Creación y ejecución de canalizaciones de Machine Learning con el SDK de Azure Machine Learning
SE APLICA A:  Azure ML del SDK de Python v1
Azure ML del SDK de Python v1
En este artículo, aprenderá a crear y ejecutar canalizaciones de aprendizaje automático mediante el SDK de Azure Machine Learning. Use canalizaciones de ML para crear un flujo de trabajo que reúna varias fases de ML. A continuación, publique esa canalización para acceder a ella posteriormente o compartirla con otras personas. Realice un seguimiento de las canalizaciones de ML para ver cómo funciona el modelo en el mundo real y detectar el desfase de datos. Las canalizaciones de ML son ideales para puntuar escenarios por lotes, para usar varios procesos, para reutilizar pasos en lugar de volver a ejecutarlos y para compartir flujos de trabajo de ML con otros usuarios.
Este artículo no es un tutorial. Para obtener instrucciones sobre cómo crear su primera canalización, consulte Tutorial: Compilación de una canalización de Azure Machine Learning para la puntuación por lotes o Uso de ML automatizado en una canalización de Azure Machine Learning en Python.
Si bien se puede usar un tipo distinto de canalización, denominado Azure Pipelines, para la automatización de CI/CD de tareas de Machine Learning, este tipo de canalización no se almacena en el área de trabajo. Compare ambas canalizaciones.
Las canalizaciones de Machine Learning que cree serán visibles para los miembros de su área de trabajo de Azure Machine Learning.
Las canalizaciones de ML se ejecutan en destinos de proceso (consulte ¿Qué son los destinos de proceso en Azure Machine Learning?). Asimismo, las canalizaciones pueden leer y escribir datos en y desde las ubicaciones deAzure Storage.
Si no tiene una suscripción de Azure, cree una cuenta gratuita antes de empezar. Pruebe la versión gratuita o de pago de Azure Machine Learning.
Requisitos previos
Un área de trabajo de Azure Machine Learning. Creación de recursos para el área de trabajo.
Configure un entorno de desarrollo para instalar el SDK de Azure Machine Learning o use una instancia de proceso de Azure Machine Learning con el SDK ya instalado.
Empiece asociando el área de trabajo:
import azureml.core
from azureml.core import Workspace, Datastore
ws = Workspace.from_config()
Configurar los recursos de aprendizaje automático
Cree los recursos necesarios para ejecutar una canalización de Machine Learning:
Configure un almacén de datos que puede usar para obtener acceso a los datos necesarios en los pasos de la canalización.
Configure un objeto
Datasetpara que apunte a los datos que se guardan o a los que puede acceder en un almacén de datos. Configure un objetoOutputFileDatasetConfigpara los datos temporales pasados entre los pasos de una canalización.Configure los destinos de proceso en los que se ejecutarán los pasos de su canalización.
Configurar un almacén de datos
Un almacén de datos almacena los datos a los que la canalización puede obtener acceso. Cada área de trabajo tiene un almacén de datos predeterminado. Puede registrar más almacenes de datos.
Cuando crea su área de trabajo, una instancia de Azure Files y una de Azure Blob Storage se adjuntan al área de trabajo. Se registra un almacén de datos predeterminado para conectarse al almacenamiento de blobs de Azure. Para obtener más información, consulte Decisión sobre cuándo usar Azure Files, Azure Blobs o Azure Disks.
# Default datastore
def_data_store = ws.get_default_datastore()
# Get the blob storage associated with the workspace
def_blob_store = Datastore(ws, "workspaceblobstore")
# Get file storage associated with the workspace
def_file_store = Datastore(ws, "workspacefilestore")
Los pasos suelen consumir datos y generar datos de salida. Igualmente, un paso puede crear datos como un modelo, un directorio con archivos dependientes o datos temporales. Estos datos están disponibles para otros pasos más adelante en la canalización. Para más información sobre cómo conectar la canalización a los datos, consulte los artículos Cómo tener acceso a los datos y Cómo registrar conjuntos de datos.
Configuración de datos con los objetos Dataset y OutputFileDatasetConfig
La mejor manera de proporcionar datos a una canalización es un objeto Dataset. El objeto Dataset apunta a datos que están en un almacén de datos o que son accesibles desde este o en una dirección URL web. La clase Dataset es abstracta, así que creará una instancia de un objeto FileDataset (que hace referencia a uno o varios archivos) o de un objeto TabularDataset que se crea a partir de uno o varios archivos con columnas delimitadas de datos.
Creará un objeto Dataset con métodos como from_file o from_delimited_files.
from azureml.core import Dataset
my_dataset = Dataset.File.from_files([(def_blob_store, 'train-images/')])
Los datos intermedios (o la salida de un paso) se representan mediante un objeto OutputFileDatasetConfig. output_data1 se genera como salida de un paso. Opcionalmente, estos datos se pueden registrar como un conjunto de datos mediante una llamada a register_on_complete. Si crea OutputFileDatasetConfig en un paso y lo usa como entrada para otro paso, esa dependencia de datos entre pasos crea un orden de ejecución implícito en la canalización.
Los objetos OutputFileDatasetConfig devuelven un directorio y, de forma predeterminada, escriben la salida en el almacén de datos predeterminado del área de trabajo.
from azureml.data import OutputFileDatasetConfig
output_data1 = OutputFileDatasetConfig(destination = (datastore, 'outputdataset/{run-id}'))
output_data_dataset = output_data1.register_on_complete(name = 'prepared_output_data')
Importante
Azure no elimina automáticamente los datos intermedios almacenados mediante OutputFileDatasetConfig.
Debe eliminar los datos intermedios mediante programación al final de una ejecución de canalización, usar un almacén de datos con una directiva de retención de datos corta o realizar la limpieza manual de forma periódica.
Sugerencia
Cargue solo los archivos pertinentes para el trabajo entre manos. Cualquier cambio en los archivos dentro del directorio de datos se considerará un motivo para volver a ejecutar el paso la próxima vez que se ejecute la canalización, incluso si se especifica la reutilización.
Configuración de un destino de proceso
En Azure Machine Learning, el término proceso (o destino de proceso) se refiere a las máquinas o clústeres que realizarán los pasos del cálculo en su canalización de aprendizaje automático. En el apartado sobre los destinos de proceso para el entrenamiento de modelos encontrará una lista completa de destinos de proceso, mientras que en el apartado sobre la creación de destinos de proceso obtendrá información sobre cómo crearlos y adjuntarlos a un área de trabajo. El proceso para crear o adjuntar un destino de proceso es el mismo independientemente de si entrena un modelo o ejecuta un paso de la canalización. Después de crear y adjuntar el destino de proceso, utilice el objeto ComputeTarget en su paso de canalización.
Importante
No se admite la realización de operaciones de administración en destinos de proceso desde dentro de trabajos remotos. Puesto que las canalizaciones de aprendizaje automático se envían como un trabajo remoto, no use operaciones de administración en destinos de proceso desde dentro de la canalización.
Proceso de Azure Machine Learning
Puede crear un proceso de Azure Machine Learning para ejecutar sus pasos. El código de otros destinos de proceso es similar, con parámetros ligeramente diferentes, en función del tipo.
from azureml.core.compute import ComputeTarget, AmlCompute
compute_name = "aml-compute"
vm_size = "STANDARD_NC6"
if compute_name in ws.compute_targets:
compute_target = ws.compute_targets[compute_name]
if compute_target and type(compute_target) is AmlCompute:
print('Found compute target: ' + compute_name)
else:
print('Creating a new compute target...')
provisioning_config = AmlCompute.provisioning_configuration(vm_size=vm_size, # STANDARD_NC6 is GPU-enabled
min_nodes=0,
max_nodes=4)
# create the compute target
compute_target = ComputeTarget.create(
ws, compute_name, provisioning_config)
# Can poll for a minimum number of nodes and for a specific timeout.
# If no min node count is provided it will use the scale settings for the cluster
compute_target.wait_for_completion(
show_output=True, min_node_count=None, timeout_in_minutes=20)
# For a more detailed view of current cluster status, use the 'status' property
print(compute_target.status.serialize())
Configuración del entorno de ejecución de entrenamiento
El siguiente paso consiste en asegurarse de que la ejecución del entrenamiento remoto tiene todas las dependencias necesarias para los pasos de entrenamiento. Las dependencias y el contexto del entorno de ejecución se establecen creando y configurando un objeto RunConfiguration.
from azureml.core.runconfig import RunConfiguration
from azureml.core.conda_dependencies import CondaDependencies
from azureml.core import Environment
aml_run_config = RunConfiguration()
# `compute_target` as defined in "Azure Machine Learning compute" section above
aml_run_config.target = compute_target
USE_CURATED_ENV = True
if USE_CURATED_ENV :
curated_environment = Environment.get(workspace=ws, name="AzureML-sklearn-0.24-ubuntu18.04-py37-cpu")
aml_run_config.environment = curated_environment
else:
aml_run_config.environment.python.user_managed_dependencies = False
# Add some packages relied on by data prep step
aml_run_config.environment.python.conda_dependencies = CondaDependencies.create(
conda_packages=['pandas','scikit-learn'],
pip_packages=['azureml-sdk', 'azureml-dataset-runtime[fuse,pandas]'],
pin_sdk_version=False)
El código anterior muestra dos opciones para administrar las dependencias. Tal como se presenta, con USE_CURATED_ENV = True, la configuración se basa en un entorno seleccionado. Los entornos seleccionados están preparados con bibliotecas interdependientes comunes y pueden ponerse en línea más rápido. Los entornos seleccionados tienen imágenes de Docker creadas previamente en Microsoft Container Registry. Para más información, consulte Entornos mantenidos de Azure Machine Learning.
La ruta de acceso que se toma si cambia USE_CURATED_ENV a False muestra el patrón para establecer explícitamente las dependencias. En ese escenario, se creará una nueva imagen de Docker personalizada y se registrará en Azure Container Registry dentro del grupo de recursos (consulte Introducción a los registros de contenedores privados de Docker en Azure). La creación y el registro de esta imagen pueden tardar unos minutos.
Construir los pasos de la canalización
Una vez creado el recurso de proceso y el entorno, está listo para definir los pasos de la canalización. Hay muchos pasos integrados disponibles a través del SDK de Azure Machine Learning, como puede ver en la documentación de referencia del paquete de azureml.pipeline.steps. La clase más flexible es PythonScriptStep, que ejecuta un script de Python.
from azureml.pipeline.steps import PythonScriptStep
dataprep_source_dir = "./dataprep_src"
entry_point = "prepare.py"
# `my_dataset` as defined above
ds_input = my_dataset.as_named_input('input1')
# `output_data1`, `compute_target`, `aml_run_config` as defined above
data_prep_step = PythonScriptStep(
script_name=entry_point,
source_directory=dataprep_source_dir,
arguments=["--input", ds_input.as_download(), "--output", output_data1],
compute_target=compute_target,
runconfig=aml_run_config,
allow_reuse=True
)
En el código anterior se muestra un paso típico de canalización inicial. El código de preparación de los datos está en un subdirectorio (en este ejemplo, "prepare.py" en el directorio "./dataprep.src"). Como parte del proceso de creación de la canalización, este directorio se comprime y se carga en el elemento compute_target y el paso ejecuta el script especificado como el valor de script_name.
Los valores arguments especifican las entradas y salidas del paso. En el ejemplo anterior, los datos de línea base son el conjunto de datos my_dataset. Los datos correspondientes se descargarán en el recurso de proceso, ya que el código lo especifica como as_download(). El script prepare.py realiza las tareas de transformación de datos adecuadas para la tarea a mano y envía los datos a output_data1, de tipo OutputFileDatasetConfig. Para más información, consulte Movimiento de datos a los pasos de canalización de Machine Learning (Python) y entre ellos.
El paso se ejecutará en el equipo definido por compute_target, con la configuración aml_run_config.
La reutilización de los resultados anteriores (allow_reuse) es clave cuando se usan canalizaciones en un entorno de colaboración, ya que eliminar las repeticiones innecesarias ofrece agilidad. La reutilización es el comportamiento predeterminado cuando el nombre del script, las entradas y los parámetros de un paso siguen siendo los mismos. Si se permite la reutilización, los resultados de la ejecución anterior se envían inmediatamente al paso siguiente. Si allow_reuse se establece en False, siempre se generará una nueva ejecución para este paso durante la ejecución de la canalización.
Es posible crear una canalización con un solo paso, pero casi siempre tendrá elegirá dividir el proceso general en varios pasos. Por ejemplo, puede tener pasos para la preparación de los datos, el entrenamiento, la comparación de modelos y la implementación. Por ejemplo, puede imaginarse que, después del elemento data_prep_step especificado anteriormente, el paso siguiente sería el entrenamiento:
train_source_dir = "./train_src"
train_entry_point = "train.py"
training_results = OutputFileDatasetConfig(name = "training_results",
destination = def_blob_store)
train_step = PythonScriptStep(
script_name=train_entry_point,
source_directory=train_source_dir,
arguments=["--prepped_data", output_data1.as_input(), "--training_results", training_results],
compute_target=compute_target,
runconfig=aml_run_config,
allow_reuse=True
)
El código anterior es similar al del paso de preparación de datos. El código de entrenamiento está en un directorio independiente del código de preparación de datos. La salida de OutputFileDatasetConfig del paso de preparación de datos, output_data1, se usa como entrada al paso de entrenamiento. Un nuevo objeto OutputFileDatasetConfig, training_results, se crea para almacenar los resultados de un paso posterior de comparación o implementación.
Para obtener otros ejemplos de código, vea cómo compilar una canalización de ML en dos pasos y cómo reescribir datos en almacenes de datos tras la finalización de la ejecución.
Después de definir sus pasos, debe compilar la canalización mediante algunos o todos ellos.
Nota
No se carga ningún archivo o dato en Azure Machine Learning cuando define los pasos o compila la canalización. Los archivos se cargan al llamar a Experiment.submit().
# list of steps to run (`compare_step` definition not shown)
compare_models = [data_prep_step, train_step, compare_step]
from azureml.pipeline.core import Pipeline
# Build the pipeline
pipeline1 = Pipeline(workspace=ws, steps=[compare_models])
Uso de un conjunto de datos
Los conjuntos de datos creados desde Azure Blob Storage, Azure Files, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, Azure SQL Database y Azure Database for PostgreSQL se pueden usar como entrada en cualquier paso de una canalización. Puede escribir la salida en DataTransferStep, DatabricksStep o, si quiere escribir los datos en un almacén de datos específico, use OutputFileDatasetConfig.
Importante
La reescritura de datos de salida en un almacén de datos con OutputFileDatasetConfig solo se admite en almacenes de datos de Azure Blob, Recurso compartido de archivos de Azure, ADLS Gen1 y Gen2.
dataset_consuming_step = PythonScriptStep(
script_name="iris_train.py",
inputs=[iris_tabular_dataset.as_named_input("iris_data")],
compute_target=compute_target,
source_directory=project_folder
)
A continuación, recupere el conjunto de datos de la canalización mediante el diccionario Run.input_datasets.
# iris_train.py
from azureml.core import Run, Dataset
run_context = Run.get_context()
iris_dataset = run_context.input_datasets['iris_data']
dataframe = iris_dataset.to_pandas_dataframe()
Merece la pena resaltar la línea Run.get_context(). Esta función recupera un objeto Run que representa la ejecución experimental actual. En el ejemplo anterior, se usa para recuperar un conjunto de datos registrado. Otro uso común del objeto Run es recuperar el propio experimento y el área de trabajo en el que reside el experimento:
# Within a PythonScriptStep
ws = Run.get_context().experiment.workspace
Para más información, incluidas formas alternativas de pasar datos y acceder a ellos, consulte Movimiento de datos a los pasos de canalización de ML (Python) o entre ellos.
Almacenamiento en caché y reutilización
Para optimizar y personalizar el comportamiento de las canalizaciones, puede hacer algunas cosas en relación con el almacenamiento en caché y la reutilización. Por ejemplo, puede hacer lo siguiente:
- Desactivar la reutilización predeterminada de la salida de ejecución de pasos configurando
allow_reuse=Falsedurante la definición de pasos. La reutilización es clave cuando se usan canalizaciones en un entorno de colaboración, ya que eliminar las repeticiones innecesarias ofrece agilidad. Sin embargo, puede optar por ignorar esta reutilización. - Forzar la regeneración de salida de todos los pasos de una ejecución con
pipeline_run = exp.submit(pipeline, regenerate_outputs=True)
De forma predeterminada, se habilita allow_reuse para los pasos y se crea un hash para el valor de source_directory especificados en la definición del paso. Así pues, si el script de un paso determinado permanece igual (script_name, entradas y parámetros) y no ha cambiado nada más de source_directory, se reutiliza la salida de un paso anterior ejecutado, el trabajo no se envía al proceso y los resultados de la ejecución anterior están inmediatamente disponibles para el siguiente paso.
step = PythonScriptStep(name="Hello World",
script_name="hello_world.py",
compute_target=aml_compute,
source_directory=source_directory,
allow_reuse=False,
hash_paths=['hello_world.ipynb'])
Nota
Si cambian los nombres de las entradas de datos, el paso se volverá a ejecutar, incluso si los datos subyacentes no cambian. Debe establecer explícitamente el campo name de los datos de entrada (data.as_input(name=...)). Si no establece explícitamente este valor, el campo name se establecerá en un GUID aleatorio y los resultados del paso no se reutilizarán.
Enviar la canalización
Cuando envía la canalización, Azure Machine Learning comprueba las dependencias para cada paso y carga una instantánea del directorio de origen especificado. Si no se especifica ningún directorio de origen, se carga el directorio local actual. La instantánea también se almacena como parte del experimento del área de trabajo.
Importante
Para evitar que se incluyan archivos innecesarios en la instantánea, cree un archivo ignore (.gitignore o .amlignore) en el directorio. Agregue los archivos y directorios que se van a excluir a este archivo. Para obtener más información sobre la sintaxis que se debe usar dentro de este archivo, vea sintaxis y patrones para .gitignore. El archivo .amlignore usa la misma sintaxis. Si ambos archivos existen, el archivo .amlignore se usa y el archivo .gitignore, no.
Para más información, consulte Instantánea.
from azureml.core import Experiment
# Submit the pipeline to be run
pipeline_run1 = Experiment(ws, 'Compare_Models_Exp').submit(pipeline1)
pipeline_run1.wait_for_completion()
Cuando se ejecuta por primera vez una canalización, Azure Machine Learning:
Descarga la instantánea del proyecto en el destino de proceso de la instancia de Blob Storage asociada al área de trabajo.
Crea una imagen de docker correspondiente a cada paso en la canalización.
Descarga la imagen de docker para cada paso en el destino de proceso del registro de contenedor.
Configura el acceso a los objetos
DatasetyOutputFileDatasetConfig. En modo de accesoas_mount(), se usa FUSE para proporcionar acceso virtual. Si no se admite el montaje o si el usuario especificó el acceso comoas_upload(), los datos se copian en su lugar en el destino de proceso.Ejecuta el paso en el destino de proceso especificado en la definición del paso.
Crea artefactos como registros, las propiedades stdout y stderr, métricas y resultados que especifica el paso. Estos artefactos se cargan y se guardan en el almacén de datos predeterminado del usuario.
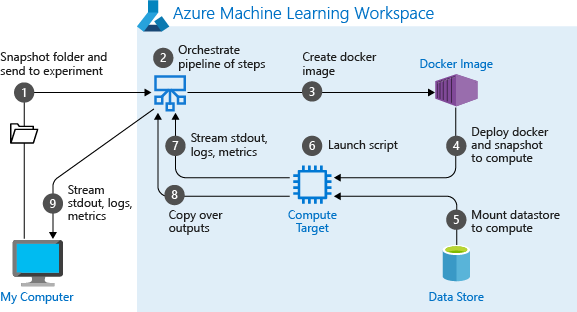
Para obtener más información, consulte la documentación de referencia de la clase Experimento.
Uso de parámetros de canalización para argumentos que cambian en tiempo de inferencia
A veces, los argumentos de pasos individuales de una canalización se relacionan con el período de desarrollo y entrenamiento: aspectos como las tarifas de entrenamiento y el momento, o las rutas de acceso a los datos o archivos de configuración. Pero cuando se implementa un modelo, se recomienda pasar de forma dinámica los argumentos en los que se está basando (es decir, la consulta cuya respuesta ha motivado la compilación del modelo). Debe convertir estos tipos de argumentos en parámetros de canalización. Para hacer esto en Python, use la clase azureml.pipeline.core.PipelineParameter, como se muestra en el siguiente fragmento de código:
from azureml.pipeline.core import PipelineParameter
pipeline_param = PipelineParameter(name="pipeline_arg", default_value="default_val")
train_step = PythonScriptStep(script_name="train.py",
arguments=["--param1", pipeline_param],
target=compute_target,
source_directory=project_folder)
Cómo funcionan los entornos de Python con los parámetros de canalización
Como se ha explicado anteriormente en Configuración del entorno de ejecución de entrenamiento, el estado del entorno y las dependencias de la biblioteca de Python se especifican mediante un objeto Environment. Por lo general, puede especificar un objeto Environment existente haciendo referencia a su nombre y, opcionalmente, a una versión:
aml_run_config = RunConfiguration()
aml_run_config.environment.name = 'MyEnvironment'
aml_run_config.environment.version = '1.0'
Sin embargo, si decide usar objetos PipelineParameter para establecer las variables dinámicamente en tiempo de ejecución para los pasos de la canalización, no puede usar esta técnica para hacer referencia a un objeto Environment existente. En su lugar, si quiere usar objetos PipelineParameter, debe establecer el campo environment de RunConfiguration en un objeto Environment. Es su responsabilidad asegurarse de que dicho Environment tenga establecidas correctamente sus dependencias en los paquetes externos de Python.
Visualización de los resultados de una canalización
Consulte la lista de todas las canalizaciones y sus detalles de ejecución en Studio:
Inicie sesión en Azure Machine Learning Studio.
A la izquierda, seleccione Canalizaciones para ver todas las ejecuciones de la canalización.
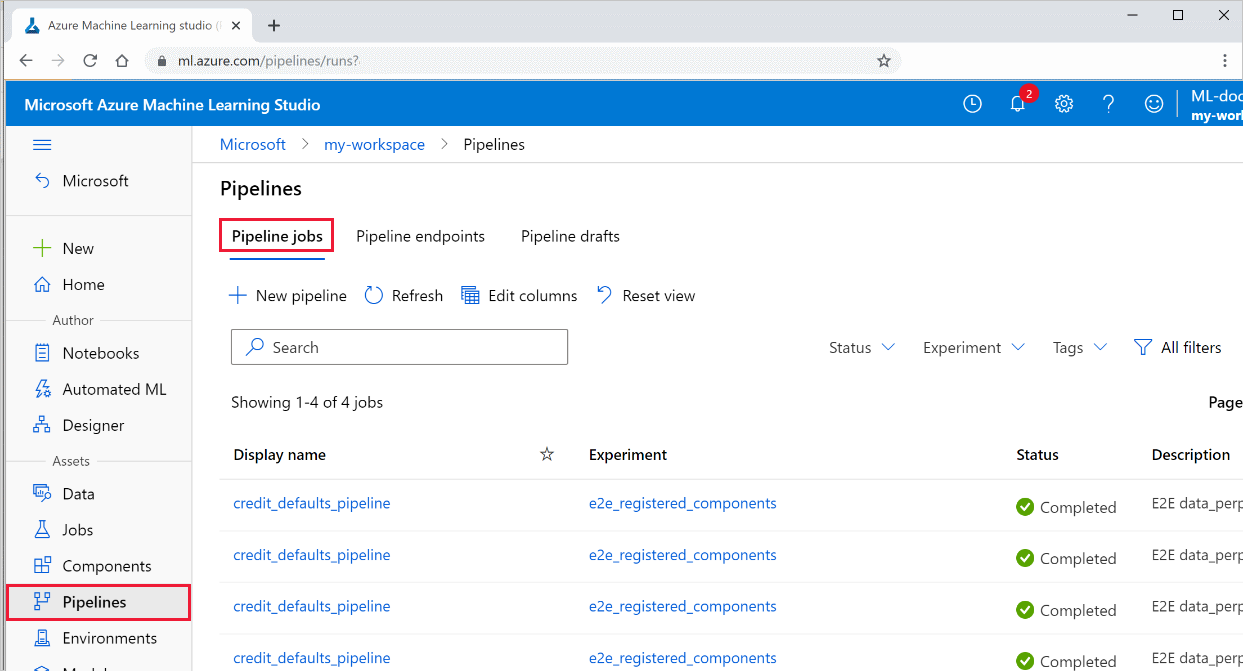
Seleccione una canalización específica para ver los resultados de la ejecución.
Integración y seguimiento de Git
Cuando se inicia una ejecución de entrenamiento en la que el directorio de origen es un repositorio de GIT local, se almacena información sobre el repositorio en el historial de ejecución. Para más información, consulte Integración de Git con Azure Machine Learning.
Pasos siguientes
- Para compartir su canalización con compañeros o clientes, consulte Publicación de canalizaciones de aprendizaje automático.
- Use estos cuadernos de Jupyter Notebook en GitHub para explorar en profundidad las canalizaciones de aprendizaje automático.
- Consulte la referencia del SDK para obtener ayuda con el paquete azureml-pipelines-core y el paquete azureml-pipelines-steps.
- Consulte los procedimientos para obtener sugerencias sobre la depuración y la solución de problemas de canalizaciones.
- Siga las instrucciones del artículo Exploración de Azure Machine Learning con cuadernos de Jupyter para aprender a ejecutar cuadernos.