder a las métricas de consulta mediante la API del historial de consultas.
- Obtenga más información sobre el historial de consultas.