Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo, se proporciona una introducción general a los objetos del área de trabajo de Azure Databricks. Puedes crear, ver y organizar objetos del área de trabajo en el explorador del área de trabajo entre personas.
Nota sobre cómo asignar nombres a los recursos del área de trabajo
El nombre completo de un recurso del área de trabajo consta de su nombre base y su extensión de archivo. Por ejemplo, la extensión de archivo de un cuaderno puede ser .py, .sql, .scala, .ry .ipynb dependiendo del idioma y el formato del cuaderno.
Al crear un recurso de cuaderno, su nombre base y su nombre completo (el nombre base concatenado con la extensión de archivo) debe ser único dentro de cualquier carpeta del área de trabajo. Al asignar un nombre a un recurso, Databricks comprueba si cumple estos criterios agregándole la extensión de archivo. Si el nombre completo coincide con un archivo existente en la carpeta, ese nombre no se permite y debe elegir un nuevo nombre de cuaderno. Por ejemplo, si intenta crear un cuaderno de Python (en formato de origen de Python) denominado test en la misma carpeta que un archivo de Python denominado test.py, no se permitirá.
Clústeres
Los clústeres de Azure Databricks de ciencia de datos e ingeniería y Databricks Mosaic AI proporcionan una plataforma unificada para varios casos de uso, como la ejecución de canalizaciones ETL de producción, el análisis de streaming, el análisis ad hoc y el aprendizaje automático. Un clúster es un tipo de recurso de proceso de Azure Databricks. Otros tipos de recursos de proceso incluyen los almacenes de SQL de Azure Databricks.
Para obtener información detallada sobre cómo administrar y usar clústeres, consulte Proceso.
Cuadernos
Un cuaderno es una interfaz basada en Internet para documentos que contienen una serie de celdas ejecutables (comandos) que funcionan en archivos y tablas, visualizaciones y texto narrativo. Los comandos se pueden ejecutar en secuencia, haciendo referencia a la salida de uno o varios comandos ejecutados anteriormente.
Los cuadernos son un mecanismo para ejecutar código en Azure Databricks. El otro mecanismo son los trabajos.
Para obtener información detallada sobre cómo administrar y usar cuadernos, consulte Cuadernos de Databricks.
Trabajos
Las tareas son un mecanismo para ejecutar código en Azure Databricks. El otro mecanismo son los cuadernos.
Para obtener información detallada sobre cómo administrar y usar trabajos, consulte Trabajos de Lakeflow.
Bibliotecas
Una biblioteca pone disponible código de terceros o desarrollado localmente para cuadernos y trabajos que se ejecutan en los clústeres.
Para obtener información detallada sobre cómo administrar y usar bibliotecas, consulte Instalación de bibliotecas.
Datos
Puede importar datos a un sistema de archivos distribuido y que esté montado en un área de trabajo de Azure Databricks, y trabajar con ellos en clústeres y cuadernos de Azure Databricks. También puede usar una amplia variedad de orígenes de datos de Apache Spark para acceder a los datos.
Para obtener información detallada sobre cómo cargar datos, consulte Conectores estándar en Lakeflow Connect.
Archivos
Importante
Esta característica está en versión preliminar pública.
En Databricks Runtime 11.3 LTS y versiones posteriores, puede crear y usar archivos arbitrarios en el área de trabajo de Databricks. Los archivos pueden ser de cualquier tipo. Entre los ejemplos de tipos de archivo comunes se incluyen:
- Archivos
.pyusados en módulos personalizados. - Archivos
.md, comoREADME.md. -
.csvu otros archivos de datos pequeños. - Archivos
.txt. - Archivos de registro.
Para obtener información detallada sobre el uso de archivos, consulte Trabajo con archivos en Azure Databricks. Para obtener información sobre cómo usar archivos para modularizar el código a medida que desarrolla con cuadernos de Databricks, consulta Uso compartido de código entre cuadernos de Databricks
Directorios Git
Las carpetas Git son carpetas de Azure Databricks cuyo contenido puede tener versiones conjuntas mediante su sincronización con un repositorio de Git remoto. Mediante carpetas Git de Databricks, es posible desarrollar cuadernos en Azure Databricks y usar un repositorio remoto de Git para la colaboración y el control de versiones.
Para obtener información detallada sobre el uso de repositorios, consulte Carpetas de Git de Azure Databricks.
Modelos
El modelo hace referencia a un modelo que esté en el Registro de modelos de MLflow. El Registro de modelos es un almacén de modelos centralizado que le permite administrar el ciclo de vida completo de los modelos de MLflow. Proporciona linaje cronológico de modelos, versionado de modelos, transiciones de etapas y anotaciones y descripciones de modelos y sus versiones.
Para obtener información detallada sobre la administración y el uso de modelos, consulte Administración del ciclo de vida del modelo en Unity Catalog.
Experimentos
Un experimento de MLflow es la unidad principal de organización y control de acceso para las ejecuciones de MLflow, incluidos los seguimientos del agente, las evaluaciones de aplicaciones LLM y las ejecuciones de entrenamiento del modelo de ML. Todas las ejecuciones de MLflow pertenecen a un experimento. Cada experimento le permite visualizar, buscar y comparar ejecuciones, y descargar y ejecutar artefactos o metadatos para su análisis en otras herramientas.
Para obtener información detallada sobre cómo administrar y usar experimentos, consulte Organizar ejecuciones de entrenamiento con experimentos de MLflow.
Consultas
Las consultas son instrucciones SQL que permiten interactuar con los datos. Para más información, consulte Acceso y administración de consultas guardadas.
Panel de control
Los paneles son presentaciones de visualizaciones de consultas y comentarios. Consulte Paneles.
Alertas
Las alertas son notificaciones de que un campo que ha devuelto una consulta ha alcanzado un umbral. Para más información, consulte Alertas de SQL de Databricks.
Referencias a objetos del área de trabajo
Históricamente, los usuarios debían incluir el prefijo de ruta /Workspace para algunas API de Databricks (%sh) pero no para otras (%run, entradas de API REST).
Los usuarios pueden utilizar rutas de áreas de trabajo con el prefijo /Workspace en todas partes. Las referencias antiguas a rutas sin el prefijo /Workspace se redirigen y siguen funcionando. Recomendamos que todas las rutas del área de trabajo lleven el prefijo /Workspace para diferenciarlas de las rutas de Volumen y DBFS.
El prerrequisito para un comportamiento consistente del prefijo de ruta /Workspace es este: No puede haber una carpeta /Workspace en el nivel raíz del área de trabajo. Si tiene una carpeta /Workspace en el nivel raíz y quiere habilitar esta mejora de UX, elimine o cambie el nombre de la carpeta /Workspace creada y póngase en contacto con el equipo de la cuenta de Azure Databricks.
Compartir un archivo, una carpeta o una URL del cuaderno
En el área de trabajo de Azure Databricks, las direcciones URL de los archivos, cuadernos y carpetas del área de trabajo se encuentran en los formatos:
Direcciones URL de archivos del área de trabajo
https://<databricks-instance>/?o=<16-digit-workspace-ID>#files/<16-digit-object-ID>
Direcciones URL de cuadernos
https://<databricks-instance>/?o=<16-digit-workspace-ID>#notebook/<16-digit-object-ID>/command/<16-digit-command-ID>
Direcciones URL de carpetas (área de trabajo y Git)
https://<databricks-instance>/browse/folders/<16-digit-ID>?o=<16-digit-workspace-ID>
Estos vínculos podrían interrumpirse si cualquier carpeta, archivo o cuaderno de la ruta de acceso actual se actualizase con un comando de extracción de Git o se eliminase y se volviese a crear con el mismo nombre. Sin embargo, es posible construir un vínculo basado en la ruta de acceso del área de trabajo para compartirlo con otros usuarios de Databricks con los niveles de acceso adecuados cambiando a un vínculo en este formato:
https://<databricks-instance>/?o=<16-digit-workspace-ID>#workspace/<full-workspace-path-to-file-or-folder>
Los vínculos a carpetas, cuadernos y archivos se pueden compartir reemplazando todo lo de la dirección URL después de ?o=<16-digit-workspace-ID> por la ruta de acceso al archivo, la carpeta o el cuaderno de la raíz del área de trabajo. Si comparte una dirección URL a una carpeta, quite también /browse/folders/<16-digit-ID> de la dirección URL original.
Para obtener la ruta de acceso del archivo, abra el menú contextual haciendo clic con el botón derecho en la carpeta, cuaderno o archivo del área de trabajo que desee compartir y seleccione Copiar dirección URL o ruta de acceso>Ruta de acceso completa. Anteponga #workspace a la ruta de acceso del archivo que acaba de copiar y anexe la cadena resultante después de ?o=<16-digit-workspace-ID> para que coincida con el formato de dirección URL anterior.
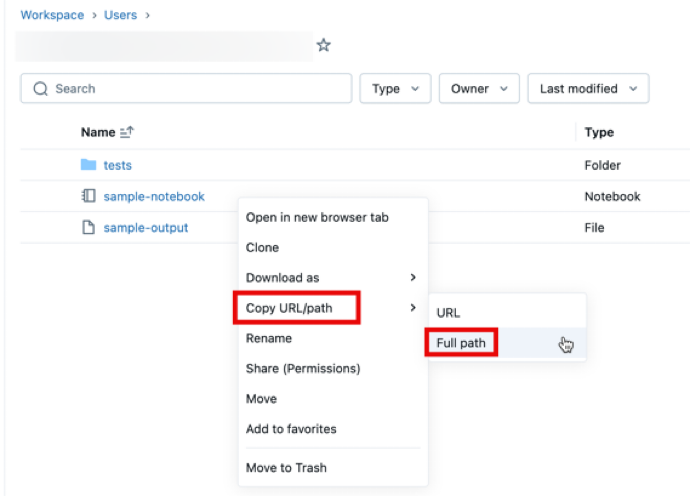
Ejemplo de formulación de direcciones URL n.º 1: direcciones URL de carpetas
Para compartir la URL de la carpeta del área de trabajo https://<databricks-instance>/browse/folders/1111111111111111?o=2222222222222222, quite la subcadena browse/folders/1111111111111111 de la URL. Agregue #workspace seguido de la ruta de acceso al objeto del área de trabajo o carpeta que desee compartir.
En este caso, la ruta de acceso del área de trabajo es a una carpeta: /Workspace/Users/user@example.com/team-git/notebooks. Después de copiar la ruta de acceso completa desde el área de trabajo, ya podrá construir el vínculo compartible:
https://<databricks-instance>/?o=2222222222222222#workspace/Workspace/Users/user@example.com/team-git/notebooks
Ejemplo de formulación de direcciones URL n.º 2: direcciones URL de cuadernos
Para compartir la dirección URL del notebook https://<databricks-instance>/?o=1111111111111111#notebook/2222222222222222/command/3333333333333333, elimine #notebook/2222222222222222/command/3333333333333333. Agregue #workspace seguido de la ruta de acceso al objeto del área de trabajo o carpeta.
En este caso, la ruta de acceso del área de trabajo apunta a un cuaderno, /Workspace/Users/user@example.com/team-git/notebooks/v1.0/test-notebook. Después de copiar la ruta de acceso completa desde el área de trabajo, ya podrá construir el vínculo compartible:
https://<databricks-instance>/?o=1111111111111111#workspace/Workspace/Users/user@example.com/team-git/notebooks/v1.0/test-notebook
Ya tiene una dirección URL estable para una ruta de acceso de archivo, carpeta o cuaderno para compartir. Para obtener más información sobre direcciones URL e identificadores, consulte Obtener identificadores para objetos del área de trabajo.