Solución de problemas de canalizaciones de aprendizaje automático
SE APLICA A:  SDK de Python azureml v1
SDK de Python azureml v1
En este artículo aprenderá a resolver los problemas al recibir errores de ejecución de una canalización de aprendizaje automático en el SDK de Azure Machine Learning y el diseñador de Azure Machine Learning.
Sugerencias de solución de problemas
La tabla siguiente contiene problemas comunes que se pueden producir durante el desarrollo de canalizaciones y posibles soluciones a los mismo.
| Problema | Posible solución |
|---|---|
No se pueden pasar datos al directorio PipelineData |
Asegúrese de haber creado un directorio en el script que se corresponda con el lugar en el que la canalización espera los datos de salida del paso. En la mayoría de los casos, un argumento de entrada definirá el directorio de salida y, a continuación, se creará el directorio de forma explícita. Use os.makedirs(args.output_dir, exist_ok=True) para crear el directorio de salida. Si necesita un ejemplo de script de puntuación que muestra este patrón de diseño, acuda al tutorial correspondiente. |
| Errores de dependencia | Si viera errores de dependencia en la canalización remota que no se produjeron durante las pruebas locales, confirme que las dependencias y las versiones del entorno remoto coincidan con las de su entorno de prueba. Consulte el artículo Compilación, almacenamiento en caché y reutilización de entornos. |
| Errores ambiguos con destinos de proceso | Pruebe a eliminar y volver a crear los destinos de proceso. Volver a crear los destinos de proceso es un proceso rápido y puede resolver algunos problemas transitorios. |
| La canalización no reutiliza los pasos | La reutilización de pasos está habilitada de forma predeterminada, asegúrese de que no la ha deshabilitado en un paso de la canalización. Si la reutilización está deshabilitada, el parámetro allow_reuse del paso se establecerá en False. |
| La canalización se está volviendo a ejecutar innecesariamente | Para asegurarse de que los pasos solo se vuelven a ejecutar cuando sus datos o scripts subyacentes cambian, desacople los directorios de código fuente en cada paso. Si usa el mismo directorio de origen para varios pasos, puede experimentar la repetición innecesaria de ejecuciones. Use el parámetro source_directory en un objeto de paso de canalización para apuntar a su directorio aislado para ese paso, y asegúrese de que no está usando la misma ruta de acceso source_directory para varios pasos. |
| Paso más lento en los tiempos de entrenamiento u otro comportamiento de bucle | Intente cambiar cualquier escritura de archivo, incluido el registro, de as_mount() a as_upload(). El modo de montaje usa un sistema de archivos virtualizado remoto y carga todo el archivo cada vez que se anexa a este. |
| El destino de proceso tarda mucho en iniciarse | Las imágenes de Docker de los destinos de proceso se cargan desde Azure Container Registry (ACR). De manera predeterminada, Azure Machine Learning crea una instancia de ACR que usa el nivel de servicio Básico. Si se cambia la instancia de ACR del área de trabajo al nivel Estándar o Premium, puede reducirse el tiempo que se tarda en compilar y cargar imágenes. Para más información, consulte Niveles de servicio de Azure Container Registry. |
Errores de autenticación
Si realiza una operación de administración en un destino de proceso desde un trabajo remoto, recibirá uno de los siguientes errores:
{"code":"Unauthorized","statusCode":401,"message":"Unauthorized","details":[{"code":"InvalidOrExpiredToken","message":"The request token was either invalid or expired. Please try again with a valid token."}]}
{"error":{"code":"AuthenticationFailed","message":"Authentication failed."}}
Por ejemplo, si intenta crear o asociar un destino de proceso desde una canalización de aprendizaje automático que se envía para ejecución remota, recibirá un error.
Solución de problemas de ParallelRunStep
El script para ParallelRunStep debe contener dos funciones:
init(): utilice esta función para cualquier preparación costosa o común para la inferencia posterior. Por ejemplo, para cargar el modelo en un objeto global. Solo se llama a esta función una vez al principio del proceso.run(mini_batch): la función se ejecuta para cada instancia demini_batch.mini_batch:ParallelRunStepinvoca el método run y pasará una lista oDataFramede Pandas como argumento al método. Cada entrada de mini_batch es una ruta de acceso de archivo si la entrada esFileDataset, o bienDataFramede Pandas si la entrada esTabularDataset.response: El método run() debe devolverDataFramede Pandas o una matriz. Para append_row output_action, estos elementos devueltos se anexan al archivo de salida común. Para summary_only, se omite el contenido de los elementos. Para todas las acciones de salida, cada elemento de salida devuelto indica una ejecución correcta del elemento de entrada en el minilote de entrada. Asegúrese de que se incluyen suficientes datos en el resultado de la ejecución para asignar la entrada al resultado de la salida de la ejecución. La salida de la ejecución se escribe en el archivo de salida y no se garantiza que esté en orden, por lo que deberá usar alguna clave en la salida para asignarla a la entrada.
%%writefile digit_identification.py
# Snippets from a sample script.
# Refer to the accompanying digit_identification.py
# (https://github.com/Azure/MachineLearningNotebooks/tree/master/how-to-use-azureml/machine-learning-pipelines/parallel-run)
# for the implementation script.
import os
import numpy as np
import tensorflow as tf
from PIL import Image
from azureml.core import Model
def init():
global g_tf_sess
# Pull down the model from the workspace
model_path = Model.get_model_path("mnist")
# Construct a graph to execute
tf.reset_default_graph()
saver = tf.train.import_meta_graph(os.path.join(model_path, 'mnist-tf.model.meta'))
g_tf_sess = tf.Session()
saver.restore(g_tf_sess, os.path.join(model_path, 'mnist-tf.model'))
def run(mini_batch):
print(f'run method start: {__file__}, run({mini_batch})')
resultList = []
in_tensor = g_tf_sess.graph.get_tensor_by_name("network/X:0")
output = g_tf_sess.graph.get_tensor_by_name("network/output/MatMul:0")
for image in mini_batch:
# Prepare each image
data = Image.open(image)
np_im = np.array(data).reshape((1, 784))
# Perform inference
inference_result = output.eval(feed_dict={in_tensor: np_im}, session=g_tf_sess)
# Find the best probability, and add it to the result list
best_result = np.argmax(inference_result)
resultList.append("{}: {}".format(os.path.basename(image), best_result))
return resultList
Si tiene otro archivo o carpeta en el mismo directorio que el script de inferencia, puede hacer referencia a él buscando el directorio de trabajo actual.
script_dir = os.path.realpath(os.path.join(__file__, '..',))
file_path = os.path.join(script_dir, "<file_name>")
Parámetros para ParallelRunConfig
ParallelRunConfig es la configuración principal de la instancia de ParallelRunStep dentro de la canalización de Azure Machine Learning. Se usa para encapsular el script y configurar los parámetros necesarios, incluidos los de las siguientes entradas:
entry_script: script de usuario como ruta de acceso de archivo local que se ejecuta en paralelo en varios nodos. Sisource_directoryestá presente, utilice una ruta de acceso relativa. De lo contrario, use cualquier ruta de acceso accesible desde la máquina.mini_batch_size: tamaño del minilote que se pasa a una sola llamada derun(). (Opcional; el valor predeterminado es10archivos paraFileDataset, y1MBparaTabularDataset).- En el caso de
FileDataset, es el número de archivos con un valor mínimo de1. Puede combinar varios archivos en un solo minilote. - En el caso de
TabularDataset, es el tamaño de los datos. Los valores posibles son1024,1024KB,10MBy1GB.1MBes el valor recomendado. El minilote deTabularDatasetnunca cruzará los límites de los archivos. Por ejemplo, si tiene archivos. csv de varios tamaños, el menor es de 100 KB y el mayor es de 10 MB. Si establecemini_batch_size = 1MB, los archivos con un tamaño menor que 1 MB se tratan como un solo minilote. Los archivos de tamaño mayor que 1 MB se dividen en varios minilotes.
- En el caso de
error_threshold: número de errores de registro paraTabularDatasety errores de archivo paraFileDatasetque se deben omitir durante el procesamiento. Si el recuento de errores de la entrada supera este valor, el trabajo se anula. El umbral de error es para toda la entrada y no para los minilotes individuales que se envían al métodorun(). El intervalo es[-1, int.max]. La parte-1indica que se omitirán todos los errores durante el procesamiento.output_action: uno de los valores siguientes indica cómo se organiza la salida:summary_only: el script de usuario almacena la salida.ParallelRunStepusa la salida solo para el cálculo del umbral de error.append_row: en las entradas, solo se crea un archivo en la carpeta de salida para anexar todas las salidas separadas por líneas.
append_row_file_name: para personalizar el nombre del archivo de salida de append_row output_action (opcional; el valor predeterminado esparallel_run_step.txt).source_directory: rutas de acceso a las carpetas que contienen todos los archivos que se van a ejecutar en el destino de proceso (opcional).compute_target: Solo se admiteAmlCompute.node_count: número de nodos de proceso que se usarán para ejecutar el script de usuario.process_count_per_node: número de procesos por nodo. El procedimiento recomendado es establecerlo en el número de GPU o CPU que tenga un nodo (opcional; el valor predeterminado es1).environment: definición del entorno de Python. Puede configurarla para usar un entorno de Python existente o un entorno temporal. La definición también es responsable de establecer las dependencias de la aplicación necesarias (opcional).logging_level: nivel de detalle del registro. Los valores con nivel de detalle en aumento son:WARNING,INFOyDEBUG. (Opcional; el valor predeterminado esINFO).run_invocation_timeout: tiempo de espera de invocación del métodorun()en segundos. (Opcional; el valor predeterminado es60).run_max_try: número máximo de intentos derun()para un minilote. Se produce un error enrun()si se genera una excepción o no se devuelve nada cuando se alcanzarun_invocation_timeout(opcional; el valor predeterminado es3).
Puede especificar mini_batch_size, node_count, process_count_per_node, logging_level, run_invocation_timeout y run_max_try como PipelineParameter, de modo que, cuando vuelva a enviar una ejecución de la canalización, pueda optimizar los valores de los parámetros. En este ejemplo, se usa PipelineParameter para mini_batch_size y Process_count_per_node, y se cambian estos valores cuando se vuelve a enviar una ejecución posteriormente.
Parámetros para crear ParallelRunStep
Cree ParallelRunStep mediante el script, la configuración del entorno y los parámetros. Especifique el destino de proceso que ya adjuntó a su área de trabajo como destino de ejecución del script de inferencia. Use ParallelRunStep para crear el paso de canalización de inferencias por lotes, que toma todos los parámetros siguientes:
name: el nombre del paso, con las siguientes restricciones de nomenclatura: unique, 3-32 caracteres y regex ^[a-z]([-a-z0-9]*[a-z0-9])?$.parallel_run_config: objetoParallelRunConfig, tal y como se definió anteriormente.inputs: uno o varios conjuntos de datos de Azure Machine Learning de tipo único que se van a particionar para el procesamiento en paralelo.side_inputs: uno o varios datos de referencia o conjuntos de datos que se usan como entradas laterales sin necesidad de crear particiones.output: objetoOutputFileDatasetConfigque corresponde al directorio de salida.arguments: lista de los argumentos pasados al script de usuario. Use unknown_args para recuperarlos en el script de entrada (opcional).allow_reuse: sirve para decidir si el paso debe volver a usar los resultados anteriores cuando se ejecuta con la misma configuración o entrada. Si este parámetro fueraFalse, siempre se genera una nueva ejecución para este paso durante la ejecución de la canalización. (Opcional; el valor predeterminado esTrue).
from azureml.pipeline.steps import ParallelRunStep
parallelrun_step = ParallelRunStep(
name="predict-digits-mnist",
parallel_run_config=parallel_run_config,
inputs=[input_mnist_ds_consumption],
output=output_dir,
allow_reuse=True
)
Técnicas de depuración
Hay tres técnicas principales para depurar las canalizaciones:
- Depurar pasos de canalización individuales en el equipo local
- Usar el registro y Application Insights para aislar y diagnosticar el origen del problema
- Conectar un depurador remoto a una canalización que se ejecute en Azure
Depuración de scripts de forma local
Uno de los errores más comunes en una canalización es que el script de dominio no se ejecute según lo previsto, o que contenga errores en tiempo de ejecución difíciles de depurar en el contexto de proceso remoto.
Las propias canalizaciones no se pueden ejecutar localmente. Pero la ejecución de los scripts de forma aislada en la máquina local le permite depurar más rápido, ya que no es necesario esperar al proceso de compilación de proceso y de entorno. Para ello, se necesita realizar algo de trabajo de desarrollo:
- Si los datos estuvieran en un almacén de datos en la nube, tendrá que descargarlos y ponerlos a disposición del script. El uso de una pequeña muestra de los datos es una buena forma de reducir el tiempo de ejecución y obtener rápidamente comentarios sobre el comportamiento del script
- Si intenta simular un paso de canalización intermedio, es posible que tenga que compilar manualmente los tipos de objeto que el script específico espera del paso anterior
- Es necesario definir su propio entorno y replicar las dependencias definidas en el entorno de proceso remoto
Una vez que tenga una configuración de script que se ejecute en su entorno local, es más fácil realizar tareas de depuración como:
- Incorporación de una configuración de depuración personalizada
- Pausa de la ejecución e inspección del estado del objeto
- Detección de errores lógicos o de tipo que no se expondrían hasta el tiempo de ejecución
Sugerencia
Una vez que pueda comprobar que el script se ejecuta según lo previsto, un buen paso posterior es ejecutar el script en una canalización de un solo paso antes de intentar ejecutarlo en una canalización con varios pasos.
Configuración, escritura y revisión de los registros de canalización
Probar scripts localmente es una excelente manera de depurar fragmentos de código principales y lógica compleja antes de empezar a crear una canalización. En algún momento, debería depurar los scripts durante la ejecución real de la canalización, especialmente cuando se diagnostique el comportamiento que da lugar durante la interacción entre los pasos de la canalización. Se recomienda el uso generoso de las instrucciones print() en los scripts de paso, con el fin de ver el estado del objeto y los valores esperados durante la ejecución remota, de manera similar a como se depuraría el código de JavaScript.
Opciones de registro y comportamiento
En la tabla siguiente, se proporciona información sobre las distintas opciones de depuración para las canalizaciones. No se trata de una lista exhaustiva, ya que existen otras opciones aparte de las de Azure Machine Learning y Python que se muestran aquí.
| Biblioteca | Tipo | Ejemplo | Destination | Recursos |
|---|---|---|---|---|
| SDK de Azure Machine Learning | Métrica | run.log(name, val) |
UI del portal de Azure Machine Learning | Seguimiento de experimentos Clase azureml.core.Run |
| Impresión/registro de Python | Log | print(val)logging.info(message) |
Registros de controladores, el diseñador de Azure Machine Learning | Seguimiento de experimentos Registro de Python |
Ejemplo de opciones de registro
import logging
from azureml.core.run import Run
run = Run.get_context()
# Azure Machine Learning Scalar value logging
run.log("scalar_value", 0.95)
# Python print statement
print("I am a python print statement, I will be sent to the driver logs.")
# Initialize Python logger
logger = logging.getLogger(__name__)
logger.setLevel(args.log_level)
# Plain Python logging statements
logger.debug("I am a plain debug statement, I will be sent to the driver logs.")
logger.info("I am a plain info statement, I will be sent to the driver logs.")
handler = AzureLogHandler(connection_string='<connection string>')
logger.addHandler(handler)
Diseñador de Azure Machine Learning
En el caso de las canalizaciones creadas en el diseñador, puede encontrar el archivo 70_driver_log en la página de creación o en la página de detalles de ejecución de la canalización.
Habilitación del registro para puntos de conexión en tiempo real
Para solucionar problemas y depurar puntos de conexión en tiempo real en el diseñador, tiene que habilitar el registro de Application Insights mediante el SDK. El registro le permite depurar y solucionar problemas de uso e implementación de modelos. Para más información, consulte Registro para modelos implementados.
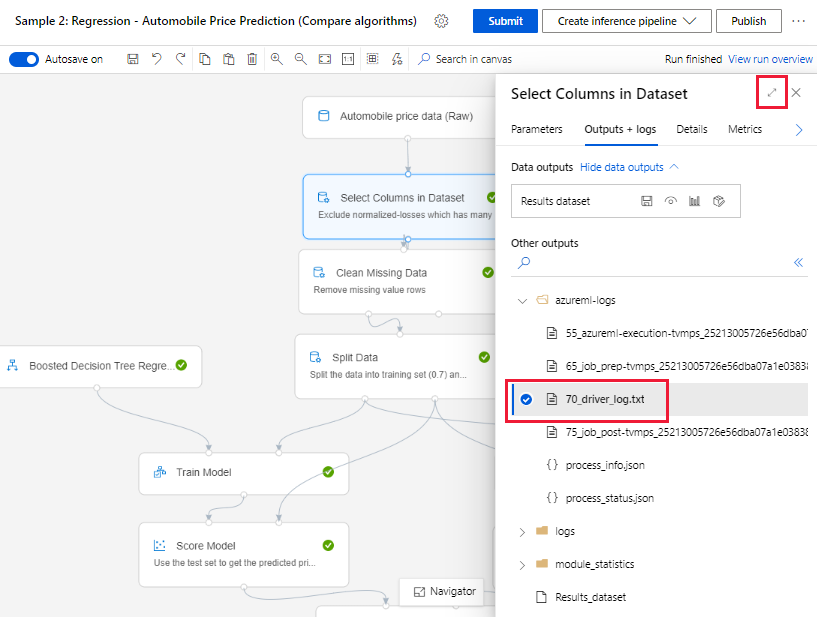
Obtención de los registros desde la página de creación
Cuando envía una ejecución de canalización y permanece en la página de creación, puede encontrar los archivos de registro generados para cada componente a medida que cada componente finaliza su ejecución.
Seleccione un componente que haya terminado de ejecutarse en el lienzo de creación.
En el panel derecho del componente, vaya a la pestaña Resultados y registros.
Expanda el panel derecho y seleccione el archivo 70_driver_log. txt para verlo en el explorador. También puede descargar registros localmente.
Obtención de registros desde las ejecuciones de canalización
También puede buscar los archivos de registro de ejecuciones específicas en la página de detalles de ejecución de canalización en las secciones Canalizaciones o Experimentos de Studio.
Seleccione una ejecución de canalización creada en el diseñador.

Seleccione un componente en el panel de vista previa.
En el panel derecho del componente, vaya a la pestaña Resultados y registros.
Expanda el panel derecho para ver el archivo std_log.txt en el explorador, o seleccione el archivo para descargar los registros de forma local.
Importante
Para actualizar una canalización desde la página de detalles de ejecución de la canalización, tiene que clonar la ejecución de la canalización en un nuevo borrador de canalización. Una ejecución de canalización es una instantánea de la canalización. Es similar a un archivo de registro y no se puede modificar.
Depuración interactiva con Visual Studio Code
En algunos casos, es posible que tenga que depurar interactivamente el código de Python usado en la canalización de ML. Mediante Visual Studio Code (VS Code) y debugpy, se puede conectar al código que se ejecuta en el entorno de entrenamiento. Para más información, visite la guía de depuración interactiva de VS Code.
Error de HyperdriveStep y AutoMLStep con aislamiento de red
Después de usar HyperdriveStep y AutoMLStep, al intentar registrar el modelo es posible que reciba un error.
Está usando el SDK de Azure Machine Learning v1.
El área de trabajo de Azure Machine Learning está configurada para el aislamiento de red (VNet).
La canalización intenta registrar el modelo generado por el paso anterior. Por ejemplo, en el ejemplo siguiente, el parámetro
inputses el modelo_guardado de un HyperdriveStep:register_model_step = PythonScriptStep(script_name='register_model.py', name="register_model_step01", inputs=[saved_model], compute_target=cpu_cluster, arguments=["--saved-model", saved_model], allow_reuse=True, runconfig=rcfg)
Solución alternativa
Importante
Este comportamiento no se producirá cuando se use el SDK de Azure Machine Learning v2.
Para solucionar este error, use la clase Run para obtener el modelo creado a partir de HyperdriveStep o AutoMLStep. A continuación, se muestra un script de ejemplo que obtiene el modelo de salida de un HyperdriveStep:
%%writefile $script_folder/model_download9.py
import argparse
from azureml.core import Run
from azureml.pipeline.core import PipelineRun
from azureml.core.experiment import Experiment
from azureml.train.hyperdrive import HyperDriveRun
from azureml.pipeline.steps import HyperDriveStepRun
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
'--hd_step_name',
type=str, dest='hd_step_name',
help='The name of the step that runs AutoML training within this pipeline')
args = parser.parse_args()
current_run = Run.get_context()
pipeline_run = PipelineRun(current_run.experiment, current_run.experiment.name)
hd_step_run = HyperDriveStepRun((pipeline_run.find_step_run(args.hd_step_name))[0])
hd_best_run = hd_step_run.get_best_run_by_primary_metric()
print(hd_best_run)
hd_best_run.download_file("outputs/model/saved_model.pb", "saved_model.pb")
print("Successfully downloaded model")
Después, el archivo se podrá usar desde PythonScriptStep:
from azureml.pipeline.steps import PythonScriptStep
conda_dep = CondaDependencies()
conda_dep.add_pip_package("azureml-sdk")
conda_dep.add_pip_package("azureml-pipeline")
rcfg = RunConfiguration(conda_dependencies=conda_dep)
model_download_step = PythonScriptStep(
name="Download Model 9",
script_name="model_download9.py",
arguments=["--hd_step_name", hd_step_name],
compute_target=compute_target,
source_directory=script_folder,
allow_reuse=False,
runconfig=rcfg
)
Pasos siguientes
Para un tutorial completo sobre cómo usar
ParallelRunStep, consulte Tutorial: Compilación de una canalización de Azure Machine Learning para la puntuación por lotes.Para un ejemplo completo en el que se muestra el aprendizaje automático automatizado en las canalizaciones de ML, consulte Uso de ML automatizado en una canalización de Azure Machine Learning en Python.
Consulte la referencia del SDK para encontrar ayuda para los paquetes azureml-pipelines-core y azureml-pipelines-steps.
Vea la lista de excepciones y códigos de error del diseñador.