Acceso a registros de aplicación de YARN de Apache Hadoop en HDInsight basado en Linux
Aprenda a acceder a los registros de aplicaciones Apache Hadoop YARN (del inglés Yet Another Resource Negotiator) en un clúster Apache Hadoop en Azure HDInsight.
¿Qué es Apache YARN?
YARN admite varios modelos de programación (MapReduce de Apache Hadoop es uno de ellos) al desacoplar la administración de recursos de la programación/supervisión de aplicaciones. Así, YARN usa una instancia de ResourceManager (RM) global, NodeManagers (NM) por nodo de trabajo y ApplicationMasters (AM) por aplicación. El AM por aplicación negocia recursos (CPU, memoria, disco, red) para ejecutar la aplicación con el RM. El RM funciona con NM para conceder estos recursos como contenedores. El AM es responsable del seguimiento del progreso de los contenedores asignados a él por el RM. Una aplicación puede requerir muchos contenedores según la naturaleza de la aplicación.
Cada aplicación puede constar de varios intentos de aplicación. Si se produce un error en una aplicación, se puede reintentar como un nuevo intento. Cada intento se ejecuta en un contenedor. En cierto sentido, un contenedor proporciona el contexto de la unidad básica de trabajo realizado por una aplicación de YARN. Todo el trabajo que se realiza en el contexto de un contenedor se lleva a cabo en el nodo de trabajo individual en el que se dio el contenedor. Vea Hadoop: escritura de aplicaciones YARN o Apache Hadoop YARN como referencia.
Para escalar el clúster a fin de admitir un mayor rendimiento de procesamiento, se puede usar Escalabilidad automática o Escalar los clústeres manualmente mediante unos pocos idiomas distintos.
Servidor de escala de tiempo de YARN
El servidor de escala de tiempo de Apache Hadoop YARN proporciona información genérica sobre aplicaciones completadas.
El servidor de escala de tiempo de YARN incluye los siguientes tipos de datos:
- El ID de la aplicación, que es el identificador único de una aplicación.
- El usuario que ha iniciado la aplicación.
- La información acerca de los intentos realizados para completar la aplicación.
- Los contenedores usados por cualquier intento de aplicación concreto.
Registros y aplicaciones de YARN
Los registros de aplicación (y los registros de contenedor asociados) son fundamentales en la depuración de las aplicaciones de Hadoop problemáticas. YARN proporciona un buen marco para recopilar, agregar y almacenar registros de aplicaciones con Agregación de registro.
La característica Agregación de registro hace que el acceso a los registros de las aplicaciones sea más determinista. Esta característica agrega los registros en todos los contenedores de un nodo de trabajo y los almacena como un archivo de registros agregados por cada nodo de trabajo. El registro se almacena en el sistema de archivos de forma predeterminada una vez finalizada una aplicación. Su aplicación puede usar cientos o miles de contenedores, pero los registros para todos los contenedores que se ejecutan en un único nodo de trabajo se agregarán siempre a un único archivo. Por tanto, solo hay un registro por nodo de trabajo usado por la aplicación. La agregación de registros está habilitada de forma predeterminada en los clústeres de HDInsight de la versión 3.0 y superior. Los registros agregados se encuentran en el almacenamiento predeterminado del clúster. La siguiente ruta de acceso es la ruta de acceso de HDFS a los registros:
/app-logs/<user>/logs/<applicationId>
En la ruta de acceso, user es el nombre del usuario que inició la aplicación. applicationId es el identificador único asignado a una aplicación mediante el RM de YARN.
Los registros agregados no son legibles directamente, ya que se escriben en TFile, un formato binario indexado por contenedor. Use los registros de ResourceManager de YARN o las herramientas de la CLI para ver estos registros como texto sin formato para aplicaciones o contenedores de interés.
Registros de YARN en un clúster de ESP
Se deben agregar dos configuraciones al elemento mapred-site personalizado en Ambari.
En un explorador web, vaya a
https://CLUSTERNAME.azurehdinsight.net, dondeCLUSTERNAMEes el nombre del clúster.En la interfaz de usuario de Ambari, vaya a MapReduce2>Configs>Advanced>Custom mapred-site (MapReduce2 > Configuraciones > Avanzado > mapred-site personalizado).
Agregue uno de los siguientes conjuntos de propiedades:
Conjunto 1
mapred.acls.enabled=true mapreduce.job.acl-view-job=*Conjunto 2
mapreduce.job.acl-view-job=<user1>,<user2>,<user3>Guarde los cambios y reinicie todos los servicios afectados.
Herramientas de la CLI de YARN
Use el comando SSH para conectarse al clúster. Edite el comando siguiente reemplazando CLUSTERNAME por el nombre del clúster y escriba el comando:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netEnumere todos los identificadores de aplicación de las aplicaciones Yarn que se estén ejecutando con el siguiente comando:
yarn topTenga en cuenta el identificador de aplicación de la columna
APPLICATIONIDcuyos registros se van a descargar.YARN top - 18:00:07, up 19d, 0:14, 0 active users, queue(s): root NodeManager(s): 4 total, 4 active, 0 unhealthy, 0 decommissioned, 0 lost, 0 rebooted Queue(s) Applications: 2 running, 10 submitted, 0 pending, 8 completed, 0 killed, 0 failed Queue(s) Mem(GB): 97 available, 3 allocated, 0 pending, 0 reserved Queue(s) VCores: 58 available, 2 allocated, 0 pending, 0 reserved Queue(s) Containers: 2 allocated, 0 pending, 0 reserved APPLICATIONID USER TYPE QUEUE #CONT #RCONT VCORES RVCORES MEM RMEM VCORESECS MEMSECS %PROGR TIME NAME application_1490377567345_0007 hive spark thriftsvr 1 0 1 0 1G 0G 1628407 2442611 10.00 18:20:20 Thrift JDBC/ODBC Server application_1490377567345_0006 hive spark thriftsvr 1 0 1 0 1G 0G 1628430 2442645 10.00 18:20:20 Thrift JDBC/ODBC ServerPuede ver estos registros como texto sin formato ejecutando uno de los siguientes comandos:
yarn logs -applicationId <applicationId> -appOwner <user-who-started-the-application> yarn logs -applicationId <applicationId> -appOwner <user-who-started-the-application> -containerId <containerId> -nodeAddress <worker-node-address>Al ejecutar estos comandos, especifique la siguiente información: <applicationId>, <user-who-started-the-application>, <containerId> y <worker-node-address>.
Otros comandos de ejemplo
Descargue los registros de contenedor de Yarn para todos los maestros de aplicación con el siguiente comando. Este paso crea el archivo de registro denominado
amlogs.txten formato de texto.yarn logs -applicationId <application_id> -am ALL > amlogs.txtDescargue los registros de contenedor de Yarn solo para el maestro de aplicación más reciente con el siguiente comando:
yarn logs -applicationId <application_id> -am -1 > latestamlogs.txtDescargue los registros de contenedor de YARN para los dos primeros maestros de aplicación con el siguiente comando:
yarn logs -applicationId <application_id> -am 1,2 > first2amlogs.txtDescargue todos los registros de contenedor de Yarn con el siguiente comando:
yarn logs -applicationId <application_id> > logs.txtDescargue el registro de Yarn de un contenedor determinado con el siguiente comando:
yarn logs -applicationId <application_id> -containerId <container_id> > containerlogs.txt
UI de ResourceManager de YARN
La interfaz de usuario de ResourceManager de YARN se ejecuta en el nodo principal del clúster. Se accede a ella a través de la interfaz de usuario web de Ambari. Para ver los registros de YARN, use los siguientes pasos:
Abra el explorador y vaya a
https://CLUSTERNAME.azurehdinsight.net. Reemplace CLUSTERNAME por el nombre del clúster de HDInsight.En la lista de servicios de la izquierda de la página, seleccione YARN.
En la lista desplegable Vínculos rápidos, seleccione uno de los nodos principales del clúster y seleccione
ResourceManager Log.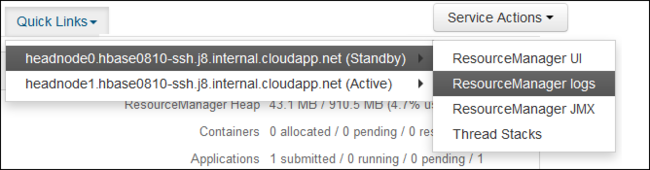
Aparece una lista de vínculos a los registros de YARN.