Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo, aprenderá a instalar Jupyter Notebook con los kernels personalizados de PySpark (para Python) y Apache Spark (para Scala) utilizando Sparkmagic. A continuación, conecte el cuaderno a un clúster de HDInsight.
Hay cuatro pasos principales implicados en la instalación de Jupyter y la conexión a Apache Spark en HDInsight.
- Configuración de un clúster de Spark.
- Instalación de Jupyter Notebook.
- Instalación de los kernels de PySpark y Spark con Sparkmagic.
- Configuración de Sparkmagic para obtener acceso al clúster de Spark en HDInsight.
Para más información sobre los kernels personalizados y Sparkmagic, consulte este artículo sobre los kernels disponibles para Jupyter Notebook con clústeres Apache Spark basados en Linux en HDInsight.
Prerrequisitos
Un clúster de Apache Spark en HDInsight. Para obtener instrucciones, vea Creación de clústeres Apache Spark en HDInsight de Azure. El cuaderno local se conecta al clúster de HDInsight.
Experiencia en el uso de Jupyter Notebooks con Spark en HDInsight.
Instalación de Jupyter Notebook en el equipo
Instale Python para poder instalar los cuadernos de Jupyter Notebook. La distribución Anaconda instalará ambas soluciones: Python y Jupyter Notebook.
Descargue el instalador de Anaconda para su plataforma y ejecute el programa de instalación. Durante la ejecución del Asistente para instalación, asegúrese de seleccionar la opción para agregar Anaconda a la variable PATH. Consulte también el tema sobre la instalación de Jupyter con Anaconda.
Instalación de Sparkmagic
Escriba el comando
pip install sparkmagic==0.13.1para instalar Spark Magic para las versiones 3.6 y 4.0 de los clústeres de HDInsight. Consulte también la documentación de Sparkmagic.Ejecute el comando siguiente para asegurarse de que
ipywidgetsestá instalado correctamente:jupyter nbextension enable --py --sys-prefix widgetsnbextension
Instalación de los kernels de PySpark y Spark
Para identificar dónde está instalado
sparkmagic, escriba el comando siguiente:pip show sparkmagicA continuación, cambie el directorio de trabajo a la ubicación identificada con el comando anterior.
Desde el directorio de trabajo nuevo, escriba uno o varios de los siguientes comandos para instalar los kernels deseados:
Kernel Get-Help Spark jupyter-kernelspec install sparkmagic/kernels/sparkkernelSparkR jupyter-kernelspec install sparkmagic/kernels/sparkrkernelPySpark jupyter-kernelspec install sparkmagic/kernels/pysparkkernelPySpark3 jupyter-kernelspec install sparkmagic/kernels/pyspark3kernelOpcional. Escriba el siguiente comando para habilitar la extensión del servidor:
jupyter serverextension enable --py sparkmagic
Configuración de Sparkmagic para acceder al clúster de Spark en HDInsight
En esta sección, configurará el conjunto de Sparkmagic que instaló anteriormente para conectarse a un clúster de Apache Spark.
Inicie el shell de Python con el comando siguiente:
pythonNormalmente, la información de configuración de Jupyter se almacena en el directorio principal de los usuarios. Escriba el comando siguiente para identificar el directorio principal y cree una carpeta denominada .sparkmagic. Se mostrará la salida de la ruta de acceso completa.
import os path = os.path.expanduser('~') + "\\.sparkmagic" os.makedirs(path) print(path) exit()Dentro de la carpeta
.sparkmagic, cree un archivo llamado config.json y agréguele el siguiente fragmento de código JSON.{ "kernel_python_credentials" : { "username": "{USERNAME}", "base64_password": "{BASE64ENCODEDPASSWORD}", "url": "https://{CLUSTERDNSNAME}.azurehdinsight.net/livy" }, "kernel_scala_credentials" : { "username": "{USERNAME}", "base64_password": "{BASE64ENCODEDPASSWORD}", "url": "https://{CLUSTERDNSNAME}.azurehdinsight.net/livy" }, "custom_headers" : { "X-Requested-By": "livy" }, "heartbeat_refresh_seconds": 5, "livy_server_heartbeat_timeout_seconds": 60, "heartbeat_retry_seconds": 1 }Realice los siguientes cambios en el archivo:
Valor de la plantilla Valor nuevo {USERNAME} Inicio de sesión del clúster; el valor predeterminado es admin.{CLUSTERDNSNAME} Nombre del clúster {BASE64ENCODEDPASSWORD} Contraseña codificada en Base64 de su contraseña real. Puede generar una contraseña codificada en Base64 en https://www.url-encode-decode.com/base64-encode-decode/. "livy_server_heartbeat_timeout_seconds": 60Manténgalo si usa sparkmagic 0.12.7(clústeres v3.5 y v3.6). Si usasparkmagic 0.2.3(clústeres 3.4), reemplácelo por"should_heartbeat": true.Puede ver un archivo de ejemplo completo en example_config.json.
Sugerencia
Los latidos se envían para garantizar que no se pierdan sesiones. Cuando un equipo entra en modo de suspensión o se apaga, no se enviará el latido, con lo que se la sesión se limpia. Para los clústeres 3.4, si desea deshabilitar este comportamiento, puede establecer la configuración de Livio
livy.server.interactive.heartbeat.timeouta0en la interfaz de usuario de Ambari. Para los clústeres 3.5, si no establece la configuración de 3.5 anterior, no se eliminará la sesión.Reinicie Jupyter. En la ventana del símbolo del sistema, ejecute el comando siguiente.
jupyter notebookCompruebe que puede utilizar el conjunto Sparkmagic disponible con los kernels. Complete los siguientes pasos.
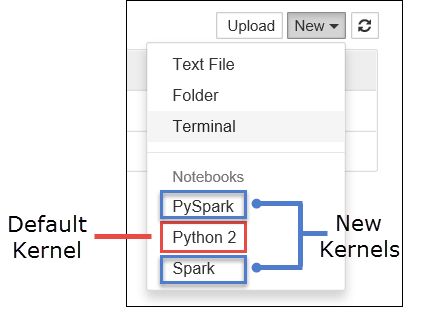
a. Cree un nuevo notebook. En la esquina de la derecha, seleccione Nuevo. Debería ver el kernel predeterminado Python 2 o Python 3 y los kernels que ha instalado. Los valores reales pueden variar según las opciones de instalación. Seleccione PySpark.
Importante
Después de seleccionar Nuevo, revise si el shell presenta errores. Si ve el error
TypeError: __init__() got an unexpected keyword argument 'io_loop', es posible que esté experimentando un problema conocido con determinadas versiones de Tornado. Si es así, detenga el kernel y degrade la versión de la instalación de Tornado con el siguiente comando:pip install tornado==4.5.3.b. Ejecute el siguiente fragmento de código.
%%sql SELECT * FROM hivesampletable LIMIT 5Si puede recuperar correctamente el resultado, se comprobará la conexión al clúster de HDInsight.
Si quiere actualizar la configuración del cuaderno para conectarse a un clúster distinto, actualice el archivo config.json con el nuevo conjunto de valores como se muestra en el paso 3 anterior.
¿Por qué debo instalar Jupyter en mi equipo?
Motivos para instalar Jupyter en el equipo y, a continuación, conectarlo a un clúster Apache Spark en HDInsight:
- Ofrece la opción de crear sus cuadernos localmente, probar la aplicación en un clúster en ejecución y, después, cargar los cuadernos en el clúster. Para cargar los cuadernos en el clúster, puede utilizar la instancia de Jupyter Notebook en ejecución o el clúster, o bien guardarlos en la carpeta
/HdiNotebooksde la cuenta de almacenamiento asociada al clúster. Para más información acerca de cómo se almacenan los cuadernos en el clúster, consulte la sección Almacenamiento de los cuadernos. - Con los cuadernos disponibles localmente, puede conectarse a diferentes clústeres de Spark según los requisitos de la aplicación.
- Puede usar GitHub para implementar un sistema de control de código fuente y tener el control de las versiones de los cuadernos. También puede tener un entorno de colaboración donde varios usuarios pueden trabajar con el mismo cuaderno.
- Puede trabajar con cuadernos localmente sin necesidad de un clúster activo. Solo necesita un clúster para probar los cuadernos, no para administrar manualmente los cuadernos o un entorno de desarrollo.
- Puede resultar más fácil configurar su propio entorno de desarrollo local que configurar la instalación de Jupyter en el clúster. Puede aprovechar todo el software que haya instalado localmente sin configurar uno o más clústeres remotos.
Advertencia
Con Jupyter instalado en el equipo local, varios usuarios pueden ejecutar el mismo cuaderno en el mismo clúster de Spark al mismo tiempo. En tal situación, se crean varias sesiones de Livy. Si surge un problema y desea depurarlo, es una tarea compleja realizar el seguimiento de a qué sesión de Livy pertenece cada usuario.