API de Table y SQL en clústeres de Apache Flink® en HDInsight en AKS
Nota:
Retiraremos Azure HDInsight en AKS el 31 de enero de 2025. Antes del 31 de enero de 2025, deberá migrar las cargas de trabajo a Microsoft Fabric o un producto equivalente de Azure para evitar la terminación repentina de las cargas de trabajo. Los clústeres restantes de la suscripción se detendrán y quitarán del host.
Solo el soporte técnico básico estará disponible hasta la fecha de retirada.
Importante
Esta funcionalidad actualmente está en su versión preliminar. En Términos de uso complementarios para las versiones preliminares de Microsoft Azure encontrará más términos legales que se aplican a las características de Azure que están en versión beta, en versión preliminar, o que todavía no se han lanzado con disponibilidad general. Para más información sobre esta versión preliminar específica, consulte la Información de Azure HDInsight sobre la versión preliminar de AKS. Para plantear preguntas o sugerencias sobre la característica, envíe una solicitud en AskHDInsight con los detalles y síganos para obtener más actualizaciones sobre Comunidad de Azure HDInsight.
Apache Flink incluye dos API relacionales( Table API y SQL) para el procesamiento por lotes y flujos unificados. Table API es una API de consulta integrada en lenguaje que permite la composición de consultas de operadores relacionales, como la selección, el filtro y la combinación intuitivamente. La compatibilidad con SQL de Flink se basa en Apache Calcte, que implementa el estándar SQL.
Las interfaces table API y SQL se integran perfectamente entre sí y con la API DataStream de Flink’. Puede cambiar fácilmente entre todas las API y bibliotecas, que se basan en ellas.
Apache Flink SQL
Al igual que otros motores de SQL, las consultas de Flink funcionan sobre tablas. Difiere de una base de datos tradicional porque Flink no administra los datos en reposo localmente; en su lugar, sus consultas funcionan continuamente sobre tablas externas.
Las canalizaciones de procesamiento de datos de Flink comienzan con tablas de origen y terminan con tablas receptoras. Las tablas de origen generan filas operadas durante la ejecución de la consulta; son las tablas a las que se hace referencia en la cláusula FROM de una consulta. Los conectores pueden ser de tipo HDInsight Kafka, HDInsight HBase, Azure Event Hubs, bases de datos, sistemas de archivos o cualquier otro sistema cuyo conector se encuentra en la ruta de clase.
Uso del cliente SQL de Flink en clústeres de HDInsight en AKS
Puede consultar este artículo sobre cómo usar la CLI desde Secure Shell en Azure Portal. Estos son algunos ejemplos rápidos de cómo empezar.
Para iniciar el cliente SQL
./bin/sql-client.shPara pasar un archivo sql de inicialización para ejecutarse junto con sql-client
./sql-client.sh -i /path/to/init_file.sqlPara establecer una configuración en sql-client
SET execution.runtime-mode = streaming; SET sql-client.execution.result-mode = table; SET sql-client.execution.max-table-result.rows = 10000;
SQL DDL
Flink SQL admite las siguientes instrucciones CREATE
- CREATE TABLE
- CREATE DATABASE
- CREATE CATÁLOGO
A continuación se muestra una sintaxis de ejemplo para definir una tabla de origen mediante el conector jdbc para conectarse a MSSQL, con el identificador, el nombre como columnas de una instrucción crear tabla
CREATE TABLE student_information (
id BIGINT,
name STRING,
address STRING,
grade STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:sqlserver://servername.database.windows.net;database=dbname;encrypt=true;trustServerCertificate=true;create=false;loginTimeout=30',
'table-name' = 'students',
'username' = 'username',
'password' = 'password'
);
CREACIÓN DE UNA BASE DE DATOS:
CREATE DATABASE students;
CREACIÓN DE CATÁLOGO:
CREATE CATALOG myhive WITH ('type'='hive');
Puede ejecutar consultas continuas sobre estas tablas
SELECT id,
COUNT(*) as student_count
FROM student_information
GROUP BY grade;
Escriba en Tabla receptora desde Tabla de origen:
INSERT INTO grade_counts
SELECT id,
COUNT(*) as student_count
FROM student_information
GROUP BY grade;
Adición de dependencias
Las instrucciones JAR se usan para agregar archivos JAR de usuario a la ruta de clase o quitar los archivos jar de usuario de la ruta de clase o mostrar los archivos jar agregados en la ruta de acceso de clase en el tiempo de ejecución.
Flink SQL admite las siguientes instrucciones JAR:
- ADD JAR
- MOSTRAR ARCHIVOS JAR
- REMOVER JAR
Flink SQL> ADD JAR '/path/hello.jar';
[INFO] Execute statement succeed.
Flink SQL> ADD JAR 'hdfs:///udf/common-udf.jar';
[INFO] Execute statement succeed.
Flink SQL> SHOW JARS;
+----------------------------+
| jars |
+----------------------------+
| /path/hello.jar |
| hdfs:///udf/common-udf.jar |
+----------------------------+
Flink SQL> REMOVE JAR '/path/hello.jar';
[INFO] The specified jar is removed from session classloader.
Metastore de Hive en clústeres de Apache Flink® en HDInsight en AKS
Los catálogos proporcionan metadatos, como bases de datos, tablas, particiones, vistas y funciones e información necesarias para acceder a los datos almacenados en una base de datos u otros sistemas externos.
En HDInsight en AKS, Flink admite dos opciones de catálogo:
GenericInMemoryCatalog
El GenericInMemoryCatalog es una implementación en memoria de un catálogo. Todos los objetos solo están disponibles durante la vigencia de la sesión sql.
HiveCatalog
El HiveCatalog sirve para dos propósitos; como almacenamiento persistente para metadatos de Flink puros y como una interfaz para leer y escribir metadatos de Hive existentes.
Nota:
Los clústeres de HDInsight en AKS incluyen una opción integrada del Metastore de Hive para Apache Flink. Puede optar por Metastore de Hive durante creación de clústeres
Cómo crear y registrar bases de datos de Flink en catálogos
Puede consultar este artículo sobre cómo usar la CLI y empezar a trabajar con Flink SQL Client desde Secure Shell en Azure Portal.
Iniciar sesión de
sql-client.sh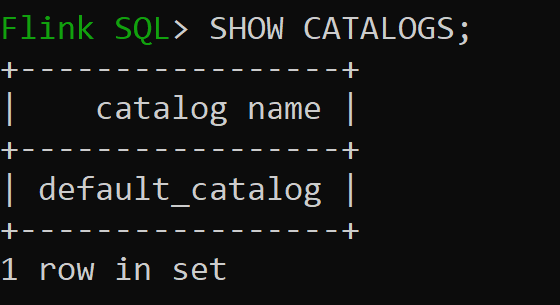
Default_catalog es el catálogo en memoria predeterminado
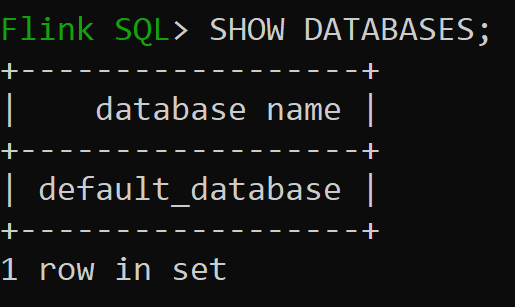
Ahora vamos a comprobar la base de datos predeterminada del catálogo en memoria
Vamos a crear el catálogo de Hive de la versión 3.1.2 y usarlo
CREATE CATALOG myhive WITH ('type'='hive'); USE CATALOG myhive;Nota:
HDInsight en AKS admite Hive 3.1.2 y Hadoop 3.3.2. El
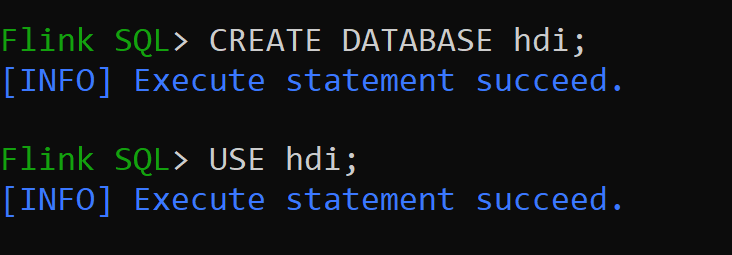
hive-conf-dirse establece en ubicación/opt/hive-confVamos a crear la base de datos en el catálogo de hive y convertirlo en valor predeterminado para la sesión (a menos que se cambie).
Cómo crear y registrar tablas de Hive en el catálogo de Hive
Siga las instrucciones de Creación y registro de bases de datos de Flink en catálogo
Vamos a crear la tabla Flink del tipo de conector Hive sin partición
CREATE TABLE hive_table(x int, days STRING) WITH ( 'connector' = 'hive', 'sink.partition-commit.delay'='1 s', 'sink.partition-commit.policy.kind'='metastore,success-file');Insertar datos en hive_table
INSERT INTO hive_table SELECT 2, '10'; INSERT INTO hive_table SELECT 3, '20';Leer datos de hive_table
Flink SQL> SELECT * FROM hive_table; 2023-07-24 09:46:22,225 INFO org.apache.hadoop.mapred.FileInputFormat[] - Total input files to process : 3 +----+-------------+--------------------------------+ | op | x | days | +----+-------------+--------------------------------+ | +I | 3 | 20 | | +I | 2 | 10 | | +I | 1 | 5 | +----+-------------+--------------------------------+ Received a total of 3 rowsNota:
El directorio de Hive Warehouse se encuentra en el contenedor designado de la cuenta de almacenamiento elegida durante la creación del clúster de Apache Flink, se puede encontrar en el subárbol del directorio/almacenamiento/
Vamos a crear la tabla Flink del tipo de conector hive sin partición
CREATE TABLE partitioned_hive_table(x int, days STRING) PARTITIONED BY (days) WITH ( 'connector' = 'hive', 'sink.partition-commit.delay'='1 s', 'sink.partition-commit.policy.kind'='metastore,success-file');
Importante
Hay una limitación conocida en Apache Flink. Las últimas columnas ‘n’ se eligen para las particiones, independientemente de la columna de partición definida por el usuario. FLINK-32596 La clave de partición será incorrecta al usar el dialecto de Flink para crear una tabla de Hive.
Referencia
- API de Apache Flink Table y SQL
- Apache, Apache Flink, Flink y los nombres de proyecto de código abierto asociados son marcas comerciales de Apache Software Foundation (ASF).