Federación en varios sitios y regiones
Muchas soluciones sofisticadas requieren que las mismas secuencias de eventos estén disponibles para su consumo en varias ubicaciones, o bien requieren que se recopilen las secuencias de eventos en varias ubicaciones y luego se consoliden en una ubicación específica para su consumo. También suele ser necesario enriquecer o reducir las secuencias de eventos o realizar conversiones de formato de evento, también para dentro de una única región y solución.
En la práctica, esto significa que la solución mantendrá varios Event Hubs, a menudo en diferentes regiones y espacios de nombres de Event Hubs, y luego replicará los eventos entre ellos. También puede intercambiar eventos con orígenes y destinos como Azure Service Bus, Azure IoT Hub o Apache Kafka.
Mantener varios Event Hubs activos en diferentes regiones también permite a los clientes elegir y cambiar entre ellos si se combina su contenido, lo que hace que el sistema global sea más resistente a los problemas de disponibilidad regional.
En este capítulo "Federación" se explican los patrones de federación y cómo se obtienen estos patrones con los runtimes de Azure Stream Analytics sin servidor o Azure Functions, con la opción de tener su propio código de transformación o enriquecimiento en la ruta del flujo de eventos.
Patrones de federación
Existen muchos motivos posibles por los que puede querer trasladar eventos entre distintos Event Hubs u otros orígenes y destinos. En esta sección, se enumeran los patrones más importantes y también se proporciona un vínculo a instrucciones más detalladas para los patrones respectivos.
- Resistencia frente a eventos de disponibilidad regional
- Optimización de la latencia
- Validación, reducción y enriquecimiento
- Integración con servicios de análisis
- Consolidación y normalización de secuencias de eventos
- División y enrutamiento de secuencias de eventos
- Proyecciones de registros
Resistencia frente a eventos de disponibilidad regional
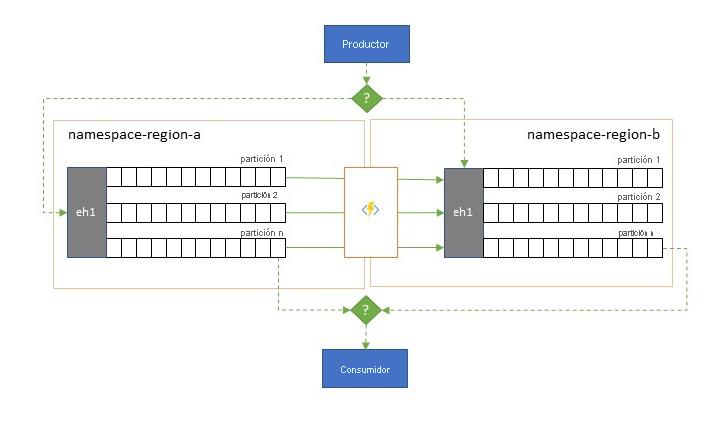
Aunque la disponibilidad y la confiabilidad máximas son las prioridades operativas principales de Event Hubs, hay muchas maneras en las que un productor o consumidor puede ver impedida la comunicación con su instancia de Event Hubs "principal" asignada, debido a problemas de red o de resolución de nombres, o si una instancia de Event Hubs deja de responder temporalmente o devuelve errores.
Estas condiciones no son tan "desastrosas" como para abandonar totalmente la implementación regional como podría pasar en una situación de recuperación ante desastres. Sin embargo, el escenario empresarial de algunas aplicaciones podría estar ya afectado por eventos de disponibilidad que no duren más de unos minutos o incluso segundos.
Hay dos patrones fundamentales para abordar tales escenarios:
- El patrón de replicación se usa para replicar el contenido de una instancia de Event Hubs principal en una instancia de Event Hubs secundaria; con lo cual, la aplicación usará la instancia de Event Hubs principal para generar y consumir eventos y la secundaria actuará como opción de reserva para el caso en que la instancia de Event Hubs principal deje de estar disponible. Puesto que la replicación es unidireccional, desde la instancia principal a la secundaria, un cambio de productores y consumidores de una instancia principal no disponible a la secundaria hará que la instancia principal anterior deje de recibir nuevos eventos y, por lo tanto, ya no estará actualizada. Por consiguiente, la replicación pura solo es adecuada para escenarios de conmutación por error unidireccionales. Una vez realizada la conmutación por error, se abandona la instancia principal anterior y se debe crear una nueva instancia de Event Hubs secundaria en una región de destino diferente.
- El patrón de combinación amplía el patrón de replicación mediante la realización de una combinación continua del contenido de dos o más Event Hubs. Cada evento producido originalmente en una de las instancias de Event Hubs incluidas en el esquema se replica en la otra instancia de Event Hubs. A medida que se replican los eventos, se anotan para que el proceso de replicación del destino de replicación los omita posteriormente. Los resultados del uso del patrón de combinación son dos o más Event Hubs que contendrán el mismo conjunto de eventos en un modo coherente.
En cualquier caso, el contenido de Event Hubs no será idéntico. Los eventos de cualquier productor, agrupados por la misma clave de partición, aparecerán en el mismo orden relativo que en el que se enviaron originalmente, pero el orden absoluto de los eventos puede ser diferente. Esto es especialmente cierto en los escenarios en los que el número de particiones de las instancias de Event Hubs de origen y destino son diferentes, lo que es deseable en algunos de los patrones extendidos que se describen aquí. Un separador o enrutador puede obtener un segmento de una instancia de Event Hubs mucho más grande con cientos de particiones y canalizarlo a una instancia de Event Hubs más pequeña con solo unas pocas particiones, más adecuada para controlar el subconjunto con recursos de procesamiento limitados. Por el contrario, una consolidación puede canalizar datos de varias instancias de Event Hubs más pequeñas a una sola instancia de Event Hubs más grande con más particiones para hacer frente a las necesidades de procesamiento y rendimiento consolidadas.
El criterio para mantener juntos los eventos es la clave de partición y no el id. de partición original. En la descripción del patrón de replicación se explican más consideraciones sobre el orden relativo y cómo realizar una conmutación por error de una instancia de Event Hubs a la siguiente, sin depender del mismo ámbito de desplazamientos de secuencias.
Orientación:
Optimización de la latencia
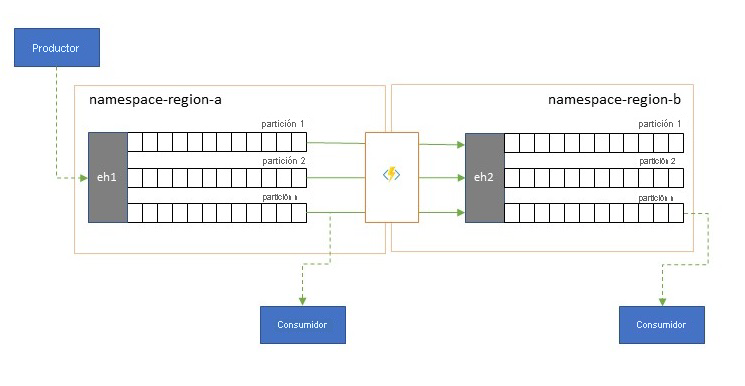
Los productores escriben una vez las secuencias de eventos, pero los consumidores de eventos pueden leerlas cualquier número de veces. En el caso de los escenarios en que varios consumidores comparten una secuencia de eventos de una región y es necesario que accedan a ella de forma repetida durante el procesamiento analítico que reside en una región distinta, o con todas las demandas que podrían colapsar los consumidores simultáneos, puede ser beneficioso colocar una copia de la secuencia de eventos cerca del procesador de análisis para reducir la latencia de ida y vuelta.
Ejemplos de cuándo es preferible la replicación en vez de consumir eventos de forma remota desde distintas regiones son especialmente aquellos en los que las regiones están muy alejadas, por ejemplo, Europa y Australia están casi en las antípodas geográficamente y las latencias de red pueden superar con facilidad los 250 ms para cualquier acción de ida y vuelta. No se puede acelerar la velocidad de la luz, pero se puede reducir el número de viajes de ida y vuelta de alta latencia para interactuar con los datos.
Orientación:
Validación, reducción y enriquecimiento
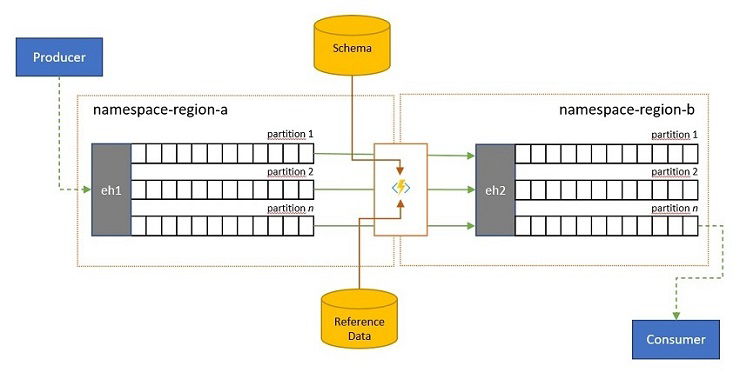
Los clientes externos a su solución pueden enviar secuencias de eventos a una instancia de Event Hubs. Esas secuencias de eventos pueden requerir que se compruebe la compatibilidad de los eventos enviados externamente con un esquema determinado y que se quiten los eventos no compatibles.
En los escenarios en los que los clientes tienen un ancho de banda muy restringido, como es el caso de muchos escenarios de "Internet de las cosas" con ancho de banda medido, o cuando los eventos se envían originalmente a través de redes que no son IP con tamaños de paquete restringidos, es posible que los eventos tengan que enriquecerse con datos de referencia para agregar más contexto y para que los procesadores de eventos posteriores puedan usarlos.
En otros casos, especialmente cuando se consolidan las secuencias, es posible que los datos de eventos tengan que reducirse en complejidad o a un tamaño reducido omitiendo algunos detalles.
Cualquiera de estas operaciones puede realizarse como parte de los flujos de replicación, consolidación o combinación.
Orientación:
Integración con servicios de análisis
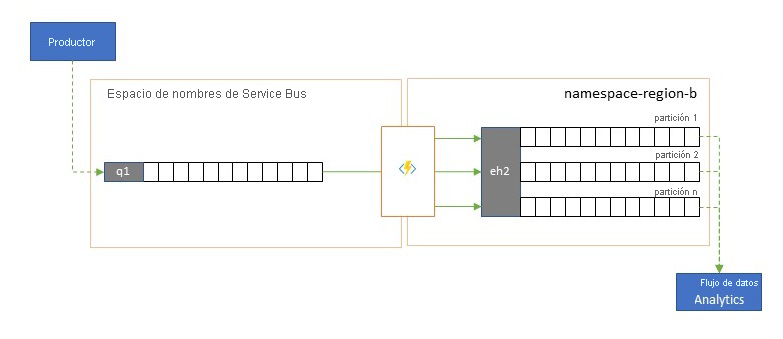
Algunos de los servicios de análisis nativos de nube de Azure, como Azure Stream Analytics o Azure Synapse, funcionan mejor con datos en secuencia u organizados previamente por lotes que se sirven desde Azure Event Hubs, y Azure Event Hubs también permite la integración con varios paquetes de análisis de código abierto, como Apache Samza, Apache Flink, Apache Spark y Apache Storm.
Si la solución usa principalmente Service Bus o Event Grid, puede facilitar el acceso de estos sistemas de análisis a los eventos y también archivarlos con Event Hubs Capture si los canaliza a la instancia de Event Hubs. Event Grid puede hacerlo de forma nativa con su integración de la instancia de Event Hubs, para Service Bus se sigue la orientación de la replicación de Service Bus.
Azure Stream Analytics se integra con Event Hubsdirectamente.
Orientación:
Consolidación y normalización de secuencias de eventos
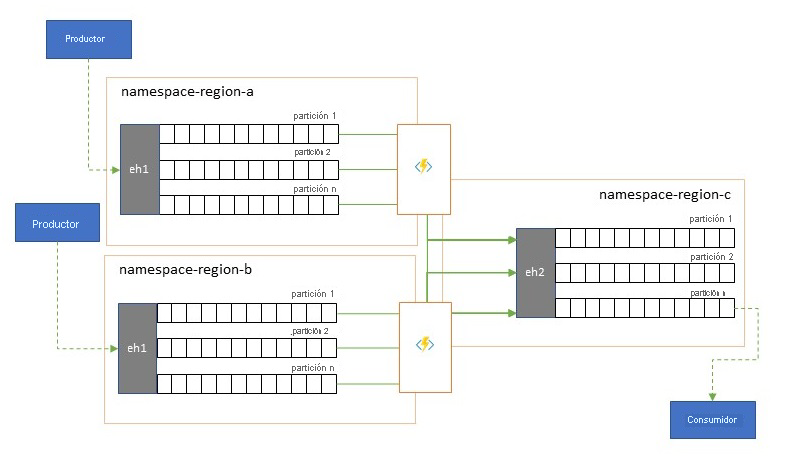
Las soluciones globales suelen constar de superficies regionales que son en gran medida independientes, por ejemplo, tienen sus propias funcionalidades de análisis; sin embargo, las perspectivas de análisis suprarregionales y globales requerirán una perspectiva integrada y, es por eso por lo que una consolidación centralizada de las mismas secuencias de datos se evalúa en las superficies regionales respectivas para la perspectiva local.
La normalización es un tipo de escenario de consolidación en el que dos o más secuencias de eventos entrantes transportan el mismo tipo de evento, pero con distintas estructuras o codificaciones, y los eventos deben transcodificarse o transformarse para poderse consumir.
La normalización también puede incluir trabajo criptográfico, como descifrar cargas cifradas de un extremo a otro y volver a cifrarlas con diferentes claves y algoritmos para el público del consumidor de nivel inferior.
Orientación:
División y enrutamiento de secuencias de eventos
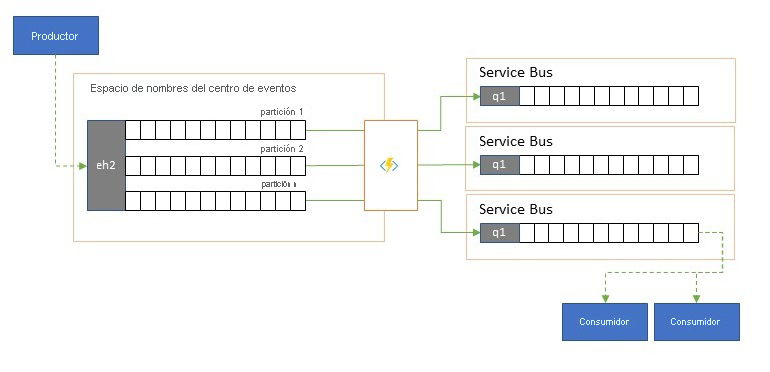
Azure Event Hubs se usa ocasionalmente en escenarios del estilo "suscribir a publicación", donde un torrente entrante de eventos ingeridos supera ampliamente la capacidad de Azure Service Bus o Azure Event Grid, que tienen capacidades de filtrado y distribución de suscripción a publicación nativas y son preferibles para este patrón.
Aunque una verdadera funcionalidad "suscribir a publicación" deja elegir a los suscriptores los eventos que quieren, el patrón de división hace que el productor asigne los eventos a particiones por un modelo de distribución predeterminado y los consumidores designados los extraen exclusivamente de "su" partición. Con el almacenamiento en búfer del tráfico global que hace la instancia de Event Hubs, el contenido de una partición concreta, que representa una fracción del volumen de rendimiento original, se puede replicar en una cola para el consumo confiable, transaccional y competitivo por parte del consumidor.
Muchos escenarios en los que Event Hubs se usa principalmente para mover eventos de una aplicación dentro de una región presentan algunos casos en los que los eventos seleccionados, tal vez solo de una sola partición, tienen que estar disponibles en otro lugar. Este escenario es similar al escenario de división, pero puede usar un enrutador escalable que tenga en cuenta todos los mensajes que llegan a una instancia de Event Hubs y seleccionar de forma exclusiva solo algunos para el enrutamiento posterior, y puede diferenciar los destinos de enrutamiento por metadatos de eventos o contenido.
Orientación:
Proyecciones de registros
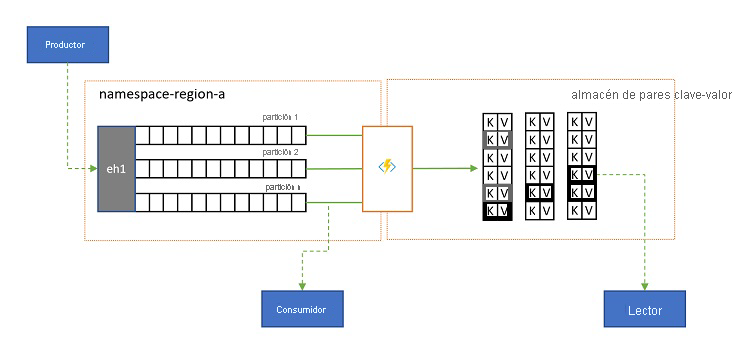
En algunos escenarios, querrá tener acceso al último valor enviado para cualquier subsecuencia de un evento y que comúnmente se distingue por la clave de partición. En Apache Kafka, se suele conseguir habilitando la "compactación del registro" en un tema, que descarta todos los eventos, excepto el etiquetado más recientemente con cualquier clave única. El enfoque de compactación del registro tiene tres desventajas agravantes:
- La compactación requiere una reorganización continua del registro, que es una operación demasiado costosa para un agente que está optimizado para cargas de trabajo de solo anexar.
- La compactación es destructiva y no permite una perspectiva compactada y no compactada de la misma secuencia.
- Una secuencia compactada sigue teniendo un modelo de acceso secuencial, lo que significa que la búsqueda del valor deseado en el registro requiere leer todo el registro en el peor de los casos, lo que normalmente conduce a optimizaciones que implementan el patrón exacto que se presenta aquí: proyección del contenido del registro en una base de datos o en una caché.
En última instancia, un registro compactado es un almacén de clave-valor y, como tal, es la peor opción de implementación posible para este tipo de almacén. Es mucho más eficaz para las búsquedas y consultas crear y usar una proyección permanente del registro en un almacén de clave-valor o en otra base de datos.
Dado que los eventos son inmutables y siempre se conserva el orden en un registro, cualquier proyección de un registro en un almacén de clave-valor siempre será idéntica para el mismo intervalo de eventos, lo que significa que una proyección que se mantenga actualizada siempre proporciona una vista fiable y no hay ningún motivo para recompilarla a partir del contenido del registro una vez creada.
Orientación:
Tecnologías de aplicaciones de replicación
Para implementar los patrones anteriores se requiere un entorno de ejecución escalable y confiable para las tareas de replicación que quiera configurar y ejecutar. En Azure, los entornos en tiempo de ejecución que son más adecuados para estas tareas sin estado son Azure Stream Analytics para las tareas de replicación de secuencias con estado y Azure Functions para las tareas de replicación sin estado.
Aplicaciones de replicación con estado en Azure Stream Analytics
En el caso de las aplicaciones de replicación con estado que necesitan tener en cuenta las relaciones entre eventos, crear eventos compuestos, enriquecer eventos o reducir eventos, crear agregaciones de datos y transformar cargas de eventos, Azure Stream Analytics es la mejor opción de implementación.
En Azure Stream Analytics, se crean trabajos que integran entradas y salidas e integran los datos de las entradas a través de consultas que producen un resultado que se pone a disposición de las salidas.
Las consultas se basan en el lenguaje de consulta SQL y se puede usar para filtrar, ordenar, agregar y unir con facilidad los datos de transmisión a lo largo de un período de tiempo. También puede ampliar este lenguaje SQL con JavaScript y funciones definidas por el usuario (UDF) de C#. Puede ajustar fácilmente las opciones de ordenación de eventos y la duración de las ventanas de tiempo al realizar operaciones de agregación mediante configuraciones o construcciones de lenguaje sencillas.
Cada trabajo tiene una o varias salidas para los datos transformados, y puede controlar lo que ocurre como respuesta a la información que ha analizado. Por ejemplo, puede:
- Enviar datos a servicios como Azure Functions, Temas o Colas de Service Bus para desencadenar comunicaciones o flujos de trabajo personalizados de bajada.
- Enviar datos al panel de Power BI para ordenarlos en el panel en tiempo real.
- Almacenar los datos en otros servicios de Azure Storage (como Azure Data Lake o Azure Synapse Analytics, entre otros) para realizar un análisis por lotes o entrenar modelos de Machine Learning basados en grupos indexados muy grandes de datos históricos.
- Almacenar proyecciones (también denominadas "vistas materializadas") en las bases de datos (SQL Database, Azure Cosmos DB).
Aplicaciones de replicación sin estado en Azure Functions
En el caso de las tareas de replicación sin estado en las que quiera reenviar eventos sin tener en cuenta sus cargas o procesarlas de manera individual sin tener en cuenta las relaciones de los eventos (excepto su orden relativo), puede usar Azure Functions, lo que proporciona una gran flexibilidad.
Azure Functions cuenta con desencadenadores y enlaces de salida pregenerados y escalables para Azure Event Hubs, Azure IoT Hub, Azure Service Bus, Azure Event Grid y Azure Queue Storage, así como extensiones personalizadas para RabbitMQ y Apache Kafka. La mayoría de los desencadenadores se adaptan dinámicamente a las necesidades de rendimiento al escalar y reducir verticalmente el número de instancias que se ejecutan a la vez en función de las métricas documentadas.
Para crear proyecciones de registro, Azure Functions admite enlaces de salida para Azure Cosmos DB y Azure Table Storage.
Azure Functions puede ejecutarse en una identidad administrada de Azure y con ello, puede almacenar los valores de configuración de esas credenciales en el almacenamiento con acceso estrictamente controlado dentro de Azure Key Vault.
Además, Azure Functions permite que las tareas de replicación se integren directamente con las redes virtuales y los puntos de conexión de servicio de Azure en todos los servicios de mensajería de Azure, y se integra fácilmente con Azure Monitor.
Con el plan de consumo de Azure Functions, los desencadenadores pregenerados se pueden reducir verticalmente hasta cero mientras no haya mensajes disponibles para la replicación, lo que significa que no se generan costos por mantener la configuración lista para escalar verticalmente de nuevo; la principal desventaja de usar el plan de consumo es que la latencia de "reactivación" de las tareas de replicación desde este estado es significativamente mayor que con los planes de hospedaje en los que la infraestructura se mantiene en ejecución.
En contraste con todo esto, los motores de replicación más comunes de mensajería y eventos, como MirrorMaker de Apache Kafka requieren que proporcione un entorno de hospedaje y que escale el motor de replicación por su cuenta. Esto incluye configurar e integrar las características de seguridad y red y facilitar el flujo de supervisión de los datos, e incluso así, no tiene la oportunidad de insertar tareas de replicación personalizadas en el flujo.
Elección entre Azure Functions y Azure Stream Analytics
Azure Stream Analytics (ASA) es la mejor opción siempre que necesite procesar la carga de eventos mientras se replican. ASA puede copiar eventos uno a uno o puede crear agregados que condensen la información de las secuencias de eventos antes de reenviarla. Puede apoyarse fácilmente en datos de referencia complementarios, conservados en Azure Blob Storage o Azure SQL Database, sin tener que importar estos datos en una secuencia.
Con ASA, puede crear fácilmente vistas materializadas y persistentes de secuencias en bases de datos a gran escala. Se trata de un enfoque muy superior al modelo inadecuado de "compactación del registro" de Apache Kafka y las proyecciones de tablas volátiles del lado cliente de Kafka Streams.
ASA puede procesar fácilmente eventos con cargas codificadas en los formatos CSV, JSON y Apache Avro y puede conectar deserializadores personalizados para cualquier otro formato.
Para todas las tareas de replicación en las que desea copiar secuencias de eventos "tal cual" y sin tocar las cargas, o bien, si necesita implementar un enrutador, realizar trabajo criptográfico, cambiar la codificación de cargas o, si es necesario el control total sobre el contenido de las secuencias de datos, Azure Functions es la mejor opción.
Pasos siguientes
En este artículo, se ha explorado una serie de patrones de federación y se ha explicado el papel de Azure Functions como entorno de ejecución de replicación de eventos y mensajería en Azure.
A continuación, podría documentarse sobre cómo configurar una aplicación de réplica con Azure Stream Analytics o Azure Functions y, luego, cómo replicar flujos de eventos entre Event Hubs y otros diversos sistemas de mensajería y eventos: