Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Interactive Query, también llamado Apache Hive LLAP o Low Latency Analytical Processing (Procesamiento analítico de baja latencia), es un nuevo tipo de clúster de Azure HDInsight. Interactive Query admite el almacenamiento en el caché de la memoria, lo que hace que las consultas de Apache Hive sean más rápidas y mucho más interactivas. Los clientes usan Interactive Query para consultar muy rápidamente los datos almacenados en Azure Storage y Azure Data Lake Storage. Interactive Query facilita que los desarrolladores y los científicos de datos trabajen con los macrodatos mediante las herramientas de BI que prefieran. Interactive Query de HDInsight admite varias herramientas para acceder a los macrodatos con facilidad.
Un clúster de Interactive Query no es igual que un clúster de Apache Hadoop. Solo contiene el servicio de Hive.
Solo se puede obtener acceso al servicio Hive en el clúster de Interactive Query mediante la vista Apache Ambari Hive, Beeline y el controlador de conectividad abierta de bases de datos de Microsoft Hive (Hive ODBC). No se puede acceder a él mediante la consola de Hive, Templeton, la CLI de Azure clásica ni Azure PowerShell.
Creación de un clúster de Interactive Query
Para obtener más información sobre cómo crear un clúster de HDInsight, consulte Create Apache Hadoop clusters in HDInsight (Creación de clústeres de Apache Hadoop en HDInsight). Elija el tipo de clúster de Interactive Query.
Importante
El tamaño mínimo del nodo principal de los clústeres de Interactive Query es Standard_D13_v2. Para más información, vea el gráfico de ajuste de tamaño de máquina virtual de Azure.
Ejecutar consultas de Apache Hive desde Interactive Query
Para ejecutar consultas de Hive, tiene las siguientes opciones:
| Método | Descripción |
|---|---|
| Microsoft Power BI | Consulte Visualización de datos de Interactive Query Apache Hive con Power BI en Azure HDInsight y Visualización de macrodatos con Power BI en Azure HDInsight. |
| Visual Studio | Consulte Conectarse a Azure HDInsight y ejecutar consultas de Apache Hive con Herramientas de Data Lake para Visual Studio. |
| Visual Studio Code | Consulte el artículo de Uso de Visual Studio Code para Apache Hive, LLAP o pySpark. |
| Vista de Hive de Apache Ambari | Consulte Use Apache Hive View with Apache Hadoop in Azure HDInsight (Uso de la vista de Apache Hive con Apache Hadoop en Azure HDInsight). La vista de Hive no está disponible para HDInsight 4.0. |
| Apache Beeline | Consulte Use Apache Hive with Apache Hadoop in HDInsight with Beeline (Uso de Apache Hive con Apache Hadoop en HDInsight con Beeline). Puede usar Beeline desde el nodo principal o desde un nodo perimetral vacío. Se recomienda usar Beeline en un nodo perimetral vacío. Para más información sobre la creación de un clúster de HDInsight con un nodo perimetral vacío, consulte Uso de nodos perimetrales vacíos en HDInsight. |
| ODBC de Hive | Consulte Connect Excel to Apache Hadoop with the Microsoft Hive ODBC driver (Conexión de Excel a Apache Hadoop con Microsoft Hive ODBC Driver). |
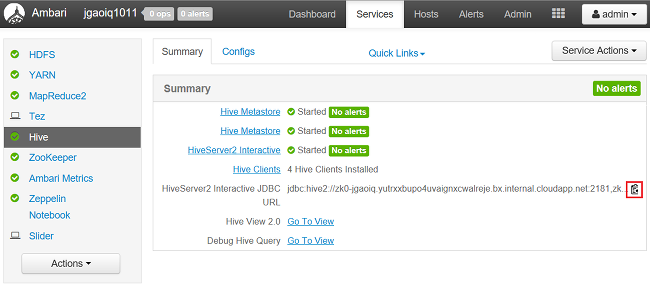
Para buscar la cadena de conexión de Java Database Connectivity (JDBC):
En un explorador web, vaya a
https://CLUSTERNAME.azurehdinsight.net/#/main/services/HIVE/summary, dondeCLUSTERNAMEes el nombre del clúster.Para copiar la dirección URL, seleccione el icono del Portapapeles: