Creación de sistemas avanzados de generación aumentada de recuperación
En el artículo anterior se trataron dos opciones para crear una aplicación de "chat sobre los datos", uno de los principales casos de uso para la inteligencia artificial generativa en empresas:
- Recuperación de generación aumentada (RAG) que complementa el entrenamiento de un modelo de lenguaje grande (LLM) con una base de datos de artículos que se pueden recuperar en función de la similitud con las consultas de los usuarios y pasarlas al LLM para su finalización.
- Ajuste preciso, que amplía el entrenamiento de LLM para comprender más sobre el dominio del problema.
En el artículo anterior también se explicó cuándo usar cada enfoque, pro's y con's de cada enfoque y otras consideraciones.
En este artículo se explora RAG con más profundidad, en concreto, todo el trabajo necesario para crear una solución lista para producción.
En el artículo anterior se muestran los pasos o fases de RAG mediante el diagrama siguiente.
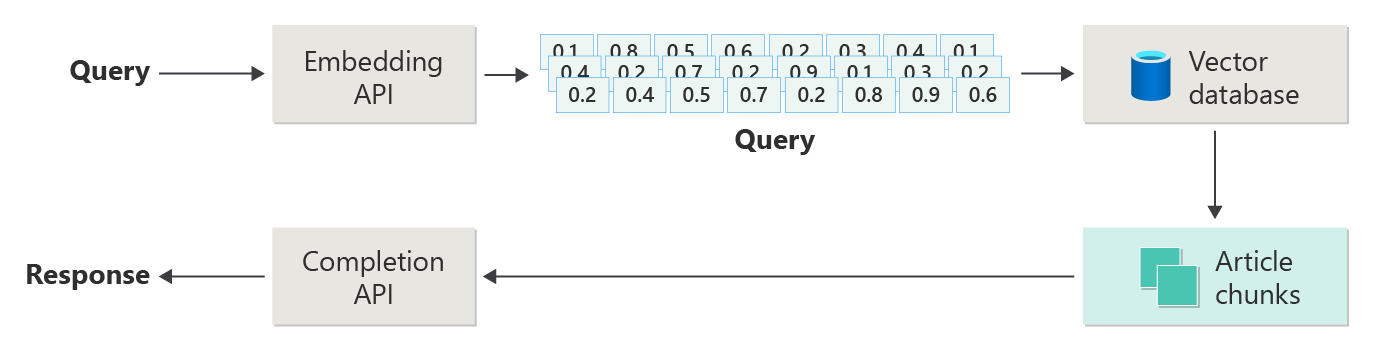
Esta representación se conoce como "RAG naïve" y es una forma útil de comprender primero los mecanismos, roles y responsabilidades necesarios para implementar un sistema de chat basado en RAG.
Sin embargo, una implementación más real tiene muchos más pasos previos y posteriores al procesamiento para preparar los artículos, las consultas y las respuestas para su uso. El siguiente diagrama es una representación más realista de un RAG, a veces denominado "RAG avanzado".

En este artículo se proporciona un marco conceptual para comprender los tipos de preocupaciones previas y posteriores al procesamiento en un sistema de chat basado en RAG real, organizado de la siguiente manera:
- Fase de ingesta
- Fase de canalización de inferencia
- Fase de evaluación
Como información general conceptual, las palabras clave e ideas se proporcionan como contexto y un punto de partida para una exploración e investigación posteriores.
Ingesta
La ingesta se preocupa principalmente por almacenar los documentos de la organización de tal manera que se puedan recuperar fácilmente para responder a la pregunta de un usuario. El desafío es asegurarse de que las partes de los documentos que mejor coincidan con la consulta del usuario se encuentran y se usan durante la inferencia. La coincidencia se logra principalmente a través de incrustaciones vectorizadas y una búsqueda de similitud coseno. Sin embargo, se facilita al comprender la naturaleza del contenido (patrones, formularios, etc.) y la estrategia de organización de datos (la estructura de los datos cuando se almacenan en la base de datos vectorial).
Para ello, los desarrolladores deben tener en cuenta lo siguiente:
- Procesamiento previo y extracción de contenido
- Estrategia de fragmentación
- Organización de fragmentación
- Estrategia de actualización
Procesamiento previo y extracción de contenido
El contenido limpio y preciso es una de las mejores maneras de mejorar la calidad general de un sistema de chat basado en RAG. Para ello, los desarrolladores deben empezar a analizar la forma y la forma de los documentos que se van a indexar. ¿Los documentos se ajustan a los patrones de contenido especificados, como la documentación? Si no es así, ¿qué tipos de preguntas pueden responder los documentos?
Como mínimo, los desarrolladores deben crear pasos en la canalización de ingesta para:
- Estandarizar formatos de texto
- Controlar caracteres especiales
- Quitar contenido no relacionado y obsoleto
- Cuenta del contenido con versiones
- Cuenta de la experiencia de contenido (pestañas, imágenes, tablas)
- Extracción de metadatos
Parte de esta información (por ejemplo, metadatos) puede ser útil mantenerse con el documento de la base de datos vectorial para su uso durante el proceso de recuperación y evaluación en la canalización de inferencia, o bien combinarlo con el fragmento de texto para convencer a la inserción de vectores del fragmento.
Estrategia de fragmentación
Los desarrolladores deben decidir cómo dividir un documento más largo en fragmentos más pequeños. Esto puede mejorar la relevancia del contenido complementario enviado al LLM para responder a la consulta del usuario con precisión. Además, los desarrolladores deben tener en cuenta cómo usar los fragmentos tras la recuperación. Este es un área en la que los diseñadores de sistemas deben realizar algunas investigaciones sobre las técnicas usadas en el sector y realizar algunas experimentaciones, incluso probarla en una capacidad limitada en su organización.
Los desarrolladores deben tener en cuenta lo siguiente:
- Optimización del tamaño del fragmento: determine cuál es el tamaño ideal del fragmento y cómo designar un fragmento. ¿Por sección? ¿Por párrafo? ¿Por frase?
- Fragmentos de ventana deslizante y superpuestos : determine cómo dividir el contenido en fragmentos discretos. ¿O se superponerán los fragmentos? ¿O ambos (ventana deslizante)?
- Small2Big : al fragmentar en un nivel pormenorizados como una sola oración, ¿se organizará el contenido de tal manera que sea fácil encontrar las oraciones vecinas o el párrafo contenedor? (Consulte "Organización de fragmentación"). Recuperar esta información adicional y proporcionarla al LLM podría proporcionarle más contexto al responder a la consulta del usuario.
Organización de fragmentación
En un sistema RAG, la organización de datos en la base de datos vectorial es fundamental para una recuperación eficaz de la información pertinente para aumentar el proceso de generación. Estos son los tipos de estrategias de indexación y recuperación que los desarrolladores pueden tener en cuenta:
- Índices jerárquicos : este enfoque implica la creación de varias capas de índices, donde un índice de nivel superior (índice de resumen) reduce rápidamente el espacio de búsqueda a un subconjunto de fragmentos potencialmente relevantes y un índice de segundo nivel (índice de fragmentos) proporciona punteros más detallados a los datos reales. Este método puede acelerar significativamente el proceso de recuperación, ya que reduce primero el número de entradas que se van a examinar en el índice detallado filtrando por el índice de resumen.
- Índices especializados: se pueden usar índices especializados, como bases de datos relacionales o basadas en grafos, según la naturaleza de los datos y las relaciones entre fragmentos. Por ejemplo:
- Los índices basados en grafos son útiles cuando los fragmentos tienen información o relaciones interconectadas que pueden mejorar la recuperación, como redes de citas o gráficos de conocimiento.
- Las bases de datos relacionales pueden ser eficaces si los fragmentos están estructurados en un formato tabular donde se podrían usar consultas SQL para filtrar y recuperar datos basados en atributos o relaciones específicos.
- Índices híbridos : un enfoque híbrido combina varias estrategias de indexación para aprovechar los puntos fuertes de cada uno. Por ejemplo, los desarrolladores pueden usar un índice jerárquico para el filtrado inicial y un índice basado en grafos para explorar las relaciones entre fragmentos dinámicamente durante la recuperación.
Optimización de alineación
Para mejorar la relevancia y la precisión de los fragmentos recuperados, puede ser beneficioso alinearlos más estrechamente con los tipos de preguntas o consultas que están diseñados para responder. Una estrategia para lograr esto es generar e insertar una pregunta hipotética para cada fragmento que representa la pregunta que el fragmento es más adecuado para responder. Esto ayuda de varias maneras:
- Coincidencia mejorada: durante la recuperación, el sistema puede comparar la consulta entrante con estas preguntas hipotéticas para encontrar la mejor coincidencia, lo que mejora la relevancia de los fragmentos capturados.
- Datos de entrenamiento para modelos de Machine Learning: estos emparejamientos de preguntas y fragmentos pueden servir como datos de entrenamiento para mejorar los modelos de aprendizaje automático subyacentes al sistema RAG, lo que le ayuda a aprender qué tipos de preguntas se responden mejor mediante los fragmentos.
- Control directo de consultas: si una consulta de usuario real coincide estrechamente con una pregunta hipotética, el sistema puede recuperar y usar rápidamente el fragmento correspondiente, lo que acelera el tiempo de respuesta.
La pregunta hipotética de cada fragmento actúa como un tipo de "etiqueta" que guía el algoritmo de recuperación, lo que hace que sea más centrado y contextualmente consciente. Esto es útil en escenarios en los que los fragmentos cubren una amplia gama de temas o tipos de información.
Estrategias de actualización
Si su organización necesita indexar documentos que se actualizan con frecuencia, es esencial mantener un corpus actualizado para asegurarse de que el componente del recuperador (la lógica del sistema responsable de realizar la consulta en la base de datos vectorial y devolver los resultados) puede acceder a la información más actual. Estas son algunas estrategias para actualizar la base de datos vectorial en estos sistemas:
- Actualizaciones incrementales:
- Intervalos regulares: programe actualizaciones a intervalos regulares (por ejemplo, diarias, semanales) en función de la frecuencia de los cambios del documento. Este método garantiza que la base de datos se actualice periódicamente.
- Actualizaciones basadas en desencadenadores: implemente un sistema en el que las actualizaciones desencadenen la reindización. Por ejemplo, cualquier modificación o adición de un documento podría iniciar automáticamente una reindexación de las secciones afectadas.
- Actualizaciones parciales:
- Reindización selectiva: en lugar de volver a indexar toda la base de datos, actualice de forma selectiva solo las partes del corpus que han cambiado. Esto puede ser más eficaz que la reindización completa, especialmente para conjuntos de datos grandes.
- Codificación delta: almacene solo las diferencias entre los documentos existentes y sus versiones actualizadas. Este enfoque reduce la carga de procesamiento de datos evitando la necesidad de procesar datos sin cambios.
- Control de versiones:
- Creación de instantáneas: mantenga las versiones del corpus del documento en distintos momentos en el tiempo. Esto permite al sistema revertir o hacer referencia a versiones anteriores si es necesario y proporciona un mecanismo de copia de seguridad.
- Control de versiones del documento: use un sistema de control de versiones para realizar un seguimiento de los cambios en los documentos sistemáticamente. Esto ayuda a mantener el historial de cambios y puede simplificar el proceso de actualización.
- Actualizaciones en tiempo real:
- Procesamiento de flujos: use tecnologías de procesamiento de flujos para actualizar la base de datos vectorial en tiempo real a medida que se realizan cambios en los documentos. Esto puede ser fundamental para las aplicaciones en las que las escalas de tiempo de información son primordiales.
- Consultas dinámicas: en lugar de confiar únicamente en vectores preindados, implemente un mecanismo para consultar datos activos para las respuestas más actualizadas, posiblemente combinándolo con resultados almacenados en caché para mejorar la eficacia.
- Técnicas de optimización:
- Procesamiento por lotes: acumula los cambios y los procesa en lotes para optimizar el uso de recursos y reducir la sobrecarga causada por actualizaciones frecuentes.
- Enfoques híbridos: combine varias estrategias, como el uso de actualizaciones incrementales para cambios menores y reindización completa para actualizaciones principales o cambios estructurales en el corpus del documento.
Elegir la estrategia de actualización adecuada o combinación de estrategias depende de requisitos específicos, como el tamaño del corpus del documento, la frecuencia de las actualizaciones, la necesidad de datos en tiempo real y la disponibilidad de recursos. Cada enfoque tiene sus ventajas en términos de complejidad, costo y latencia de actualización, por lo que es esencial evaluar estos factores en función de las necesidades específicas de la aplicación.
Canalización de inferencia
Ahora que los artículos se han fragmentado, vectorizado y almacenado en una base de datos vectorial, el foco se convierte en desafíos al finalizar.
- ¿La consulta del usuario está escrita de tal manera para obtener los resultados del sistema que el usuario está buscando?
- ¿La consulta del usuario infringe alguna de nuestras directivas?
- ¿Cómo se vuelve a escribir la consulta del usuario para mejorar sus posibilidades de encontrar coincidencias más cercanas en la base de datos vectorial?
- ¿Cómo se evalúan los resultados de la consulta para asegurarse de que los fragmentos de artículo se alinean con la consulta?
- ¿Cómo se evalúan y modifican los resultados de la consulta antes de pasarlos al LLM para asegurarse de que los detalles más relevantes se incluyen en la finalización de LLM?
- ¿Cómo se evalúa la respuesta de LLM para asegurarse de que la finalización de LLM responde a la consulta original del usuario?
- ¿Cómo garantizamos que la respuesta de LLM cumpla con nuestras directivas?
Como puede ver, hay muchas tareas que los desarrolladores deben tener en cuenta, principalmente en forma de:
- Procesamiento previo de entradas para optimizar la probabilidad de obtener los resultados deseados
- Salidas posteriores al procesamiento para garantizar los resultados deseados
Tenga en cuenta que toda la canalización de inferencia se está ejecutando en tiempo real. Aunque no hay ninguna manera correcta de diseñar la lógica que realiza los pasos previos y posteriores al procesamiento, es probable que sea una combinación de lógica de programación y llamadas adicionales a un LLM. Una de las consideraciones más importantes es el equilibrio entre la creación de la canalización más precisa y compatible posible y el costo y la latencia necesarios para que se produzca.
Echemos un vistazo a cada fase para identificar estrategias específicas.
Pasos previos al procesamiento de consultas
El procesamiento previo de consultas se produce inmediatamente después de que el usuario envíe su consulta, como se muestra en este diagrama:

El objetivo de estos pasos es asegurarse de que el usuario está haciendo preguntas dentro del ámbito de nuestro sistema (y no intentando "jailbreak" el sistema para que haga algo no deseado) y prepare la consulta del usuario para aumentar la probabilidad de que busque los mejores fragmentos de artículo posibles mediante la búsqueda de la similitud de coseno / "vecino más cercano".
Comprobación de directivas : este paso podría implicar lógica que identifica, quita, marca o rechaza cierto contenido. Algunos ejemplos pueden incluir la eliminación de información de identificación personal, la eliminación de expletivos y la identificación de intentos de "jailbreak". Jailbreaking hace referencia a los métodos que los usuarios pueden emplear para eludir o manipular las directrices integradas de seguridad, ética o operativa del modelo.
Reescritura de consultas: esto podría ser cualquier cosa desde la expansión de acrónimos y la eliminación de la jerga para volver a formular la pregunta para formularla de forma más abstracta para extraer conceptos y principios de alto nivel ("solicitud paso atrás").
Una variación en la solicitud de paso atrás es una inserción hipotética de documentos (HyDE), que usa el LLM para responder a la pregunta del usuario, crea una inserción para esa respuesta (la inserción hipotética de documentos) y usa esa inserción para realizar una búsqueda en la base de datos vectorial.
Subconsultas
Este paso de procesamiento se refiere a la consulta original. Si la consulta original es larga y compleja, puede ser útil dividirla mediante programación en varias consultas más pequeñas y, a continuación, combinar todas las respuestas.
Por ejemplo, considere una pregunta relacionada con los descubrimientos científicos, especialmente en el campo de la física. La consulta del usuario podría ser: "¿Quién hizo contribuciones más significativas a la física moderna, Albert Einstein o Niels Bohr?"
Esta consulta puede ser compleja de controlar directamente porque las "contribuciones significativas" pueden ser subjetivas y multifacéticas. Dividirla en subconsultas puede hacer que sea más fácil de administrar:
- Subconsulta 1: "¿Cuáles son las contribuciones clave de Albert Einstein a la física moderna?"
- Subconsulta 2: "¿Cuáles son las contribuciones clave de Niels Bohr a la física moderna?"
Los resultados de estas subconsultas detallarían las principales teorías y descubrimientos de cada físico. Por ejemplo:
- Para Einstein, las contribuciones podrían incluir la teoría de la relatividad, el efecto fotoeléctrico y E=mc^2.
- Para Bohr, las contribuciones podrían incluir su modelo del átomo de hidrógeno, su trabajo sobre la mecánica cuántica y su principio de complementariedad.
Una vez que se describen estas contribuciones, se pueden evaluar para determinar:
- Subconsulta 3: "¿Cómo han afectado las teorías de Einstein al desarrollo de la física moderna?"
- Subconsulta 4: "¿Cómo han afectado las teorías de Bohr al desarrollo de la física moderna?"
Estas subconsultas explorarían la influencia del trabajo de cada científico en el campo, como la forma en que las teorías de Einstein llevaron a los avances en la cosmología y la teoría cuántica, y cómo el trabajo de Bohr contribuyó a la comprensión de la estructura atómica y la mecánica cuántica.
La combinación de los resultados de estas subconsultas puede ayudar al modelo de lenguaje a formar una respuesta más completa con respecto a quién hizo contribuciones más significativas a la física moderna, en función de la extensión y el impacto de sus avances teóricos. Este método simplifica la consulta compleja original tratando con componentes más específicos y respondibles y, a continuación, sintetizando esos hallazgos en una respuesta coherente.
Enrutador de consulta
Es posible que su organización decida dividir su corpus de contenido en varios almacenes de vectores o sistemas de recuperación completos. En ese caso, los desarrolladores pueden emplear un enrutador de consultas, que es un mecanismo que determina inteligentemente qué índices o motores de recuperación usar en función de la consulta proporcionada. La función principal de un enrutador de consultas es optimizar la recuperación de información seleccionando la base de datos o índice más adecuada que puede proporcionar las mejores respuestas a una consulta específica.
El enrutador de consultas normalmente funciona en un momento después de que el usuario haya formulado la consulta, pero antes de que se envíe a cualquier sistema de recuperación. Este es un flujo de trabajo simplificado:
- Análisis de consultas: LLM u otro componente analiza la consulta entrante para comprender su contenido, contexto y el tipo de información que probablemente se necesite.
- Selección de índice: en función del análisis, el enrutador de consultas selecciona uno o varios índices potencialmente disponibles. Cada índice puede optimizarse para distintos tipos de datos o consultas, por ejemplo, algunos podrían ser más adecuados para las consultas fácticas, mientras que otros podrían destacar en proporcionar opiniones o contenido subjetiva.
- Distribución de consultas: la consulta se envía al índice seleccionado.
- Agregación de resultados: las respuestas de los índices seleccionados se recuperan y, posiblemente, se agregan o procesan más para formar una respuesta completa.
- Generación de respuestas: el paso final implica generar una respuesta coherente basada en la información recuperada, posiblemente integrando o sintetizando contenido de varios orígenes.
Su organización puede usar varios motores de recuperación o índices para los siguientes casos de uso:
- Especialización de tipos de datos: algunos índices pueden especializarse en artículos de noticias, otros en documentos académicos, y otros en contenido web general o bases de datos específicas, como las de información médica o legal.
- Optimización de tipos de consulta: es posible que determinados índices se optimicen para búsquedas fácticas rápidas (por ejemplo, fechas, eventos), mientras que otras podrían ser mejores para tareas de razonamiento complejas o consultas que requieren conocimiento profundo del dominio.
- Diferencias algorítmicas: se pueden usar algoritmos de recuperación diferentes en distintos motores, como búsquedas de similitud basadas en vectores, búsquedas basadas en palabras clave tradicionales o modelos de comprensión semántica más avanzados.
Imagine un sistema basado en RAG utilizado en un contexto de asesoramiento médico. El sistema tiene acceso a varios índices:
- Índice de un documento de investigación médica optimizado para explicaciones detalladas y técnicas.
- Índice de casos prácticos clínicos que proporciona ejemplos reales de síntomas y tratamientos.
- Índice de información de mantenimiento general para consultas básicas e información de estado público.
Si un usuario hace una pregunta técnica sobre los efectos biológicos de un nuevo medicamento, el enrutador de consultas podría priorizar el índice del documento de investigación médica debido a su profundidad y enfoque técnico. Para una pregunta sobre los síntomas típicos de una enfermedad común, sin embargo, el índice de salud general se puede elegir para su contenido amplio y fácil de entender.
Pasos posteriores al procesamiento de recuperación
El procesamiento posterior a la recuperación se produce después de que el componente del recuperador recupere los fragmentos de contenido pertinentes de la base de datos vectorial, como se muestra en el diagrama:

Con los fragmentos de contenido candidatos recuperados, los pasos siguientes son validar que los fragmentos de artículo serán útiles al aumentar el símbolo del sistema LLM y, a continuación, empezar a preparar la solicitud que se presentará al LLM.
Los desarrolladores deben tener en cuenta varios aspectos del mensaje. Se puede omitir un aviso que incluya demasiada información de suplementos y algunos (posiblemente la información más importante). Del mismo modo, una solicitud que incluye información irrelevante podría afectar indebidamente a la respuesta.
Otra consideración es la aguja en un problema de paja , un término que hace referencia a una peculiaridad conocida de algunas LLM donde el contenido al principio y el final de un mensaje tienen mayor peso para el LLM que el contenido en el medio.
Por último, se debe tener en cuenta la longitud máxima de la ventana de contexto de LLM y el número de tokens necesarios para completar solicitudes extraordinariamente largas (especialmente cuando se trabaja con consultas a escala).
Para solucionar estos problemas, una canalización de procesamiento posterior a la recuperación puede incluir los pasos siguientes:
- Resultados de filtrado : en este paso, los desarrolladores garantizan que los fragmentos de artículo devueltos por la base de datos vectorial son relevantes para la consulta. Si no es así, el resultado se omite al redactar la solicitud del LLM.
- Volver a clasificar : clasifique los fragmentos de artículo recuperados del almacén de vectores para asegurarse de que los detalles pertinentes se encuentran cerca de los bordes (principio y final) del símbolo del sistema.
- Compresión de mensajes: uso de un modelo pequeño y económico diseñado para combinar y resumir varios fragmentos de artículo en un único mensaje comprimido antes de enviarlo al LLM.
Pasos de procesamiento posteriores a la finalización
El procesamiento posterior a la finalización se produce después de que la consulta del usuario y todos los fragmentos de contenido se hayan enviado al LLM, como se muestra en el diagrama siguiente:

Una vez que el LLM ha completado la solicitud, es el momento de validar la finalización para asegurarse de que la respuesta es precisa. Una canalización de procesamiento posterior a la finalización puede incluir los pasos siguientes:
- Comprobación de hechos: esto podría adoptar muchas formas, pero la intención es identificar las notificaciones específicas realizadas en el artículo que se presentan como hechos y, a continuación, comprobar esos hechos para obtener precisión. Si se produce un error en el paso de comprobación de hechos, podría ser adecuado volver a consultar el LLM con la esperanza de una mejor respuesta o devolver un mensaje de error al usuario.
- Comprobación de directivas : esta es la última línea de defensa para asegurarse de que las respuestas no contengan contenido perjudicial, ya sea para el usuario o la organización.
Evaluación
Evaluar los resultados de un sistema no determinista no es tan sencillo como, por ejemplo, pruebas unitarias o de integración con las que la mayoría de los desarrolladores están familiarizados. Hay varios factores que se deben tener en cuenta:
- ¿Están satisfechos los usuarios con los resultados que obtienen?
- ¿Los usuarios reciben respuestas precisas a sus preguntas?
- ¿Cómo capturamos los comentarios de los usuarios? ¿Tenemos directivas que limiten los datos que podemos recopilar sobre los datos de usuario?
- Para el diagnóstico de las respuestas no satisfactorias, ¿tenemos visibilidad de todo el trabajo que entró en responder a la pregunta? ¿Mantenemos un registro de cada fase en la canalización de inferencia de entradas y salidas para que podamos realizar análisis de la causa principal?
- ¿Cómo podemos realizar cambios en el sistema sin regresión ni degradación de los resultados?
Capturar y actuar sobre los comentarios de los usuarios
Como se mencionó anteriormente, es posible que los desarrolladores necesiten trabajar con el equipo de privacidad de su organización para diseñar mecanismos de captura de comentarios y telemetría, registro, etc. para habilitar análisis forenses y de causa principal en una sesión de consulta determinada.
El siguiente paso es desarrollar una canalización de evaluación. La necesidad de una canalización de evaluación surge de la complejidad y la naturaleza intensiva del análisis de los comentarios textuales y las causas principales de las respuestas proporcionadas por un sistema de inteligencia artificial. Este análisis es fundamental, ya que implica investigar todas las respuestas para comprender cómo la consulta de IA produjo los resultados, comprobar la idoneidad de los fragmentos de contenido usados en la documentación y las estrategias empleadas para dividir estos documentos.
Además, implica considerar los pasos adicionales previos o posteriores al procesamiento que podrían mejorar los resultados. Este examen detallado suele descubrir lagunas de contenido, especialmente cuando no existe documentación adecuada en respuesta a la consulta de un usuario.
La creación de una canalización de evaluación, por lo tanto, resulta esencial para administrar la escala de estas tareas de forma eficaz. Una canalización eficaz usaría herramientas personalizadas para evaluar las métricas que aproximan la calidad de las respuestas proporcionadas por la inteligencia artificial. Este sistema simplificaría el proceso de determinar por qué se dio una respuesta específica a la pregunta de un usuario, qué documentos se usaron para generar esa respuesta y la eficacia de la canalización de inferencia que procesa las consultas.
Conjunto de datos golden
Una estrategia para evaluar los resultados de un sistema no determinista como un sistema de chat RAG es implementar un "conjunto de datos dorado". Un conjunto de datos dorado es un conjunto mantenido de preguntas con respuestas aprobadas, metadatos (como tema y tipo de pregunta), referencias a documentos de origen que pueden servir como verdad básica para las respuestas e incluso variaciones (expresiones diferentes para capturar la diversidad de cómo los usuarios pueden formular las mismas preguntas).
El "conjunto de datos dorado" representa el "mejor escenario de casos" y permite a los desarrolladores evaluar el sistema para ver el rendimiento y realizar pruebas de regresión al implementar nuevas características o actualizaciones.
Evaluación de daños
El modelado de daños es una metodología destinada a prever posibles daños, detectar deficiencias en un producto que podría suponer riesgos para las personas y desarrollar estrategias proactivas para mitigar dichos riesgos.
Para la herramienta diseñada para evaluar el impacto de la tecnología, especialmente los sistemas de inteligencia artificial, presentaría varios componentes clave basados en los principios de modelado de daños, tal como se describe en los recursos proporcionados.
Las características clave de una herramienta de evaluación de daños pueden incluir:
Identificación de las partes interesadas: la herramienta ayudaría a los usuarios a identificar y clasificar a varias partes interesadas afectadas por la tecnología, incluidos los usuarios directos, las partes afectadas indirectamente y otras entidades, como generaciones futuras o factores no humanos, como preocupaciones ambientales (.
Categorías y descripciones de daños: incluiría una lista completa de posibles daños, como la pérdida de privacidad, la angustia emocional o la explotación económica. La herramienta podría guiar al usuario a través de varios escenarios que ilustran cómo la tecnología podría causar estos daños, lo que ayuda a evaluar las consecuencias deseadas e imprevistas.
Evaluaciones de gravedad y probabilidad: la herramienta permitiría a los usuarios evaluar la gravedad y la probabilidad de cada daño identificado, lo que les permite priorizar qué problemas abordar primero. Esto podría incluir evaluaciones cualitativas y podría ser compatible con los datos cuando están disponibles.
Estrategias de mitigación: al identificar y evaluar daños, la herramienta sugeriría posibles estrategias de mitigación. Esto podría incluir cambios en el diseño del sistema, más medidas de seguridad o soluciones tecnológicas alternativas que minimicen los riesgos identificados.
Mecanismos de comentarios: la herramienta debe incorporar mecanismos para recopilar comentarios de las partes interesadas, lo que garantiza que el proceso de evaluación de daños es dinámico y responde a nuevas perspectivas e información.
Documentación e informes: para ayudar a la transparencia y la rendición de cuentas, la herramienta facilitaría la creación de informes detallados que documentan el proceso de evaluación de daños, los resultados y las acciones realizadas para mitigar los posibles riesgos.
Estas características no solo ayudarían a identificar y mitigar los riesgos, sino también a diseñar sistemas de inteligencia artificial más éticos y responsables considerando un amplio espectro de impactos desde el principio.
Para más información, vea:
Prueba y comprobación de las medidas de seguridad
En este artículo se describen varios procesos destinados a mitigar la posibilidad de que el sistema de chat basado en RAG se pueda aprovechar o poner en peligro. La formación de equipos rojos desempeña un papel fundamental para garantizar que las mitigaciones sean eficaces. La formación de equipos rojos implica simular las acciones de un adversario dirigidas a la aplicación para descubrir posibles puntos débiles o vulnerabilidades. Este enfoque es especialmente fundamental para abordar el riesgo significativo de jailbreaking.
Para probar y comprobar eficazmente las medidas de seguridad de un sistema de chat basado en RAG, los desarrolladores deben evaluar rigurosamente estos sistemas en varios escenarios en los que se podrían probar estas directrices. Esto no solo garantiza la solidez, sino que también ayuda a ajustar las respuestas del sistema para cumplir estrictamente los estándares éticos definidos y los procedimientos operativos.
Consideraciones finales que podrían influir en las decisiones de diseño de la aplicación
Esta es una breve lista de aspectos que se deben tener en cuenta y otros aspectos de este artículo que afectan a las decisiones de diseño de aplicaciones:
- Reconozca la naturaleza no determinista de la inteligencia artificial generativa en su diseño, planeando la variabilidad en las salidas y configurando mecanismos para garantizar la coherencia y relevancia en las respuestas.
- Evalúe las ventajas de preprocesar las solicitudes del usuario frente al posible aumento de la latencia y los costos. Simplificar o modificar las solicitudes antes del envío podría mejorar la calidad de la respuesta, pero podría agregar complejidad y tiempo al ciclo de respuesta.
- Investigue estrategias para paralelizar solicitudes LLM para mejorar el rendimiento. Este enfoque podría reducir la latencia, pero requiere una administración cuidadosa para evitar una mayor complejidad y posibles implicaciones en los costos.
Si desea empezar a experimentar con la creación de una solución de IA generativa inmediatamente, se recomienda echar un vistazo a Introducción al chat con su propio ejemplo de datos para Python. También hay versiones del tutorial disponibles en .NET, Java y JavaScript.