Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Los clústeres de HDInsight Spark proporcionan kernels que se pueden utilizar con el cuaderno de Jupyter Notebook en Azure Spark para probar las aplicaciones. Un kernel es un programa que ejecuta e interpreta el código. Estos son los tres kernels:
- PySpark: para aplicaciones escritas en Python2. (Solo se aplica a los clústeres de versiones de Spark 2.4)
- PySpark3: para aplicaciones escritas en Python3.
- Spark: para aplicaciones escritas en Scala.
En este artículo, aprenderá a usar estos kernels y las ventajas de utilizarlos.
Requisitos previos
Un clúster de Apache Spark en HDInsight. Para obtener instrucciones, vea Creación de clústeres Apache Spark en HDInsight de Azure.
Creación de un cuaderno de Jupyter Notebook en clústeres Spark de HDInsight
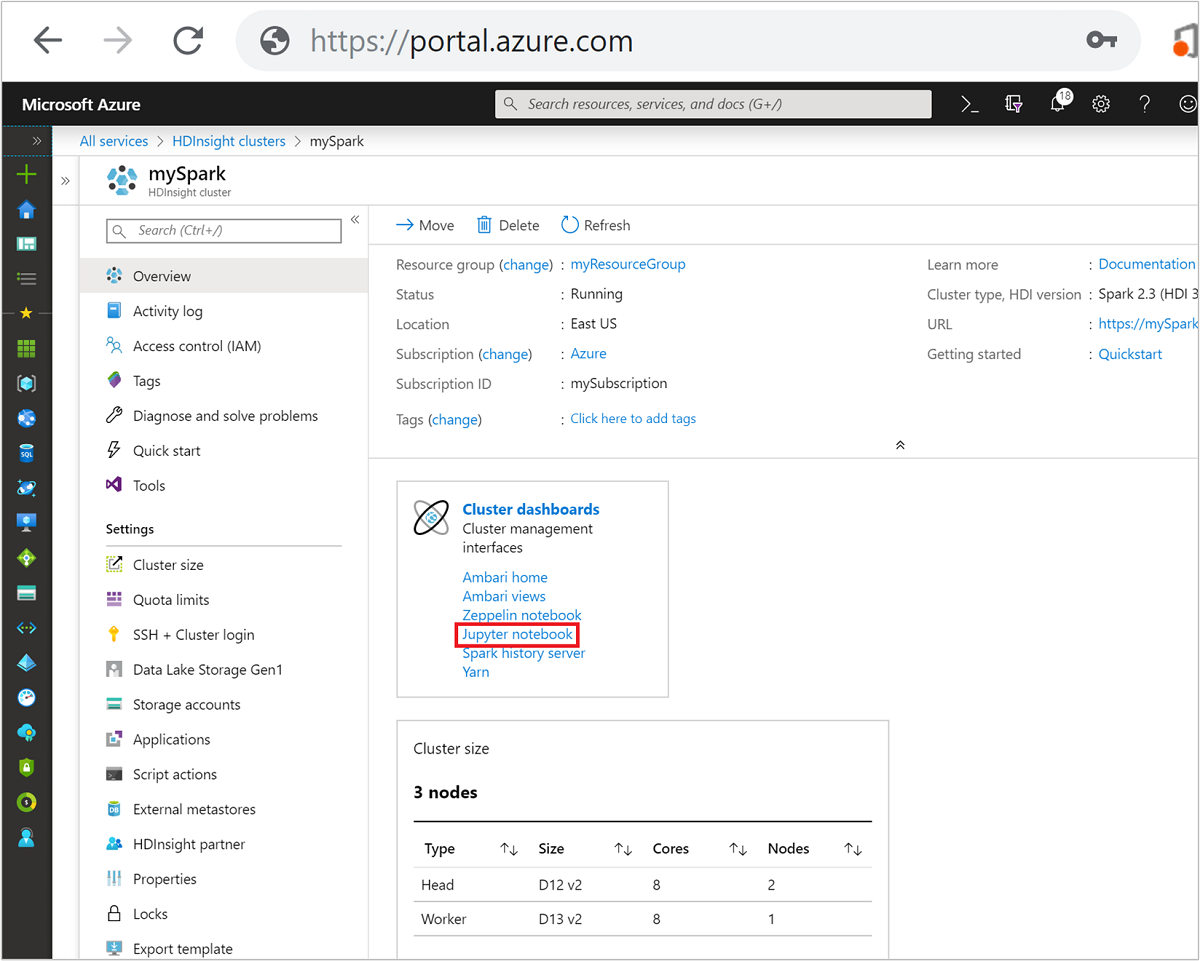
En Azure Portal, seleccione el clúster Spark. Consulte Enumeración y visualización de clústeres para obtener instrucciones. Se abre la vista Introducción.
Desde la vista Introducción, en el cuadro Paneles de clúster, seleccione Jupyter Notebook. Cuando se le pida, escriba las credenciales del clúster.
Nota:
También puede comunicarse con el cuaderno de Jupyter Notebook del clúster Spark si abre la siguiente dirección URL en el explorador. Reemplace CLUSTERNAME por el nombre del clúster:
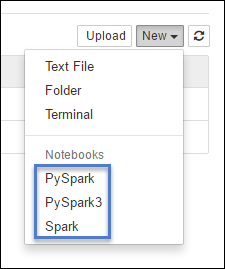
https://CLUSTERNAME.azurehdinsight.net/jupyterSeleccione Nuevo y, después, seleccione Pyspark, PySpark3 o Spark para crear un cuaderno. Utilice el kernel de Spark para las aplicaciones de Scala, kernel PySpark para aplicaciones de Python2 y kernel PySpark para3 aplicaciones de Python3.
Nota:
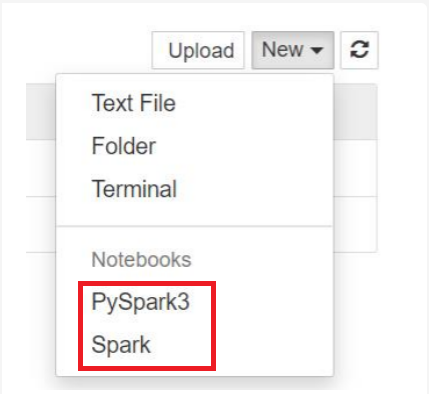
Para Spark 3.1, solo PySpark3 o Spark estarán disponibles.
- Se abre un cuaderno con el kernel que seleccionó.
Ventajas de utilizar los kernels
Estas son algunas ventajas de usar los kernels nuevos con el cuaderno de Jupyter Notebook en clústeres Spark de HDInsight.
Contextos preestablecidos. Gracias a los kernels de PySpark, PySpark3 o Spark, no necesita establecer de forma explícita los contextos de Spark o Hive para poder empezar a trabajar con las aplicaciones. Estos contextos están disponibles de forma predeterminada. Estos contextos son:
sc : para el contexto Spark
sqlContext : para el contexto Hive
Por tanto, no tiene que ejecutar instrucciones como la siguiente para definir los contextos:
sc = SparkContext('yarn-client') sqlContext = HiveContext(sc)En su lugar, puede utilizar directamente los contextos preestablecidos en la aplicación.
Instrucciones mágicas de celda. El kernel de PySpark proporciona algunas "instrucciones mágicas" predefinidas, que son comandos especiales que se pueden llamar con
%%(por ejemplo,%%MAGIC<args>). El comando mágico debe ser la primera palabra de una celda de código y permitir varias líneas de contenido. La palabra mágica debe ser la primera palabra en la celda. Si se agrega algo antes del comando mágico, incluso comentarios, se producirá un error. Para obtener más información sobre instrucciones mágicas, vaya aquí.La siguiente tabla muestra las diferentes instrucciones mágicas disponibles a través de los kernels.
Instrucción mágica Ejemplo Descripción help %%helpGenera una tabla de todas las instrucciones mágicas disponibles con el ejemplo y la descripción info %%infoProduce información de sesión del punto de conexión actual de Livy. CONFIGURAR %%configure -f{"executorMemory": "1000M","executorCores": 4}Configura los parámetros para crear una sesión. El marcador de fuerza ( -f) es obligatorio si ya se ha creado una sesión, lo que garantiza que la sesión se elimine y se vuelva a crear. Consulte Livy's POST /sessions Request Body (Cuerpo de la solicitud de sesiones o POST de Livy) para obtener una lista de parámetros válidos. Los parámetros deben pasarse como una cadena JSON y deben estar en la siguiente línea después de la instrucción mágica, como se muestra en la columna de ejemplo.sql %%sql -o <variable name>
SHOW TABLESEjecuta una consulta de Hive en el sqlContext. Si se pasa el parámetro -o, el resultado de la consulta se conserva en el contexto %%local de Python como trama de datos Pandas .local %%locala=1Todo el código de las últimas líneas se ejecuta localmente. El código debe ser un código Python2 válido con independencia del kernel que esté usando. Por tanto, aunque haya seleccionado los kernels PySpark3 o Spark al crear el cuaderno, si usa el comando mágico %%localen una celda, esta solo debe tener código Python2 válido.logs %%logsGenera los registros de la sesión actual de Livy. delete %%delete -f -s <session number>Elimina una sesión específica del punto de conexión actual de Livy. No puede eliminar la sesión iniciada para el propio kernel. cleanup %%cleanup -fElimina todas las sesiones del punto de conexión actual de Livy, incluida la sesión de este cuaderno. La marca force -f es obligatoria. Nota
Además de las instrucciones mágicas agregadas mediante el kernel PySpark, también puede utilizar las instrucciones integradas de IPython, como
%%sh. Puede usar la instrucción mágica%%shpara ejecutar scripts y el bloque de código en el nodo principal del clúster.Visualización automática. El kernel Pyspark visualiza automáticamente el resultado de las consultas de Hive y SQL. Puede elegir entre diferentes tipos de visualizaciones, como tabla, circular, línea, área o barra.
Parámetros compatibles con la instrucción mágica %%sql
El comando mágico %%sql es compatible con distintos parámetros que se pueden usar para controlar el tipo de resultado que se obtiene al ejecutar consultas. En la tabla siguiente se muestra el resultado.
| Parámetro | Ejemplo | Descripción |
|---|---|---|
| -o | -o <VARIABLE NAME> |
Use este parámetro para conservar el resultado de la consulta en el contexto %%local de Python como trama de datos Pandas . El nombre de la variable de la trama de datos es el nombre de variable que especifique. |
| -q | -q |
Use este parámetro para desactivar las visualizaciones de la celda. Si no quiere visualizar de forma automática el contenido de una celda y simplemente quiere capturarlo como una trama de datos, use -q -o <VARIABLE>. Si quiere desactivar visualizaciones sin capturar los resultados (por ejemplo, para ejecutar una consulta de SQL, como una instrucción CREATE TABLE), use -q sin especificar un argumento -o. |
| -M | -m <METHOD> |
Donde METHOD puede ser take o sample (el valor predeterminado es take). Si el método es take , el kernel toma elementos de la parte superior del conjunto de datos de resultados especificado por MAXROWS (se describe más adelante en esta tabla). Si el método es sample, el kernel toma como muestra los elementos del conjunto de datos de forma aleatoria en función del parámetro -r, que se describe a continuación en esta tabla. |
| -r | -r <FRACTION> |
Aquí FRACTION es un número de punto flotante entre 0,0 y 1,0. Si el método sample de la consulta SQL es sample, el kernel muestrea de forma aleatoria la fracción especificada de los elementos del conjunto de resultados establecido. Por ejemplo, si ejecuta una consulta SQL con los argumentos -m sample -r 0.01, el 1 % de las filas del resultados se muestrean de forma aleatoria. |
| -n | -n <MAXROWS> |
MAXROWS es un valor entero. El kernel limita el número de filas de salida a MAXROWS. Si MAXROWS tiene un valor negativo (por ejemplo, -1), no se limita el número de filas del conjunto de resultados. |
Ejemplo:
%%sql -q -m sample -r 0.1 -n 500 -o query2
SELECT * FROM hivesampletable
La instrucción anterior hace lo siguiente:
- Selecciona todos los registros de hivesampletable.
- Dado que se usa -q, desactiva la visualización automática.
- Dado que se usa
-m sample -r 0.1 -n 500, toma como muestra de forma aleatoria el 10 % de las filas de hivesampletable y limita el tamaño del conjunto de resultados a 500 filas. - Por último, dado que se ha usado
-o query2, también guarda el resultado en una trama de datos denominada query2.
Consideraciones al utilizar los kernels nuevos
Sea cual sea el kernel que se use, dejar los cuadernos en ejecución consumirá los recursos del clúster. Con estos kernels, dado que los contextos están preestablecidos, salir simplemente de los cuadernos no elimina el contexto. Y, por tanto, los recursos del clúster siguen en uso. Una buena práctica es usar la opción Cerrar y detener del menú Archivo del cuaderno cuando haya terminado de usarlo. De esta forma, se termina el contexto y luego se sale del cuaderno.
Almacenamiento de los cuadernos
Si el clúster usa Azure Storage como la cuenta de almacenamiento predeterminada, las instancias de Jupyter Notebook se guardan en la cuenta de almacenamiento de la carpeta /HdiNotebooks. Es posible acceder a los cuadernos, los archivos de texto y las carpetas que se crean en Jupyter desde la cuenta de almacenamiento. Por ejemplo, si usa Jupyter para crear una carpeta myfolder y un cuaderno myfolder/mynotebook.ipynb, puede acceder a ese cuaderno en /HdiNotebooks/myfolder/mynotebook.ipynb dentro de la cuenta de almacenamiento. También ocurre lo contrario, es decir, si carga un cuaderno directamente en la cuenta de almacenamiento en /HdiNotebooks/mynotebook1.ipynb, se ve también desde Jupyter. Los cuadernos permanecen en la cuenta de almacenamiento incluso después de que se elimine el clúster.
Nota:
Los clústeres de HDInsight con Azure Data Lake Storage como almacenamiento predeterminado no almacenan los cuadernos en un almacenamiento asociado.
La forma de guardar los cuadernos en la cuenta de almacenamiento es compatible con Apache Hadoop HDFS. Si se usa SSH en el clúster, puede usar los comandos de administración de archivos:
| Get-Help | Descripción |
|---|---|
hdfs dfs -ls /HdiNotebooks |
# Enumera todo en el directorio raíz: todo lo que se encuentra en este directorio es visible para Jupyter en la página principal. |
hdfs dfs –copyToLocal /HdiNotebooks |
# Descargar el contenido de la carpeta HdiNotebooks |
hdfs dfs –copyFromLocal example.ipynb /HdiNotebooks |
# Carga un cuaderno example.ipynb en la carpeta raíz para que sea visible desde Jupyter |
Independientemente de si el clúster usa Azure Storage o Azure Data Lake Storage como la cuenta de almacenamiento predeterminada, los cuadernos también se guardan en el nodo principal del clúster en /var/lib/jupyter.
Explorador compatible
Los cuadernos de Jupyter Notebook que se ejecutan en clústeres Spark de HDInsight solo son compatibles con Google Chrome.
Sugerencias
El nuevo kernel está en la fase de evolución y se desarrollará con el tiempo. Por lo tanto, las API podrían cambiar a medida que estos kernels se consoliden. Agradecemos cualquier comentario que tenga al utilizar estos nuevos kernels. La información es útil para dar forma a la versión final de estos kernels. Puede dejar sus comentarios la sección Comentarios al final de este artículo.
Pasos siguientes
- Información general: Apache Spark en Azure HDInsight
- Uso de cuadernos de Apache Zeppelin con un clúster de Apache Spark en HDInsight
- Uso de paquetes externos con cuadernos de Jupyter Notebook
- Instalación de un cuaderno de Jupyter Notebook en el equipo y conexión al clúster de Apache Spark en HDInsight de Azure